Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Yohei Azekatsu
PPTX, PDF
3,471 views
Parquetはカラムナなのか?
Presto は Parquet ファイルにカラムナなIOをしているか調べてみたメモ。
Technology
◦
Read more
7
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 47
2
/ 47
3
/ 47
4
/ 47
5
/ 47
Most read
6
/ 47
7
/ 47
8
/ 47
9
/ 47
10
/ 47
11
/ 47
12
/ 47
13
/ 47
14
/ 47
15
/ 47
16
/ 47
17
/ 47
18
/ 47
19
/ 47
20
/ 47
21
/ 47
22
/ 47
23
/ 47
24
/ 47
25
/ 47
26
/ 47
27
/ 47
28
/ 47
29
/ 47
30
/ 47
31
/ 47
32
/ 47
33
/ 47
34
/ 47
35
/ 47
36
/ 47
37
/ 47
38
/ 47
39
/ 47
40
/ 47
41
/ 47
42
/ 47
43
/ 47
44
/ 47
45
/ 47
46
/ 47
47
/ 47
More Related Content
PDF
[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス
by
Amazon Web Services Japan
PDF
Spring Boot の Web アプリケーションを Docker に載せて AWS ECS で動かしている話
by
JustSystems Corporation
PPTX
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
PDF
PFNのML/DL基盤を支えるKubernetesにおける自動化 / DevOpsDays Tokyo 2021
by
Preferred Networks
PDF
Amazon Redshift パフォーマンスチューニングテクニックと最新アップデート
by
Amazon Web Services Japan
PDF
Apache Arrow - データ処理ツールの次世代プラットフォーム
by
Kouhei Sutou
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PPTX
Apache Spark 2.4 and 3.0 What's Next?
by
NTT DATA Technology & Innovation
[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス
by
Amazon Web Services Japan
Spring Boot の Web アプリケーションを Docker に載せて AWS ECS で動かしている話
by
JustSystems Corporation
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料)
by
NTT DATA Technology & Innovation
PFNのML/DL基盤を支えるKubernetesにおける自動化 / DevOpsDays Tokyo 2021
by
Preferred Networks
Amazon Redshift パフォーマンスチューニングテクニックと最新アップデート
by
Amazon Web Services Japan
Apache Arrow - データ処理ツールの次世代プラットフォーム
by
Kouhei Sutou
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
Apache Spark 2.4 and 3.0 What's Next?
by
NTT DATA Technology & Innovation
What's hot
PPTX
はじめてのElasticsearchクラスタ
by
Satoyuki Tsukano
PPTX
分析指向データレイク実現の次の一手 ~Delta Lake、なにそれおいしいの?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PDF
Kinesis + Elasticsearchでつくるさいきょうのログ分析基盤
by
Amazon Web Services Japan
PDF
[AWS EXpert Online for JAWS-UG 18] 見せてやるよ、Step Functions の本気ってやつをな
by
Amazon Web Services Japan
PDF
PostgreSQLレプリケーション10周年!徹底紹介!(PostgreSQL Conference Japan 2019講演資料)
by
NTT DATA Technology & Innovation
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
PDF
IoT時代におけるストリームデータ処理と急成長の Apache Flink
by
Takanori Suzuki
PDF
PostgreSQL: XID周回問題に潜む別の問題
by
NTT DATA OSS Professional Services
PDF
AWSにおけるバッチ処理の ベストプラクティス - Developers.IO Meetup 05
by
都元ダイスケ Miyamoto
PPTX
AWSで作る分析基盤
by
Yu Otsubo
PPTX
分散システムについて語らせてくれ
by
Kumazaki Hiroki
PDF
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
PDF
SQL大量発行処理をいかにして高速化するか
by
Shogo Wakayama
PDF
20200617 AWS Black Belt Online Seminar Amazon Athena
by
Amazon Web Services Japan
PPTX
PostgreSQL 12は ここがスゴイ! ~性能改善やpluggable storage engineなどの新機能を徹底解説~ (NTTデータ テクノ...
by
NTT DATA Technology & Innovation
PPT
Cassandraのしくみ データの読み書き編
by
Yuki Morishita
PDF
Marp Tutorial
by
Rui Watanabe
PPTX
トランザクションの設計と進化
by
Kumazaki Hiroki
PPTX
大規模データ活用向けストレージレイヤソフトのこれまでとこれから(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019/09/05)
by
NTT DATA Technology & Innovation
PDF
AWS Black Belt Techシリーズ Amazon Redshift
by
Amazon Web Services Japan
はじめてのElasticsearchクラスタ
by
Satoyuki Tsukano
分析指向データレイク実現の次の一手 ~Delta Lake、なにそれおいしいの?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
Kinesis + Elasticsearchでつくるさいきょうのログ分析基盤
by
Amazon Web Services Japan
[AWS EXpert Online for JAWS-UG 18] 見せてやるよ、Step Functions の本気ってやつをな
by
Amazon Web Services Japan
PostgreSQLレプリケーション10周年!徹底紹介!(PostgreSQL Conference Japan 2019講演資料)
by
NTT DATA Technology & Innovation
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
IoT時代におけるストリームデータ処理と急成長の Apache Flink
by
Takanori Suzuki
PostgreSQL: XID周回問題に潜む別の問題
by
NTT DATA OSS Professional Services
AWSにおけるバッチ処理の ベストプラクティス - Developers.IO Meetup 05
by
都元ダイスケ Miyamoto
AWSで作る分析基盤
by
Yu Otsubo
分散システムについて語らせてくれ
by
Kumazaki Hiroki
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
SQL大量発行処理をいかにして高速化するか
by
Shogo Wakayama
20200617 AWS Black Belt Online Seminar Amazon Athena
by
Amazon Web Services Japan
PostgreSQL 12は ここがスゴイ! ~性能改善やpluggable storage engineなどの新機能を徹底解説~ (NTTデータ テクノ...
by
NTT DATA Technology & Innovation
Cassandraのしくみ データの読み書き編
by
Yuki Morishita
Marp Tutorial
by
Rui Watanabe
トランザクションの設計と進化
by
Kumazaki Hiroki
大規模データ活用向けストレージレイヤソフトのこれまでとこれから(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019/09/05)
by
NTT DATA Technology & Innovation
AWS Black Belt Techシリーズ Amazon Redshift
by
Amazon Web Services Japan
Similar to Parquetはカラムナなのか?
PDF
AWS で Presto を徹底的に使いこなすワザ
by
Noritaka Sekiyama
PDF
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
PDF
Presto on YARNの導入・運用
by
cyberagent
PDF
Prestoで実現するインタラクティブクエリ - dbtech showcase 2014 Tokyo
by
Treasure Data, Inc.
PDF
僕とヤフーと時々Teradata #prestodb
by
Yahoo!デベロッパーネットワーク
PDF
Kyoto Tycoon Guide in Japanese
by
Mikio Hirabayashi
PDF
Yahoo! JAPANにおけるApache Cassandraへの取り組み
by
Yahoo!デベロッパーネットワーク
PDF
最新版Hadoopクラスタを運用して得られたもの
by
cyberagent
PDF
人気番組との戦い! Javaシステムのパフォーマンスチューニング奮闘記
by
心 谷本
PDF
DeNAインフラの今とこれから - 今編 -
by
Tomoya Kabe
PDF
141030ceph
by
OSSラボ株式会社
PDF
Fluentdでログを集めてGlusterFSに保存してMapReduceで集計
by
maebashi
PPTX
Hadoopソースコードリーディング8/MapRを使ってみた
by
Recruit Technologies
PDF
20120117 13 meister-elasti_cache-public
by
Amazon Web Services Japan
PPTX
DeNA private cloud のその後 - OpenStack最新情報セミナー(2017年3月)
by
VirtualTech Japan Inc.
PDF
CouchDB JP & BigCouch
by
Yohei Sasaki
PDF
We Should Know About in this SocialNetwork Era 2011_1112
by
Masahito Zembutsu
PDF
Guide to Cassandra for Production Deployments
by
smdkk
PDF
Lars George HBase Seminar with O'REILLY Oct.12 2012
by
Cloudera Japan
PDF
Hadoop operation chaper 4
by
Yukinori Suda
AWS で Presto を徹底的に使いこなすワザ
by
Noritaka Sekiyama
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
Presto on YARNの導入・運用
by
cyberagent
Prestoで実現するインタラクティブクエリ - dbtech showcase 2014 Tokyo
by
Treasure Data, Inc.
僕とヤフーと時々Teradata #prestodb
by
Yahoo!デベロッパーネットワーク
Kyoto Tycoon Guide in Japanese
by
Mikio Hirabayashi
Yahoo! JAPANにおけるApache Cassandraへの取り組み
by
Yahoo!デベロッパーネットワーク
最新版Hadoopクラスタを運用して得られたもの
by
cyberagent
人気番組との戦い! Javaシステムのパフォーマンスチューニング奮闘記
by
心 谷本
DeNAインフラの今とこれから - 今編 -
by
Tomoya Kabe
141030ceph
by
OSSラボ株式会社
Fluentdでログを集めてGlusterFSに保存してMapReduceで集計
by
maebashi
Hadoopソースコードリーディング8/MapRを使ってみた
by
Recruit Technologies
20120117 13 meister-elasti_cache-public
by
Amazon Web Services Japan
DeNA private cloud のその後 - OpenStack最新情報セミナー(2017年3月)
by
VirtualTech Japan Inc.
CouchDB JP & BigCouch
by
Yohei Sasaki
We Should Know About in this SocialNetwork Era 2011_1112
by
Masahito Zembutsu
Guide to Cassandra for Production Deployments
by
smdkk
Lars George HBase Seminar with O'REILLY Oct.12 2012
by
Cloudera Japan
Hadoop operation chaper 4
by
Yukinori Suda
More from Yohei Azekatsu
PDF
シンプルでシステマチックな Linux 性能分析方法
by
Yohei Azekatsu
PDF
シンプルでシステマチックな Oracle Database, Exadata 性能分析
by
Yohei Azekatsu
PDF
簡単!AWRをEXCELピボットグラフで分析しよう♪
by
Yohei Azekatsu
PPTX
Linux Performance Analysis in 15 minutes
by
Yohei Azekatsu
PPTX
CloudTrail ログの検索を爆速化してみた
by
Yohei Azekatsu
PDF
iostatの見方
by
Yohei Azekatsu
PPTX
SIGMOD 2022 Amazon Redshift Re-invented を読んで
by
Yohei Azekatsu
PPTX
Using Lightweight Formal Methods to Validate a Key-Value Storage Node in Amaz...
by
Yohei Azekatsu
PPTX
Linux Process Snapper Introduction
by
Yohei Azekatsu
PPTX
私がPerlを使う理由
by
Yohei Azekatsu
PPTX
Dbts2012 unconference wttrw_yazekatsu_publish
by
Yohei Azekatsu
シンプルでシステマチックな Linux 性能分析方法
by
Yohei Azekatsu
シンプルでシステマチックな Oracle Database, Exadata 性能分析
by
Yohei Azekatsu
簡単!AWRをEXCELピボットグラフで分析しよう♪
by
Yohei Azekatsu
Linux Performance Analysis in 15 minutes
by
Yohei Azekatsu
CloudTrail ログの検索を爆速化してみた
by
Yohei Azekatsu
iostatの見方
by
Yohei Azekatsu
SIGMOD 2022 Amazon Redshift Re-invented を読んで
by
Yohei Azekatsu
Using Lightweight Formal Methods to Validate a Key-Value Storage Node in Amaz...
by
Yohei Azekatsu
Linux Process Snapper Introduction
by
Yohei Azekatsu
私がPerlを使う理由
by
Yohei Azekatsu
Dbts2012 unconference wttrw_yazekatsu_publish
by
Yohei Azekatsu
Recently uploaded
PDF
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
PPTX
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
PDF
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
PDF
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
Parquetはカラムナなのか?
1.
Parquet はカラムナなのか? Yohei Azekatsu Twitter:
@yoheia Dec, 2019
2.
アジェンダ • お話すること • クイズ •
カラムナフォーマット Parquet とは • Presto は Parquet をどのように読むか • Presto on EMR で検証してみた • まとめ • Appendix
3.
お話すること • Athena や
Presto on EMR で Parquet にクエリすると、必要なカラムの データだけを読んでいるか調べてみた。 • 検証手順はブログで公開しています。 https://yohei-a.hatenablog.jp/entry/20191208/1575766148 出典: https://prestodb.io/overview.html https://www.slideshare.net/julienledem/strata-ny-2017-parquet-arrow-roadmap/13
4.
クイズ
5.
どのクエリが一番速いでしょう? • Athena や
Presto で以下のクエリを実行すると、どれが一番速いでしょう? • データは S3や HDFS にある parquet ファイル。 1. select count(*) from amazon_reviews_parquet; 2. select count(product_title) from amazon_reviews_parquet; 3. select count(review_body) from amazon_reviews_parquet; 使用したデータ: https://registry.opendata.aws/amazon-reviews/
6.
答え(Athena) 使用したデータ: https://registry.opendata.aws/amazon-reviews/ # クエリ
実行時間 スキャンサイズ 1 select count(*) from amazon_reviews_parquet 6.28秒 0B 2 select count(product_title) from amazon_reviews_parquet 13.77秒 5.27GB 3 select count(review_body) from amazon_reviews_parquet 30.39秒 34GB • count(*) が最もスキャンサイズが小さく速い。 • カラム長が最も長い review_body が最もスキャンサイズが大きく遅い。 AWSマネジメントコンソールのAthenaの履歴タブ
7.
答え(Presto on EMR) 使用したデータ:
https://registry.opendata.aws/amazon-reviews/ # クエリ 実行時間 スキャンサイズ 1 select count(*) from amazon_reviews_parquet 8秒 0B 2 select count(product_title) from amazon_reviews_parquet 9秒 5.27GB 3 select count(review_body) from amazon_reviews_parquet 17秒 34GB • 順位とスキャンサイズは Athena と同じ。
8.
カラムナフォーマット Parquet とは
9.
カラムナ(列指向)とは? 出典: https://speakerdeck.com/chie8842/karamunahuomatutofalsekihon-2?slide=9
10.
列指向フォーマット 出典: https://speakerdeck.com/chie8842/karamunahuomatutofalsekihon-2?slide=10
11.
Parquet 出典: https://speakerdeck.com/chie8842/karamunahuomatutofalsekihon-2?slide=12
12.
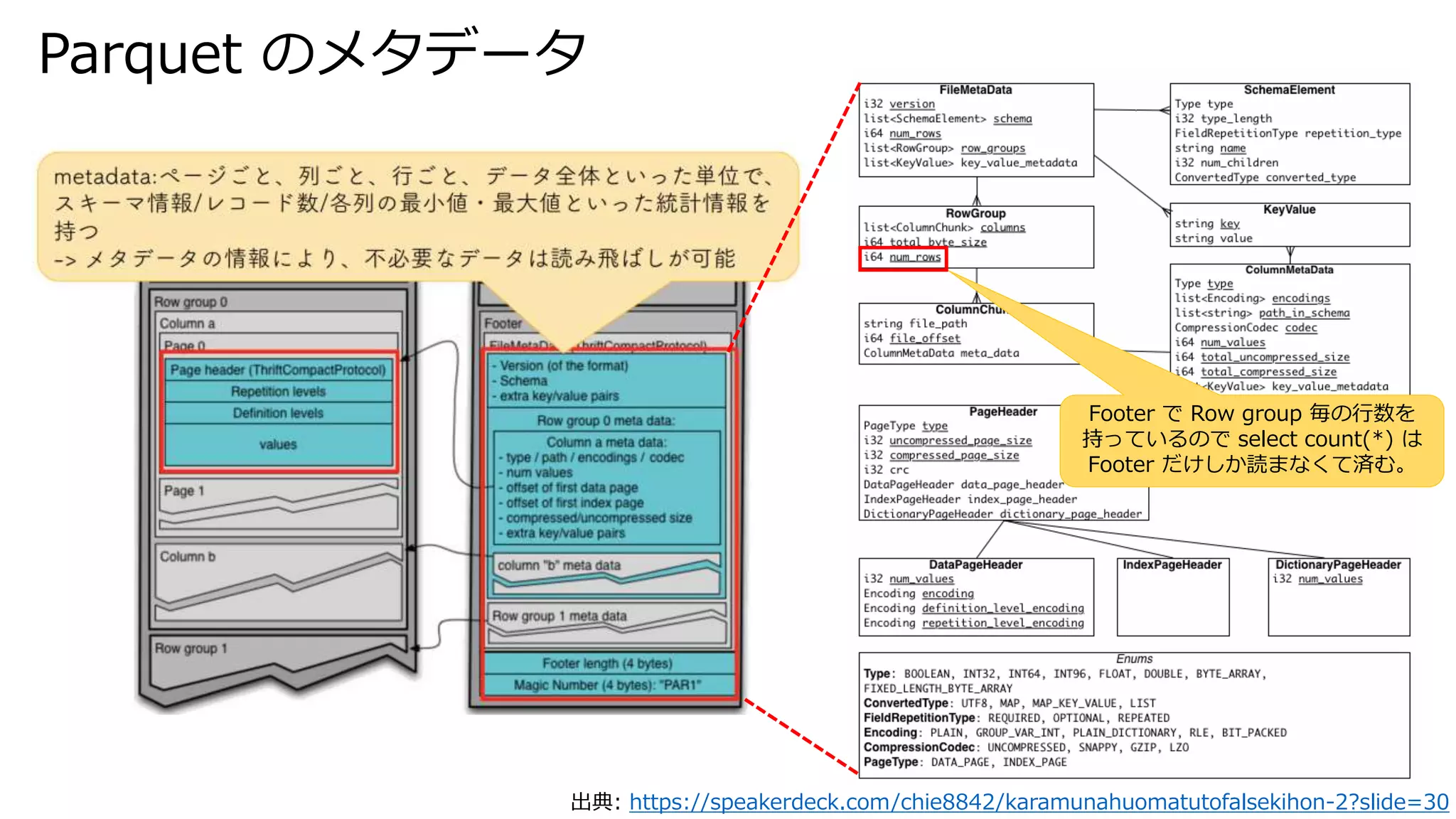
Parquet のファイルフォーマット 出典: https://speakerdeck.com/chie8842/karamunahuomatutofalsekihon-2?slide=30
13.
Parquet のメタデータ 出典: https://speakerdeck.com/chie8842/karamunahuomatutofalsekihon-2?slide=30 Footer
で Row group 毎の行数を 持っているので select count(*) は Footer だけしか読まなくて済む。
14.
ファイルの中から必要なデータのみ読むことができる 出典: https://www.slideshare.net/julienledem/strata-ny-2017-parquet-arrow-roadmap/13 ほんと?
15.
Presto は Parquet
をどのように読むか
16.
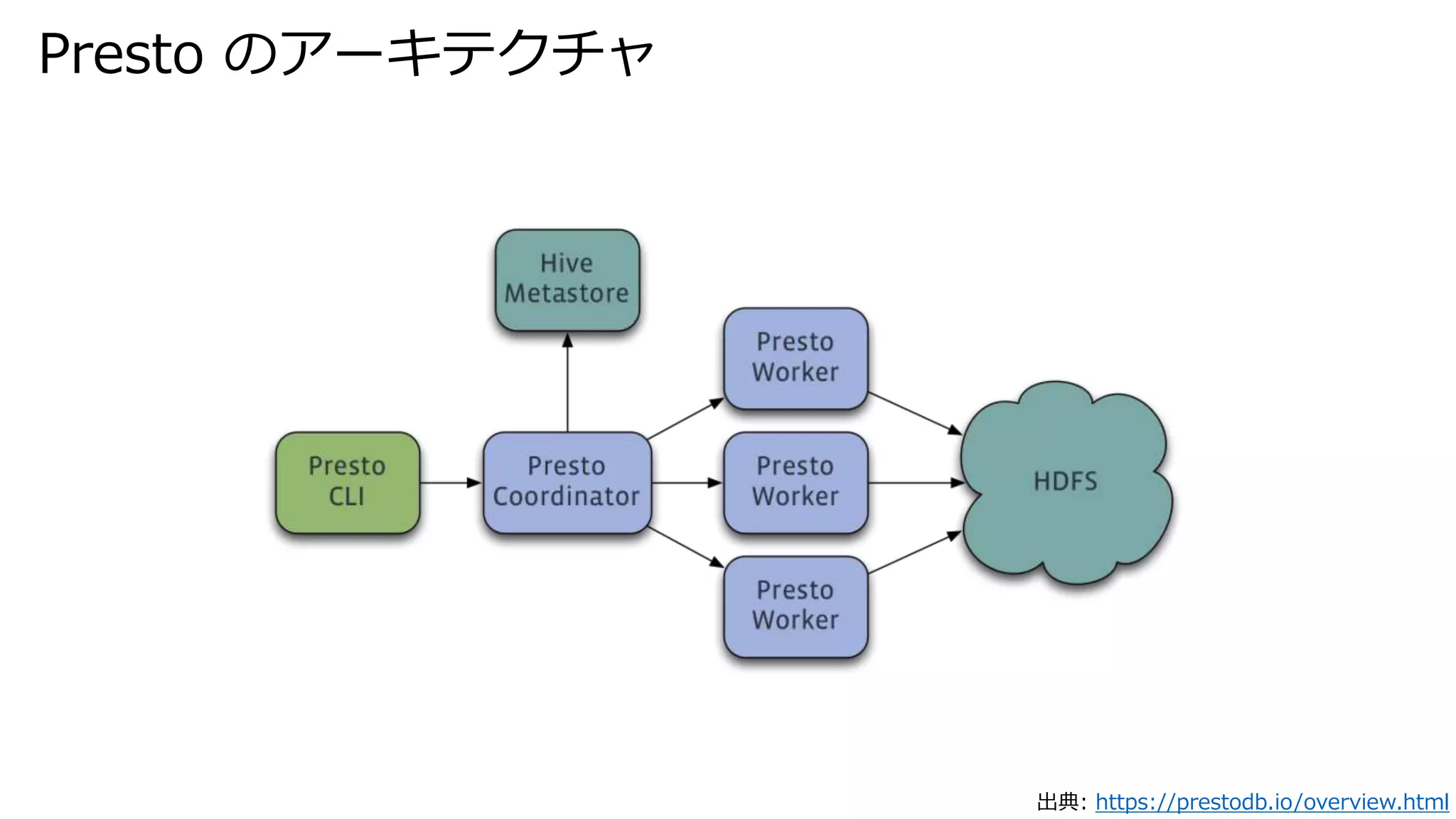
Presto のアーキテクチャ 出典: https://prestodb.io/overview.html
17.
Original open source
Parquet reader 出典: https://eng.uber.com/presto/ • オリジナルの OSS の Presto の Parquet reader は全カラムを読んでいた。
18.
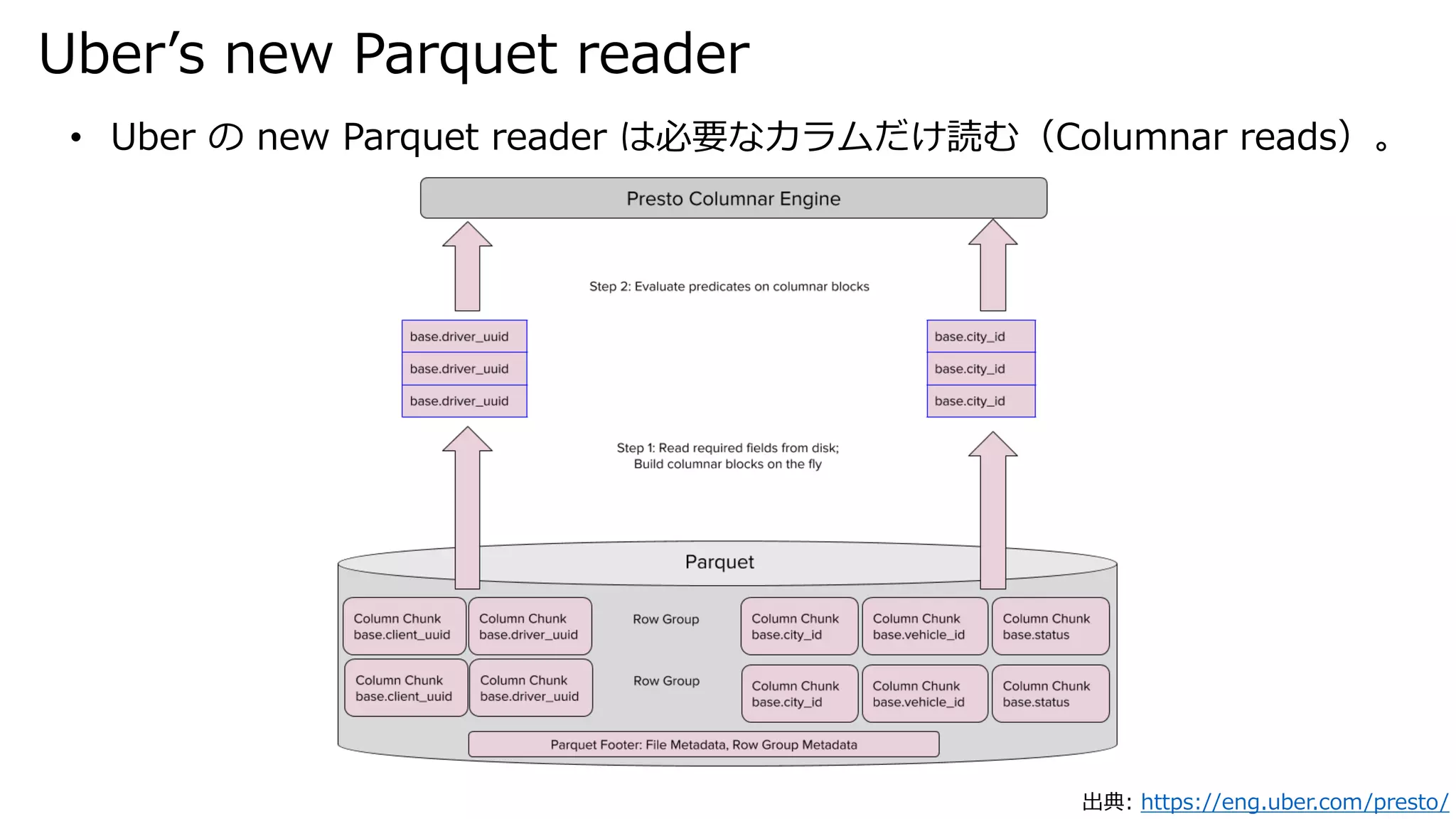
Uber’s new Parquet
reader 出典: https://eng.uber.com/presto/ • Uber の new Parquet reader は必要なカラムだけ読む(Columnar reads)。
19.
New reader demonstrated
2-10X speedup 出典: https://eng.uber.com/presto/ • Uber の new Parquet reader は必要なカラムだけ読むから。 Figure 10: Our new reader demonstrated 2- 10X speedup for Uber’s benchmark SQL queries.
20.
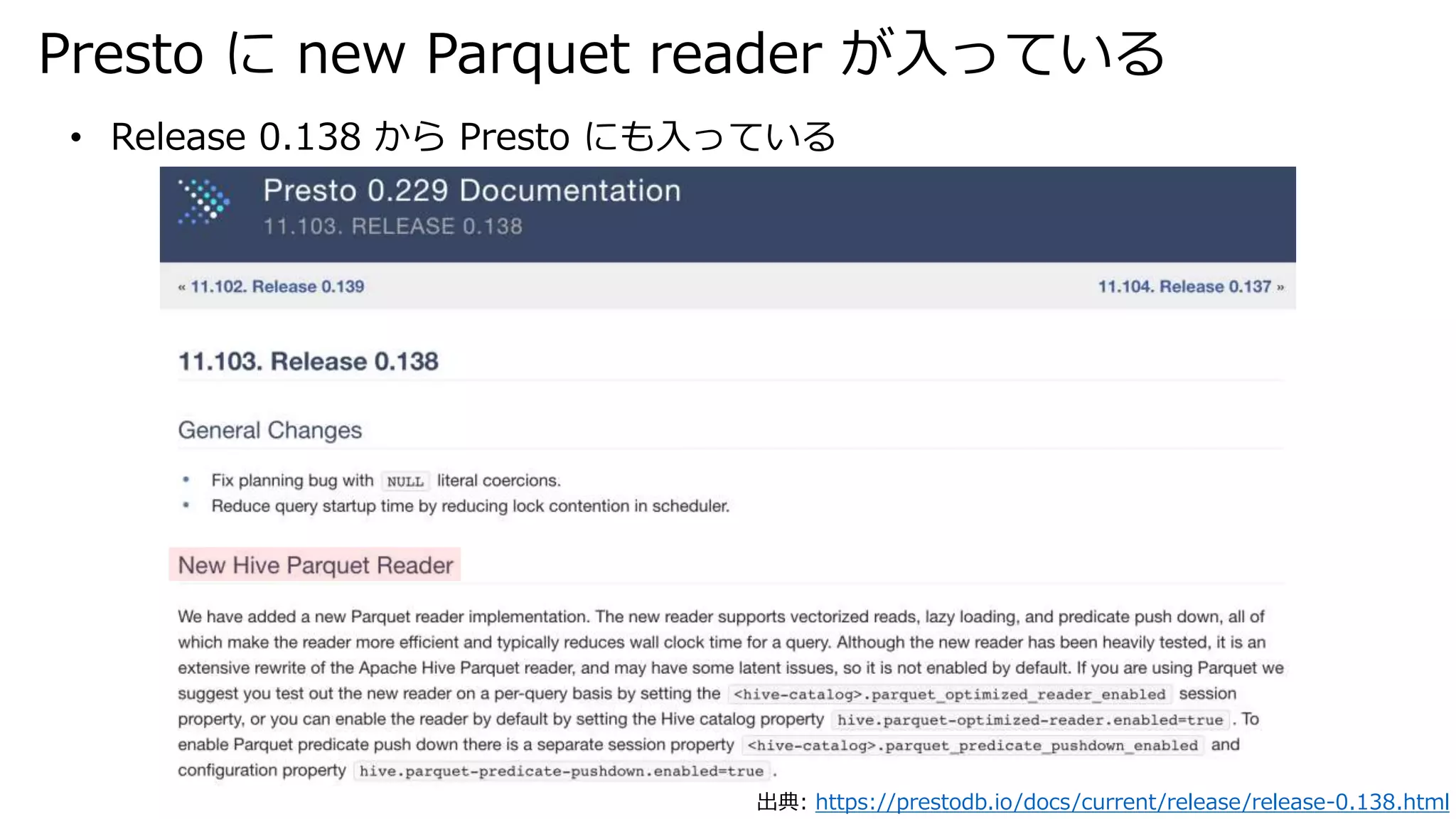
Presto に new
Parquet reader が入っている 出典: https://prestodb.io/docs/current/release/release-0.138.html • Release 0.138 から Presto にも入っている
21.
Presto のソースコード 出典: https://prestodb.io/docs/current/release/release-0.138.html •
Release 0.137 https://github.com/prestodb/presto/releases/tag/0.137 https://github.com/prestodb/presto/tree/73d6484905b0813d0e20ea71478136547913764a/presto- hive/src/main/java/com/facebook/presto/hive/parquet/reader • Release 0.138(New Hive Parquet Reader が入った) https://github.com/prestodb/presto/releases/tag/0.138 https://github.com/prestodb/presto/tree/10b581a53608c7657385cc7d49b8e699ee38ddb0/presto- hive/src/main/java/com/facebook/presto/hive/parquet/reader
22.
Presto on EMR
で検証してみた
23.
クエリを実行してみる presto:parquet> select count(review_body)
from amazon_reviews_parquet; _col0 ----------- 160789772 (1 row) Query 20191214_131823_00001_7rzxe, FINISHED, 1 node Splits: 1,137 total, 1,137 done (100.00%) 0:19 [161M rows, 34GB] [8.43M rows/s, 1.78GB/s] presto:parquet> select count(*) from amazon_reviews_parquet; _col0 ----------- 160796570 (1 row) Query 20191214_132223_00002_7rzxe, FINISHED, 1 node Splits: 1,136 total, 1,136 done (100.00%) 0:07 [161M rows, 0B] [21.5M rows/s, 0B/s]
24.
Presto Web UI http://master-public-dns-name:8889/ >
select count(review_body) from … > select count(*) from … 34GB 0B
25.
コールスタックを見ると
26.
Flame Graph: select
count(review_body) … HDFS の sun.nio.ch.FileChannelImpl:::transferTo から sendfile システムコールが呼ばれている ス タ ッ ク の 深 さ 関数名で左から右にソート(アルファベット順) 一番上がスタックが最も深く、横幅が 長いほど長時間CPUを使っている
27.
Flame Graph: select
count(review_body) … ユ ー ザ ー 空 間 カ ー ネ ル 空 間 sendfile システムコール ファイルシステム(XFS) からフィルを読んで ソケットにデータを 送っている
28.
Flame Graph: select
count(*) … ス タ ッ ク の 深 さ • わりと何もしていない
29.
Perf + Flame
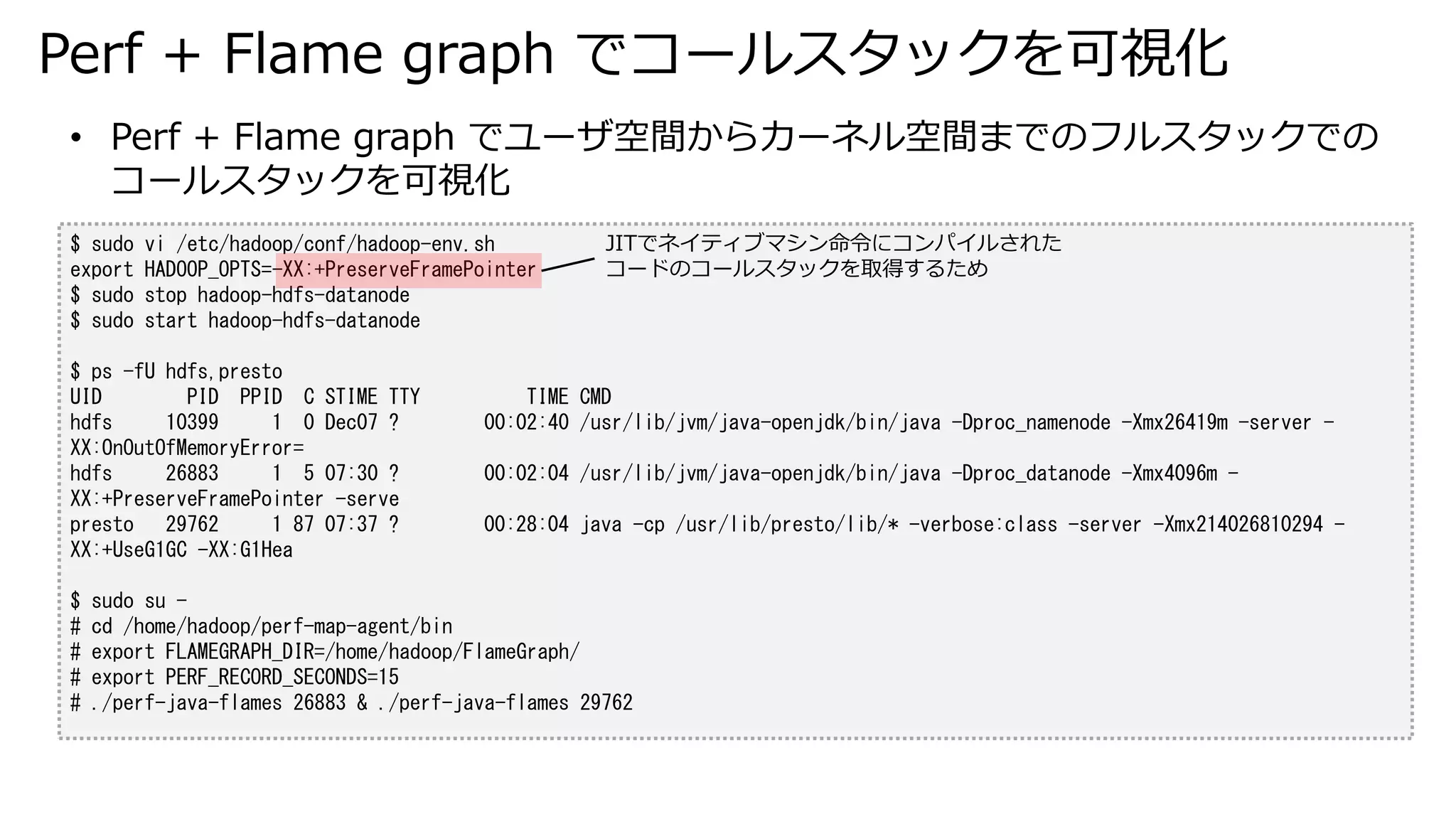
graph でコールスタックを可視化 $ sudo vi /etc/hadoop/conf/hadoop-env.sh export HADOOP_OPTS=-XX:+PreserveFramePointer $ sudo stop hadoop-hdfs-datanode $ sudo start hadoop-hdfs-datanode $ ps -fU hdfs,presto UID PID PPID C STIME TTY TIME CMD hdfs 10399 1 0 Dec07 ? 00:02:40 /usr/lib/jvm/java-openjdk/bin/java -Dproc_namenode -Xmx26419m -server - XX:OnOutOfMemoryError= hdfs 26883 1 5 07:30 ? 00:02:04 /usr/lib/jvm/java-openjdk/bin/java -Dproc_datanode -Xmx4096m - XX:+PreserveFramePointer -serve presto 29762 1 87 07:37 ? 00:28:04 java -cp /usr/lib/presto/lib/* -verbose:class -server -Xmx214026810294 - XX:+UseG1GC -XX:G1Hea $ sudo su - # cd /home/hadoop/perf-map-agent/bin # export FLAMEGRAPH_DIR=/home/hadoop/FlameGraph/ # export PERF_RECORD_SECONDS=15 # ./perf-java-flames 26883 & ./perf-java-flames 29762 • Perf + Flame graph でユーザ空間からカーネル空間までのフルスタックでの コールスタックを可視化 JITでネイティブマシン命令にコンパイルされた コードのコールスタックを取得するため
30.
HDFS の datanode
からのデータ転送 出典: https://issues.apache.org/jira/browse/HDFS-281
31.
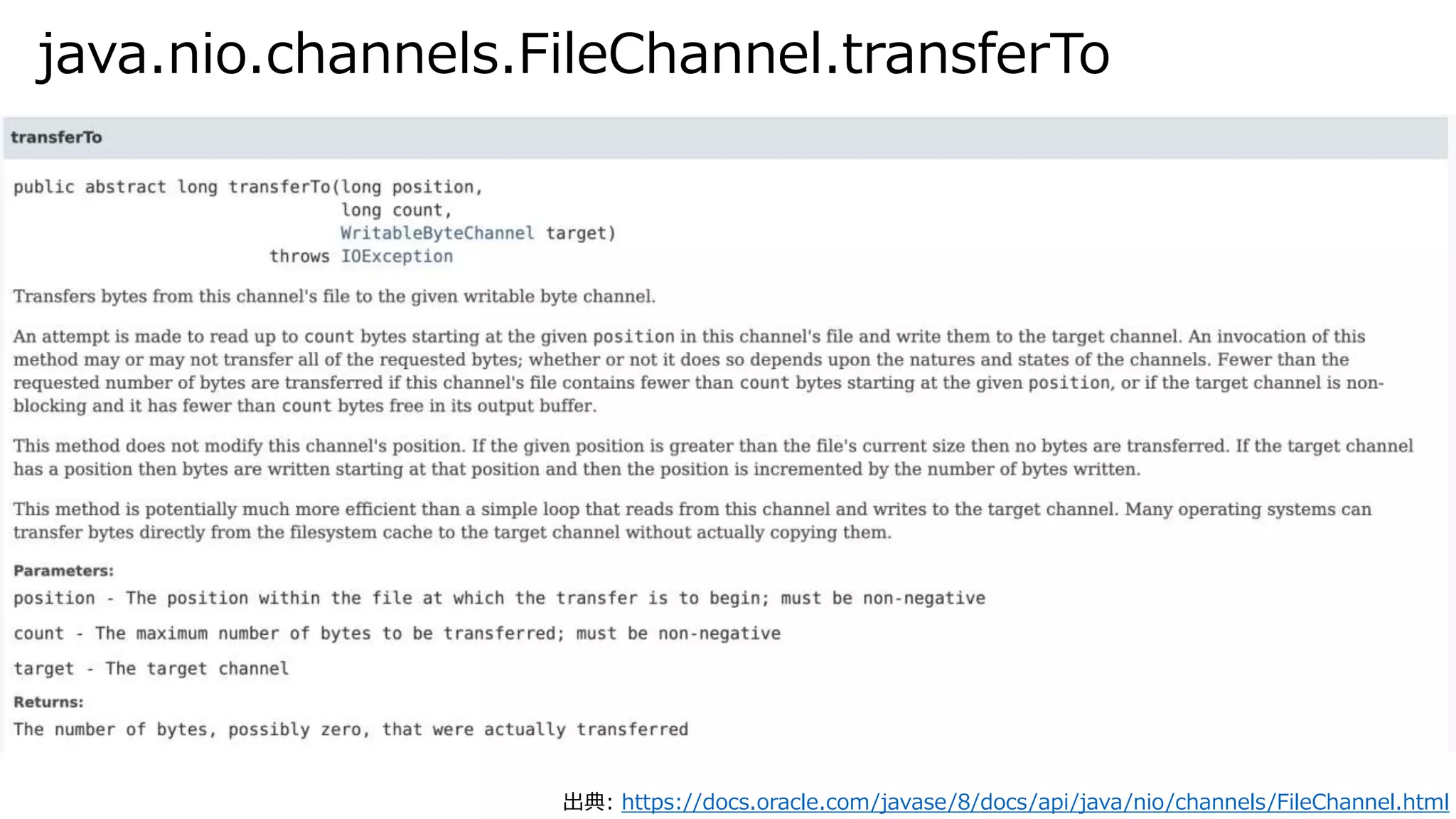
java.nio.channels.FileChannel.transferTo 出典: https://docs.oracle.com/javase/8/docs/api/java/nio/channels/FileChannel.html
32.
sendfile(2) システムコール 出典: http://man7.org/linux/man-pages/man2/sendfile.2.html
33.
strace で HDFS
のシステムコールトレースをとると $ sudo strace -fe sendfile -s 200 -p 10858 3434 sendfile(1003, 993, [68038656], 65536) = 65536 3546 sendfile(984, 1042, [16862208], 65536) = 65536 3438 sendfile(979, 1007, [86496768], 65536) = 65536 3422 sendfile(971, 1032, [101465600], 65536 <unfinished ...> • select count(review_body) from … sendfile システムコールで 64Kbyte(65536 byte) 単位で読んでいる。 $ sudo strace -fe sendfile -s 200 -p 10858 14928 sendfile(1057, 1112, [72695808], 275) = 275 14953 sendfile(1060, 1128, [47949312], 69) = 69 14954 sendfile(1041, 1112, [100519424], 489) = 489 14955 sendfile(1116, 1119, [94451200], 178) = 178 • select count(*) from … sendfile システムコールで読んでいるIOサ イズはバラバラ。
34.
システムコールレイヤーでのIOサイズとIO量 • strace で
sendfile(2) のシステムコールトレースを取得し、可視化すると、 IOサイズとIO量に差がある。 0 50,000 100,000 150,000 200,000 250,000 300,000 350,000 400,000 450,000 500,000 65536 165 177 279 24576 382 288 240 513 505 回数 IOサイズ 0 5 10 15 20 25 165 279 177 382 288 240 513 505 29861 29689 回数 IOサイズ > select count(review_body) from … > select count(*) from … $ perl -lane '$F[1]=~/^sendfile/ and ($s)=$F[4]=~/^(d+)/ and print $s' strace_hdfs_review_body.log|sort|uniq -c|sort -r|head -10
35.
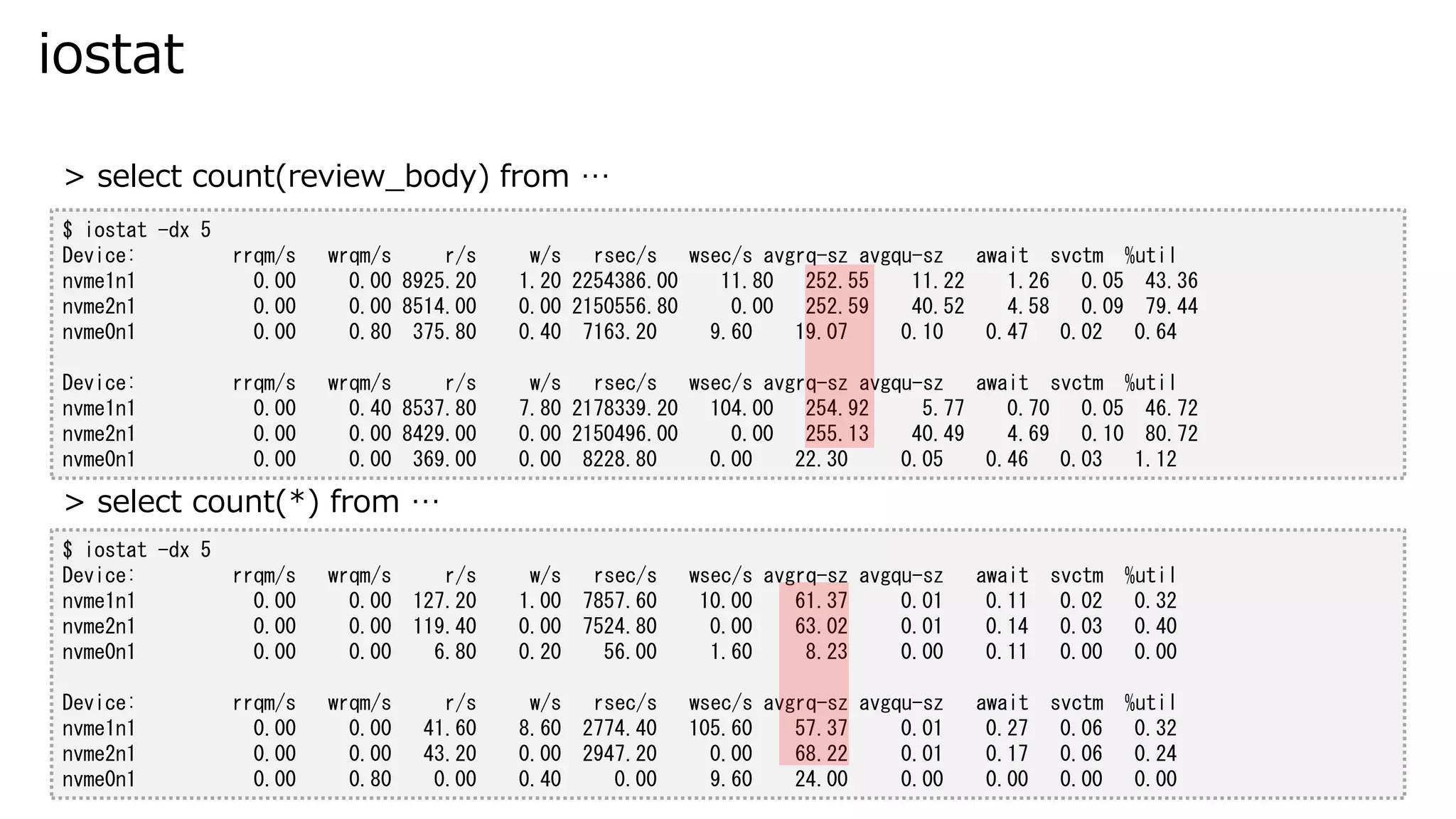
iostat $ iostat -dx
5 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util nvme1n1 0.00 0.00 8925.20 1.20 2254386.00 11.80 252.55 11.22 1.26 0.05 43.36 nvme2n1 0.00 0.00 8514.00 0.00 2150556.80 0.00 252.59 40.52 4.58 0.09 79.44 nvme0n1 0.00 0.80 375.80 0.40 7163.20 9.60 19.07 0.10 0.47 0.02 0.64 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util nvme1n1 0.00 0.40 8537.80 7.80 2178339.20 104.00 254.92 5.77 0.70 0.05 46.72 nvme2n1 0.00 0.00 8429.00 0.00 2150496.00 0.00 255.13 40.49 4.69 0.10 80.72 nvme0n1 0.00 0.00 369.00 0.00 8228.80 0.00 22.30 0.05 0.46 0.03 1.12 $ iostat -dx 5 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util nvme1n1 0.00 0.00 127.20 1.00 7857.60 10.00 61.37 0.01 0.11 0.02 0.32 nvme2n1 0.00 0.00 119.40 0.00 7524.80 0.00 63.02 0.01 0.14 0.03 0.40 nvme0n1 0.00 0.00 6.80 0.20 56.00 1.60 8.23 0.00 0.11 0.00 0.00 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util nvme1n1 0.00 0.00 41.60 8.60 2774.40 105.60 57.37 0.01 0.27 0.06 0.32 nvme2n1 0.00 0.00 43.20 0.00 2947.20 0.00 68.22 0.01 0.17 0.06 0.24 nvme0n1 0.00 0.80 0.00 0.40 0.00 9.60 24.00 0.00 0.00 0.00 0.00 > select count(review_body) from … > select count(*) from …
36.
CloudWatchメトリクス: IOPS • “select
count(review_body) from …” 実行時は約 5,7000 IOPS 57,000 IOPS
37.
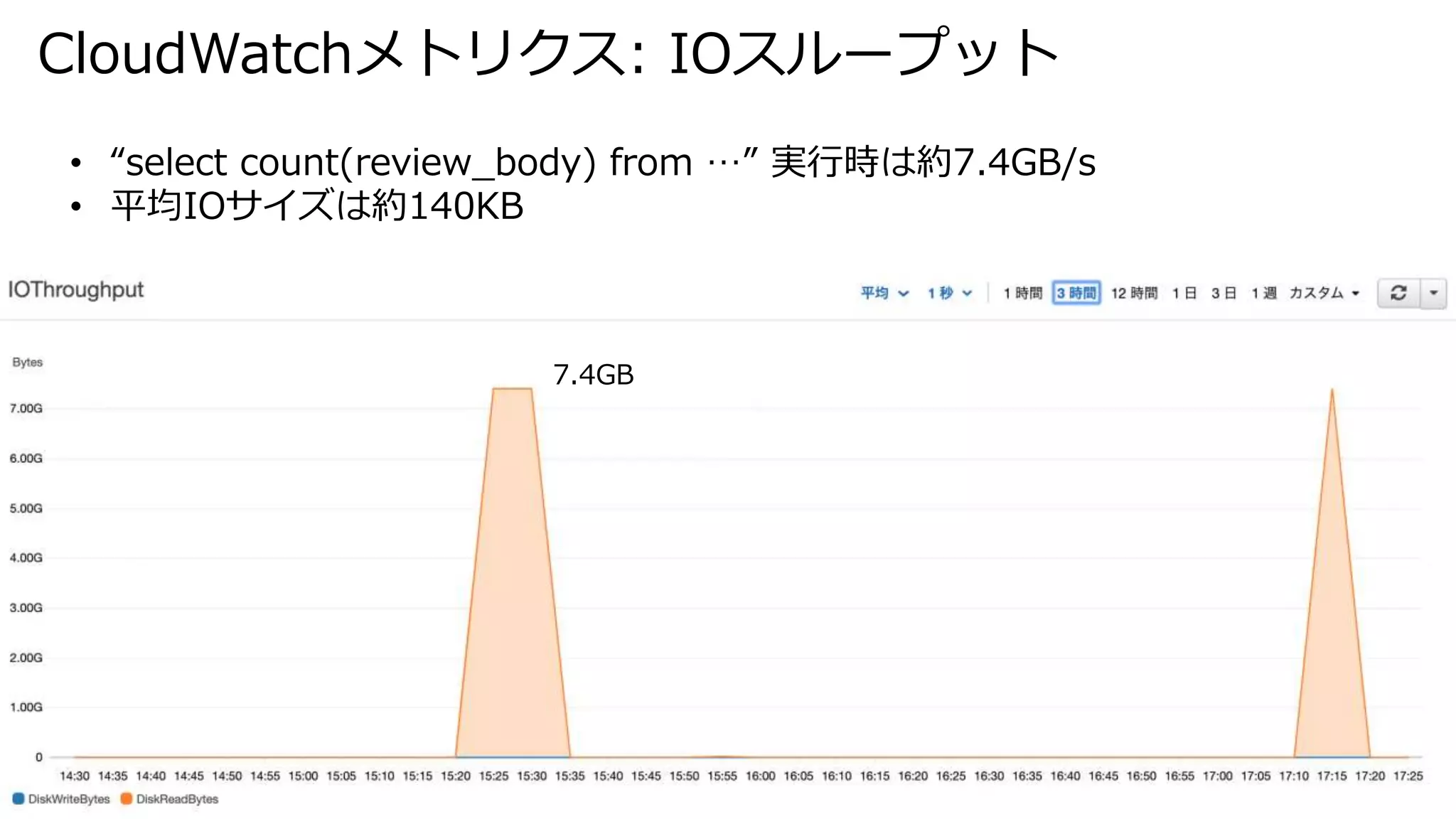
CloudWatchメトリクス: IOスループット • “select
count(review_body) from …” 実行時は約7.4GB/s • 平均IOサイズは約140KB 7.4GB
38.
カーネルブロックレイヤーでのIOサイズとIO量 > select count(review_body)
from … > select count(*) from … • blktrace でカーネルのブロックレイヤーでトレースして可視化すると、IOサ イズとIO量に差がある。
39.
まとめ • Athena や
Presto on EMR(Release 0.138 以降) で parquet にクエリす ると、必要なカラムのみディスクやストレージから読んでいる。 presto hdfs 1.snappy.parquet 2.snappy.parquet 3.snappy.parquet HDFS xfs blk_... blk_... blk_... blk_... blk_... blk_... blk_... blk_... blk_... Block Device(/dev/sd*) Parquet Row group Column chunk
40.
Appendix
41.
Appendix.1 検証に使った EMR •
emr-5.28.0 Hadoop ディストリビューション: Amazon 2.8.5 アプリケーション: Hive 2.3.6, Pig 0.17.0, Hue 4.4.0, Presto 0.227, Ganglia 3.7.2 r5d.8xlarge、コア・マスターノードなし
42.
Appendix.2 perf +
Flame graph $ ps -fU hdfs,presto UID PID PPID C STIME TTY TIME CMD hdfs 10399 1 0 Dec07 ? 00:02:40 /usr/lib/jvm/java-openjdk/bin/java -Dproc_namenode -Xmx26419m -server - XX:OnOutOfMemoryError= hdfs 26883 1 5 07:30 ? 00:02:04 /usr/lib/jvm/java-openjdk/bin/java -Dproc_datanode -Xmx4096m - XX:+PreserveFramePointer -serve presto 29762 1 87 07:37 ? 00:28:04 java -cp /usr/lib/presto/lib/* -verbose:class -server -Xmx214026810294 - XX:+UseG1GC -XX:G1Hea $ sudo su - # cd /home/hadoop/perf-map-agent/bin # export FLAMEGRAPH_DIR=/home/hadoop/FlameGraph/ # export PERF_RECORD_SECONDS=15 # ./perf-java-flames 26883 & ./perf-java-flames 29762
43.
Appnedix.3 性能分析ツールのインストール # EMR
マスターノードにログイン $ ssh -i ~/mykeytokyo.pem hadoop@ec2-54-***-**-112.ap-northeast-1.compute.amazonaws.com #各種パッケージのインストール $ sudo yum -y install htop sysstat dstat iotop ltrace strace perf blktrace gnuplot # perf-map-agent のインストール $ sudo yum -y install cmake git $ git clone --depth=1 https://github.com/jrudolph/perf-map-agent $ cd perf-map-agent $ cmake . $ make # FlameGraph のインストール $ git clone https://github.com/brendangregg/FlameGraph $ chmod +x FlameGraph/*.pl $ vi ~/.bashrc $ export FLAMEGRAPH_DIR=~/FlameGraph # sysdig のインストール $ sudo su - # rpm --import https://s3.amazonaws.com/download.draios.com/DRAIOS-GPG-KEY.public # curl -s -o /etc/yum.repos.d/draios.repo https://s3.amazonaws.com/download.draios.com/stable/rpm/draios.repo # rpm -i https://mirror.us.leaseweb.net/epel/6/i386/epel-release-6-8.noarch.rpm # yum -y install kernel-devel-$(uname -r) # yum -y install sysdig
44.
Appnedix.4 JVM のオプションを設定 #
JVM のオプションを設定 $ sudo vi /etc/hadoop/conf/hadoop-env.sh # Extra Java runtime options. Empty by default. export HADOOP_OPTS=-XX:+PreserveFramePointer # HDFS の Datanode を再起動 $ sudo stop hadoop-hdfs-datanode hadoop-hdfs-datanode stop/waiting $ sudo status hadoop-hdfs-datanode hadoop-hdfs-datanode stop/waiting $ sudo start hadoop-hdfs-datanode hadoop-hdfs-datanode start/running, process 27016 # Presto Server を再起動 $ sudo initctl list|grep presto presto-server start/running, process 17624 $ sudo stop presto-server presto-server stop/waiting $ sudo start presto-server presto-server start/running, process 29763
45.
Appendix.5 strace +
perl ワンライナーで加工 $ ps -fU hdfs,presto UID PID PPID C STIME TTY TIME CMD hdfs 10399 1 0 Dec07 ? 00:02:40 /usr/lib/jvm/java-openjdk/bin/java -Dproc_namenode -Xmx26419m -server - XX:OnOutOfMemoryError= hdfs 26883 1 5 07:30 ? 00:02:04 /usr/lib/jvm/java-openjdk/bin/java -Dproc_datanode -Xmx4096m - XX:+PreserveFramePointer -serve presto 29762 1 87 07:37 ? 00:28:04 java -cp /usr/lib/presto/lib/* -verbose:class -server -Xmx214026810294 - XX:+UseG1GC -XX:G1Hea $ sudo strace -fe sendfile -s 200 -o strace_hdfs_review_body.log -p 10858 $ head -3 strace_hdfs_review_body.log 3546 sendfile(984, 1042, [16796672], 65536★ <unfinished ...> 3438 sendfile(979, 1007, [86431232], 65536 <unfinished ...> 3546<... sendfile resumed> ) = 65536 $ perl -lane '$F[1]=~/^sendfile/ and ($s)=$F[4]=~/^(d+)/ and print $s' strace_hdfs_review_body.log|sort|uniq -c|sort -r|head -10 465521 65536 24 165 22 177 21 279 20 382 20 288 20 24576 19 240 18 513 17 505
46.
Appendix.6 blktrace +
btt + gnuplot # blktrace -w 15 -d /dev/nvme1n1p2 -o nvme1n1p2 & blktrace -w 15 -d /dev/nvme2n1 -o nvme2n1 & # ls nvme1n1p2.blktrace.*|while read LINE do btt -i ${LINE} -B ${LINE}.btt done # ls nvme2n1.blktrace.*|while read LINE do btt -i ${LINE} -B ${LINE}.btt Done # cat nvme1n1p2.blktrace.*.btt_*_c.dat > nvme1n1p2_btt_c_all_c.dat # cat nvme2n1.blktrace.*.btt_*_c.dat > nvme2n1_btt_c_all_c.dat # bno_plot.py nvme1n1p2_btt_c_all_c.dat ★/usr/bin/bno_plot.py の”os.system(‘/bin/rm -rf ’ + tmpdir)”をコメントアウト # bno_plot.py nvme2n1_btt_c_all_c.dat # cd /tmp/tmpoSibdI # vi plot.cmd set terminal png ★追記 set output ‘nvme1n1p2_btt_c_all_c.png’ ★追記 set title 'btt Generated Block Accesses' set xlabel 'Time (secs)' set ylabel 'Block Number' set zlabel '# Blocks per IO' set grid splot 'nvme1n1p2_btt_c_all_c.dat' set output ★追記 # gnuplot plot.cmds # ls nvme1n1p2_btt_c_all_c_ast.png nvme1n1p2_btt_c_all_c.dat plot.cmds
47.
Appendix.7 参考情報 • Presto
で Parquet にクエリすると、参照するカラムのみ読んでいることを確認した https://yohei-a.hatenablog.jp/entry/20191208/1575766148 • カラムナフォーマットのきほん 〜データウェアハウスを支える技術〜 https://engineer.retty.me/entry/columnar-storage-format • Strata NY 2017 Parquet Arrow roadmap https://www.slideshare.net/julienledem/strata-ny-2017-parquet-arrow-roadmap • Engineering Data Analytics with Presto and Apache Parquet at Uber https://eng.uber.com/presto/ • Even Faster: When Presto Meets Parquet @ Uber https://events.static.linuxfound.org/sites/events/files/slides/Presto.pdf • blktrace で block IO の分布を可視化する https://blog.etsukata.com/2013/12/blktrace-block-io.html • Java Mixed-Mode Flame Graphs で Java の CPU ネックをフルスタックで分析する https://yohei-a.hatenablog.jp/entry/20160506/1462536427
Editor's Notes
#4
Prestoはfacebookが開発したSQLエンジン HDFSやS3のファイルにSQLで問合せができる AthenaはPrestoのマネージド・サービス
Download



















![クエリを実行してみる
presto:parquet> select count(review_body) from amazon_reviews_parquet;
_col0
-----------
160789772
(1 row)
Query 20191214_131823_00001_7rzxe, FINISHED, 1 node
Splits: 1,137 total, 1,137 done (100.00%)
0:19 [161M rows, 34GB] [8.43M rows/s, 1.78GB/s]
presto:parquet> select count(*) from amazon_reviews_parquet;
_col0
-----------
160796570
(1 row)
Query 20191214_132223_00002_7rzxe, FINISHED, 1 node
Splits: 1,136 total, 1,136 done (100.00%)
0:07 [161M rows, 0B] [21.5M rows/s, 0B/s]](https://image.slidesharecdn.com/parquetcolumnarpresto20191218-191218113920/75/Parquet-23-2048.jpg)







![strace で HDFS のシステムコールトレースをとると
$ sudo strace -fe sendfile -s 200 -p 10858
3434 sendfile(1003, 993, [68038656], 65536) = 65536
3546 sendfile(984, 1042, [16862208], 65536) = 65536
3438 sendfile(979, 1007, [86496768], 65536) = 65536
3422 sendfile(971, 1032, [101465600], 65536 <unfinished ...>
• select count(review_body) from …
sendfile システムコールで
64Kbyte(65536 byte) 単位で読んでいる。
$ sudo strace -fe sendfile -s 200 -p 10858
14928 sendfile(1057, 1112, [72695808], 275) = 275
14953 sendfile(1060, 1128, [47949312], 69) = 69
14954 sendfile(1041, 1112, [100519424], 489) = 489
14955 sendfile(1116, 1119, [94451200], 178) = 178
• select count(*) from … sendfile システムコールで読んでいるIOサ
イズはバラバラ。](https://image.slidesharecdn.com/parquetcolumnarpresto20191218-191218113920/75/Parquet-33-2048.jpg)
![システムコールレイヤーでのIOサイズとIO量
• strace で sendfile(2) のシステムコールトレースを取得し、可視化すると、
IOサイズとIO量に差がある。
0
50,000
100,000
150,000
200,000
250,000
300,000
350,000
400,000
450,000
500,000
65536 165 177 279 24576 382 288 240 513 505
回数
IOサイズ
0
5
10
15
20
25
165 279 177 382 288 240 513 505 29861 29689
回数 IOサイズ
> select count(review_body) from … > select count(*) from …
$ perl -lane '$F[1]=~/^sendfile/ and ($s)=$F[4]=~/^(d+)/ and print $s'
strace_hdfs_review_body.log|sort|uniq -c|sort -r|head -10](https://image.slidesharecdn.com/parquetcolumnarpresto20191218-191218113920/75/Parquet-34-2048.jpg)








![Appendix.5 strace + perl ワンライナーで加工
$ ps -fU hdfs,presto
UID PID PPID C STIME TTY TIME CMD
hdfs 10399 1 0 Dec07 ? 00:02:40 /usr/lib/jvm/java-openjdk/bin/java -Dproc_namenode -Xmx26419m -server -
XX:OnOutOfMemoryError=
hdfs 26883 1 5 07:30 ? 00:02:04 /usr/lib/jvm/java-openjdk/bin/java -Dproc_datanode -Xmx4096m -
XX:+PreserveFramePointer -serve
presto 29762 1 87 07:37 ? 00:28:04 java -cp /usr/lib/presto/lib/* -verbose:class -server -Xmx214026810294 -
XX:+UseG1GC -XX:G1Hea
$ sudo strace -fe sendfile -s 200 -o strace_hdfs_review_body.log -p 10858
$ head -3 strace_hdfs_review_body.log
3546 sendfile(984, 1042, [16796672], 65536★ <unfinished ...>
3438 sendfile(979, 1007, [86431232], 65536 <unfinished ...>
3546<... sendfile resumed> ) = 65536
$ perl -lane '$F[1]=~/^sendfile/ and ($s)=$F[4]=~/^(d+)/ and print $s' strace_hdfs_review_body.log|sort|uniq -c|sort -r|head
-10
465521 65536
24 165
22 177
21 279
20 382
20 288
20 24576
19 240
18 513
17 505](https://image.slidesharecdn.com/parquetcolumnarpresto20191218-191218113920/75/Parquet-45-2048.jpg)


![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)









![[AWS EXpert Online for JAWS-UG 18] 見せてやるよ、Step Functions の本気ってやつをな](https://cdn.slidesharecdn.com/ss_thumbnails/awsxon18howfarstepfunctionsgo-211124111849-thumbnail.jpg?width=640&height=640&fit=bounds)




















































