Downloaded 109 times








![Demo
[Spinning up a HDInsight Cluster ;-)]](https://image.slidesharecdn.com/introductiontohdinsight-150207134502-conversion-gate01/75/Introduction-to-Azure-HDInsight-17-2048.jpg)



![Demo
[Query, Analyze, Transfer + Visual Studio Tools for HDInsight]](https://image.slidesharecdn.com/introductiontohdinsight-150207134502-conversion-gate01/75/Introduction-to-Azure-HDInsight-22-2048.jpg)
![Demo
[Self-Service BI with Hive and Excel…]](https://image.slidesharecdn.com/introductiontohdinsight-150207134502-conversion-gate01/75/Introduction-to-Azure-HDInsight-24-2048.jpg)




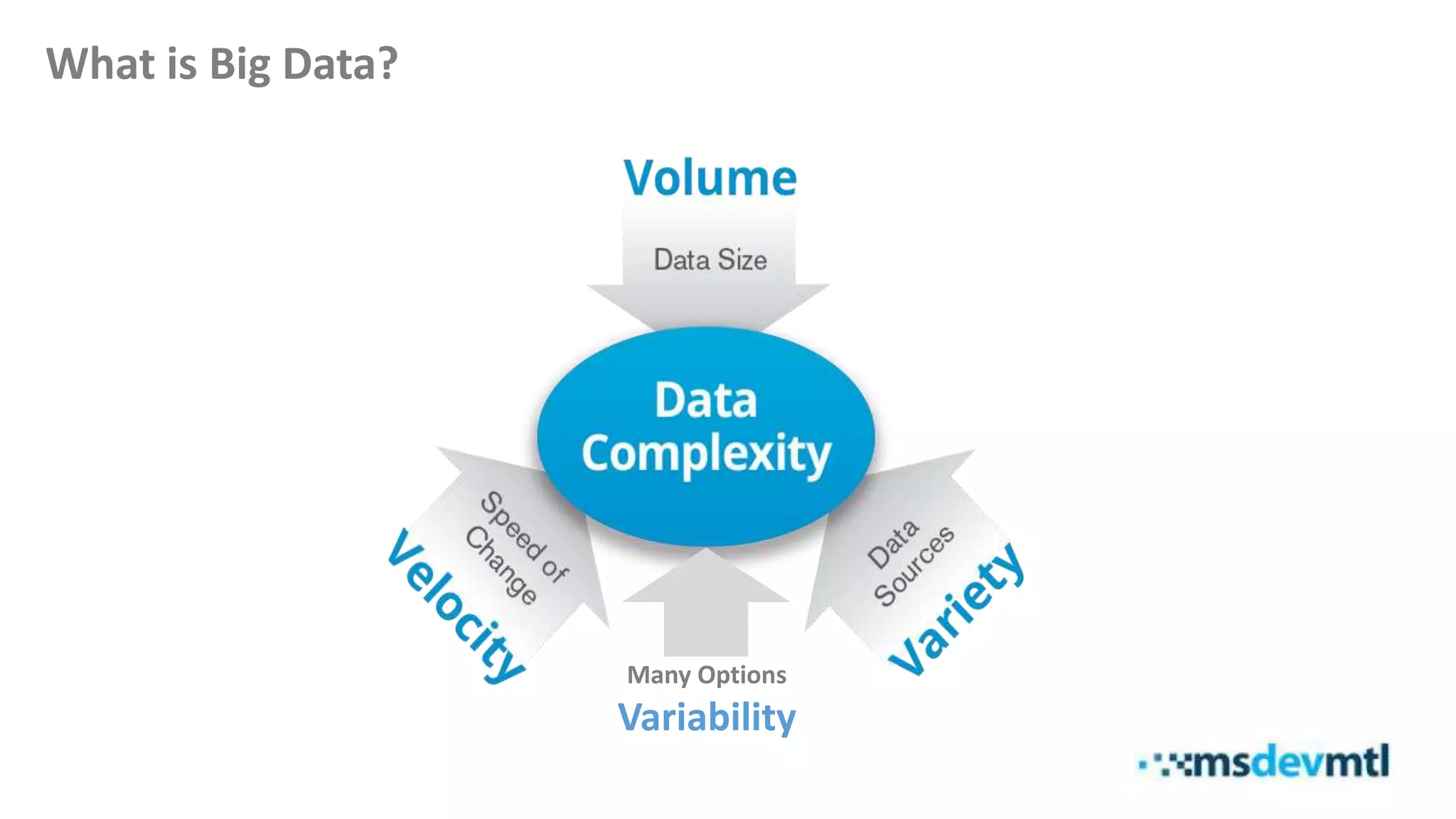
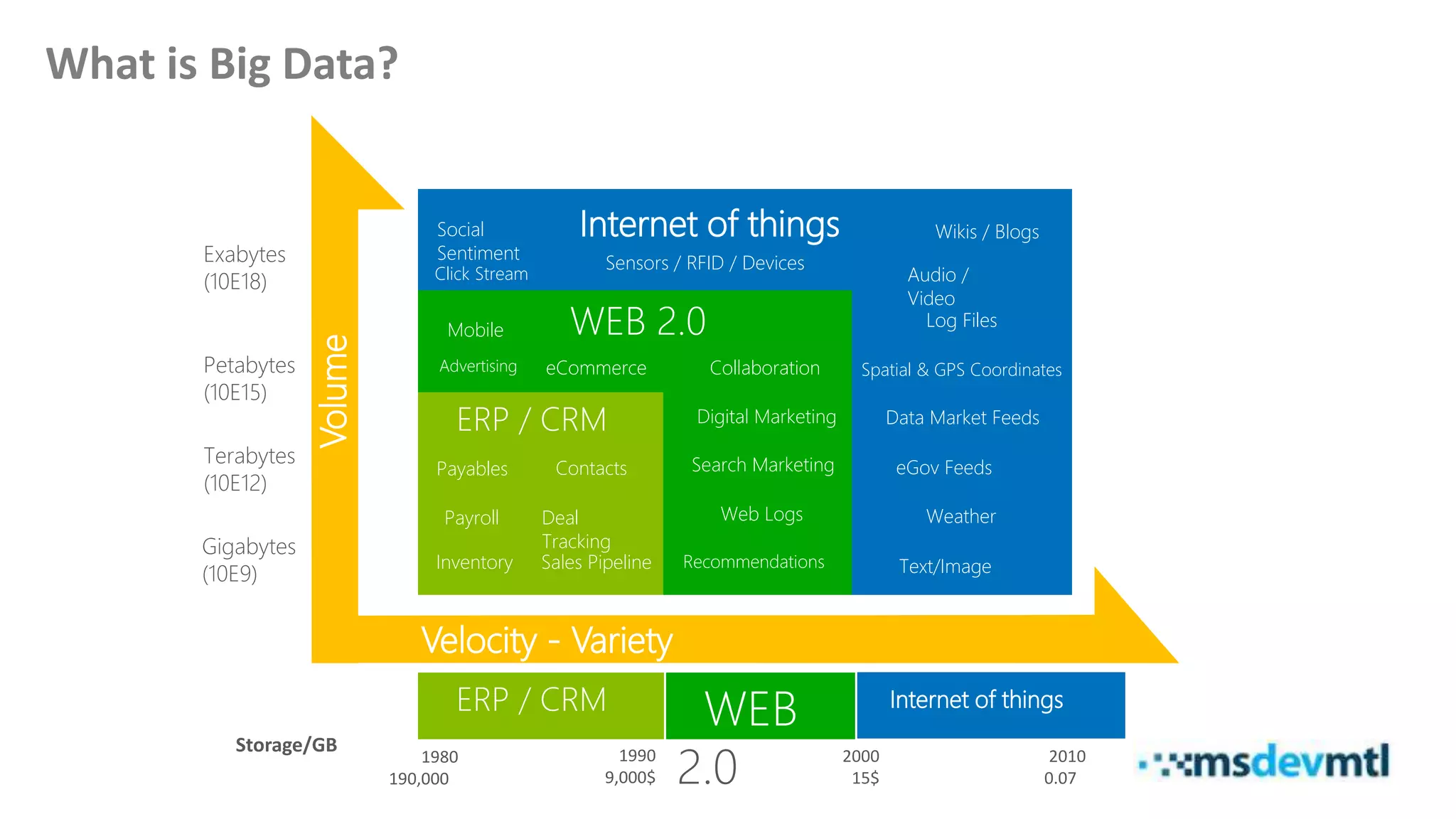
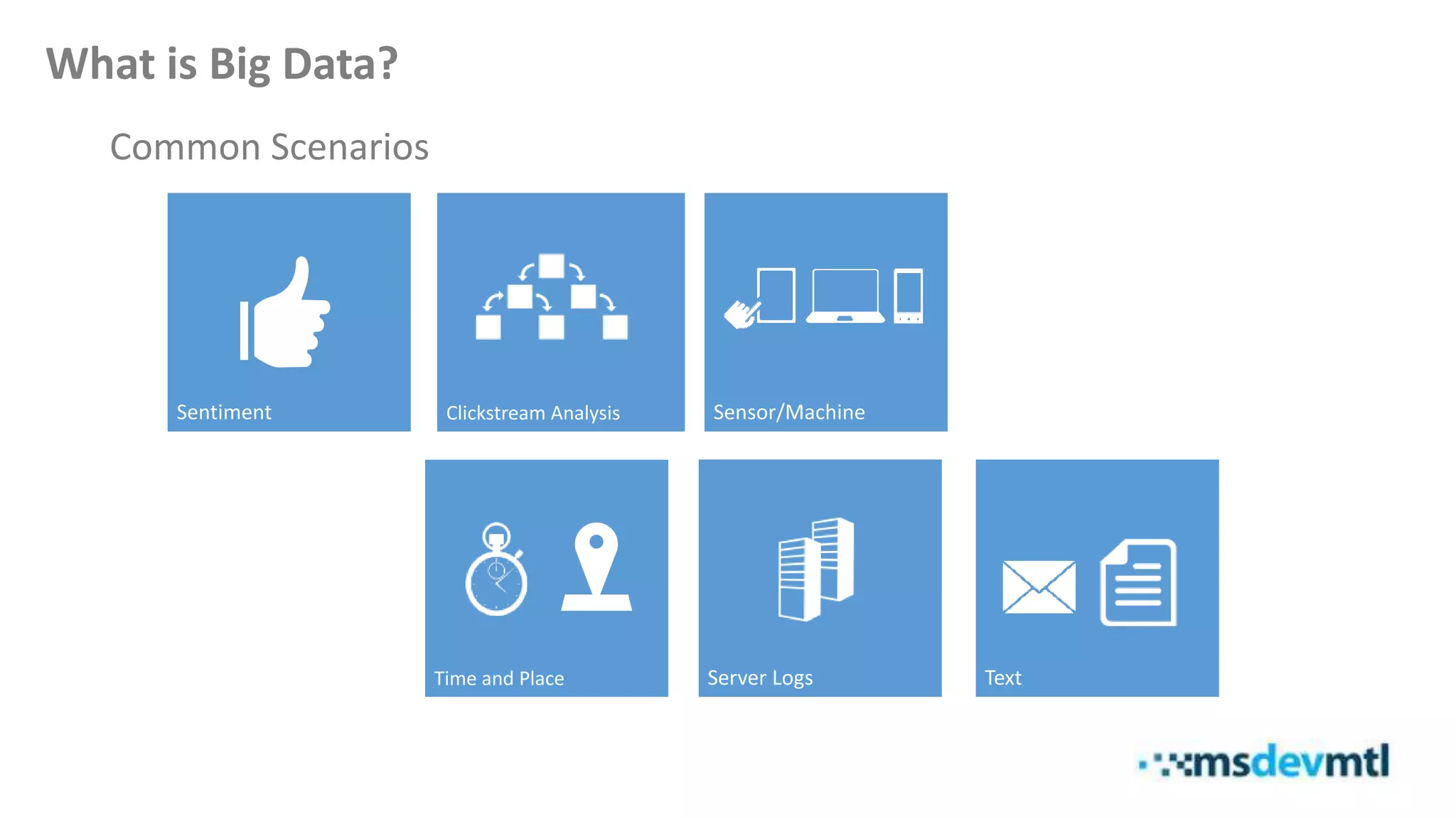
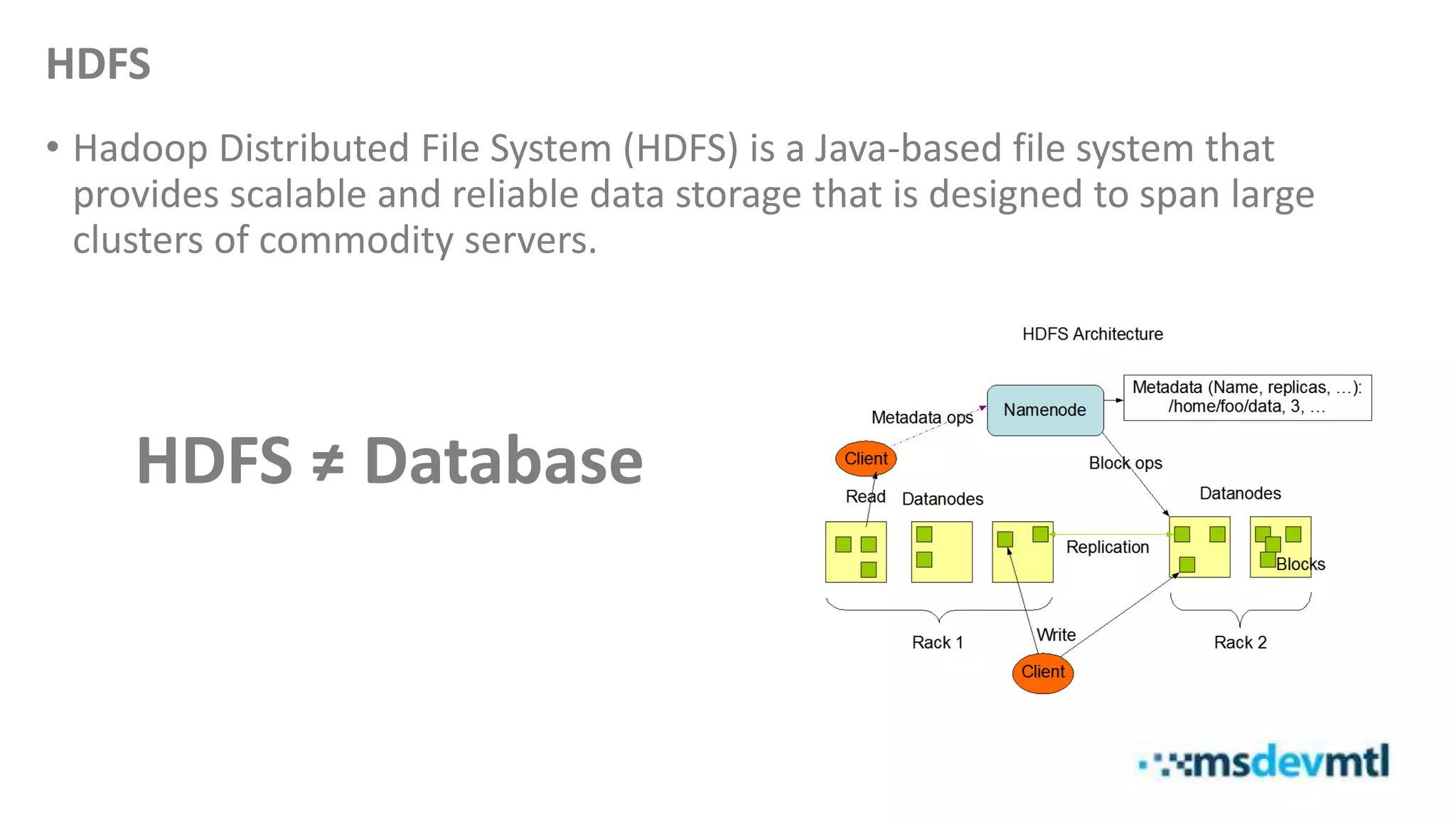
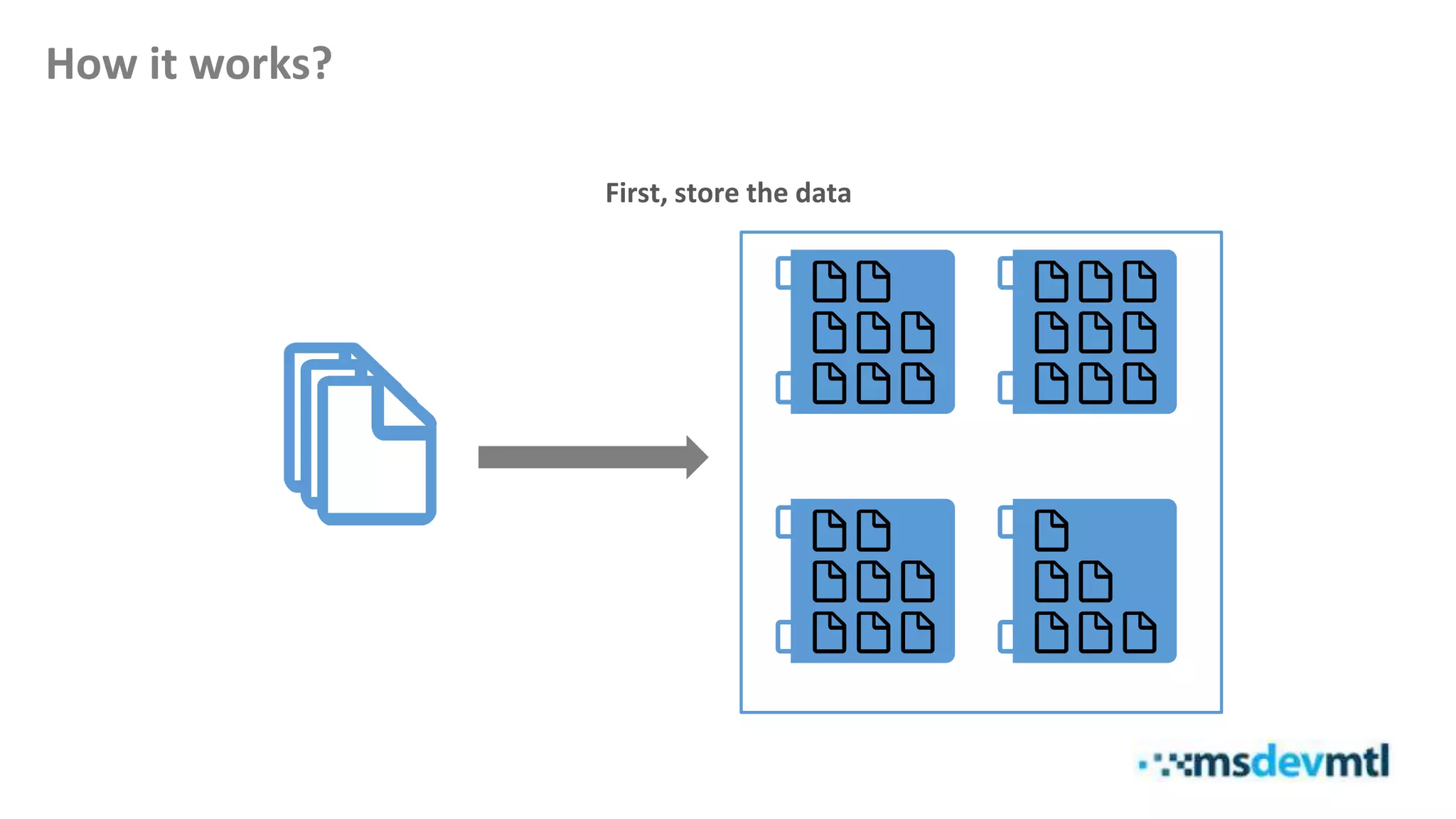
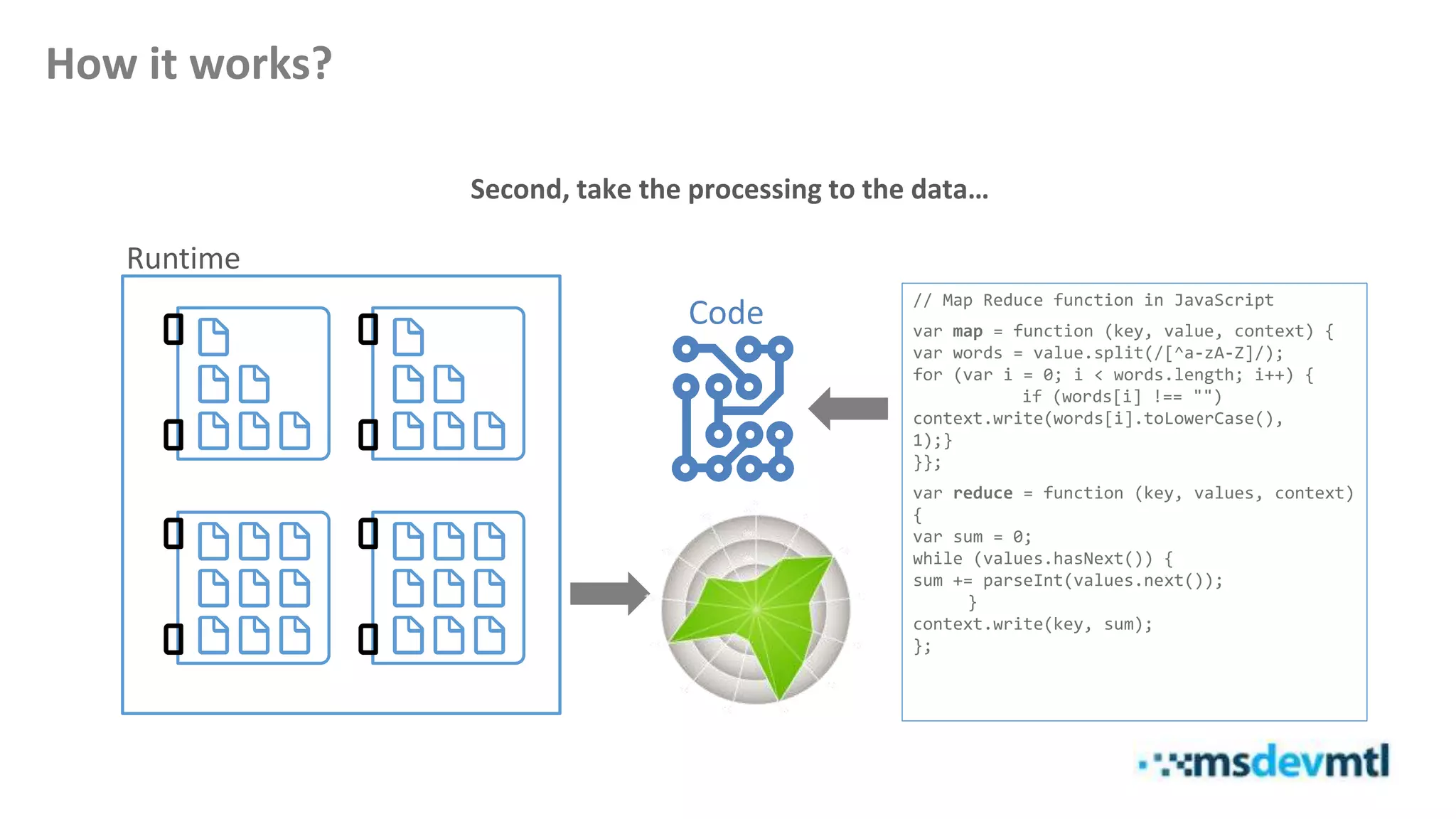
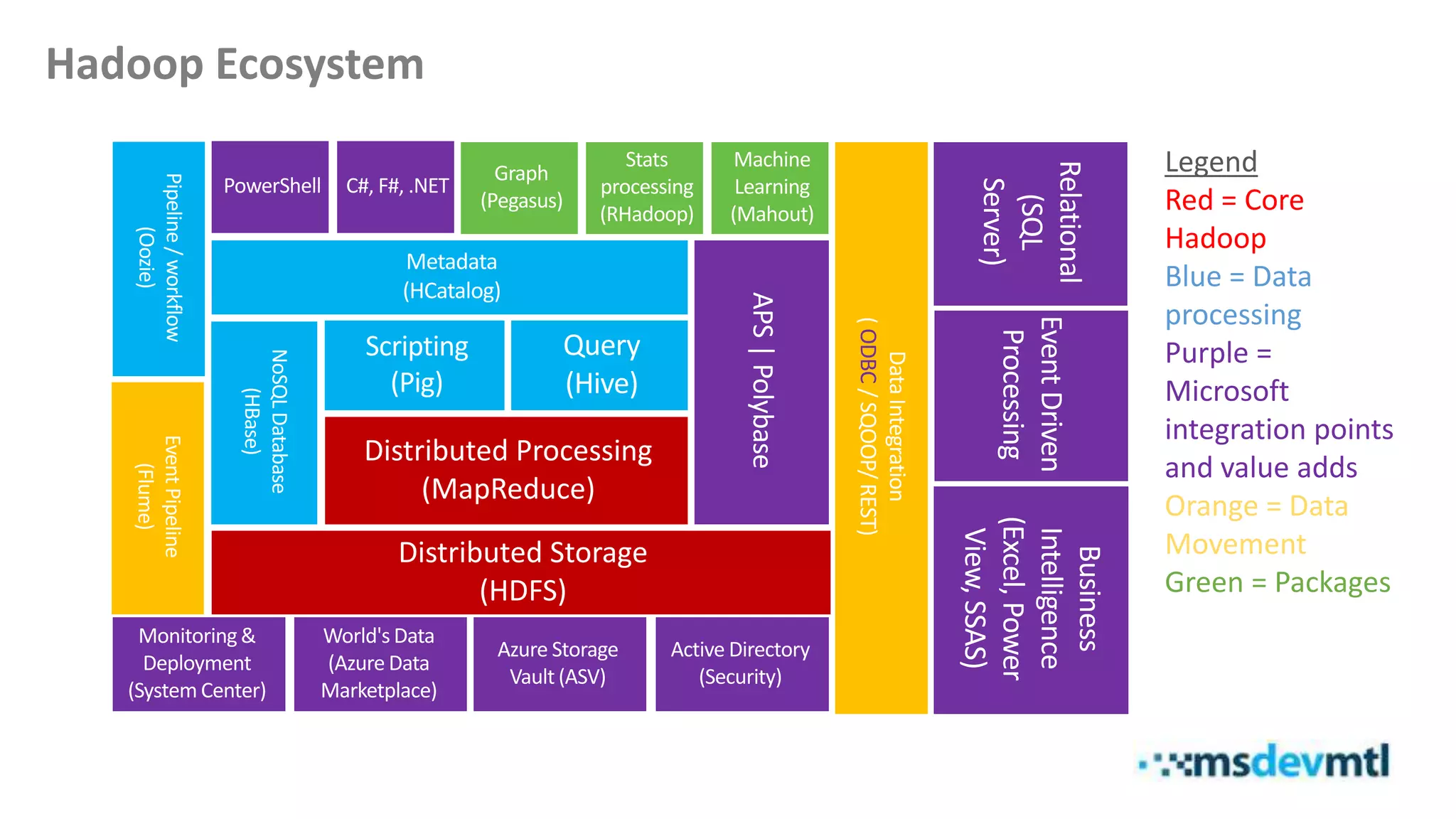
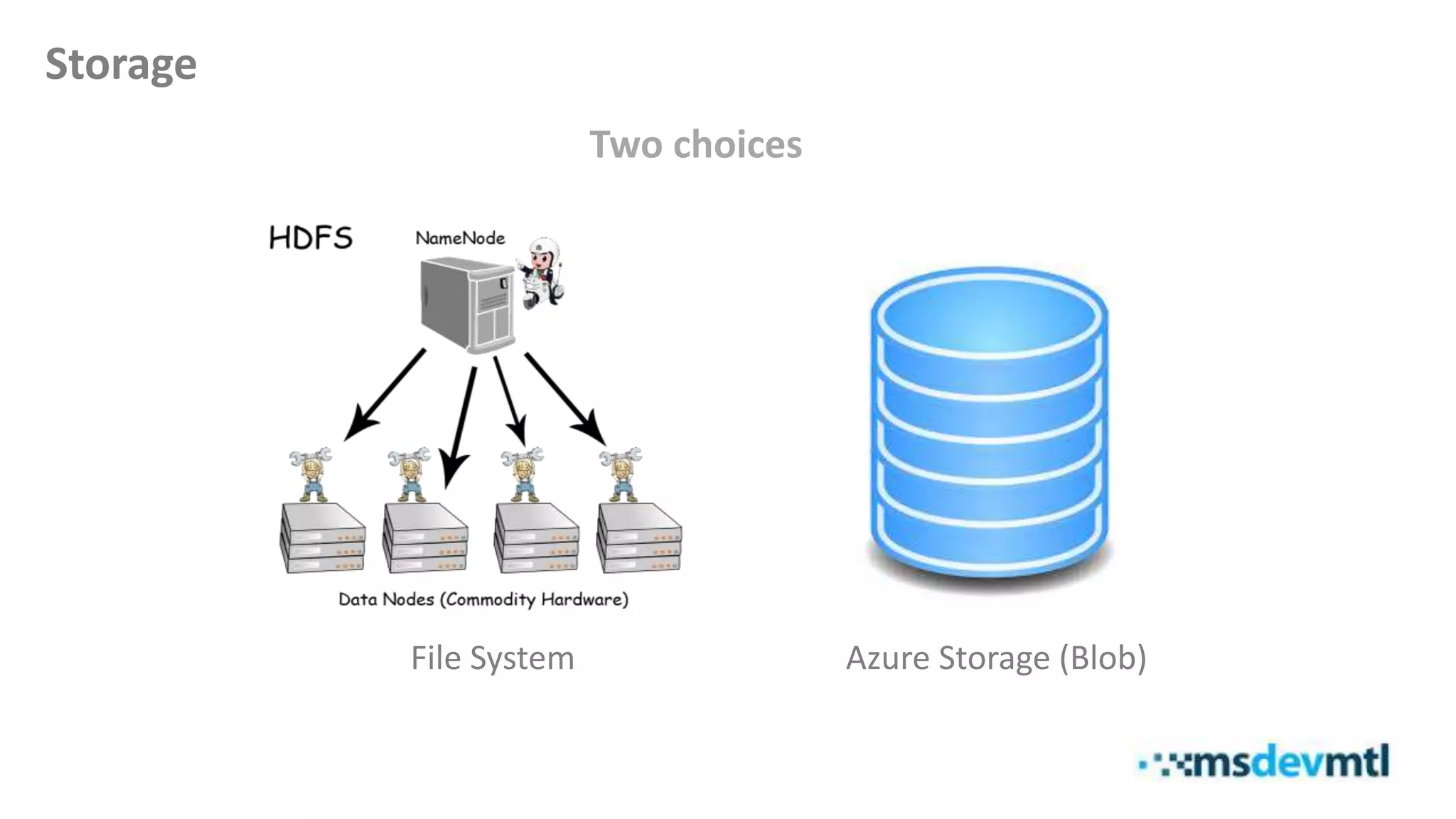
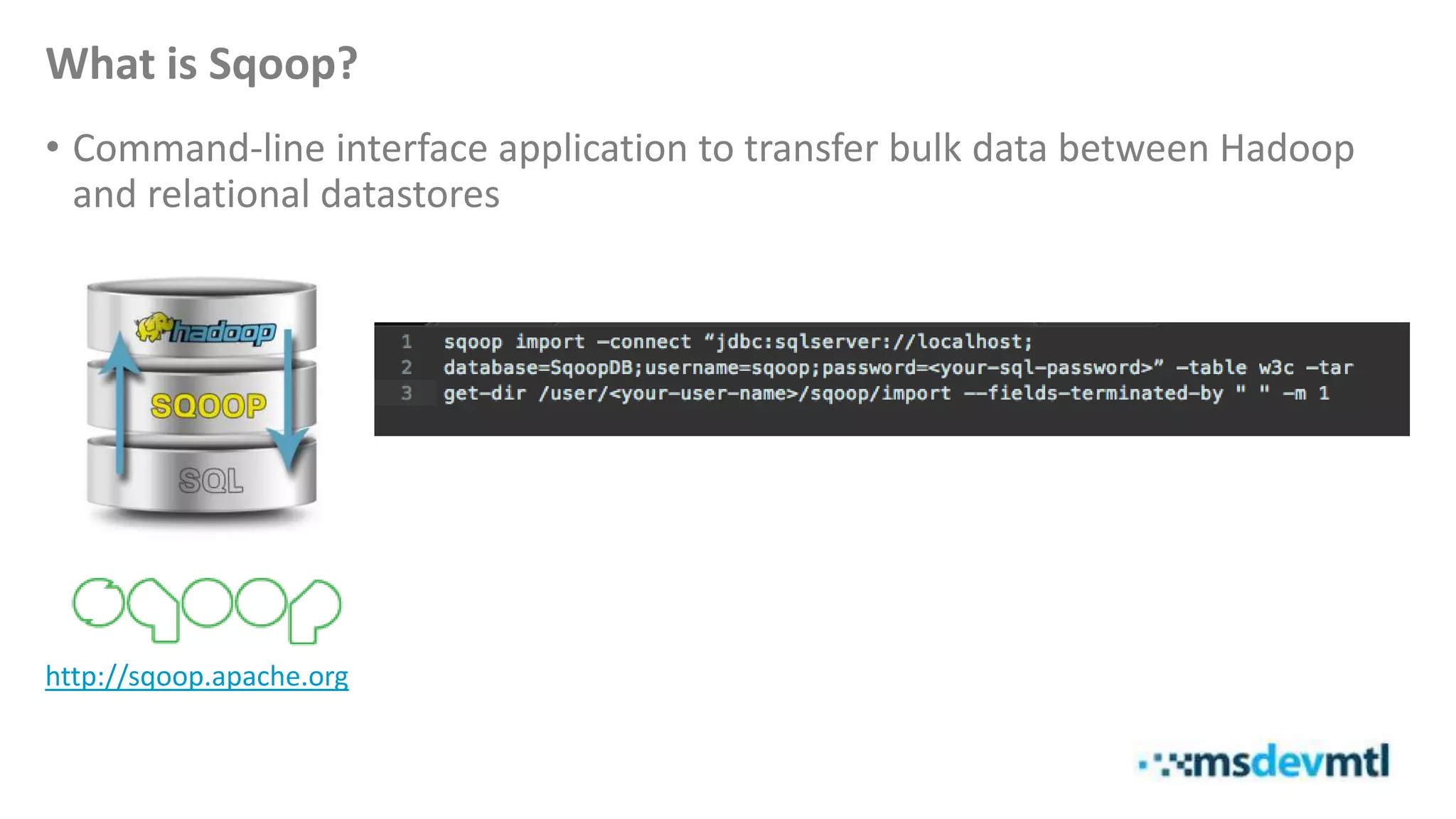
This document introduces HDInsight and big data concepts, detailing the Apache Hadoop ecosystem and its components such as HDFS and MapReduce. It discusses the role of HDInsight as a Hadoop-based service on Microsoft Azure, highlighting its scalability and integration with various tools. Additionally, it provides resources for further learning and insight into working with HDInsight clusters.







































![[Azureビッグデータ関連サービスとHortonworks勉強会] Azure HDInsight](https://cdn.slidesharecdn.com/ss_thumbnails/20160719hortonworksmeetuphdinsight-160721074805-thumbnail.jpg?width=640&height=640&fit=bounds)




























![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)













