2 2016/12/2
Singularity Copyright2016 Singularity Inc. All rights reserved
自己紹介
新村拓也
- シーエイトラボ株式会社 代表取締役
- シンギュラリティ株式会社 取締役CTO
- 機械学習のための数学塾
- RNN camp
3.
3
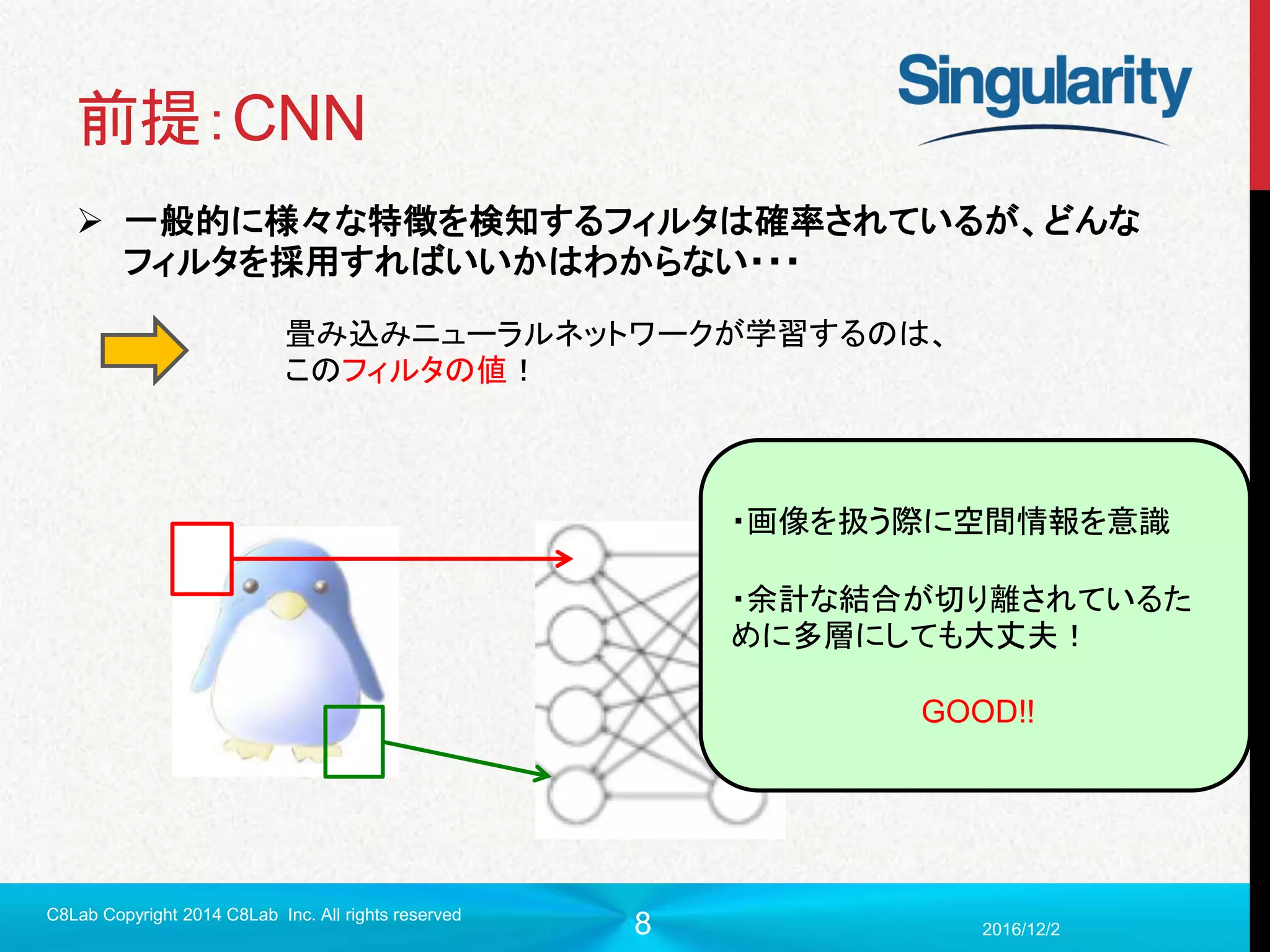
今回読んだ論文
「Convolutional LSTMNetwork: A Machine Learning Approach
for Precipitation Nowcasting」
畳み込みLSTMを用いて短時間の天気(レーダーマップ)予報を行った
実験
Moving mnistのフレーム予測とレーダーマップ予報を行った
2016/12/2
Singularity Copyright 2016 Singularity Inc. All rights reserved
https://arxiv.org/abs/1506.04214
4.
4
この論文を選んだ動機(脱線)
PredNet
「DeepPredictive Coding Networks for Video Prediction and
Unsupervised Learning」
Predictive Codingという脳科学の知見を深層学習に組み込んだ
ネットワーク
教師なし学習による動画予測を行った論文
2016/12/2
Singularity Copyright 2016 Singularity Inc. All rights reserved
https://arxiv.org/abs/1605.08104
15
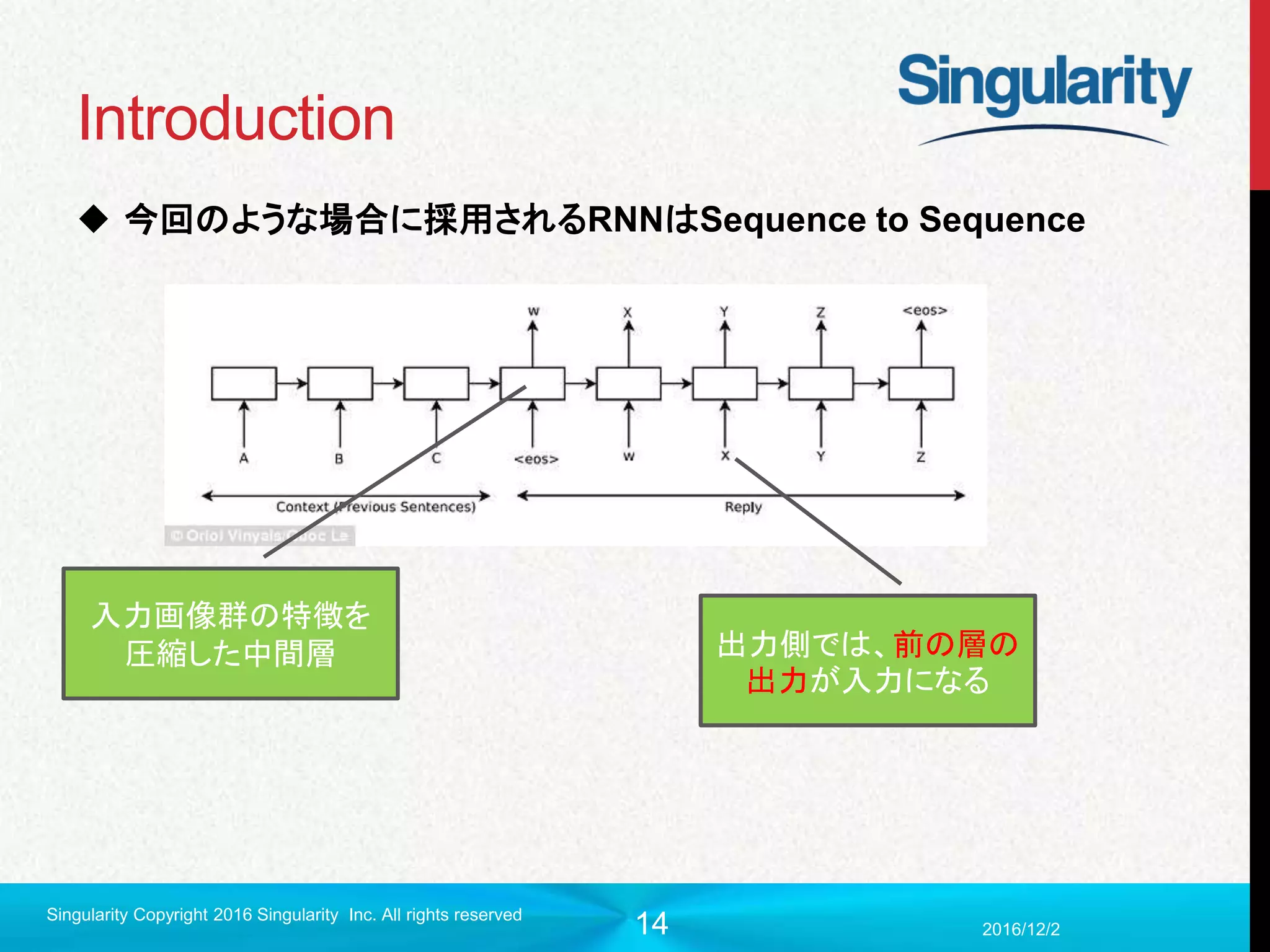
Introduction (先行研究)
実は畳み込みLSTMはすでにされていた
「 Video (language) modeling: a baseline for generative models
of natural videos. 」
フレーム予測が1フレームだけ
なぜか中間層=>中間層の畳み込みフィルタサイズが1×1のみ
「 Unsupervised learning of video representations using lstms.」
Seq to seqになって複数のフレーム予測はするようになった
でもなぜか中間層=>中間層が全結合のデフォルトLSTM
2016/12/2
Singularity Copyright 2016 Singularity Inc. All rights reserved
・中間層同士もしっかり畳み込み
・フィルタサイズもいろいろ変更
・多層LSTM
・Seq to Seq を採用して未来の多フレーム予測
このペーパーでは・・・






























![[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]画像を使ったSim2Realの現況](https://cdn.slidesharecdn.com/ss_thumbnails/imagesim2real-201030025320-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Attention Is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks170714-170714005330-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Pervasive Attention: 2D Convolutional Neural Networks for Sequence-to-...](https://cdn.slidesharecdn.com/ss_thumbnails/20180907pervasiveattention2dconvolutionalneuralnetworksforsequence-to-sequenceprediction-180907000649-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]FOTS: Fast Oriented Text Spotting with a Unified Network](https://cdn.slidesharecdn.com/ss_thumbnails/20181012yokota-181012004624-thumbnail.jpg?width=640&height=640&fit=bounds)













