Downloaded 10 times






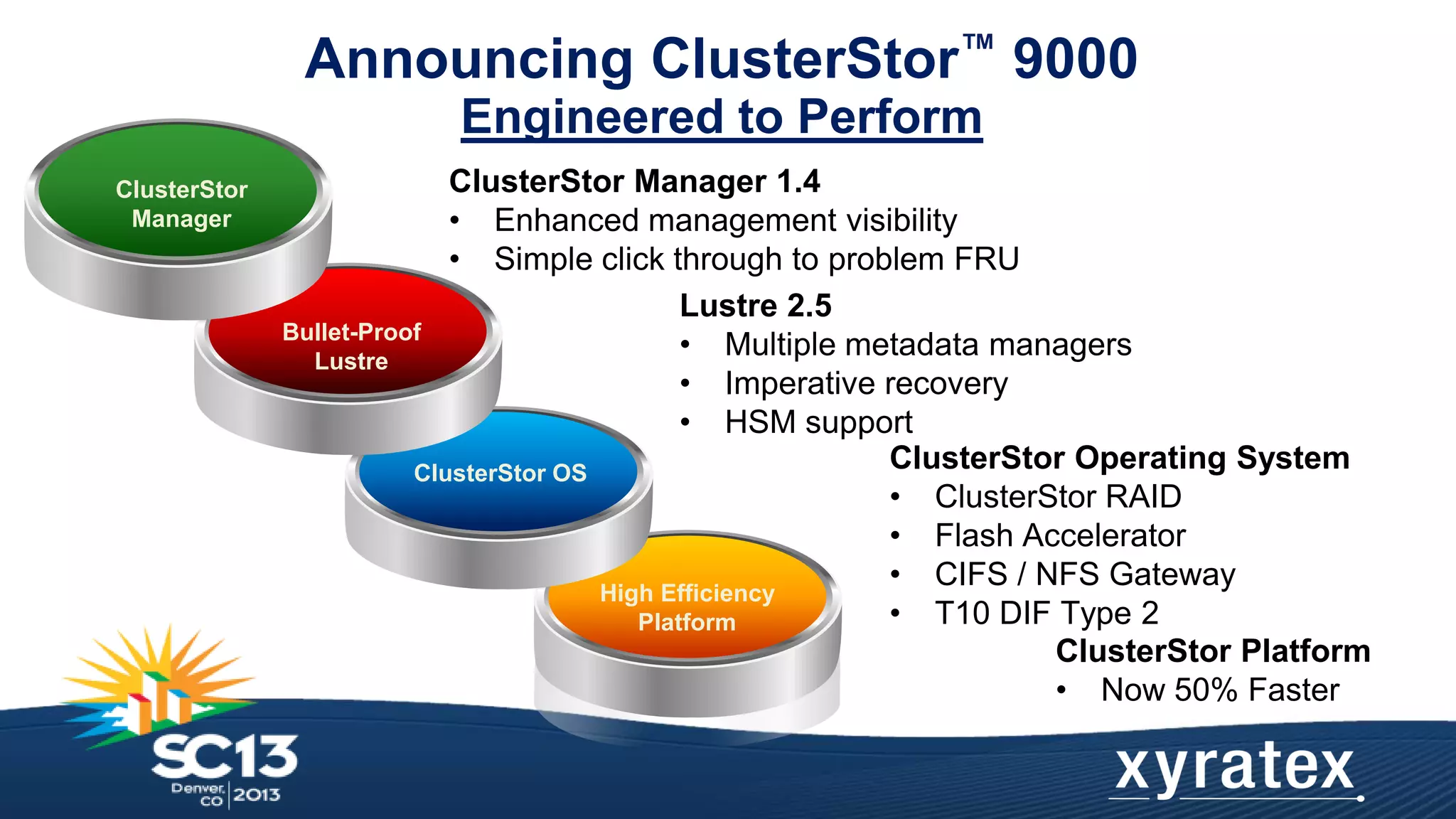





This document introduces new features of the ClusterStor 9000 storage solution that improve productivity for high-performance computing (HPC) and big data workloads. The key updates include a 50% performance increase over previous generations, new reliability features like ClusterStor RAID and T10 data integrity, and efficiency gains from technologies like flash acceleration and object storage consolidation. The ClusterStor 9000 is positioned as the engineered storage solution that delivers the fastest performance, most robust reliability, and highest efficiency to meet customer demands across industries like engineering, finance, and life sciences.







![[OpenStack Days Korea 2016] How open HW and SW drives telco infrastucture inn...](https://cdn.slidesharecdn.com/ss_thumbnails/03skt-160226163436-thumbnail.jpg?width=640&height=640&fit=bounds)


![[OpenStack Day in Korea 2015] Track 3-1 - OpenStack Storage Infrastructure & ...](https://cdn.slidesharecdn.com/ss_thumbnails/31-150213065505-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)







































































