Downloaded 33 times





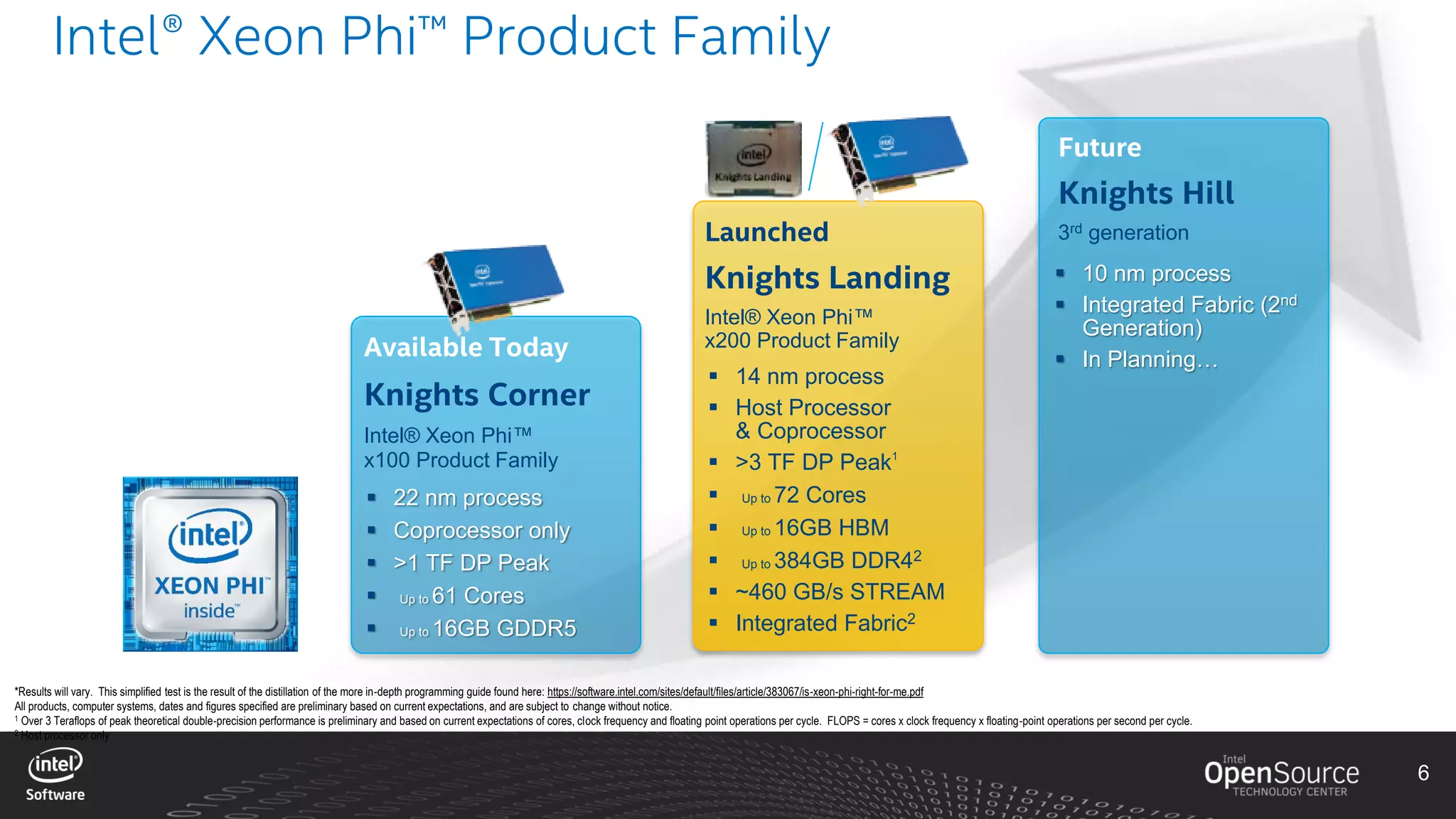
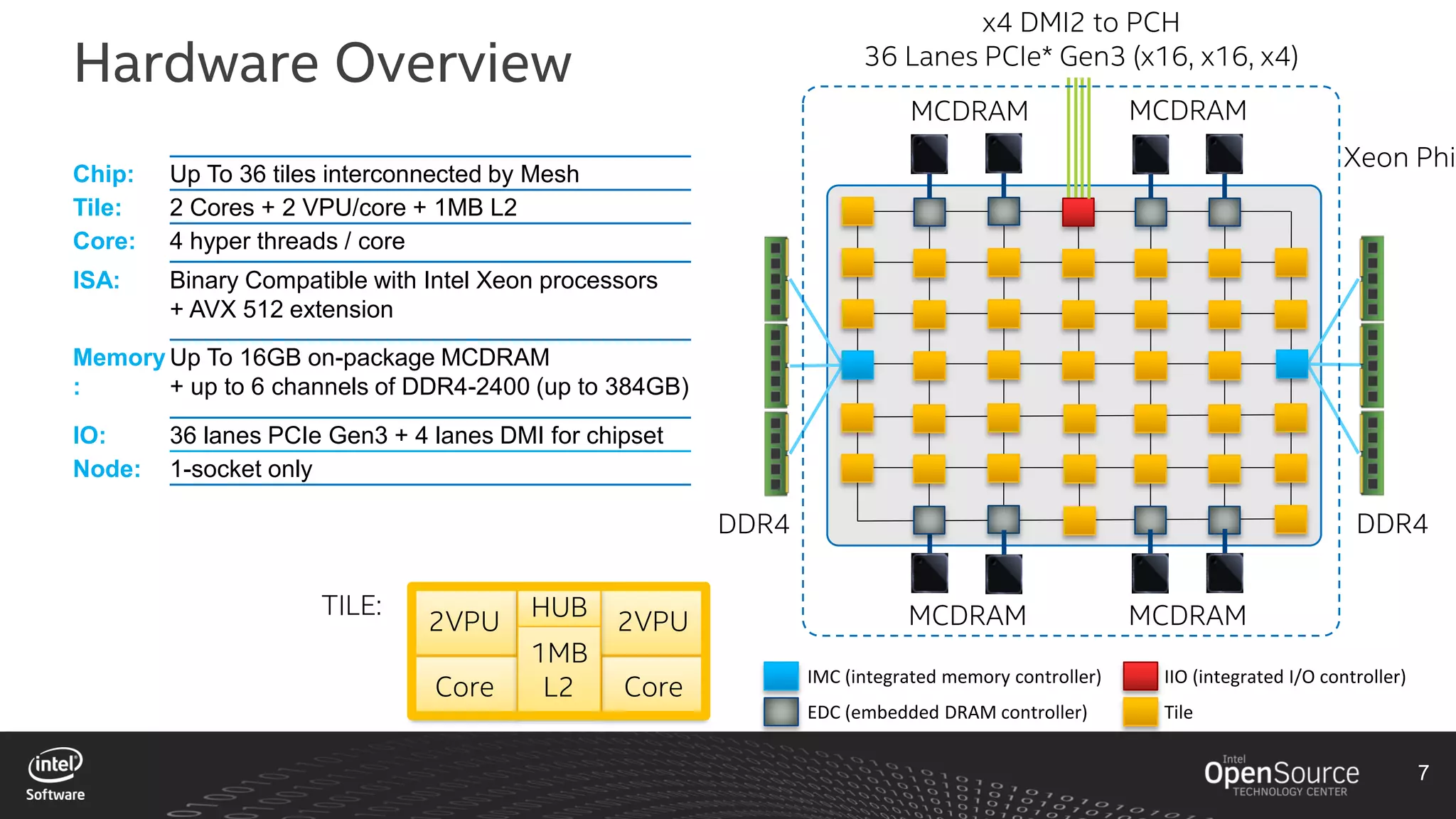
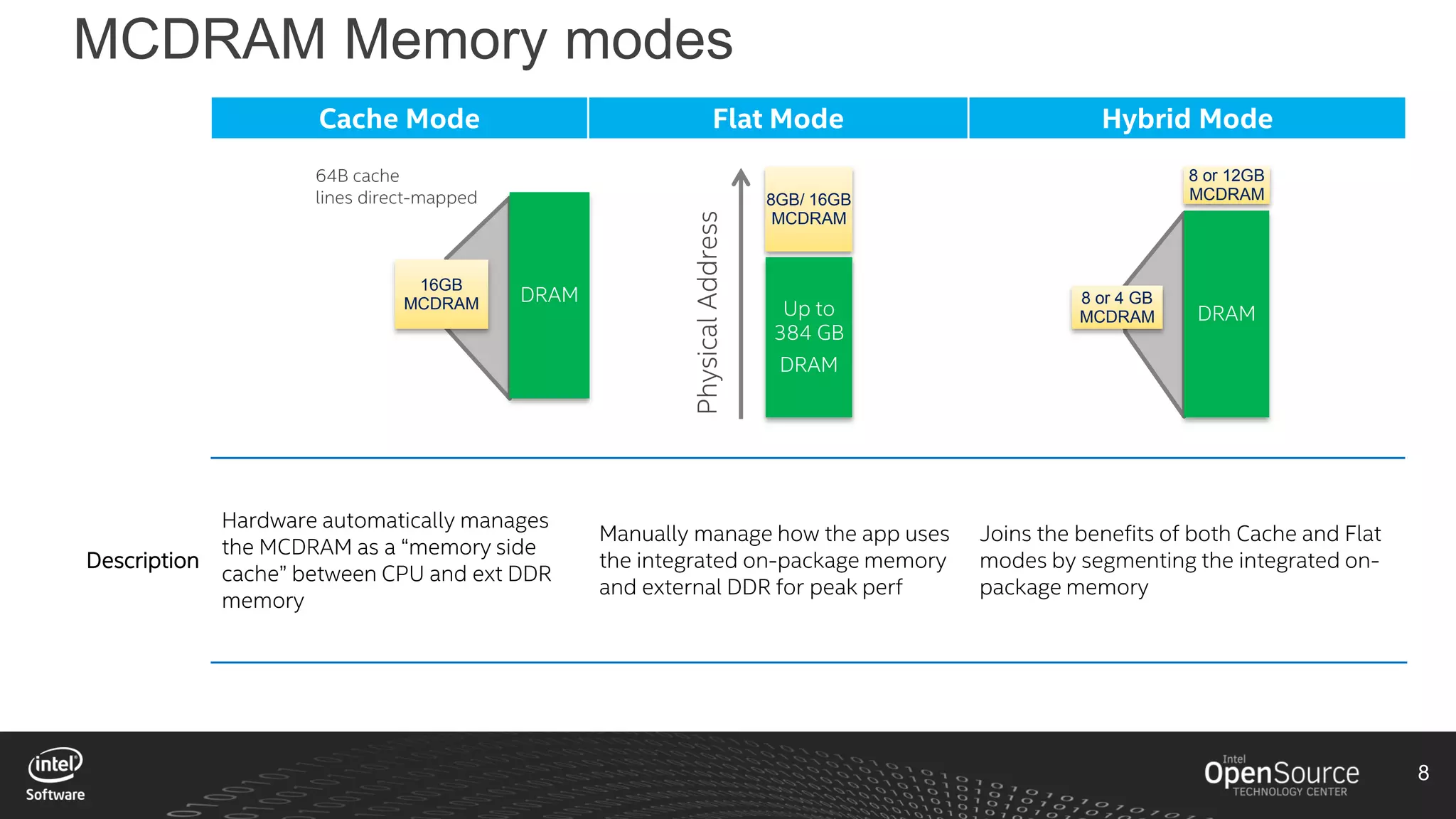
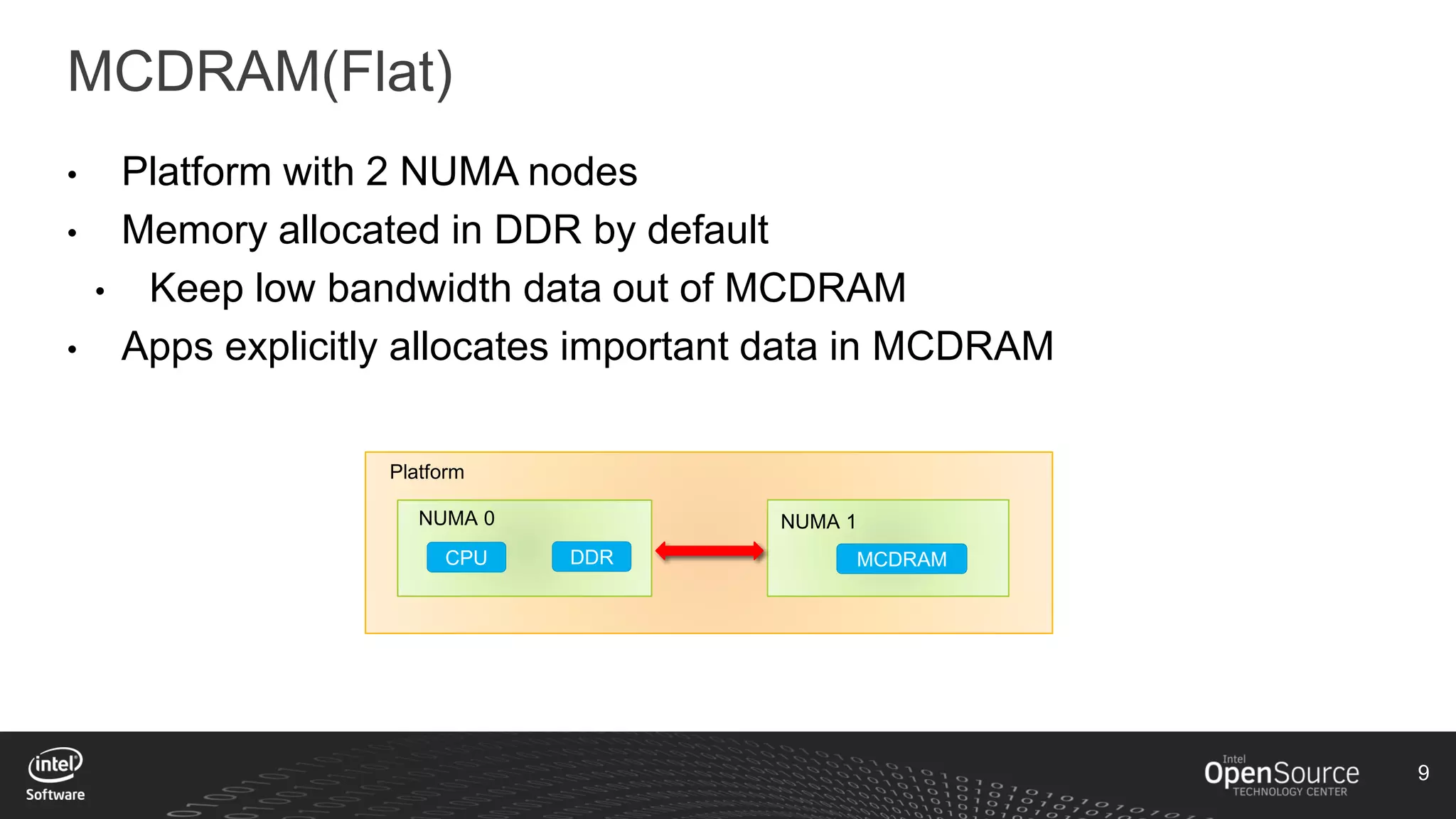





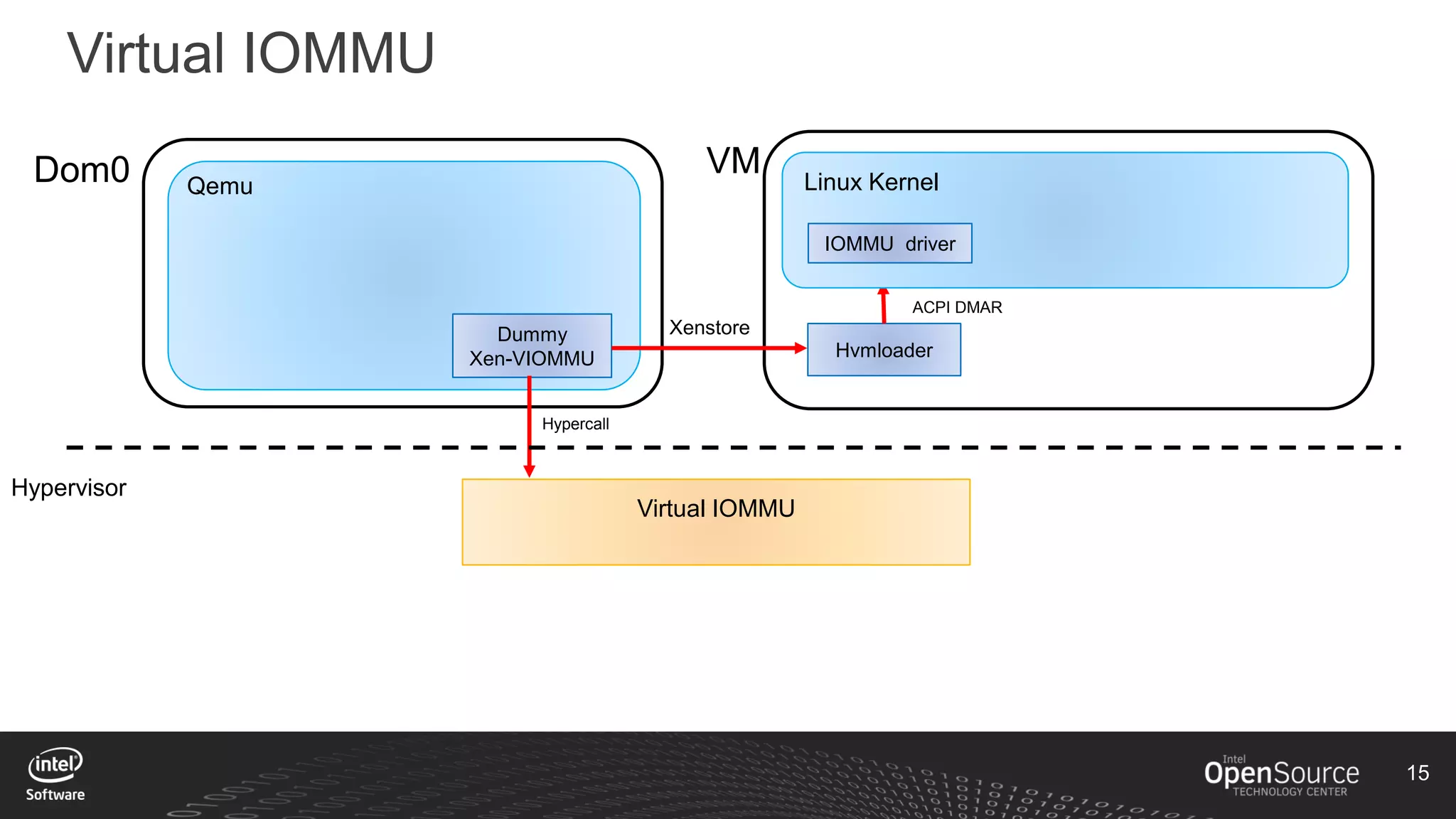
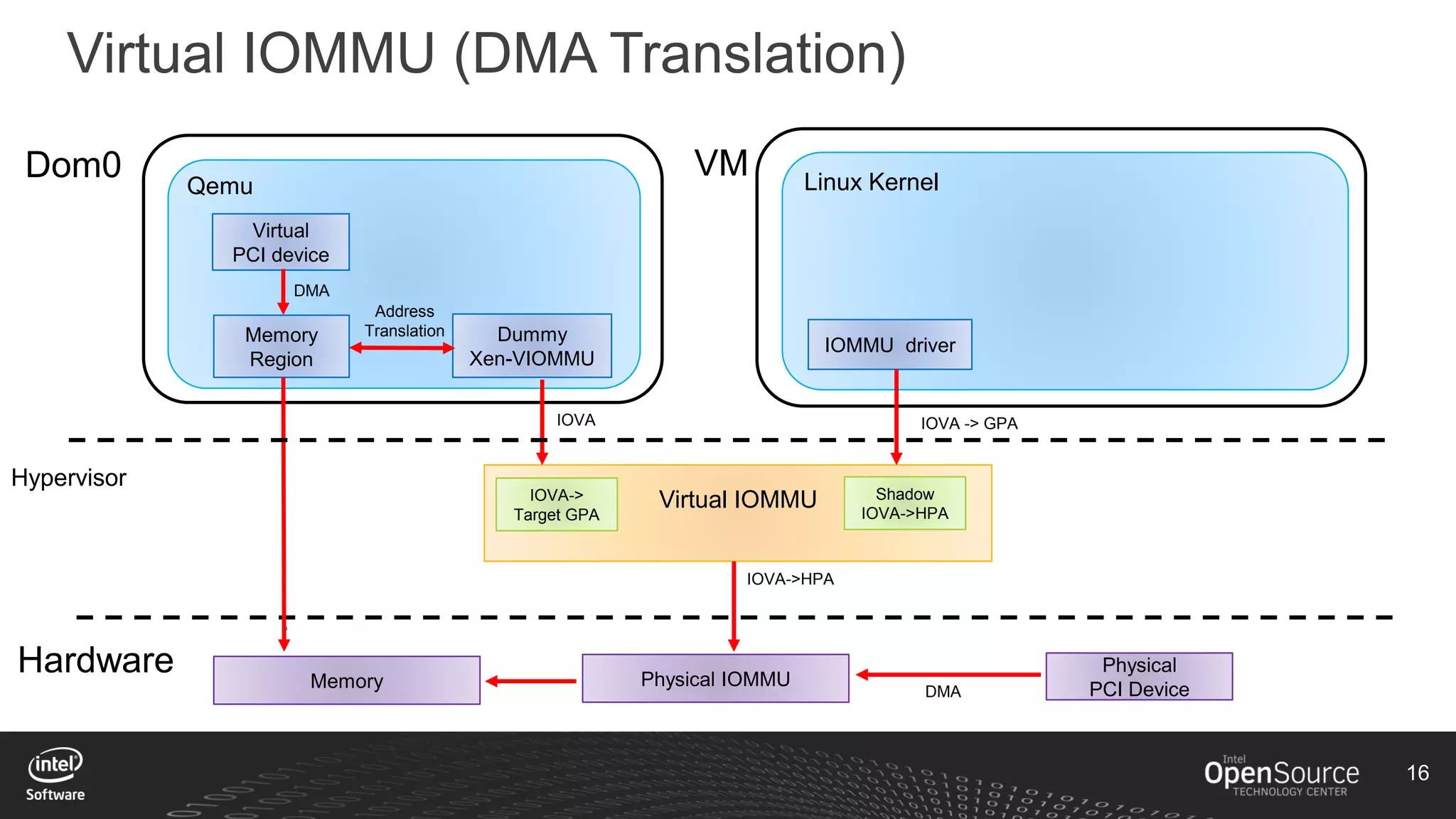
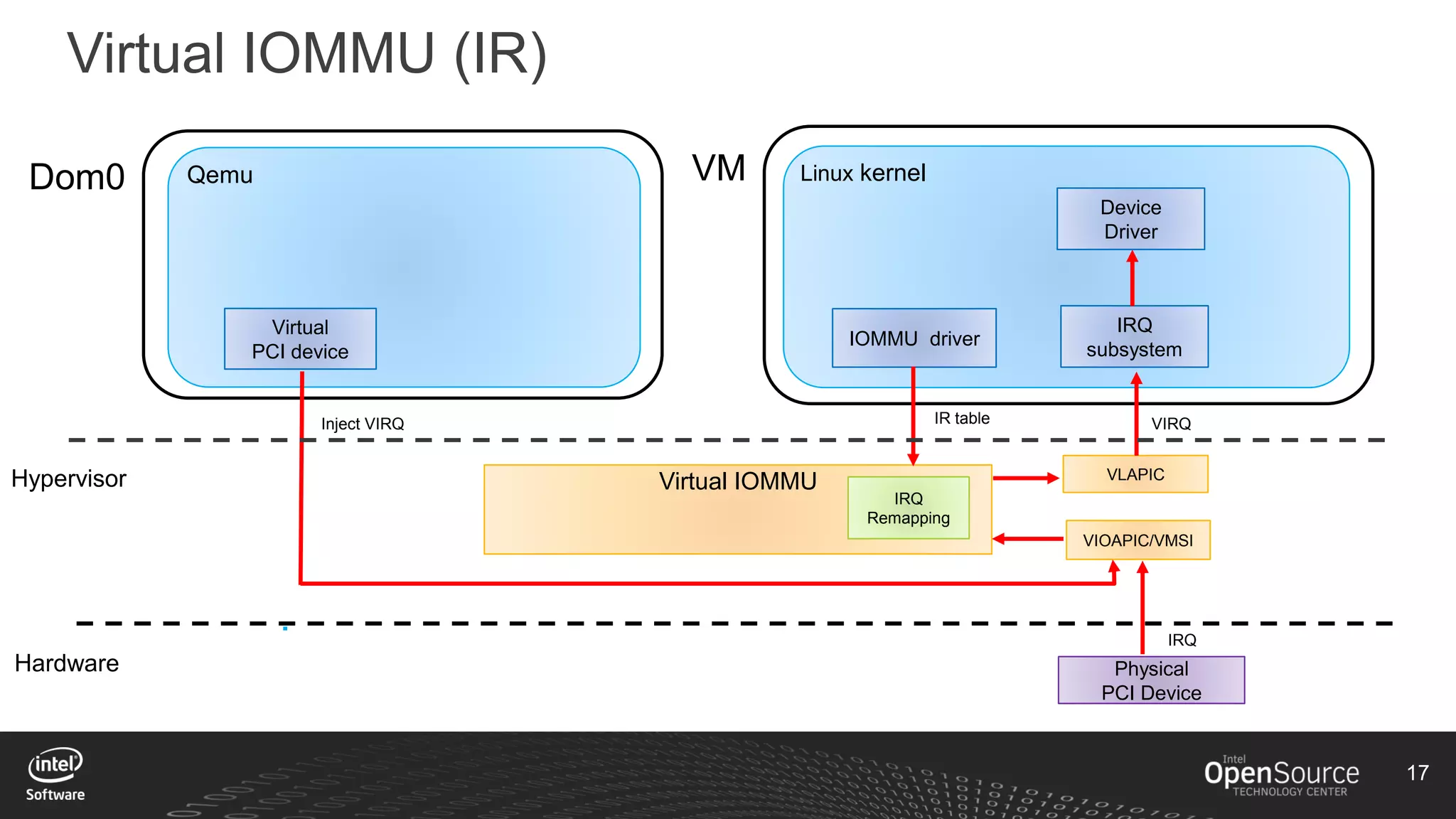

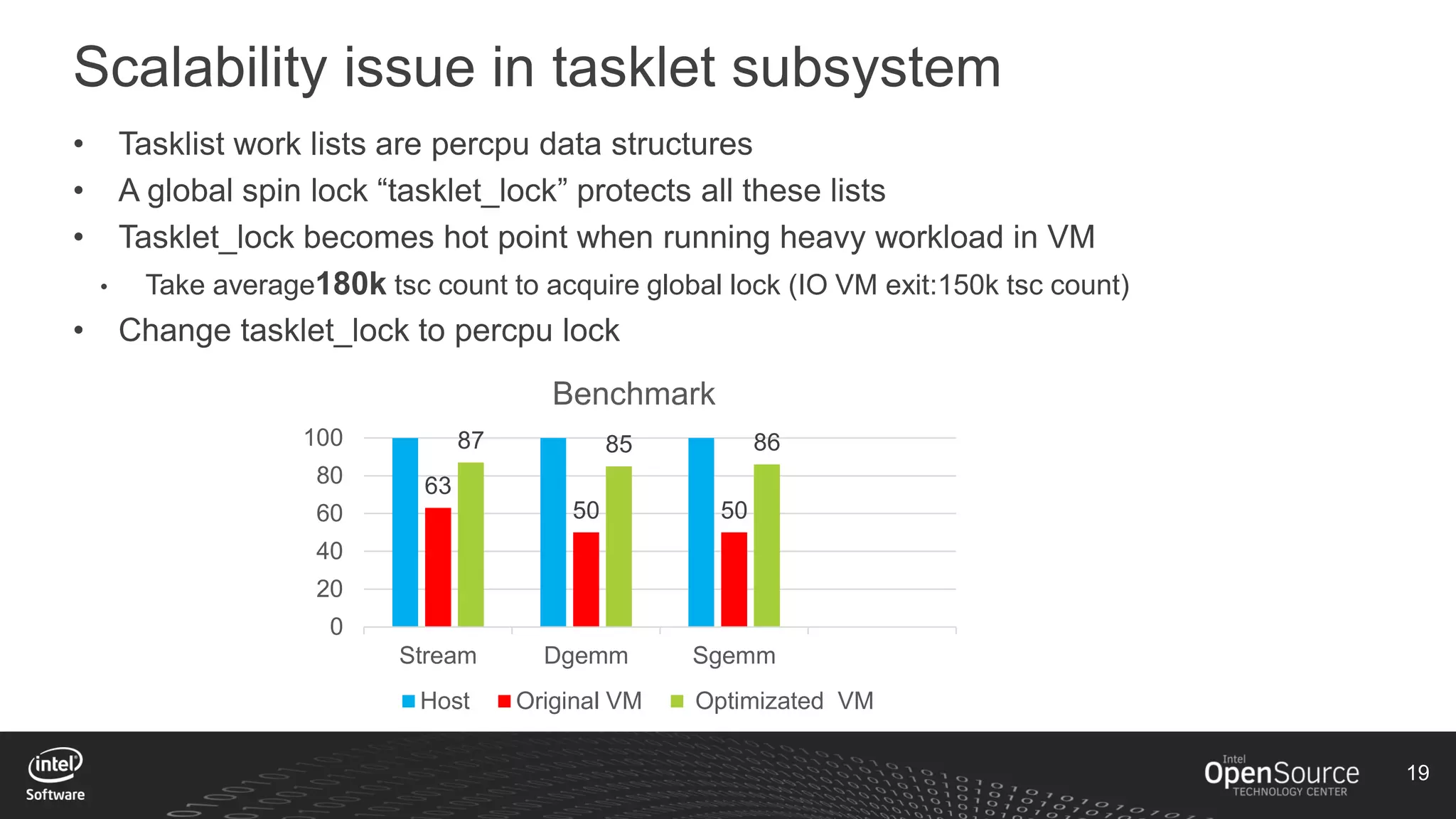


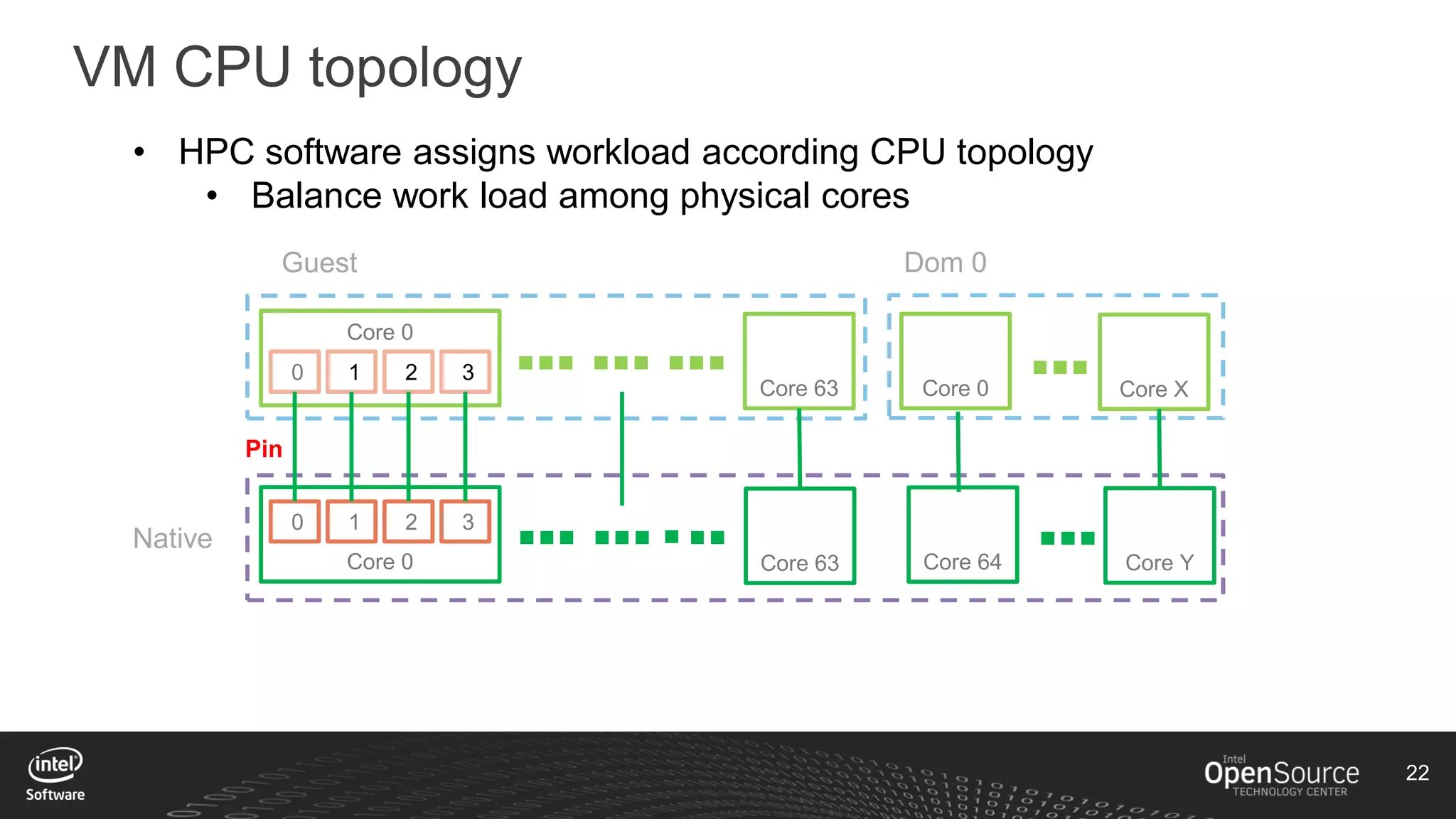
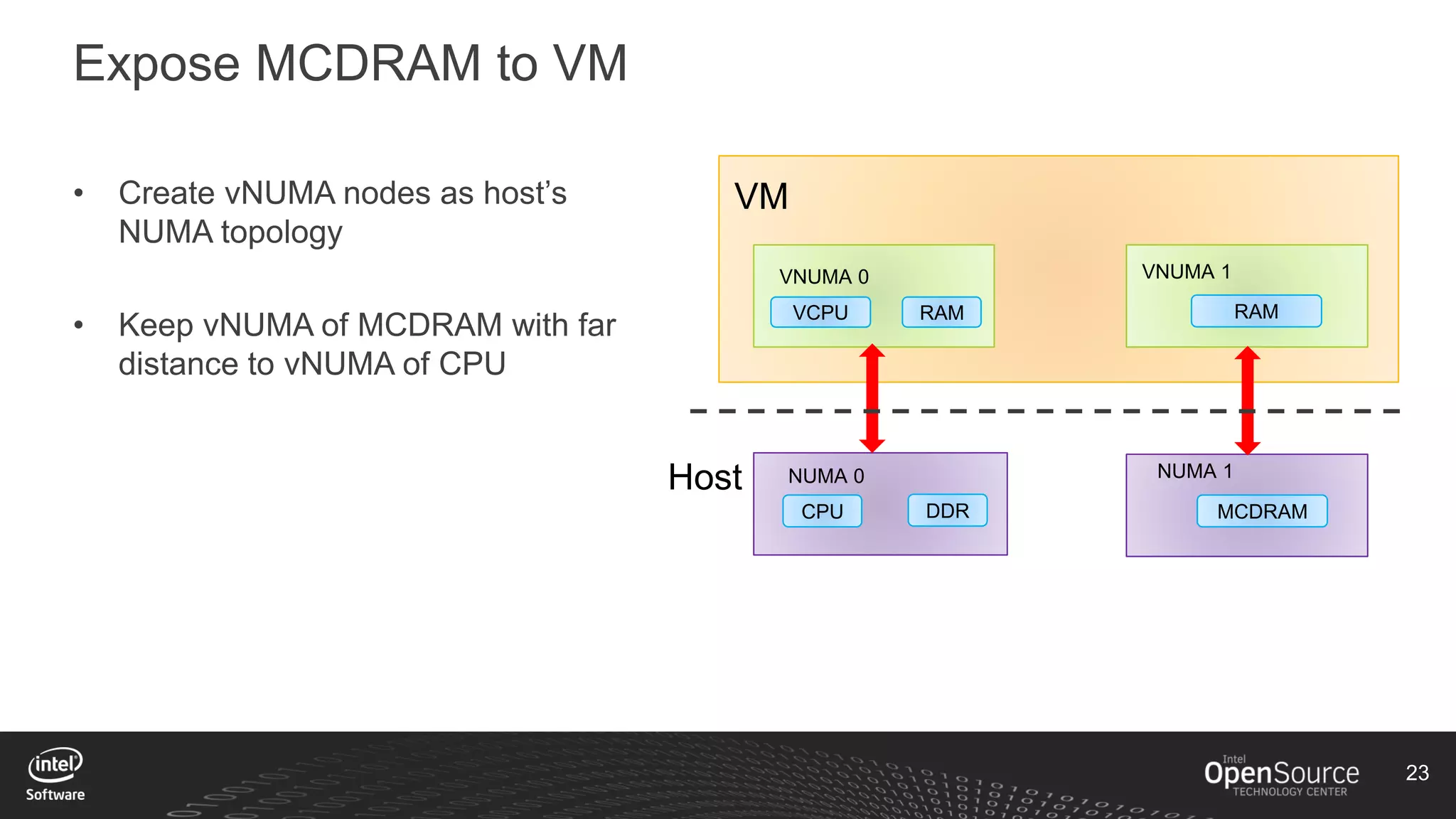
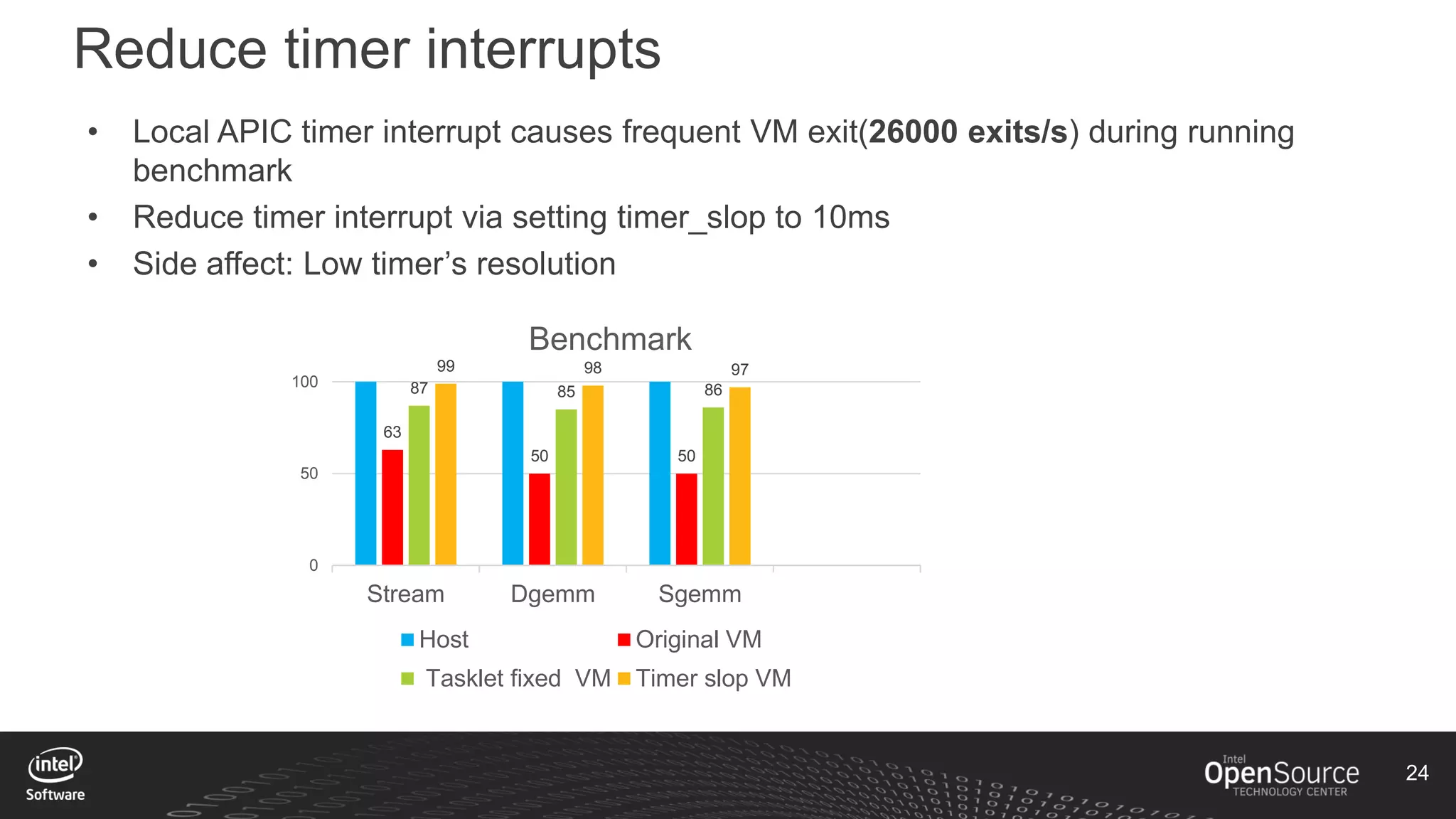





The document discusses high-performance virtualization for HPC (High-Performance Computing) on Xen, focusing on the Intel® Xeon Phi™ product family designed for cloud usage. It outlines challenges faced by Xen, such as support for more than 255 virtual CPUs and the need for virtual IOMMU support, as well as strategies to achieve high performance through optimizing compute resources. A call for action emphasizes the necessity of making changes in Xen to improve virtualization capabilities and performance.




























































![XPDDS19: [ARM] OP-TEE Mediator in Xen - Volodymyr Babchuk, EPAM Systems](https://cdn.slidesharecdn.com/ss_thumbnails/xendevsummit2019-babchuk-op-tee-190812095541-thumbnail.jpg?width=640&height=640&fit=bounds)



































