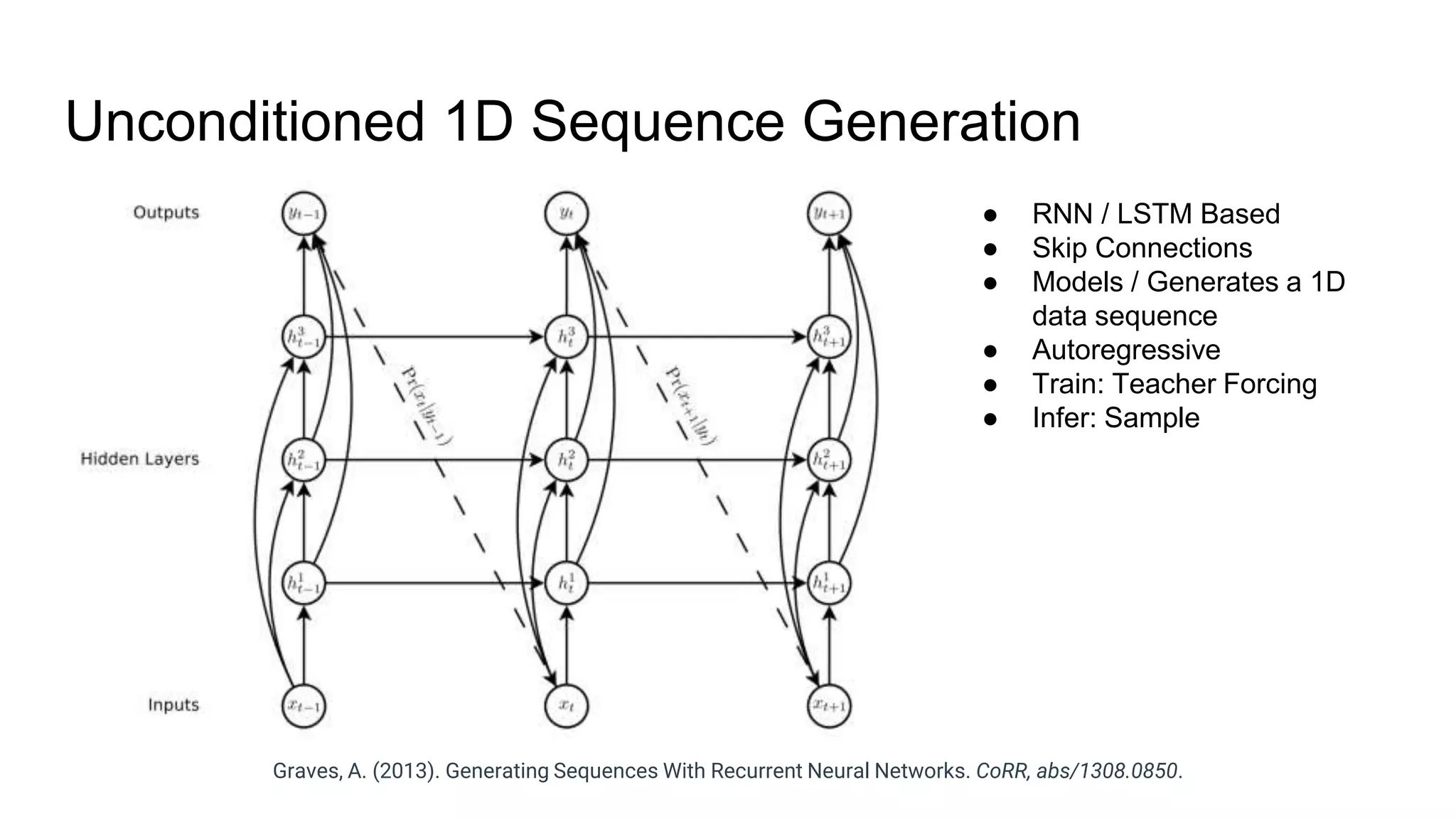
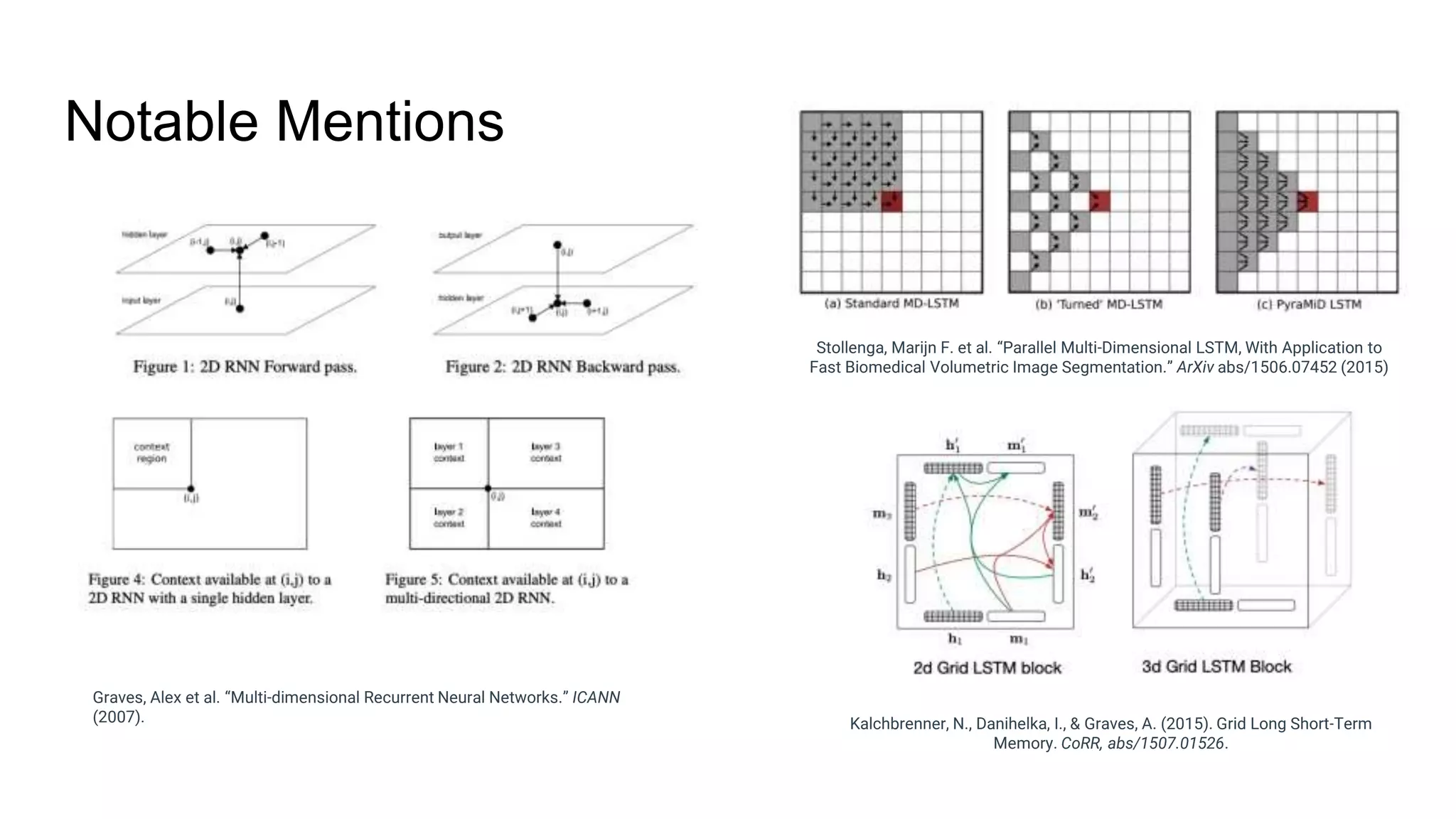
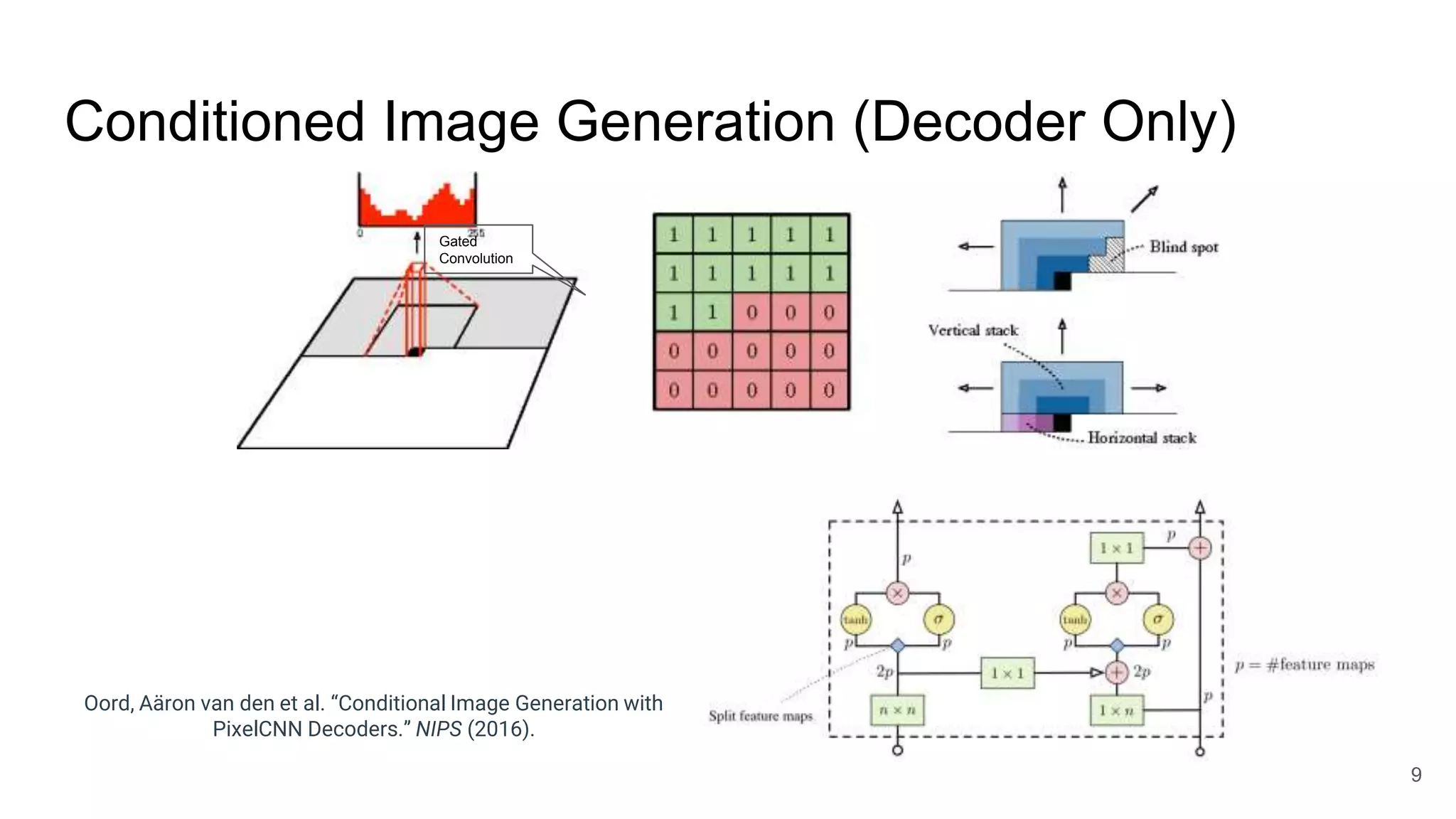
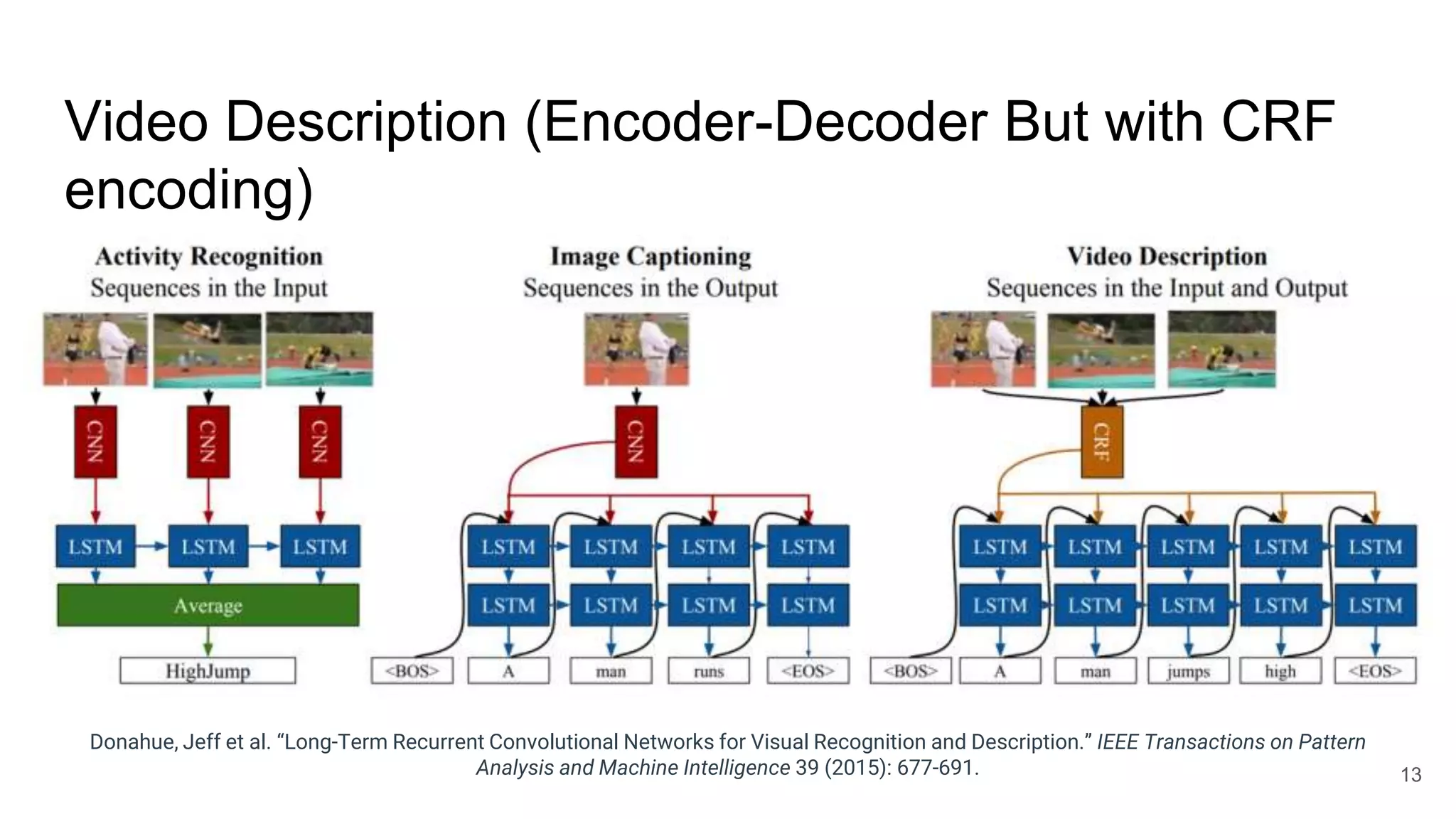
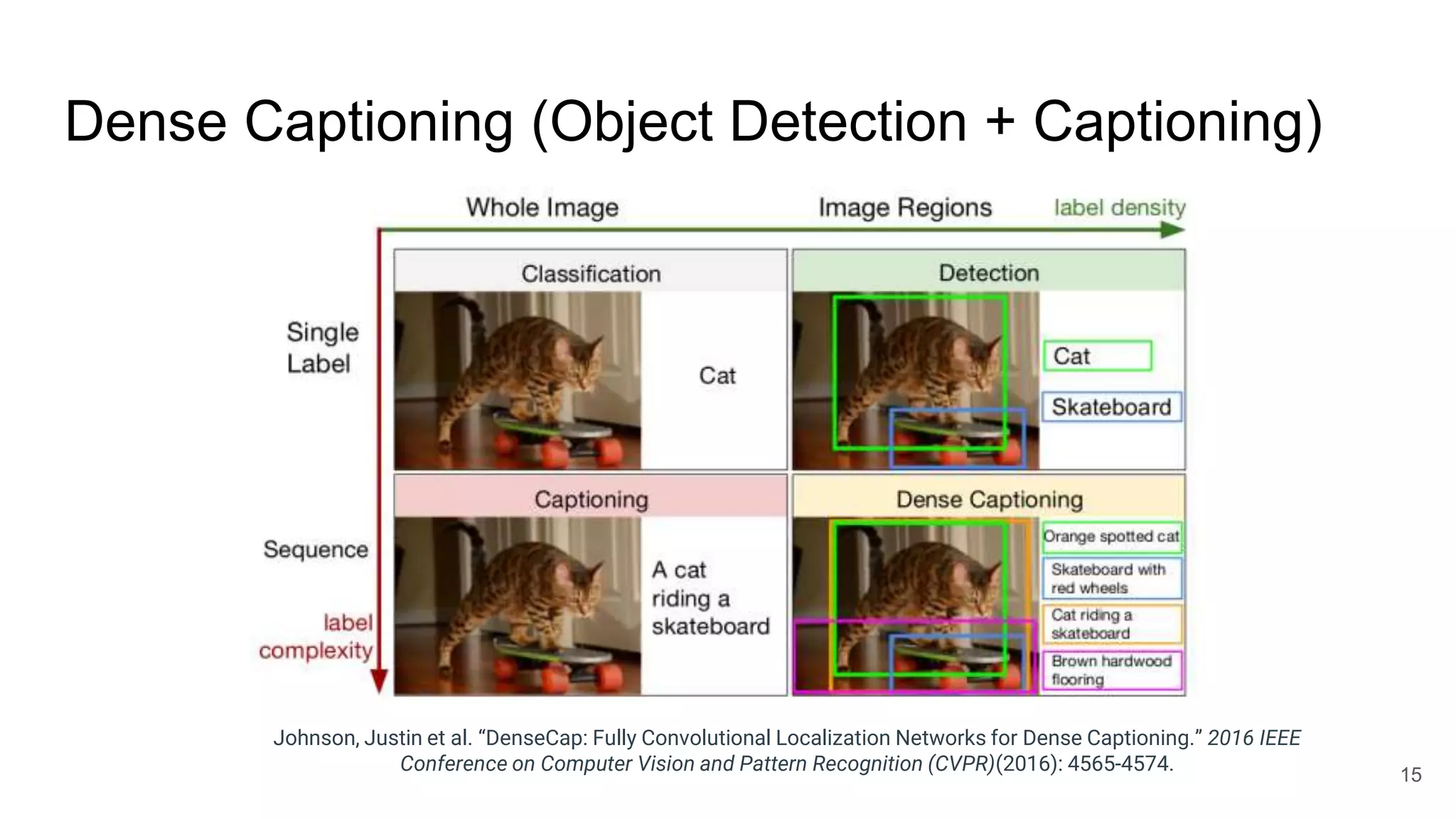
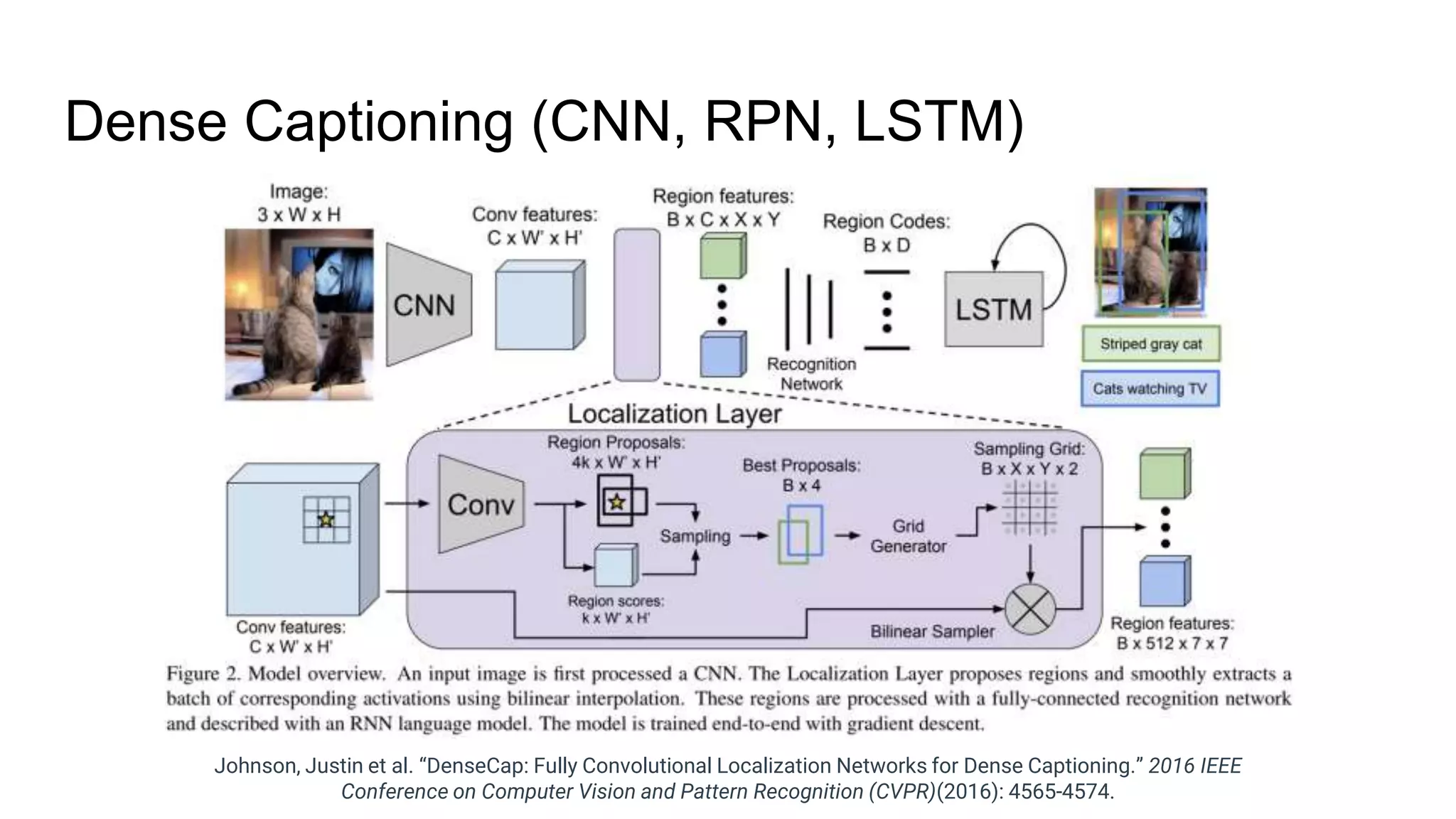
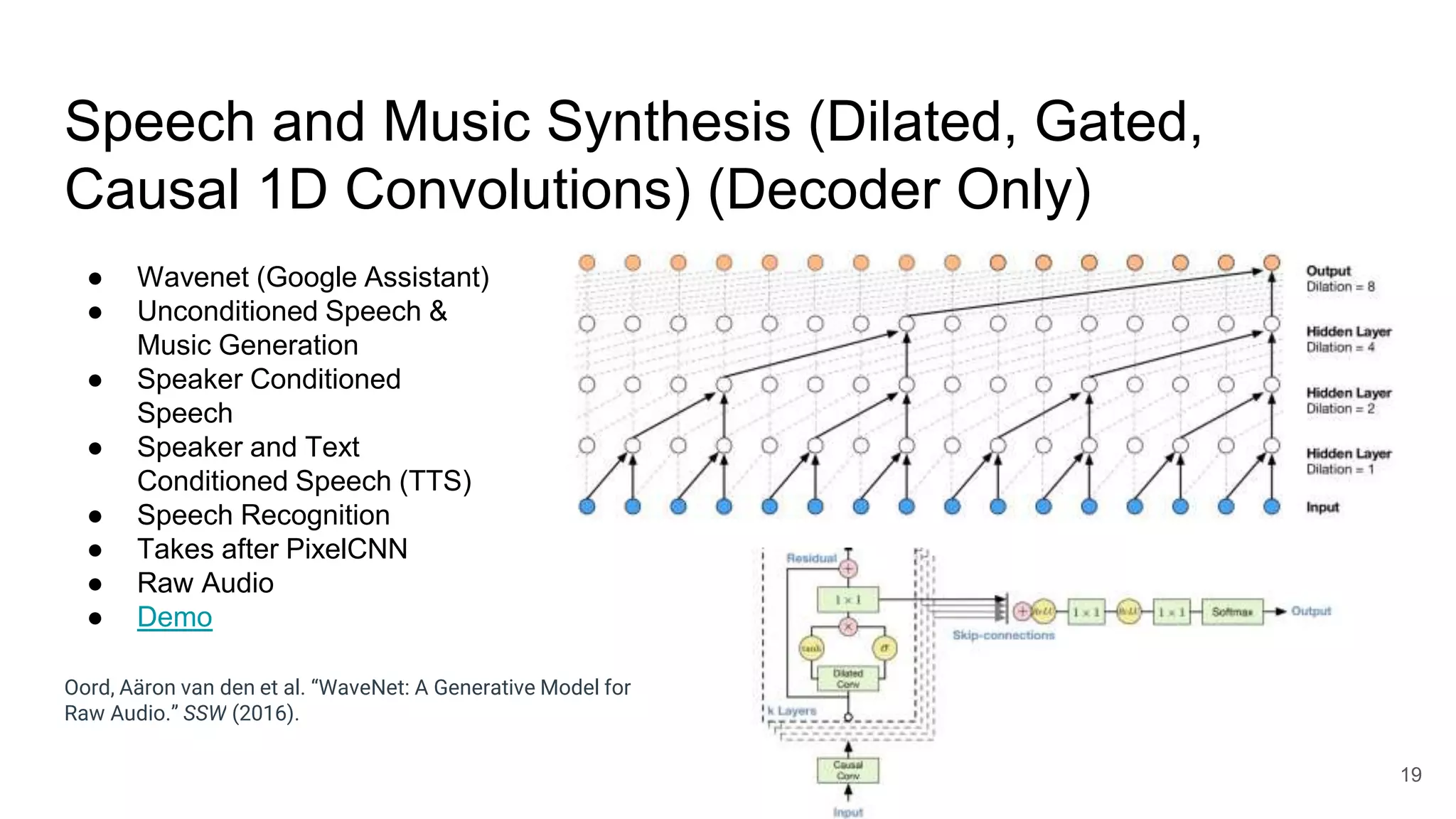
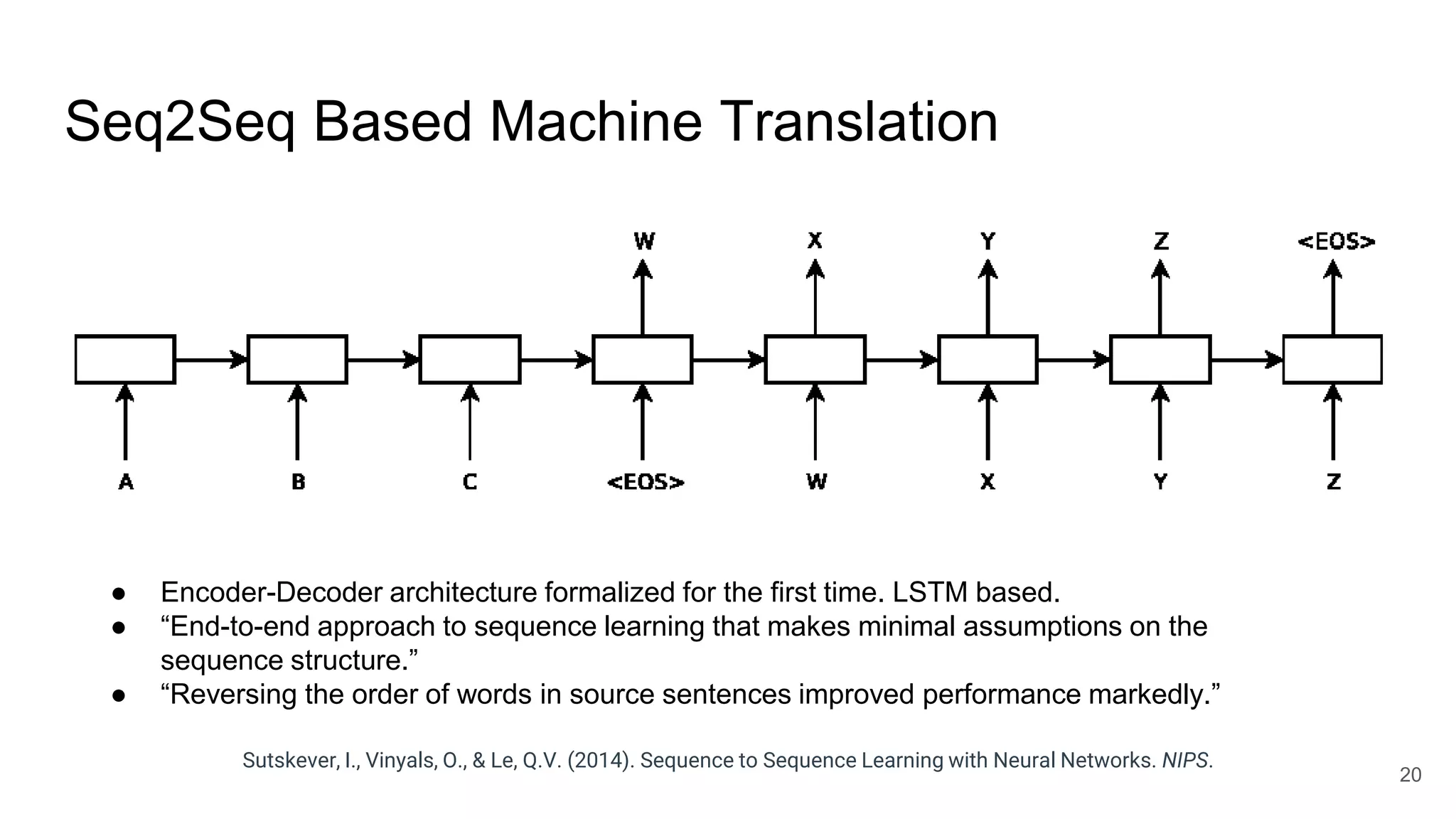
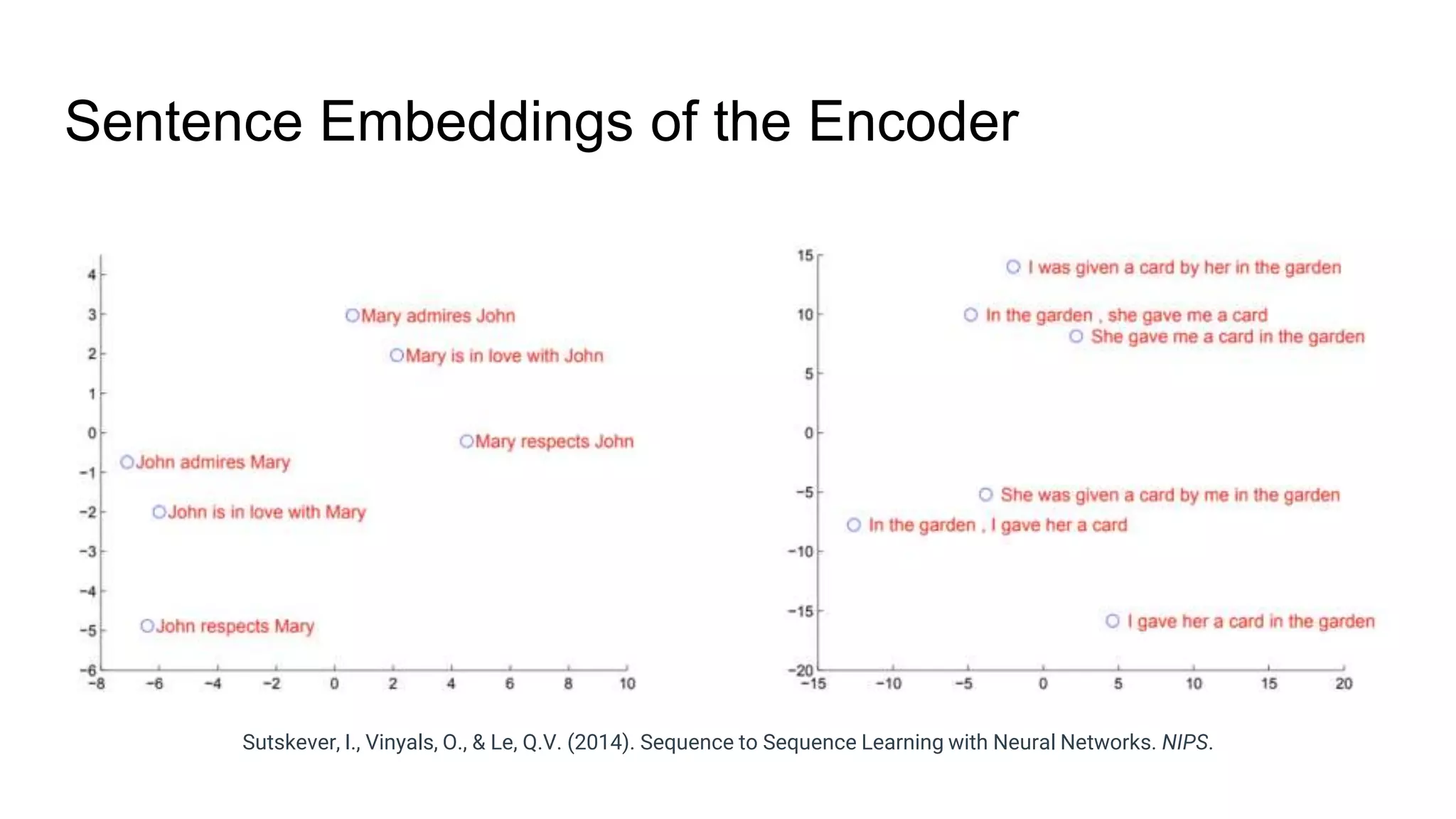
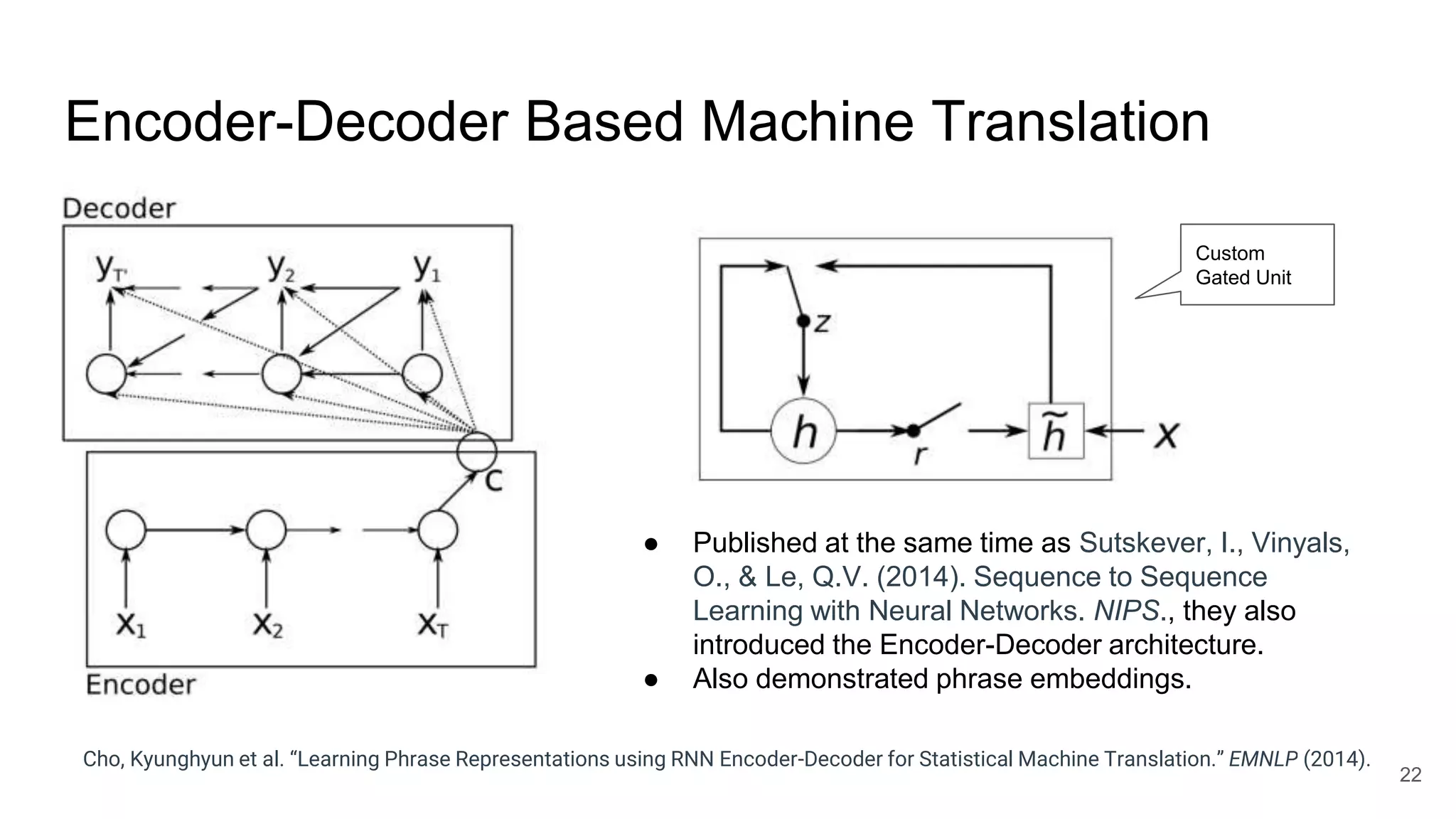
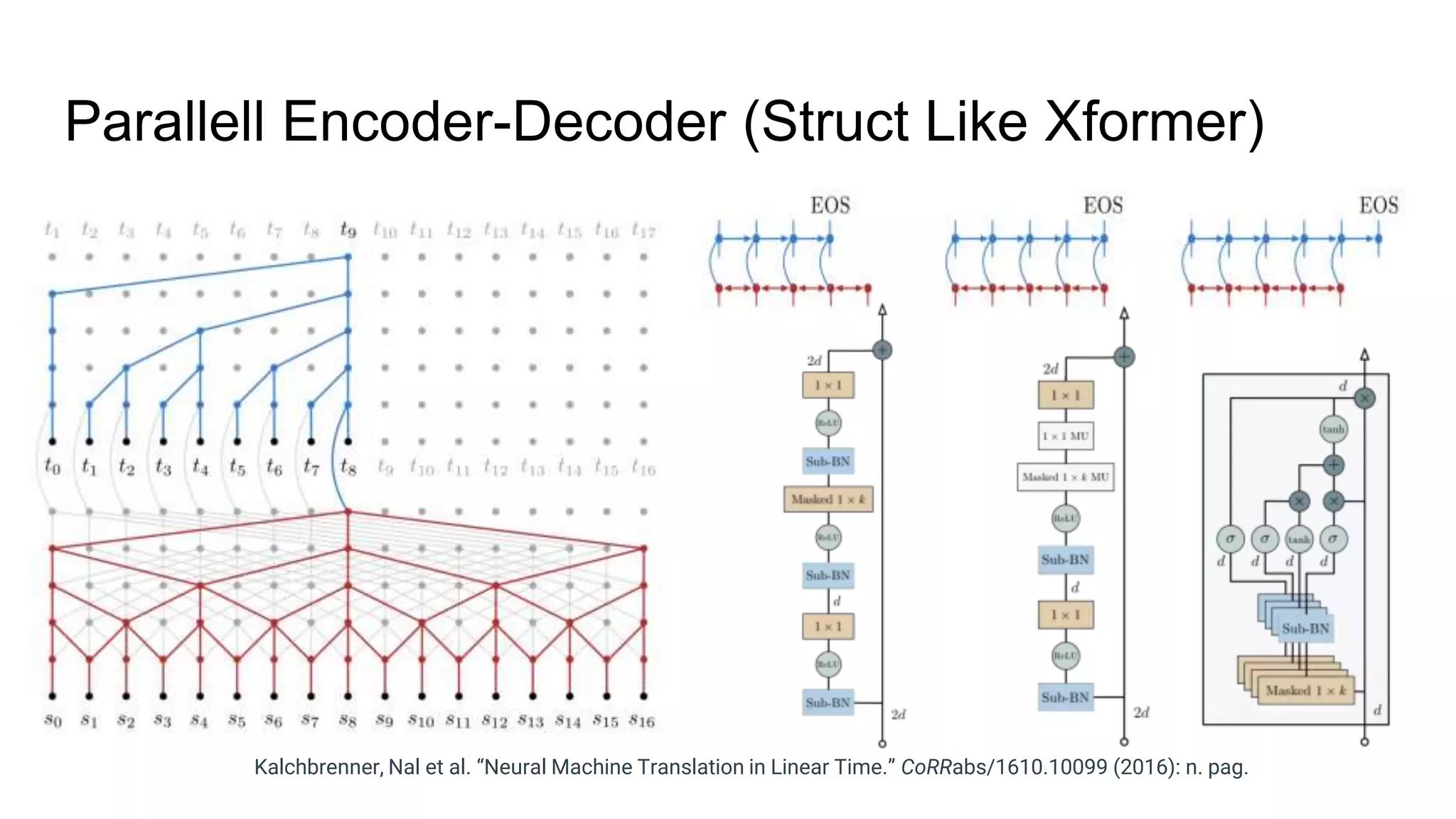
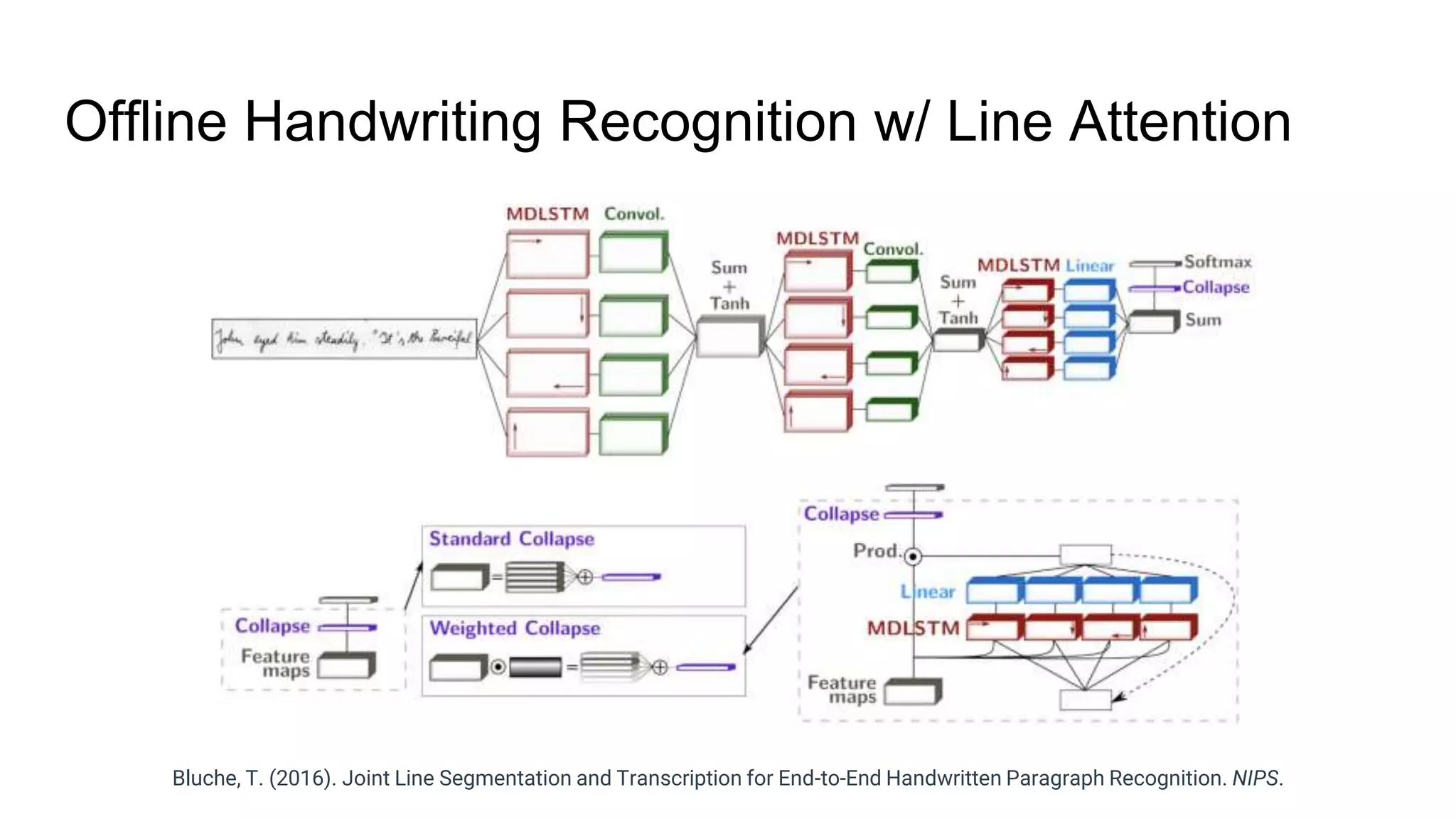
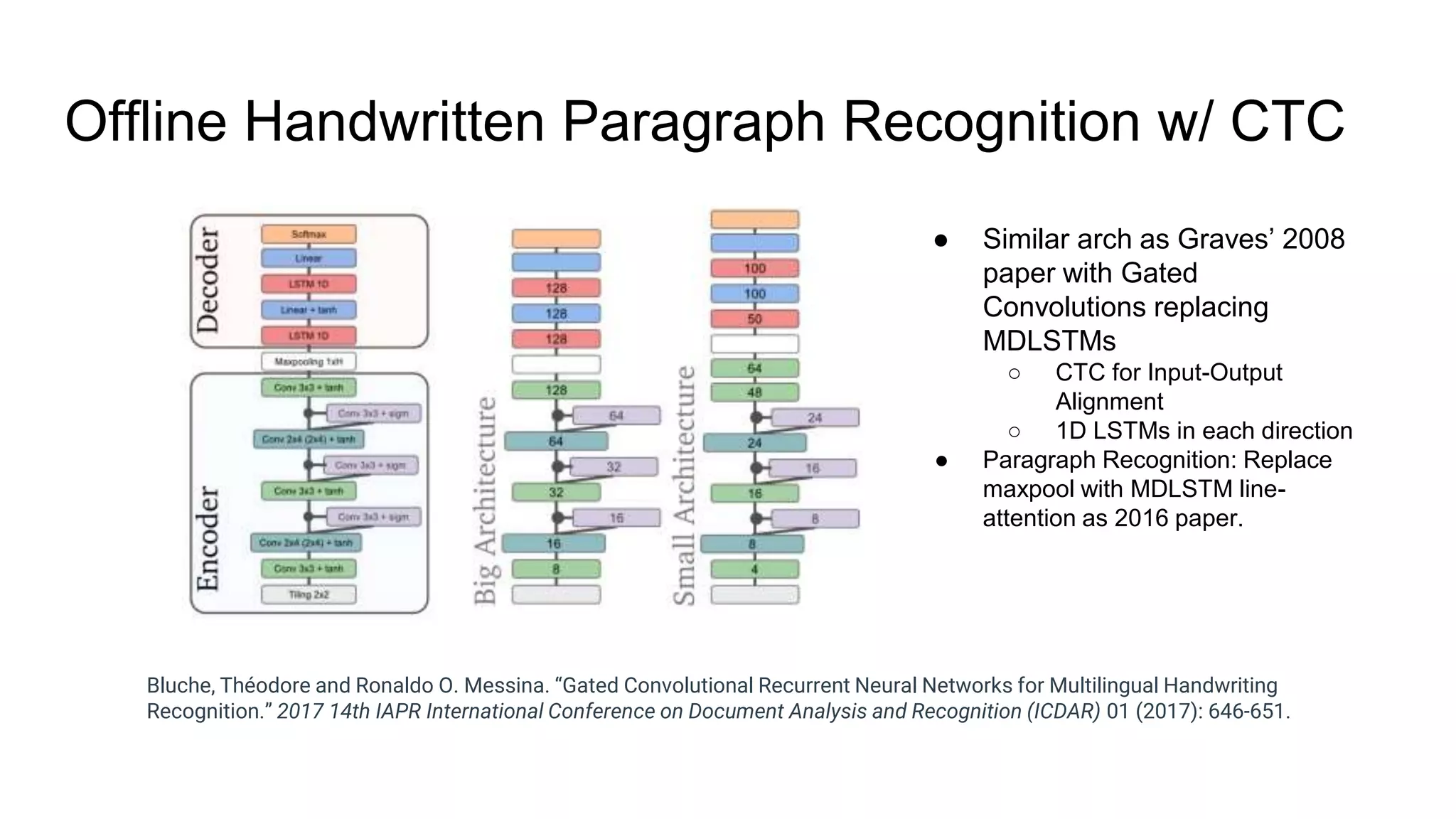
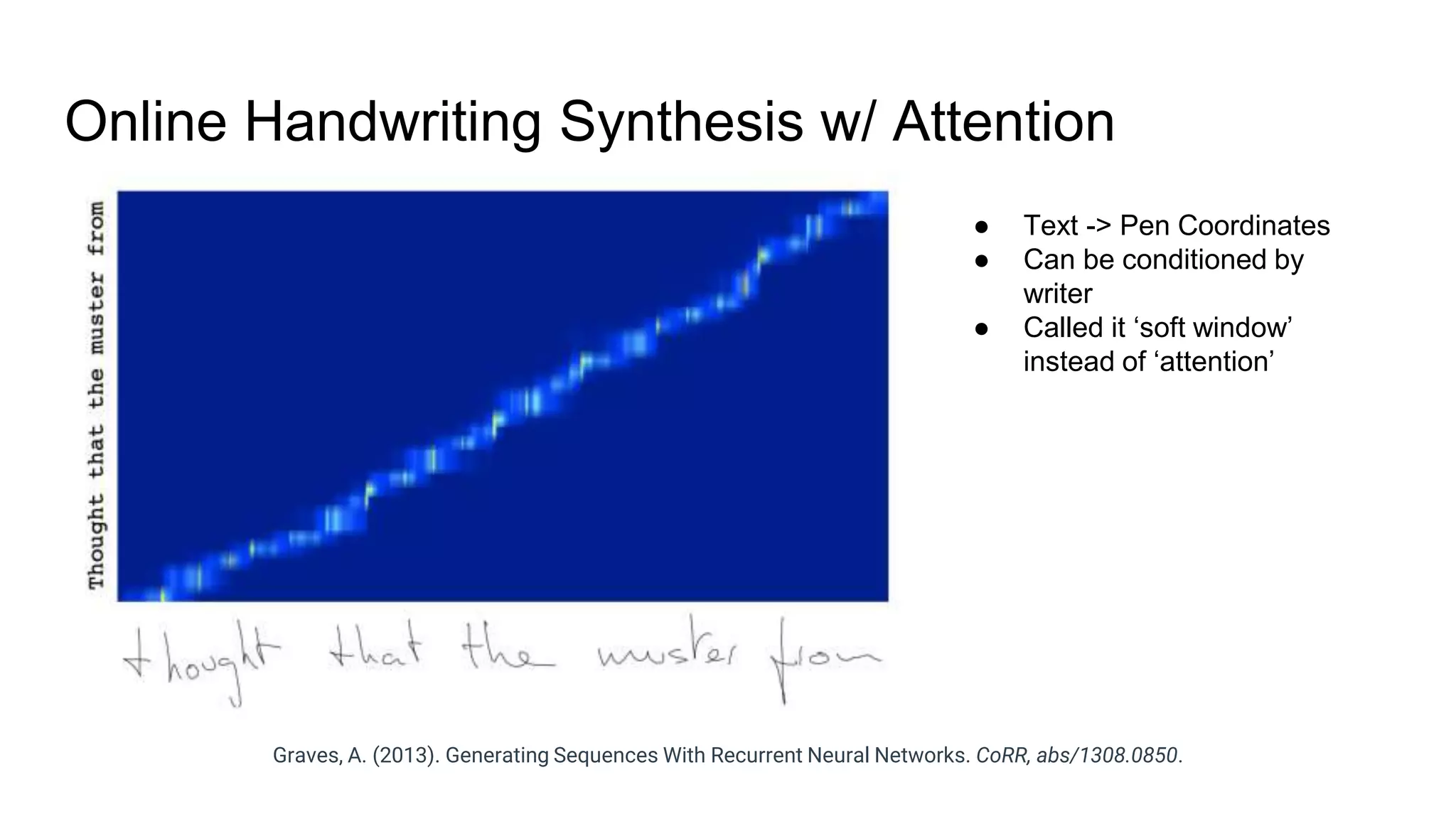
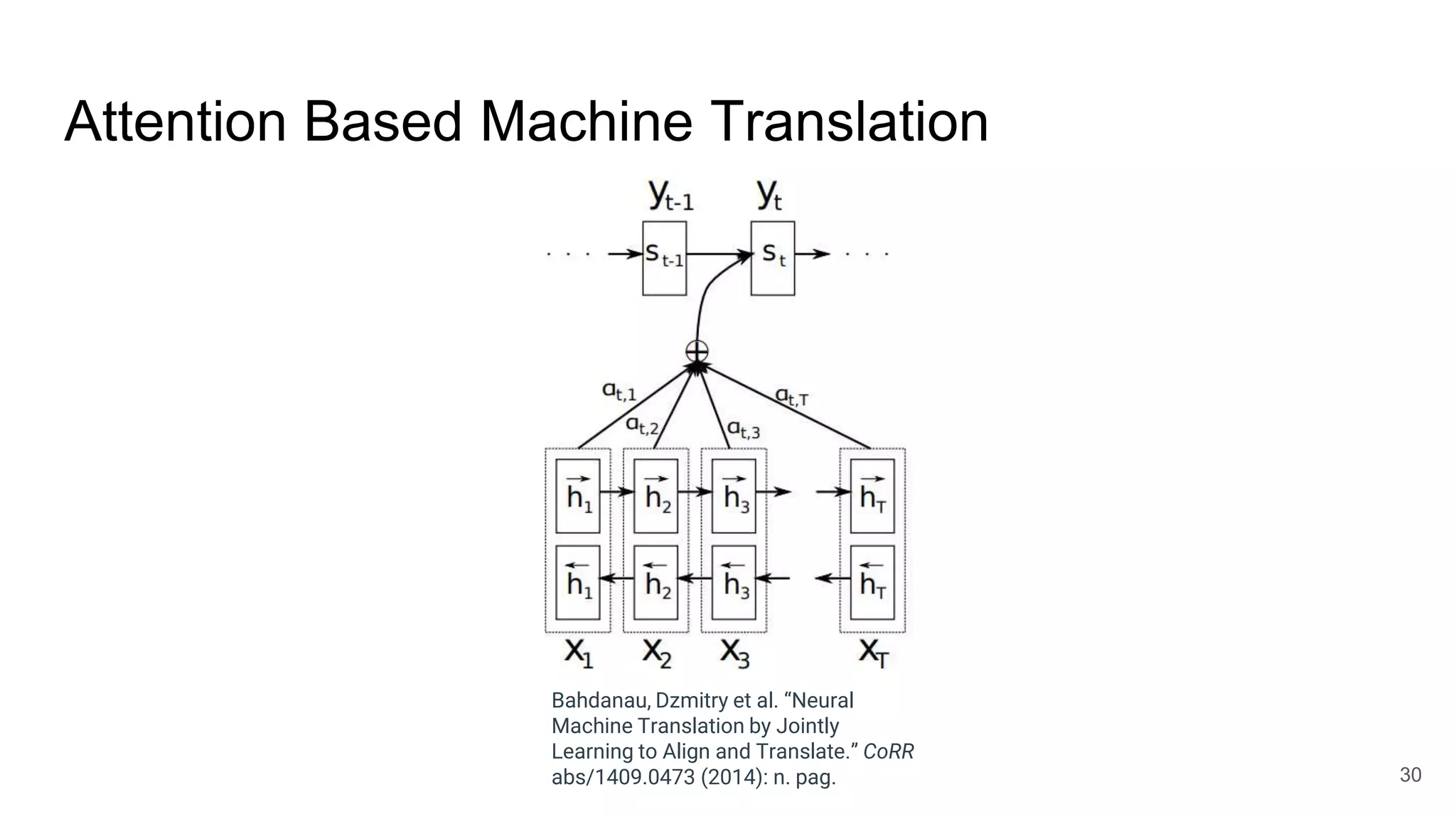
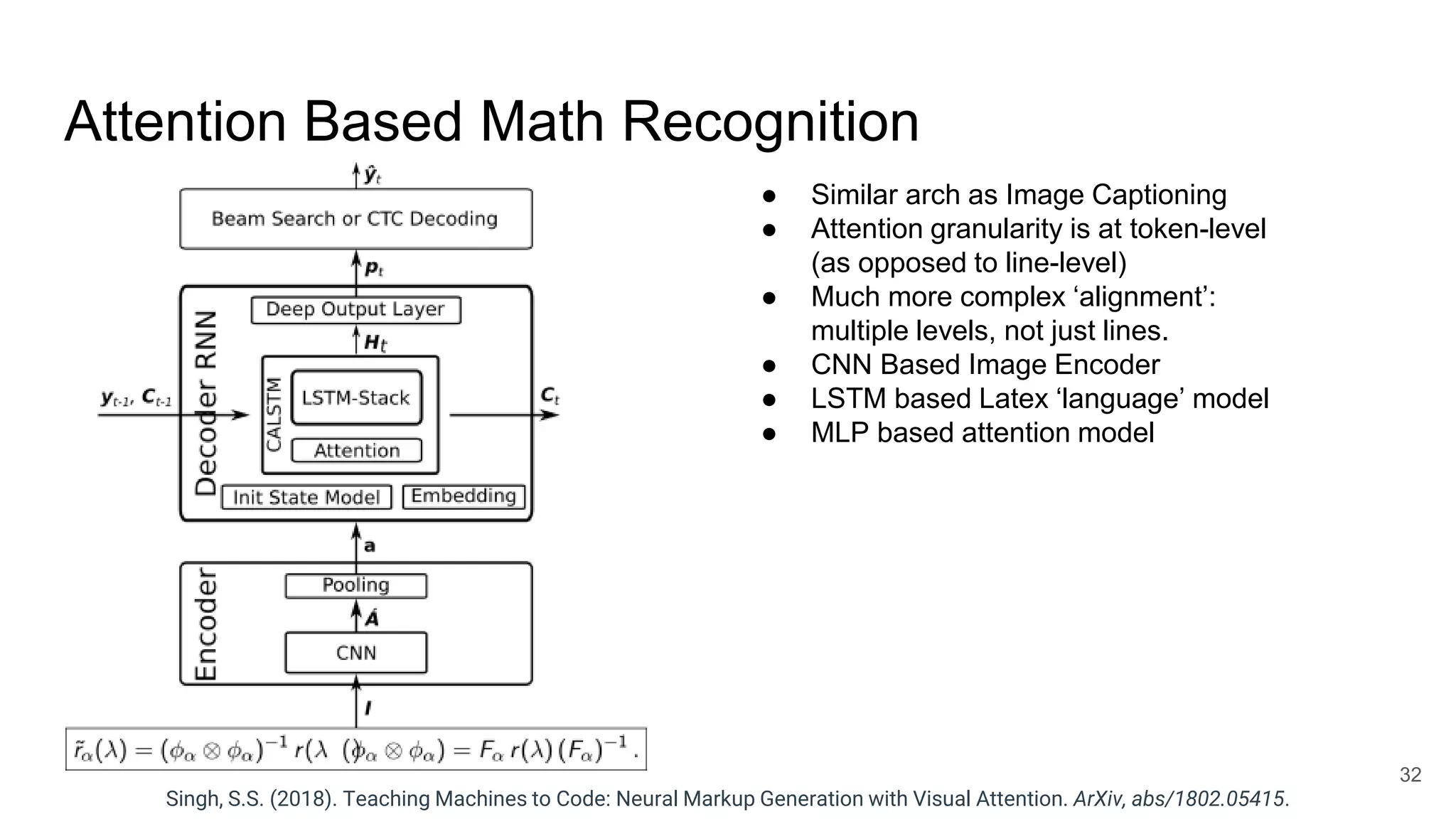
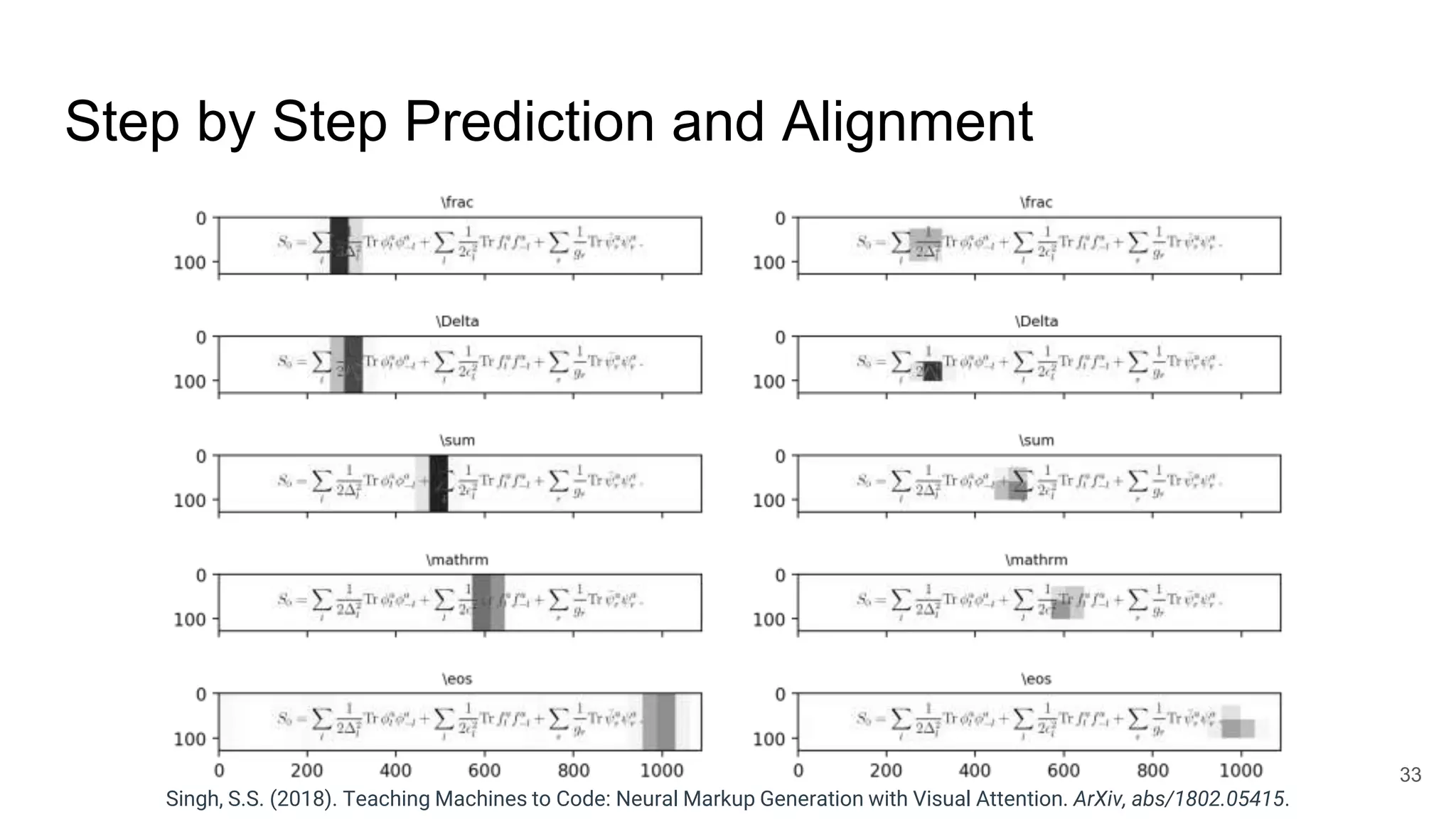
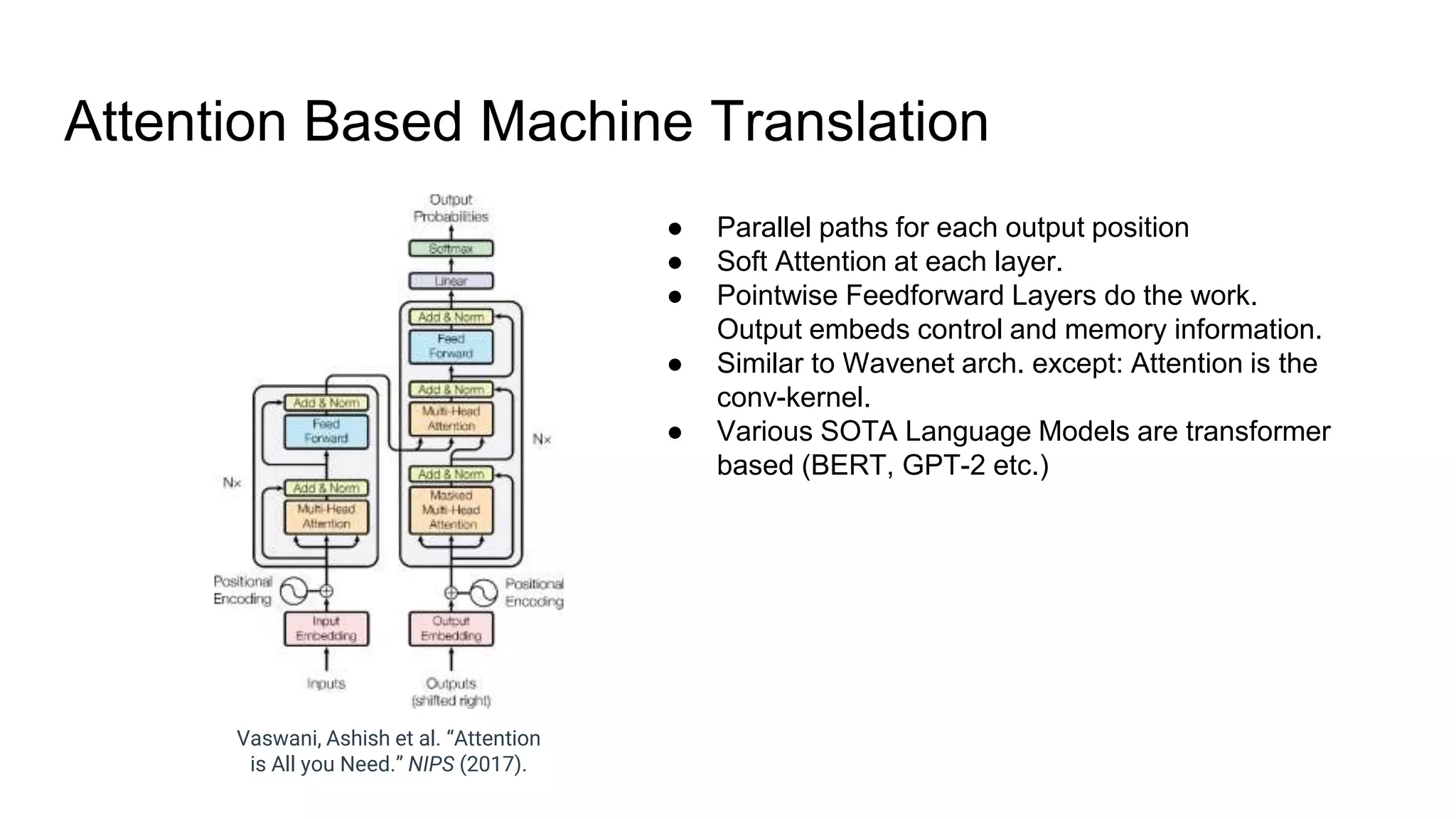
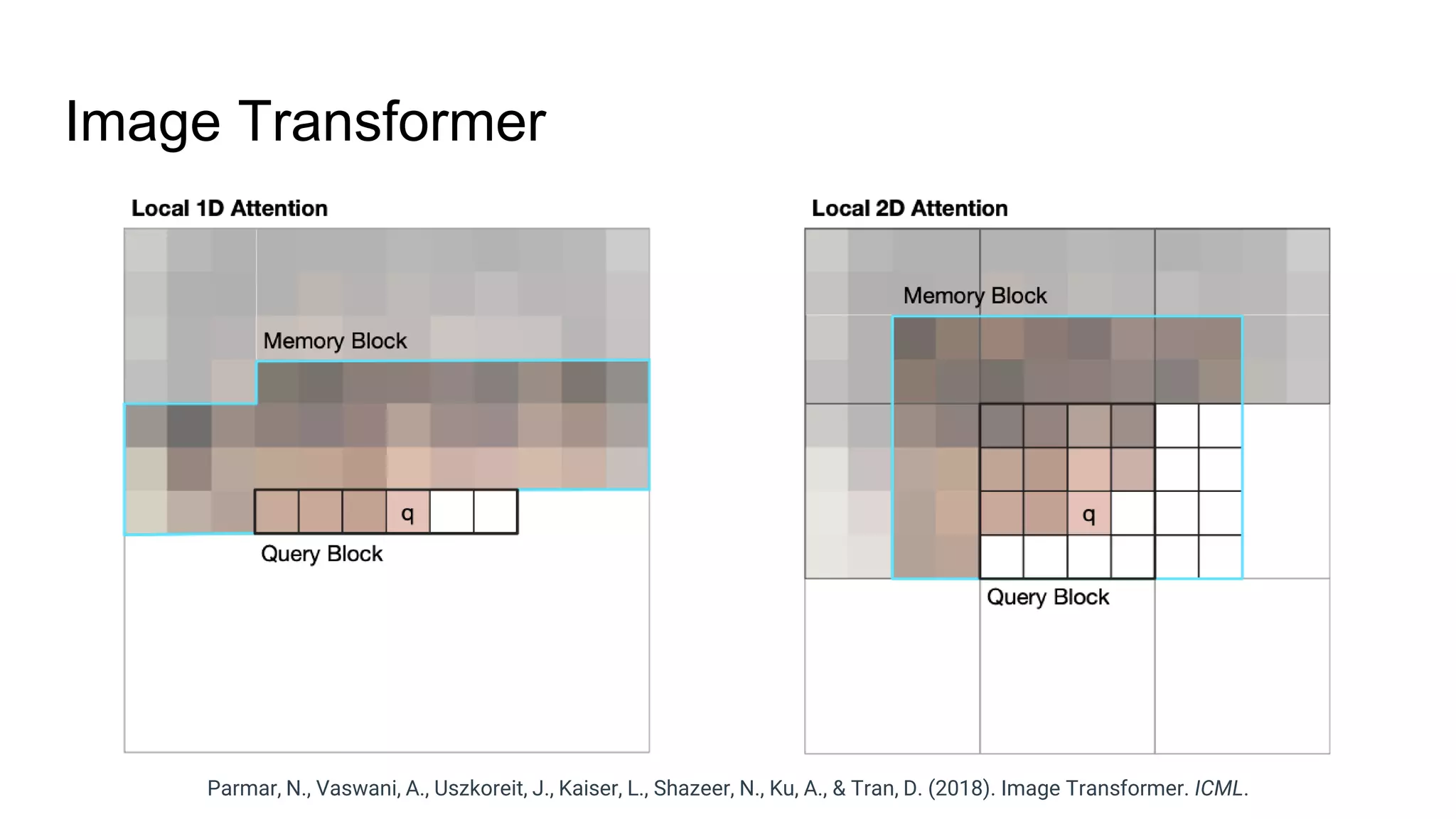
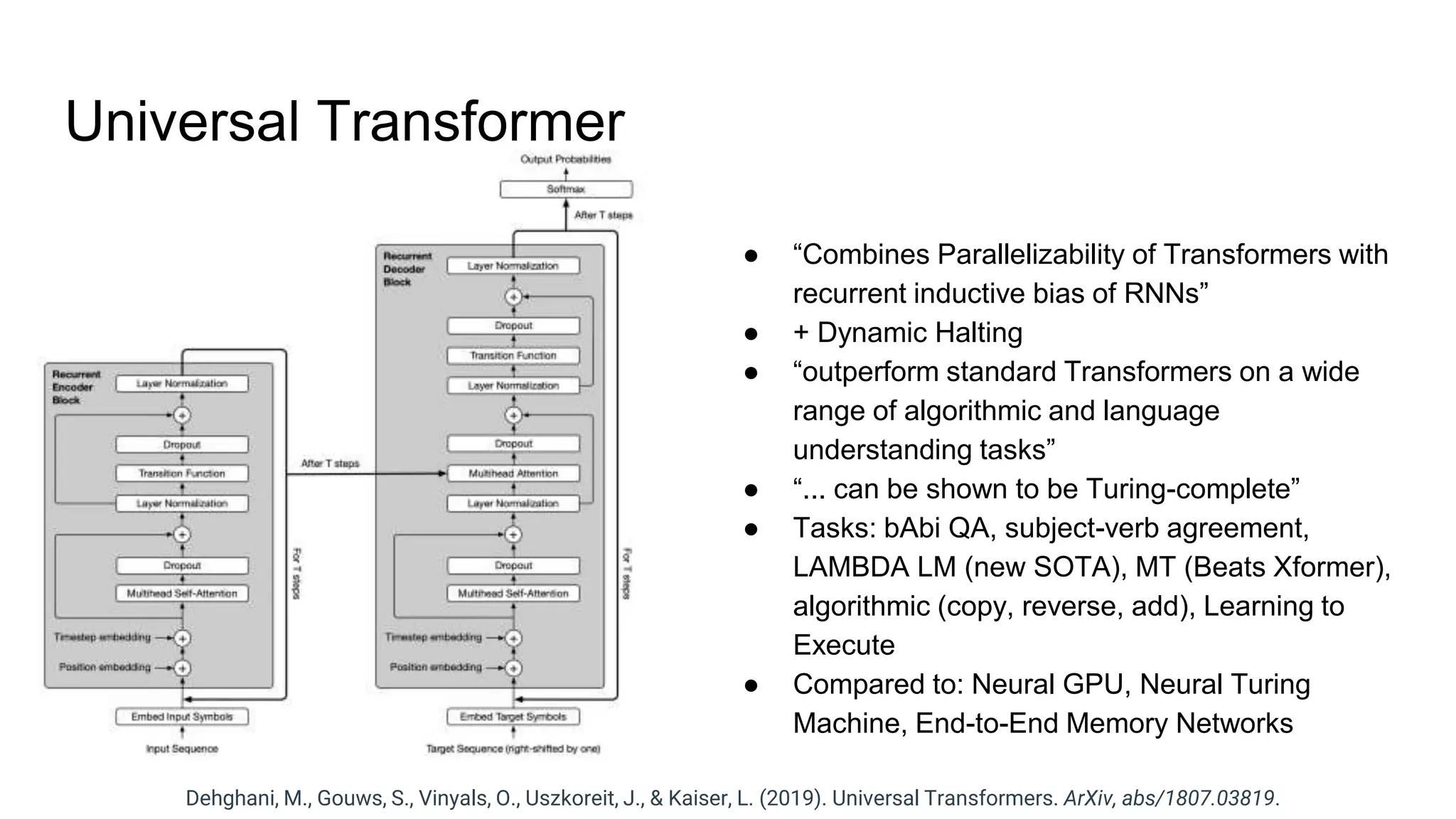
The document provides an overview of neural sequence generators and their various applications across multiple modalities, including speech, music, image, and language processing. It discusses core concepts such as autoregressive generation, attention mechanisms, and different sequence learning models like RNNs and CNNs. Additionally, it highlights notable works and techniques in the field, along with advances in machine translation and generative modeling.