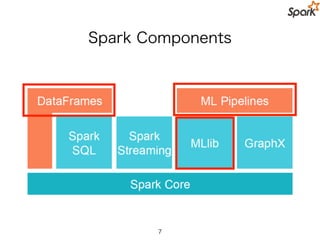
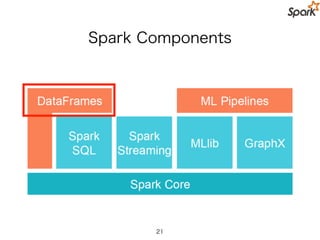
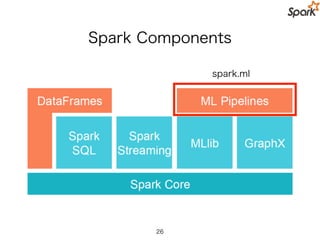
MLlib-specific Contribution Guidelines
•Be widely known
• Be used and accepted
• academic citations and concrete use cases can help justify this
• Be highly scalable
• Be well documented
• Have APIs consistent with other algorithms in MLLib that
accomplish the same thing
• Come with a reasonable expectation of developer support.
11
[https://cwiki.apache.org/confluence/display/SPARK/Contributing+to+Spark]
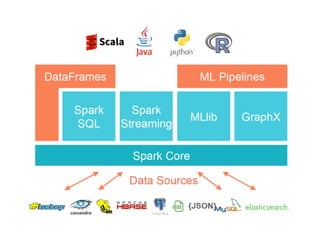
レコメンドアルゴリズム ALS の
単純な実行方法
valratings =
sc.textFile(“s3n:/path/to/csv/files/*”)
.map(_.split(","))
.map(x => Rating(x(0).toInt, x(1).toInt, x(2).toDouble)
13
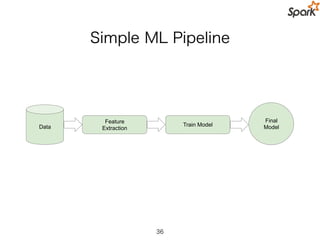
Data (CSV)
Load Data
Train Model
Evaluate
user_id product_id rating
473 348 0.8
5623 87583 0.3
6545 9382 0.5
234 246 0.6
14.
レコメンドアルゴリズム ALS の
単純な実行方法
valratings =
sc.textFile(“s3n:/path/to/csv/files/*”)
.map(_.split(","))
.map(x => Rating(x(0).toInt, x(1).toInt, x(2).toDouble)
val als = new ALS.setRank(10).setIterations(10)
val model = als.run(ratings)
14
Data
Loa Data
Train Model
Evaluate
レコメンド手法のひとつである
ALS のオブジェクトを生成して訓練
15.
レコメンドアルゴリズム ALS の
単純な実行方法
valratings =
sc.textFile(“s3n:/path/to/csv/files/*”)
.map(_.split(","))
.map(x => Rating(x(0).toInt, x(1).toInt, x(2).toDouble)
val als = new ALS.setRank(10).setIterations(10)
val model = als.run(ratings)
val userId = 12345
val productId = 987654
model.predict(userId, productId)
0.4…
15
Data
Loa Data
Train Model
EvaluateTop-level API がよくデザインされているので
非常に簡単に機械学習ライブラリが使える
16.
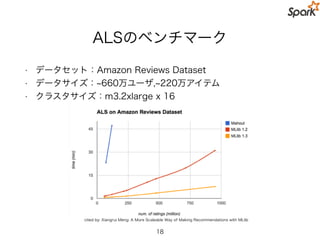
ALSのベンチマーク
• データセット:Amazon ReviewsDataset
• データサイズ: 660万ユーザ, 220万アイテム
• クラスタサイズ:m3.2xlarge x 16
16
cited by: Xiangrui Meng: A More Scaleable Way of Making Recommendations with MLlib
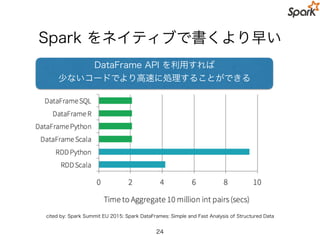
Spark をネイティブで書くより早い
22
cited by:Spark Summit EU 2015: Spark DataFrames: Simple and Fast Analysis of Structured Data
DataFrame API を利用すれば
少ないコードでより高速に処理することができる
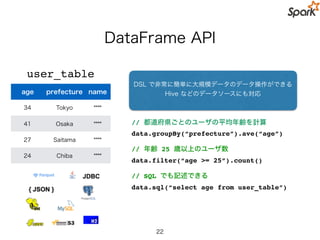
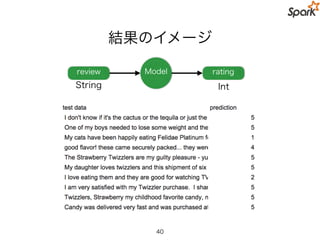
Our Task
• レビュー(review) のテキストから評価 (rating) を予測
27
review Model rating
String Int
28.
Load Data
• DataSchema
• label: Int
• text: String
28
Load Data
Feature Extraction
Train Model
Evaluate
29.
Feature Extraction
• DataSchema
• label: Int
• text: String
• words: Seq[String]
• features: Vector
29
Load Data
Hashed Term Freq.
Train Model
Evaluate
Tokenizer
Transformer
30.
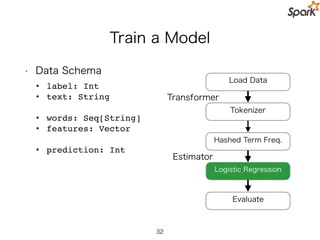
Train a Model
•Data Schema
• label: Int
• text: String
• words: Seq[String]
• features: Vector
• prediction: Int
30
Load Data
Hashed Term Freq.
Logistic Regression
Evaluate
Tokenizer
Transformer
Estimator
31.
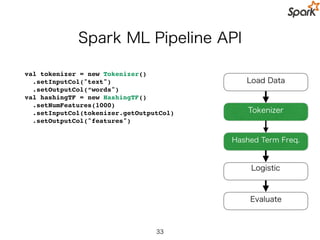
Spark ML PipelineAPI
val tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol(“words")
val hashingTF = new HashingTF()
.setNumFeatures(1000)
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("features")
31
Load Data
Hashed Term Freq.
Logistic Regression
Evaluate
Tokenizer
32.
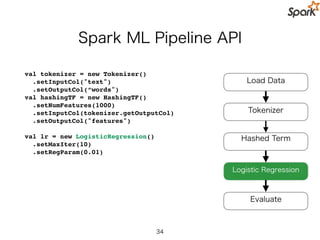
Spark ML PipelineAPI
val tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol(“words")
val hashingTF = new HashingTF()
.setNumFeatures(1000)
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("features")
val lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.01)
32
Load Data
Hashed Term Freq.
Logistic Regression
Evaluate
Tokenizer
33.
Spark ML PipelineAPI
val tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol(“words")
val hashingTF = new HashingTF()
.setNumFeatures(1000)
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("features")
val lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.01)
val pipeline = new Pipeline()
.setStages(Array(tokenizer, hashingTF, lr))
val model = pipeline.fit(training)
33
Pipeline
Load Data
Hashed Term Freq.
Logistic Regression
Evaluate
Tokenizer
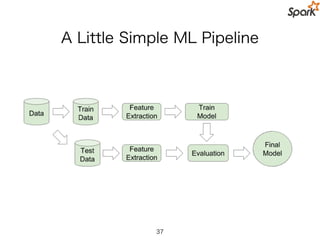
ML Pipelines forTest
36
Pipeline
Training Data
Hashed Term Freq.
Logistic Regression
Evaluate
Tokenizer
Pipeline
Test Data
Hashed Term Freq.
Logistic Regression
Evaluate
Tokenizer
37.
Pipeline API forTest
val tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol(“words")
val hashingTF = new HashingTF()
.setNumFeatures(1000)
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("features")
val lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.01)
val pipeline = new Pipeline()
.setStages(Array(tokenizer, hashingTF, lr))
val model = pipeline.fit(training)
model.transform(test)
37
Pipeline
Test Data
Hashed Term Freq.
Logistic Regression
Evaluate
Tokenizer
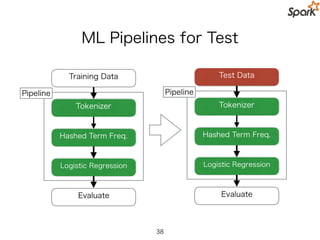
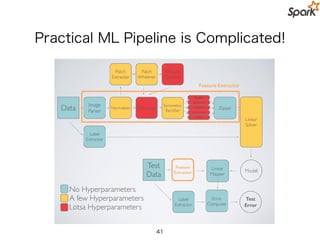
Practical ML Pipelineis Complicated!
39
Data Image!
Parser
Normalizer Convolver
sqrt,mean
Zipper
Linear
Solver
Symmetric!
Rectifier
ident,abs
ident,mean
Global
Pooler
Patch!
Extractor
Patch
Whitener
KMeans!
Clusterer
Feature Extractor
Label!
Extractor
Linear!
Mapper
Model
Test!
Data
Label!
Extractor
Feature
Extractor
Test
Error
Error!
Computer
No Hyperparameters!
A few Hyperparameters!
Lotsa Hyperparameters
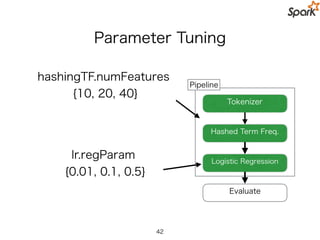
Practical Spark MLPipeline API
val paramGrid = new ParamGridBuilder()
.addGrid(hashingTF.numFeatures, Array(10, 20, 40))
.addGrid(lr.regParam, Array(0.01, 0.1, 0.5))
.build()
42
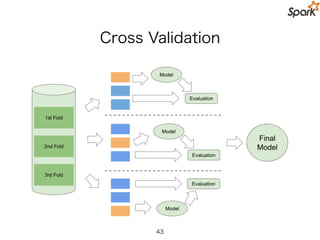
43.
Practical Spark MLPipeline API
val paramGrid = new ParamGridBuilder()
.addGrid(hashingTF.numFeatures, Array(10, 20, 40))
.addGrid(lr.regParam, Array(0.01, 0.1, 0.5))
.build()
val cv = new CrossValidator()
.setNumFolds(3)
.setEstimator(pipeline)
.setEstimatorParamMaps(paramGrid)
.setEvaluator(new BinaryClassificationEvaluator)
val cvModel = cv.fit(trainingDataset)
43
Parameter Tuning も Cross-Validation も
API が用意されているので複雑な PIpeline も簡単に定義
44.
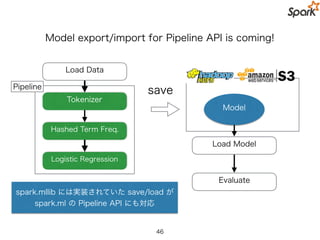
Model export/import forPipeline API is coming soon!
44
Pipeline
Load Data
Hashed Term Freq.
Logistic Regression
Tokenizer
save
Model
Load Model
Evaluate
モデルを保存することで
再構築の必要がなく再利用が簡単








![MLlib-specific Contribution Guidelines
• Be widely known
• Be used and accepted
• academic citations and concrete use cases can help justify this
• Be highly scalable
• Be well documented
• Have APIs consistent with other algorithms in MLLib that
accomplish the same thing
• Come with a reasonable expectation of developer support.
11
[https://cwiki.apache.org/confluence/display/SPARK/Contributing+to+Spark]](https://image.slidesharecdn.com/2015-11-17sparkmllib-151116005454-lva1-app6891/85/2015-11-17-Apache-Spark-11-320.jpg)









![Feature Extraction
• Data Schema
• label: Int
• text: String
• words: Seq[String]
• features: Vector
29
Load Data
Hashed Term Freq.
Train Model
Evaluate
Tokenizer
Transformer](https://image.slidesharecdn.com/2015-11-17sparkmllib-151116005454-lva1-app6891/85/2015-11-17-Apache-Spark-29-320.jpg)
![Train a Model
• Data Schema
• label: Int
• text: String
• words: Seq[String]
• features: Vector
• prediction: Int
30
Load Data
Hashed Term Freq.
Logistic Regression
Evaluate
Tokenizer
Transformer
Estimator](https://image.slidesharecdn.com/2015-11-17sparkmllib-151116005454-lva1-app6891/85/2015-11-17-Apache-Spark-30-320.jpg)























































![[Oracle big data jam session #1] Apache Spark ことはじめ](https://cdn.slidesharecdn.com/ss_thumbnails/oraclebigdatajamsession1apachesparkquickstart-191127094941-thumbnail.jpg?width=640&height=640&fit=bounds)





















