Downloaded 22 times










![Combining different vocabularies
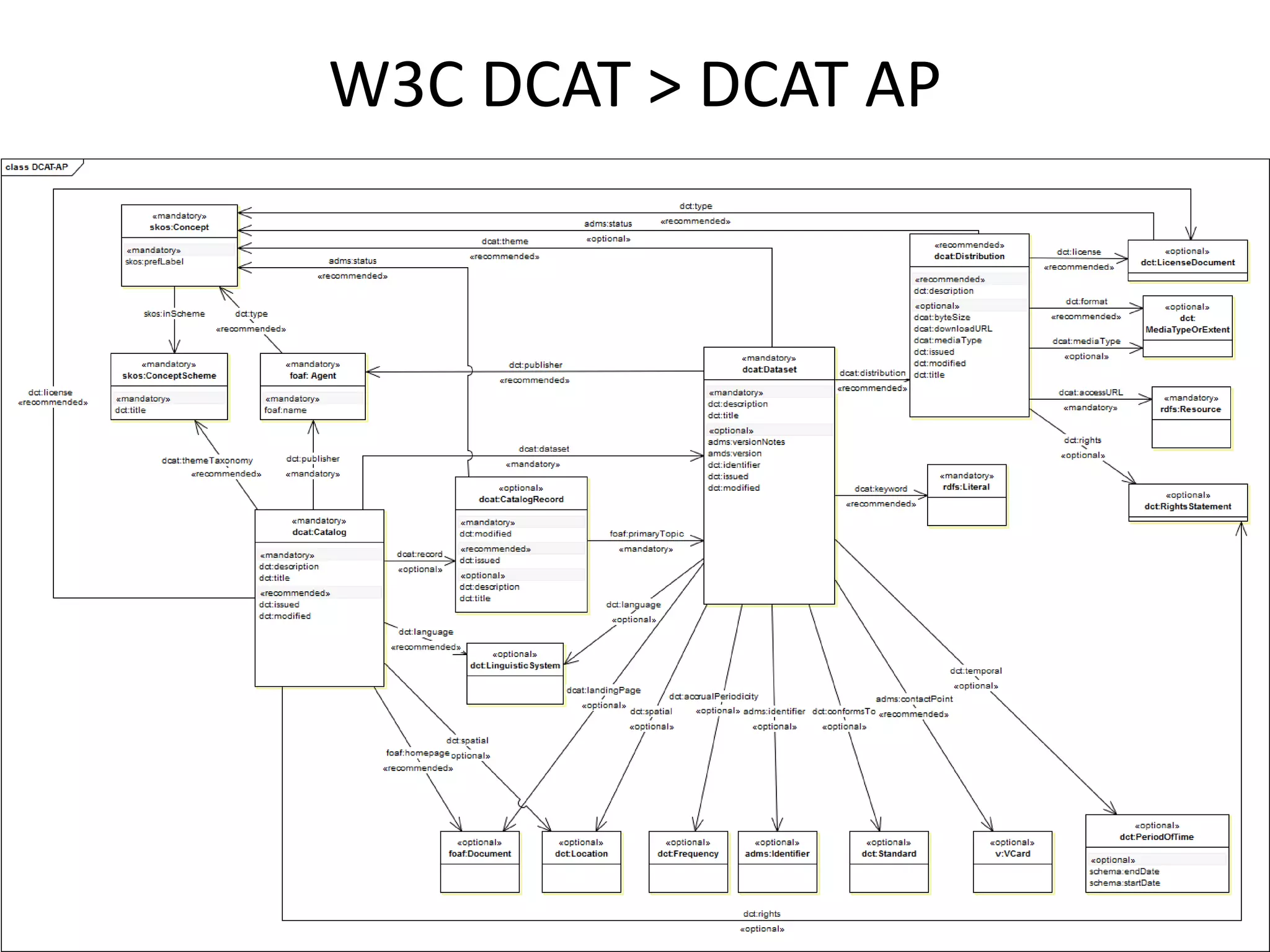
Name
URL
Owner
Content type
Topic(s)
Language
Metadata set(s)
Data structure
Distribution(s)
[…]
DATASET
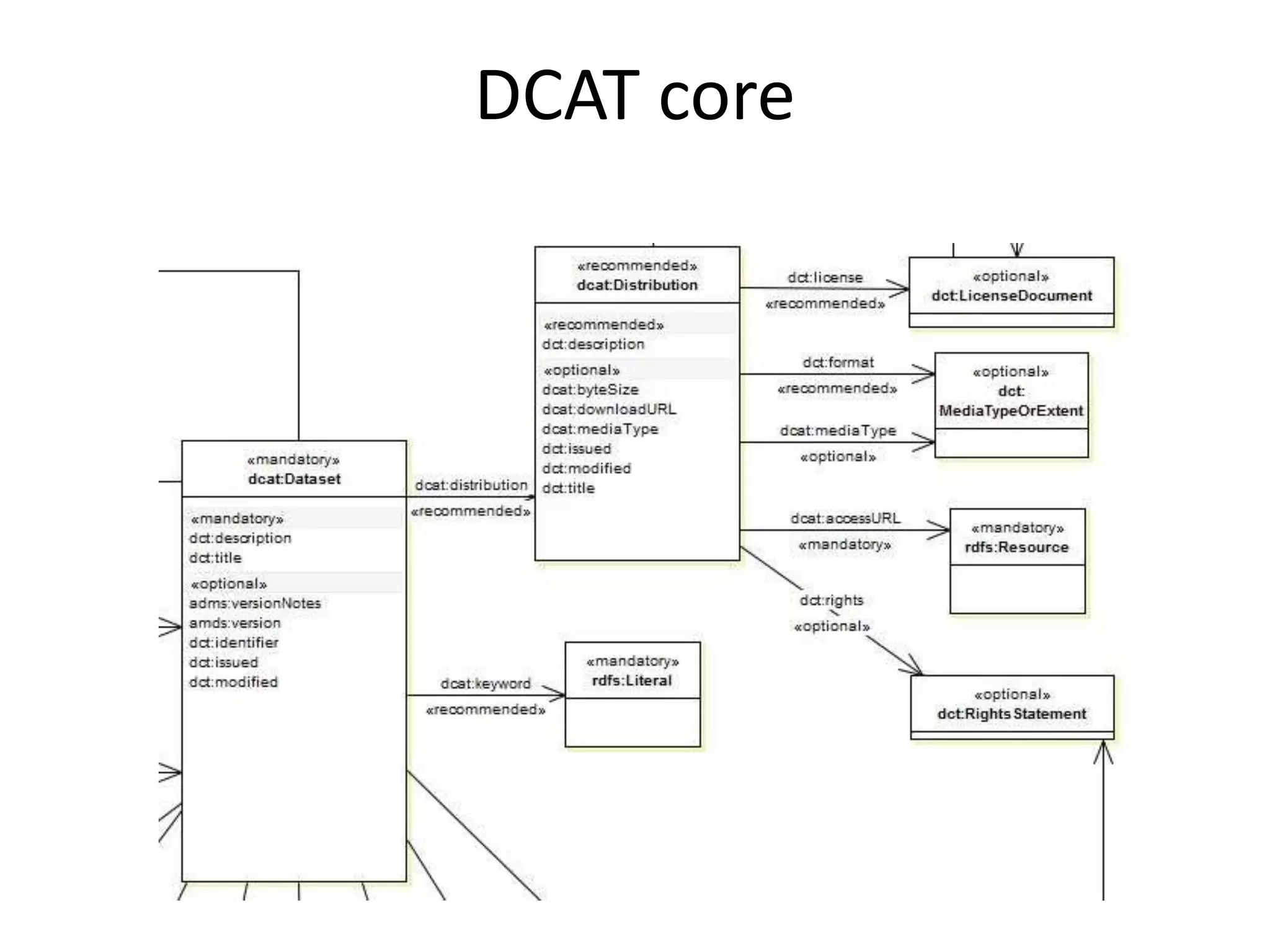
Name
Protocol
Endpoint URL
Media type
Format
Size
DISTRIBUTION
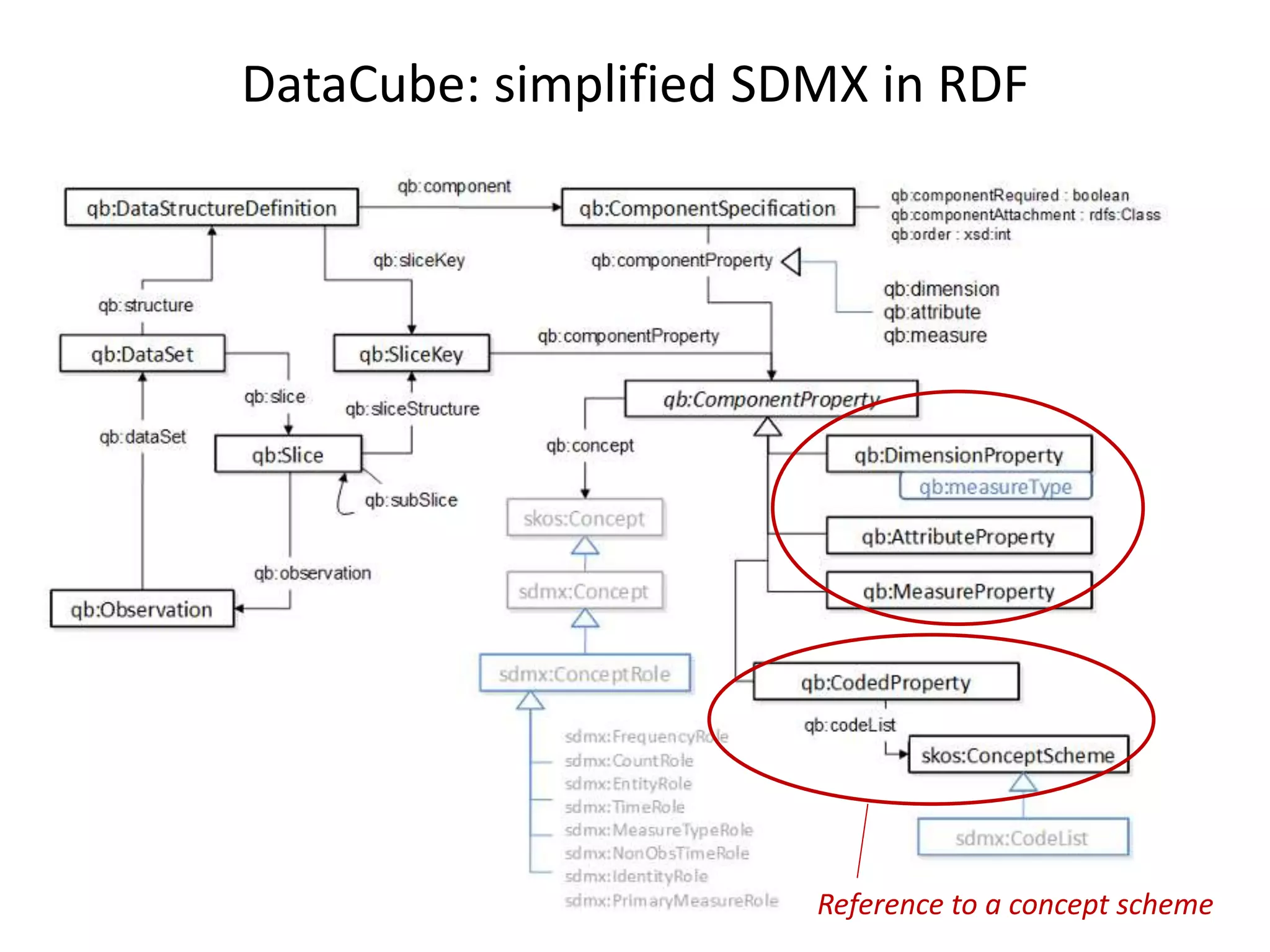
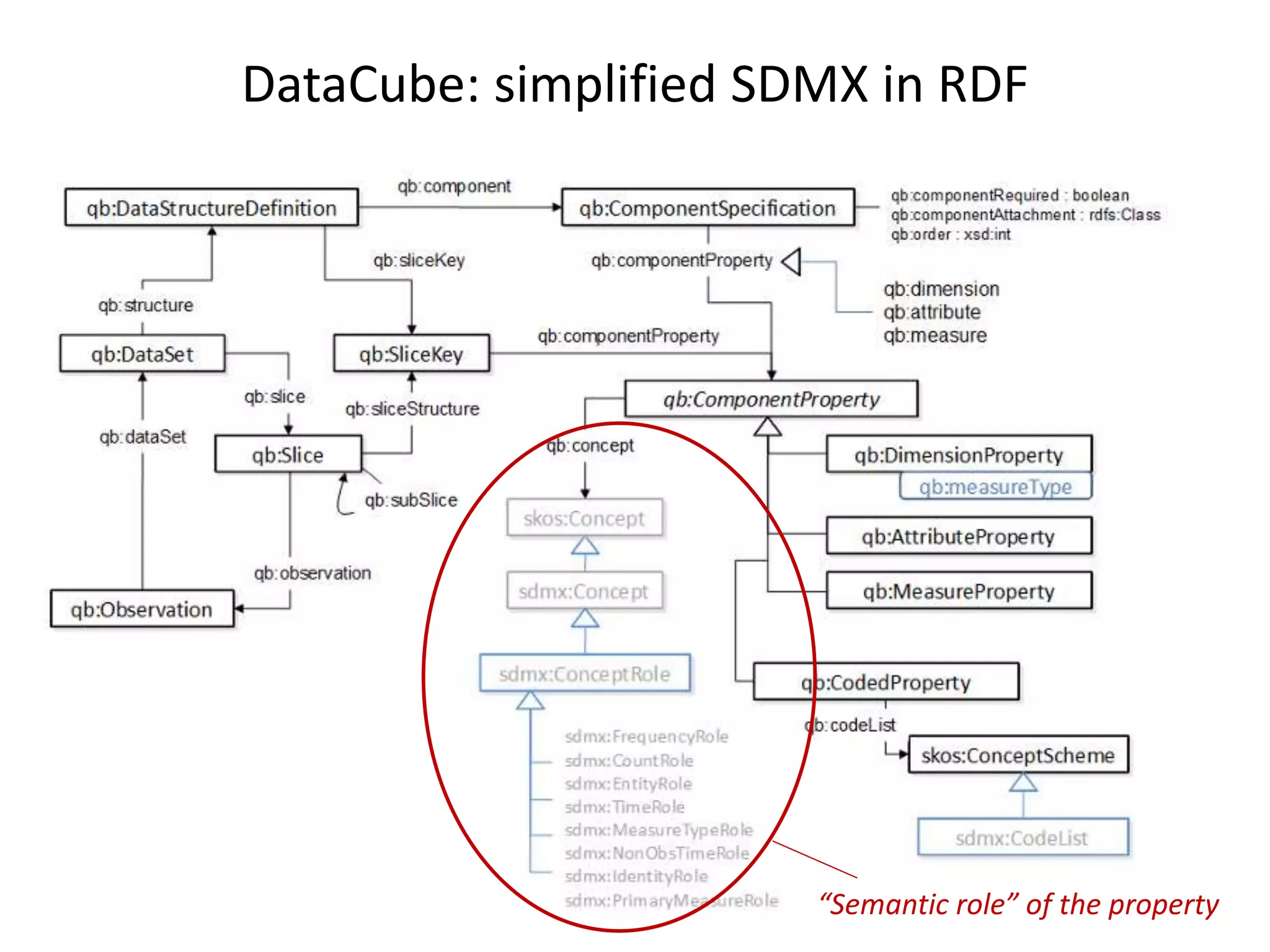
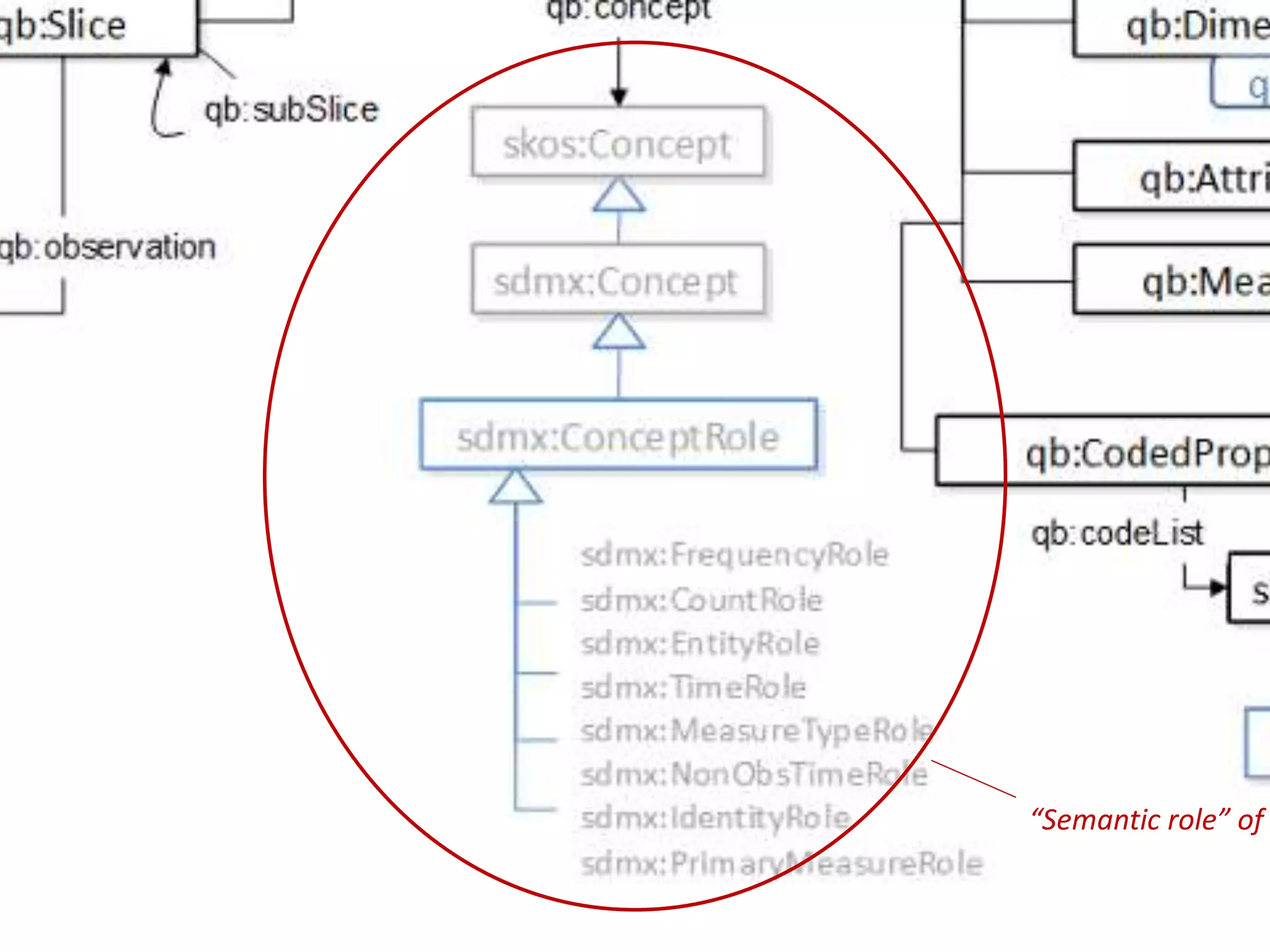
DCAT model
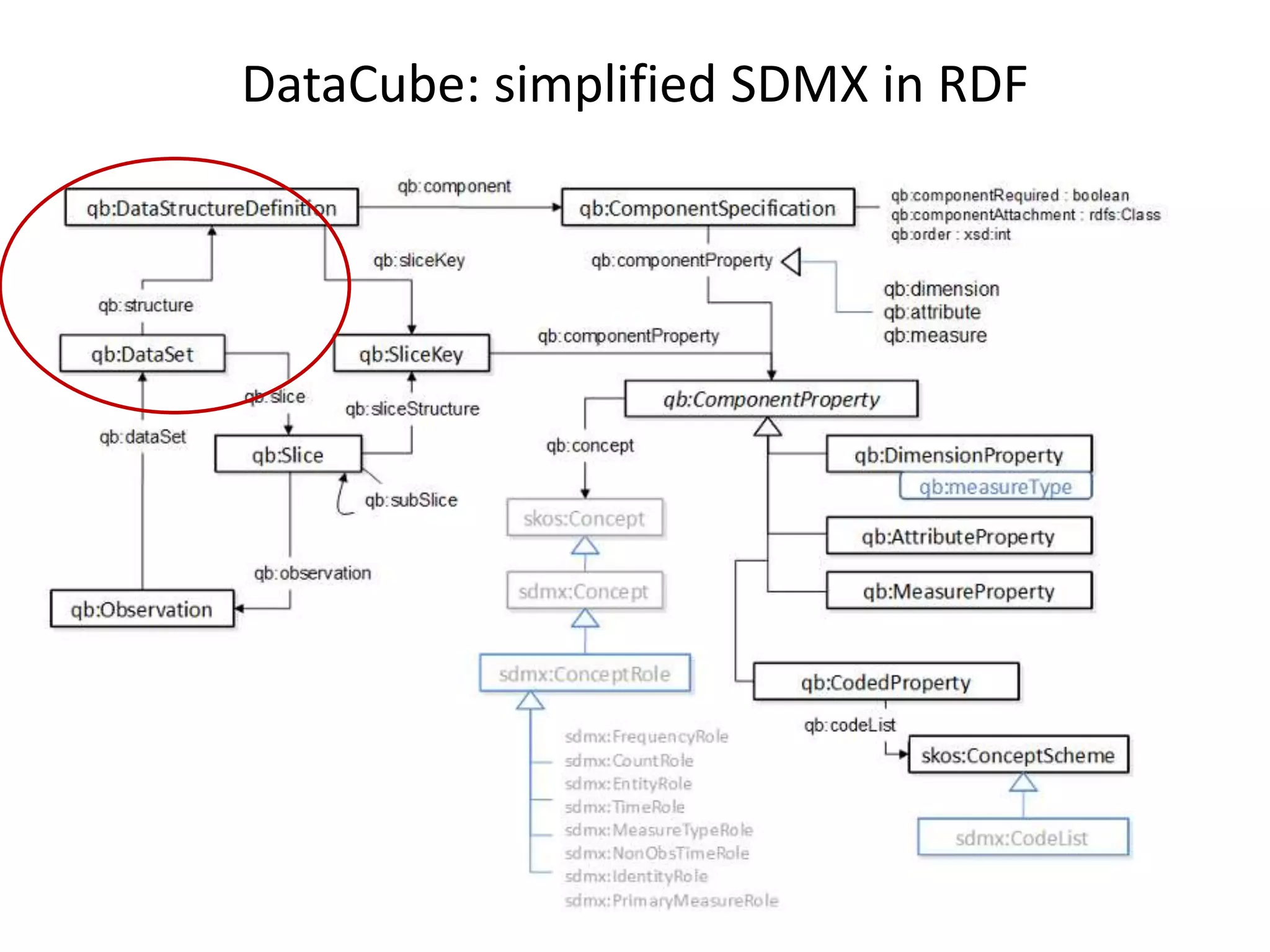
Dimensions
Attributes
Measures
Value lists
DATA STRUCTURE
DataCube model
Catalog: the directory
Vocabulary(ies)
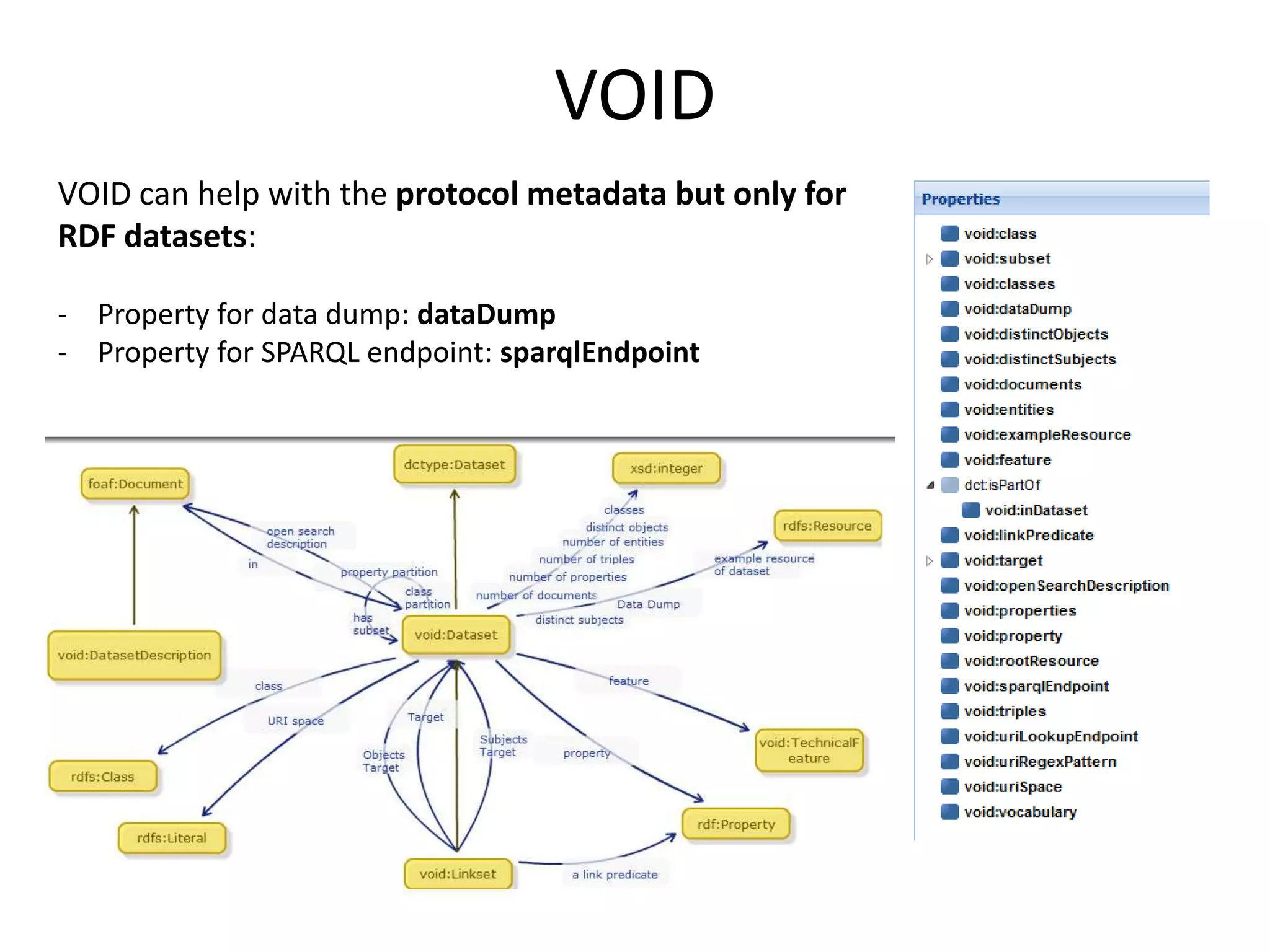
SPARQL endpoint
Data dump
Serialization format
Number of triples
RDF dataset info
VOID properties
If one or more known
published metadata sets
are used, just fill
“metadata set(s)”,
otherwise link to a “data
structure” with custom
“dimensions”
IF media type has RDF
or SPARQL response](https://image.slidesharecdn.com/igad-pre-meeting-dataset-interoperability-150924090659-lva1-app6892/75/How-to-describe-a-dataset-Interoperability-issues-18-2048.jpg)





The document discusses the definition and characteristics of datasets, emphasizing their interoperability, which allows data to be retrieved and reused by various systems. It outlines essential metadata requirements for datasets, including technical specifications, conditions for reuse, and coverage details, while also noting existing vocabularies like DCAT and SDMX that facilitate dataset description. Major challenges are identified regarding missing properties and vocabularies, necessitating further standardization efforts for improved interoperability.


















































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)














