Download as PDF, PPTX



![Outline
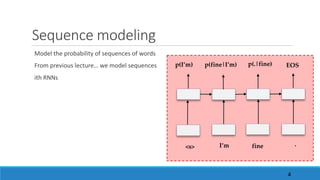
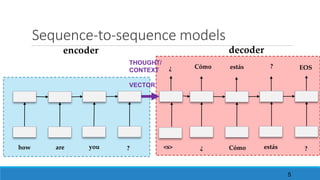
1. Sequence modeling & Sequence-to-sequence models [WRAP-UP FROM PREVIOUS RNN’s SESSION]
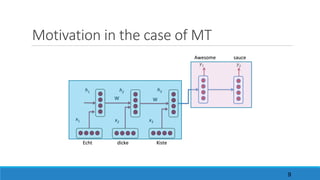
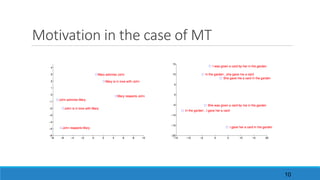
2. Attention-based mechanism
3. Attention varieties
4. Attention Improvements
5. Applications
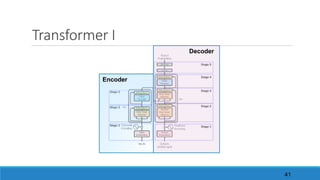
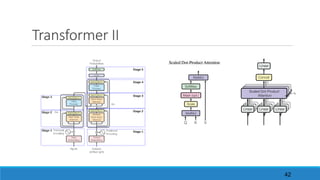
6. “Attention is all you need”
7. Summary
3](https://image.slidesharecdn.com/dlai2017d9lattention-171121141428/85/Attention-based-Models-DLAI-D8L-2017-UPC-Deep-Learning-for-Artificial-Intelligence-3-320.jpg)



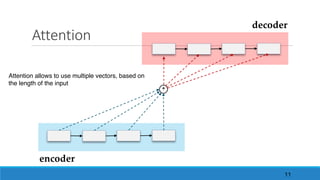

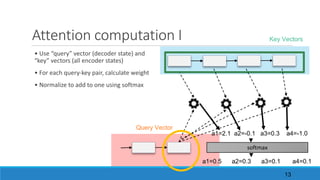
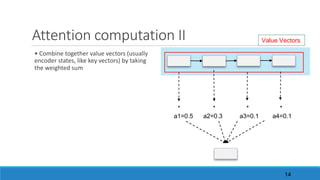


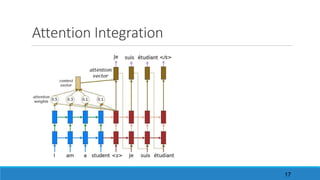























![Quizz
1.Mark all statements that are true
A. Sequence modeling only refers to language applications
B. The attention mechanism can be applied to an encoder-decoder architecture
C. Neural machine translation systems require recurrent neural networks
D. If we want to have a fixed representation (thought vector), we can not apply attention-based
mechanisms
2. Given the query vector q=[], the key vector 1 k1=[] and the key vector 2 k2=[].
A. What are the attention weights 1 & 2 computing the dot product?
B. And when computing the scaled dot product?
C. To what key vector are we giving more attention?
D. What is the advantage of computing the scaled dot product?
52](https://image.slidesharecdn.com/dlai2017d9lattention-171121141428/85/Attention-based-Models-DLAI-D8L-2017-UPC-Deep-Learning-for-Artificial-Intelligence-52-320.jpg)

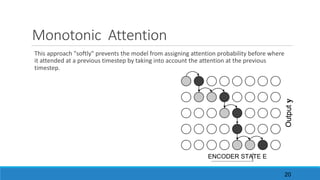
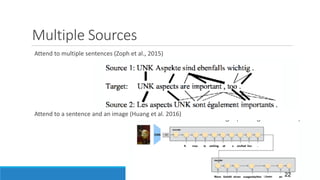
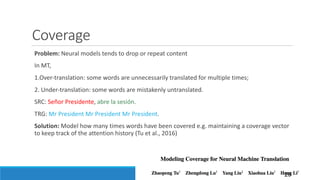
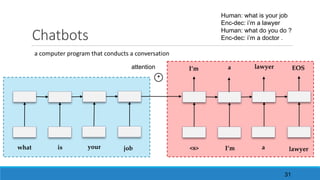
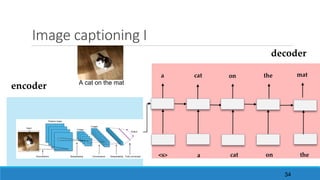
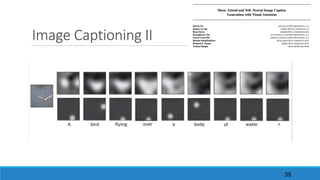
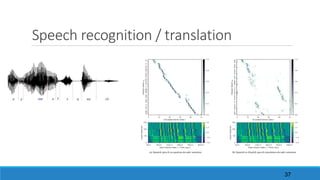
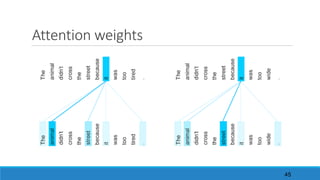
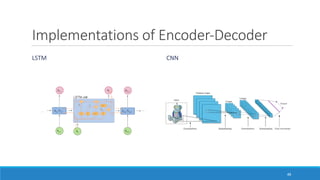
The document discusses advancements in attention models, particularly their simplicity and effectiveness in deep learning applications such as machine translation and natural language processing. It covers the mechanisms of attention, variations like hard and monotonic attention, and improvements to enhance model performance. The presentation highlights the versatility of attention models across various tasks, including chatbots, image captioning, and speech recognition.






























![240318_JW_labseminar[Attention Is All You Need].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/240318jwlabseminartransformer-240409103857-bb3838b7-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)






































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)










