Downloaded 401 times





























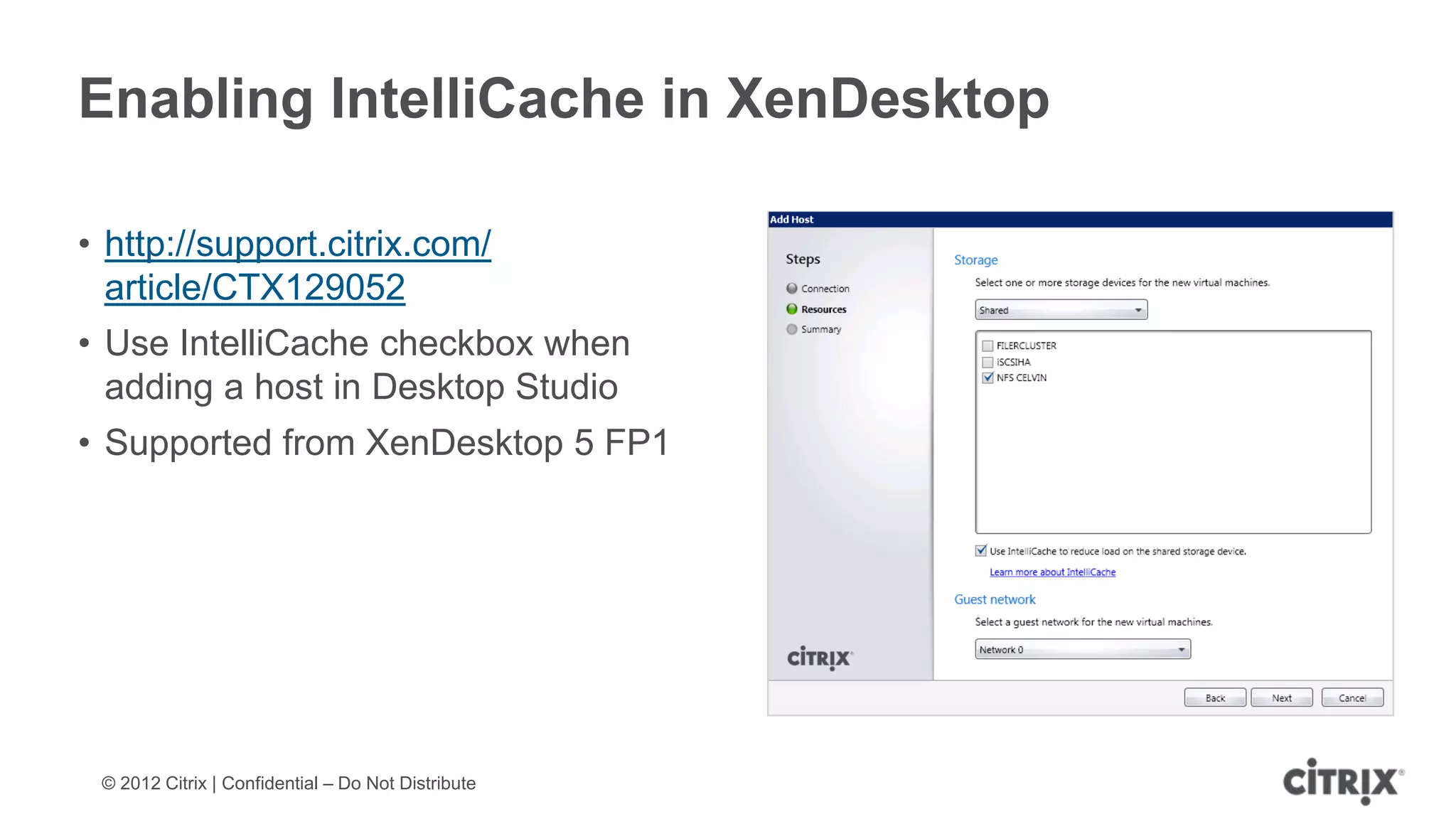
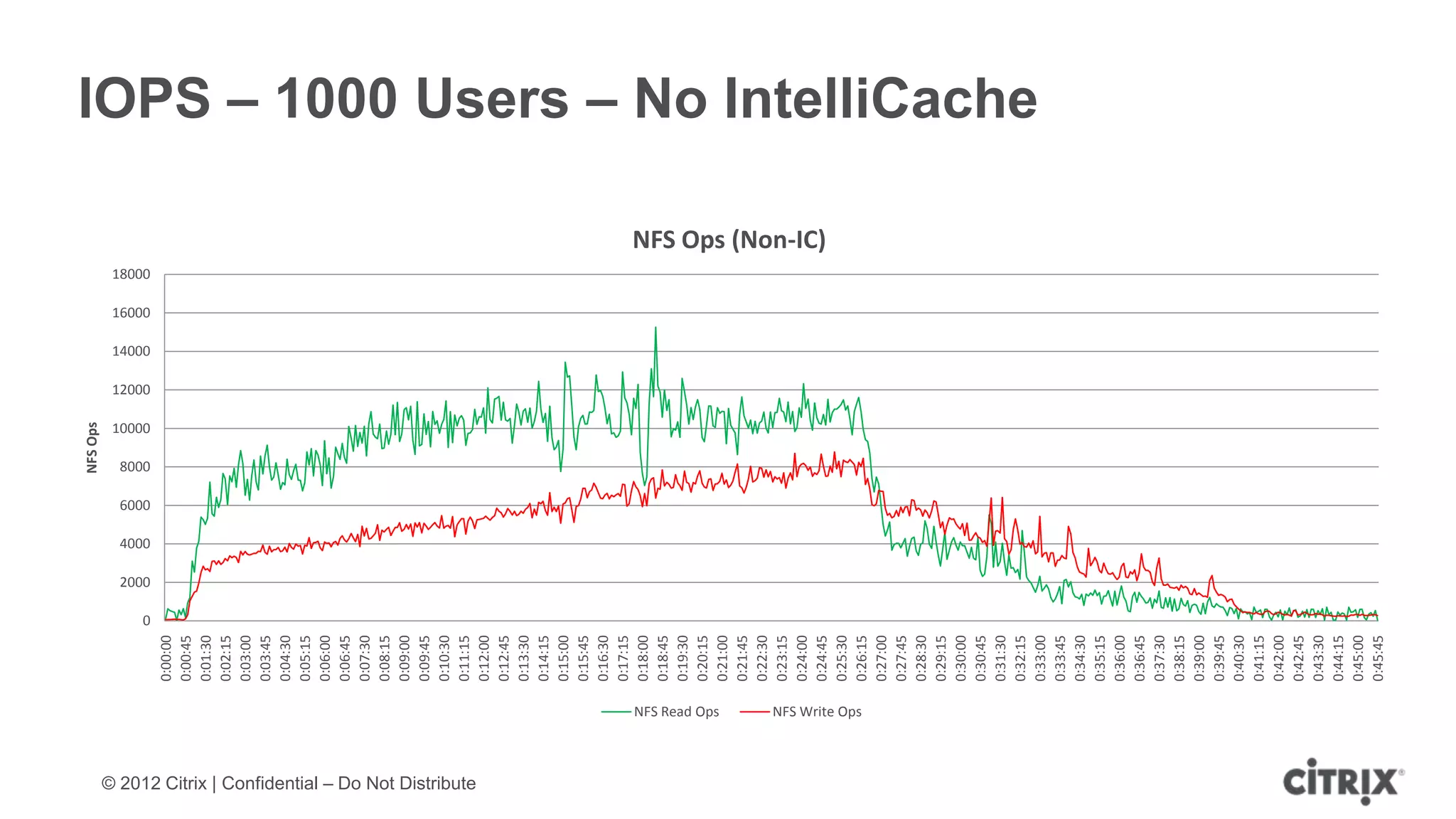
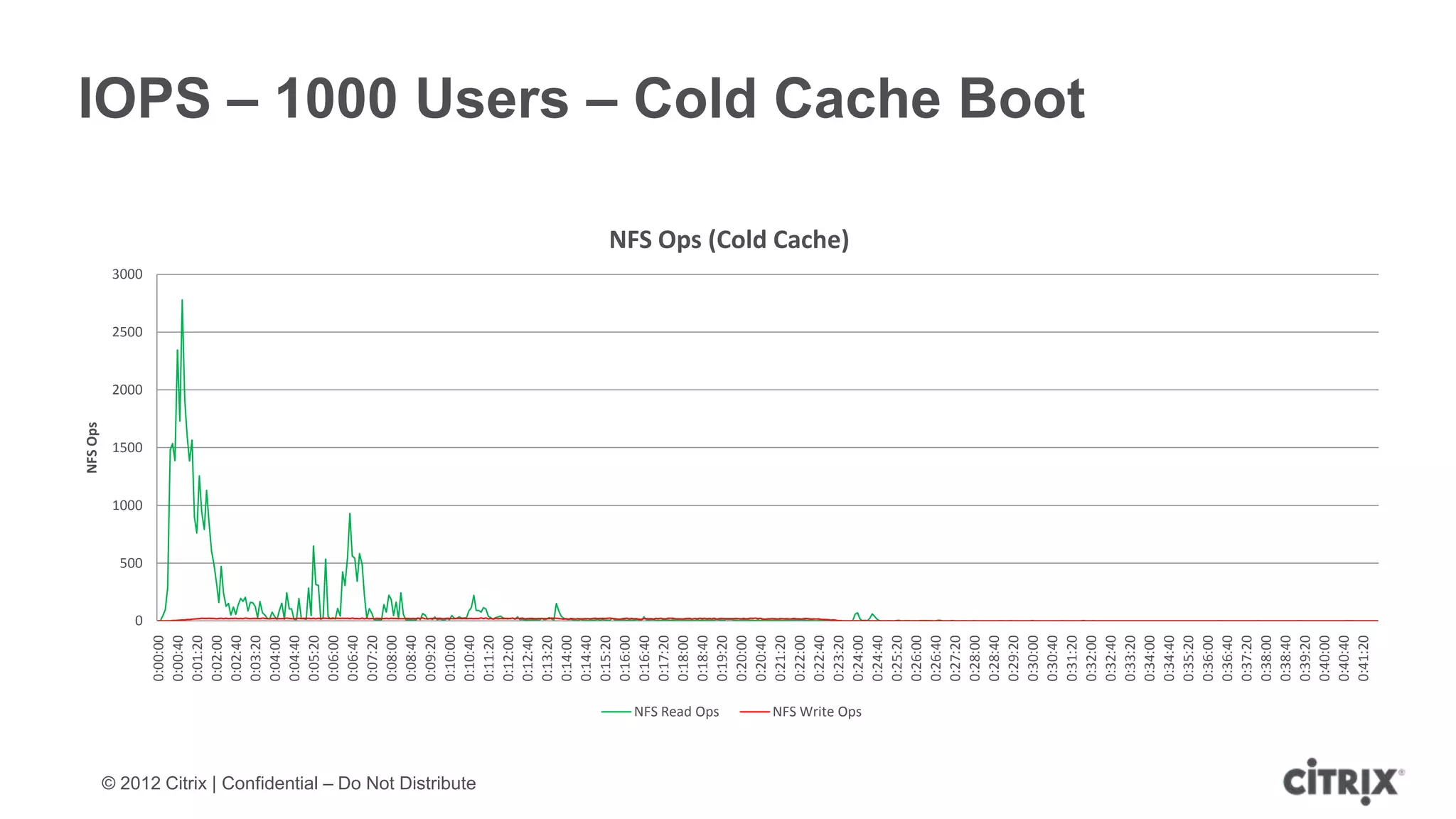
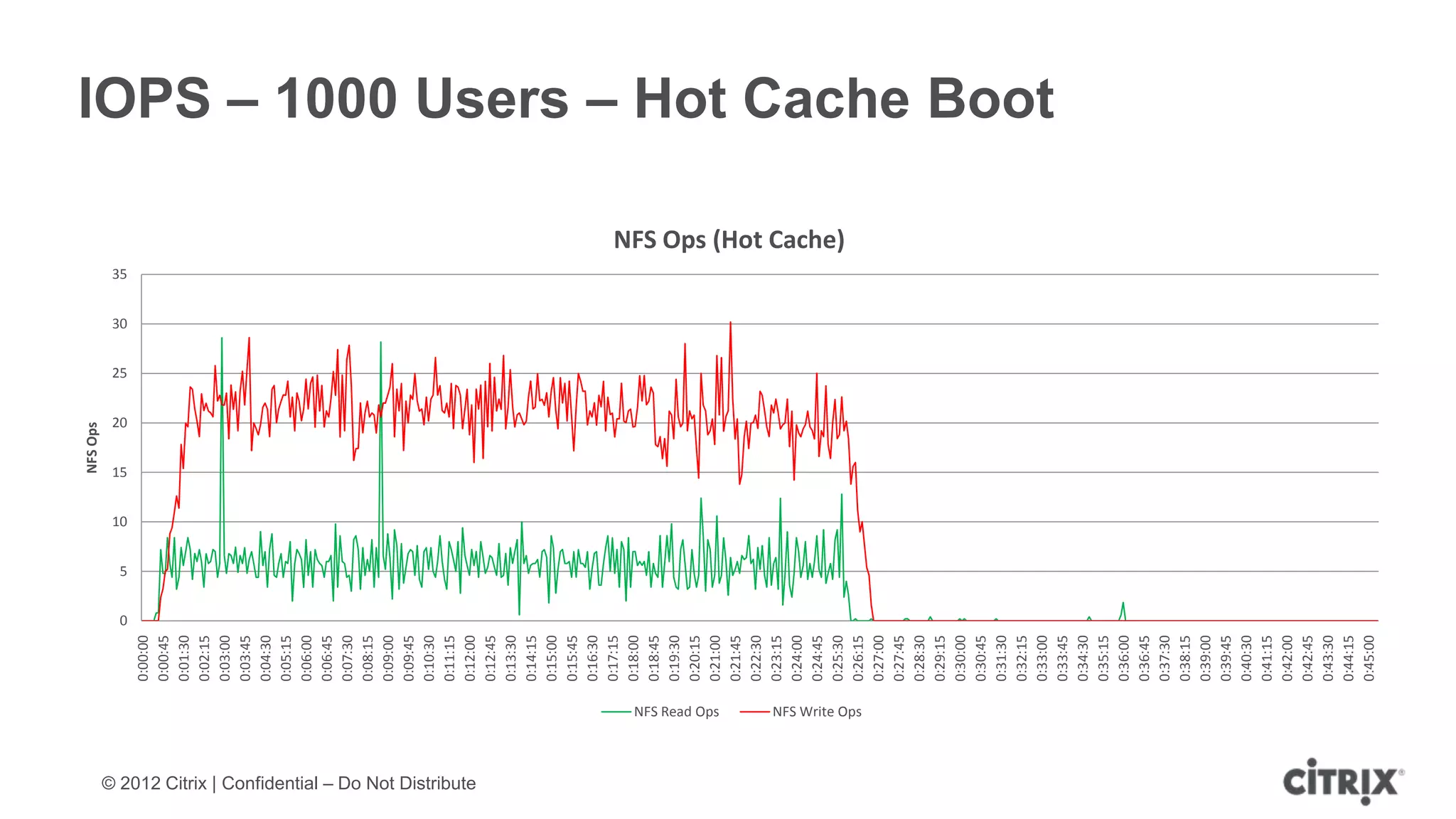
![Limitations of IntelliCache
• Best results achieved with local SSD drives
ᵒSAS and SATA supported, but spindled disks are slower
• XenMotion and WLB restrictions (pooled images)
• Best practice Local space sizing
ᵒExpecting 50% cache usage per user + daily log off
ᵒ[real size master image] + #[users per server] * [size master image] * 0,5
ᵒCache disk may vary according to VM lifecycle definition (reboot cycle)
© 2012 Citrix | Confidential – Do Not Distribute](https://image.slidesharecdn.com/xenserver6-1technicalsalespresentation-130109121511-phpapp02/75/Xen-server-6-1-technical-sales-presentation-58-2048.jpg)


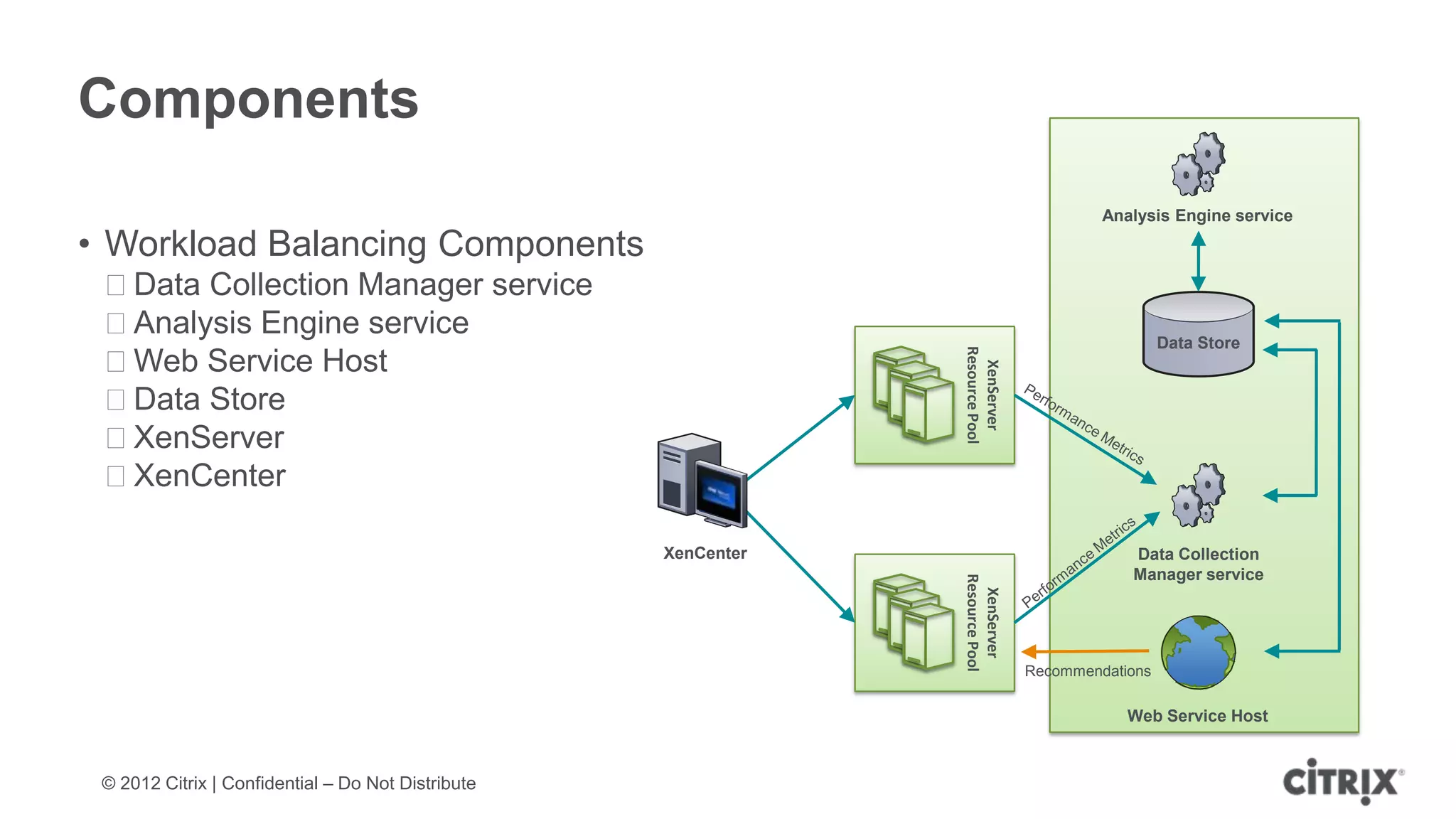






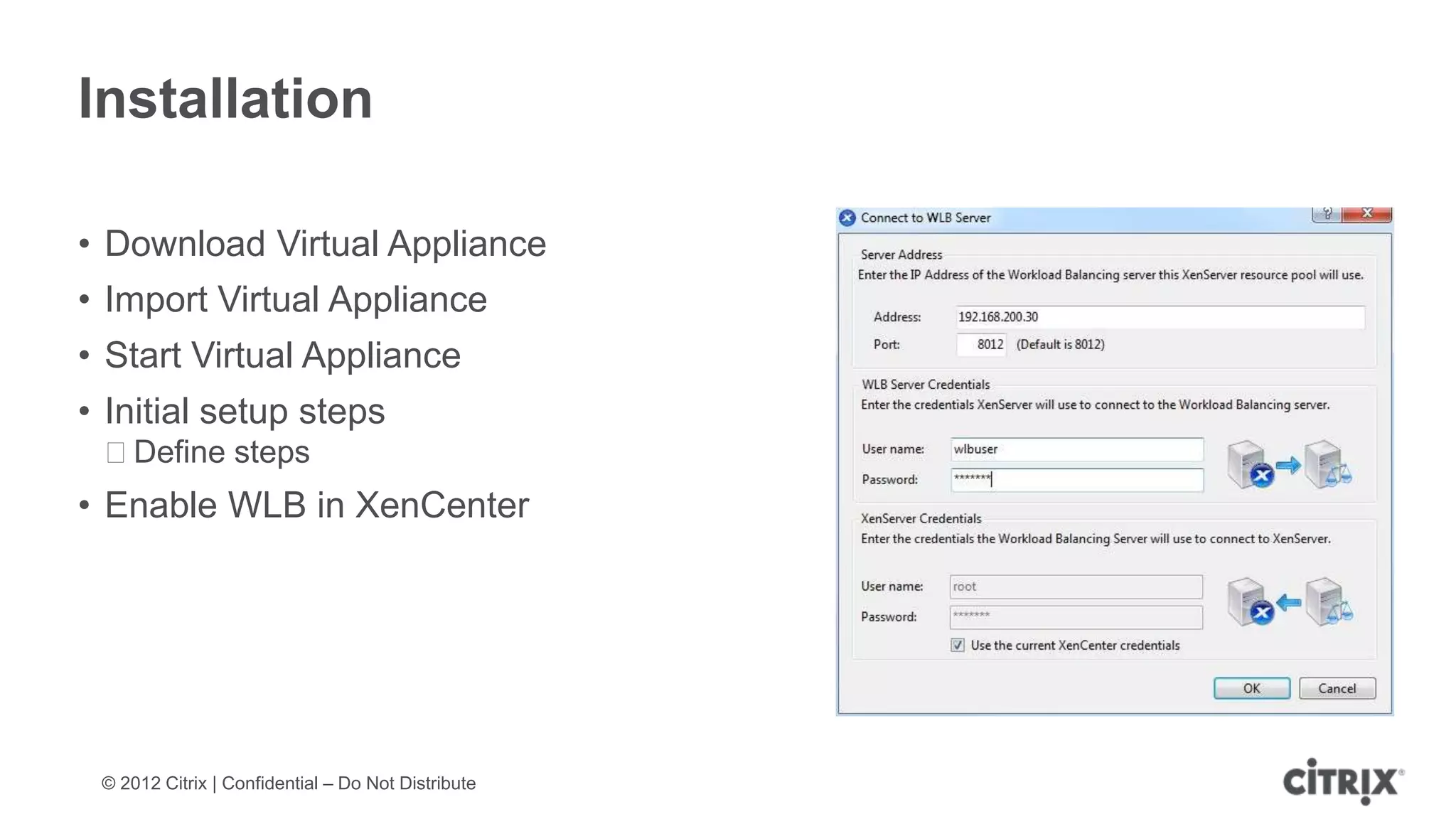




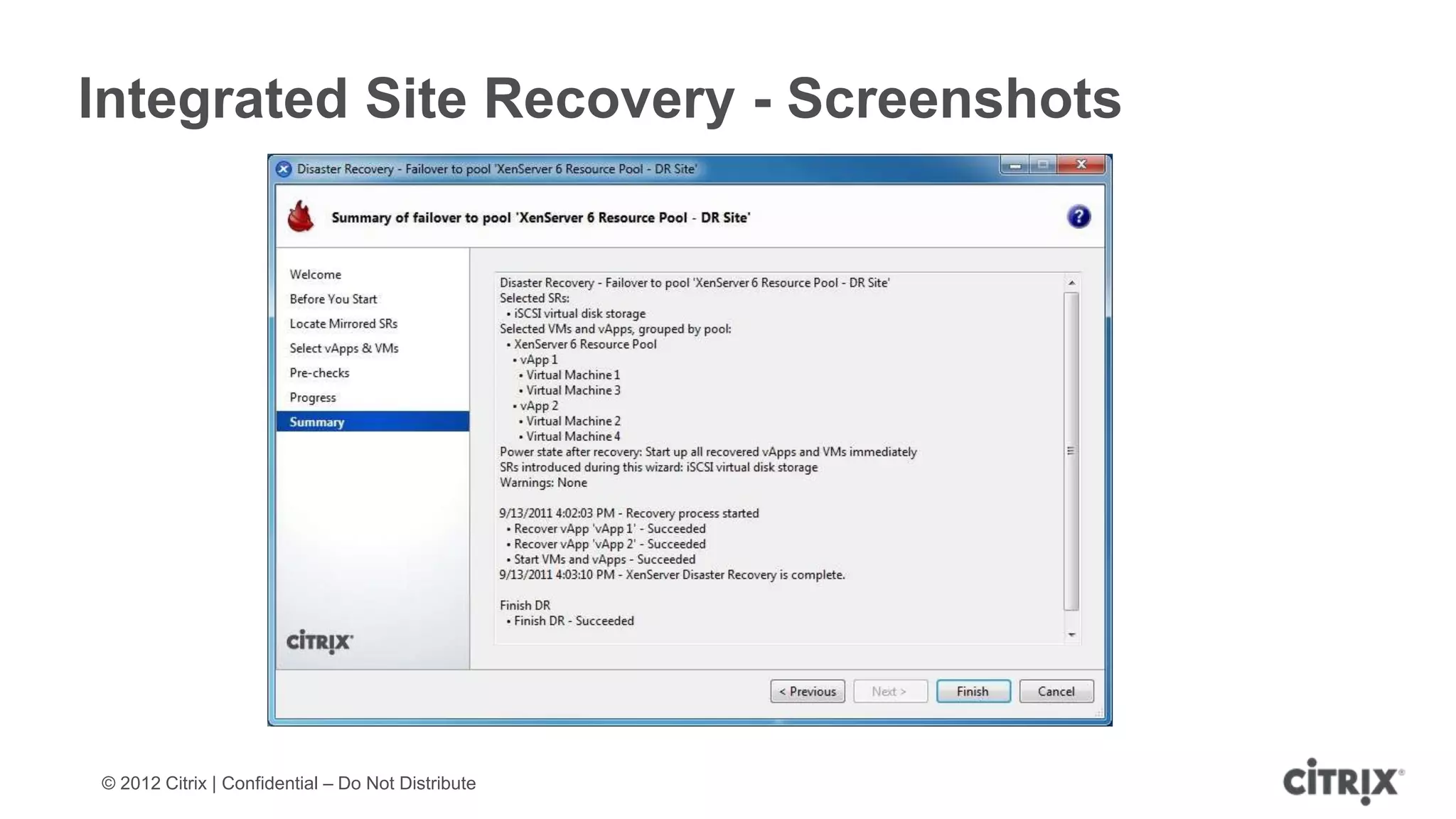






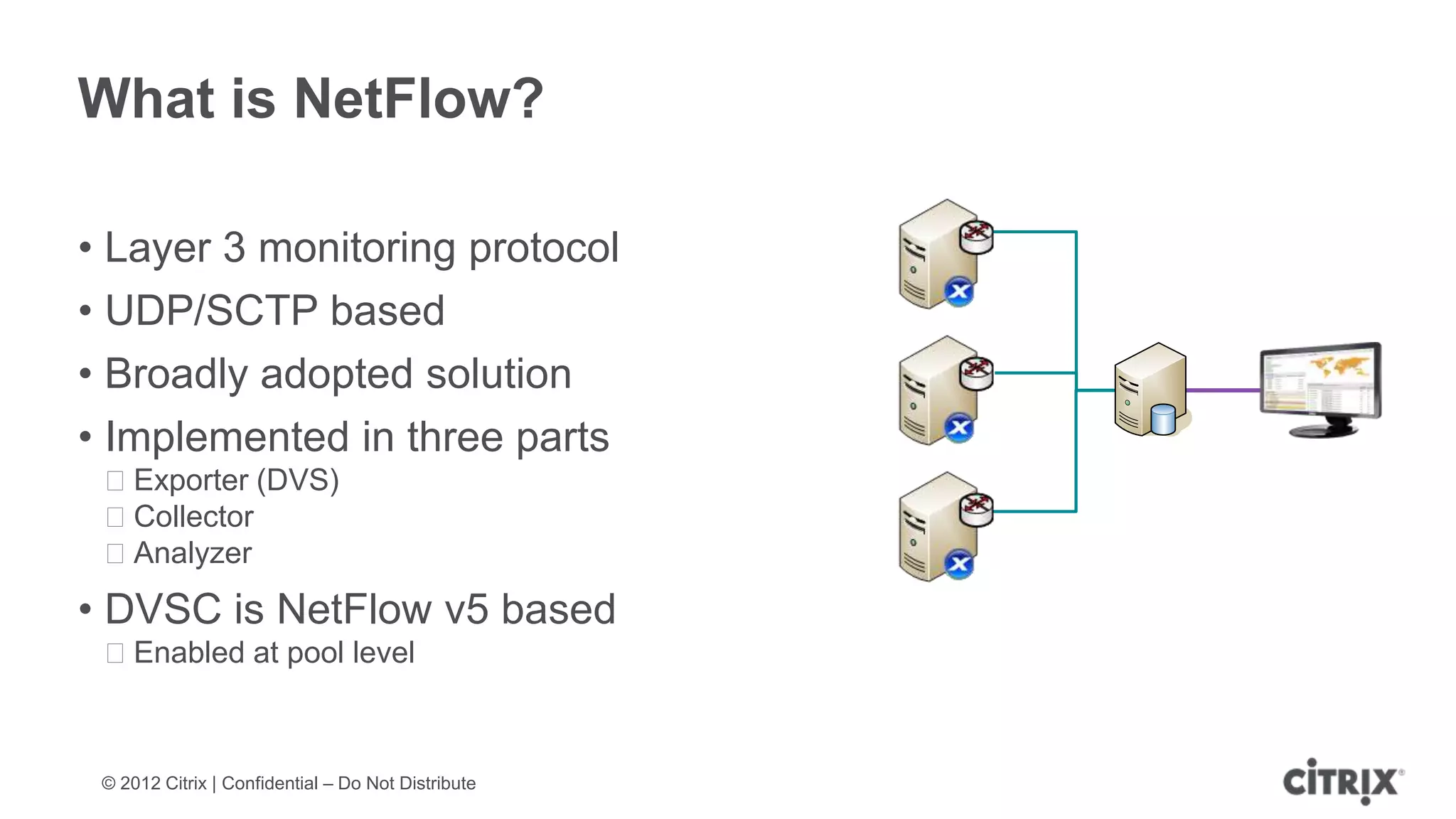
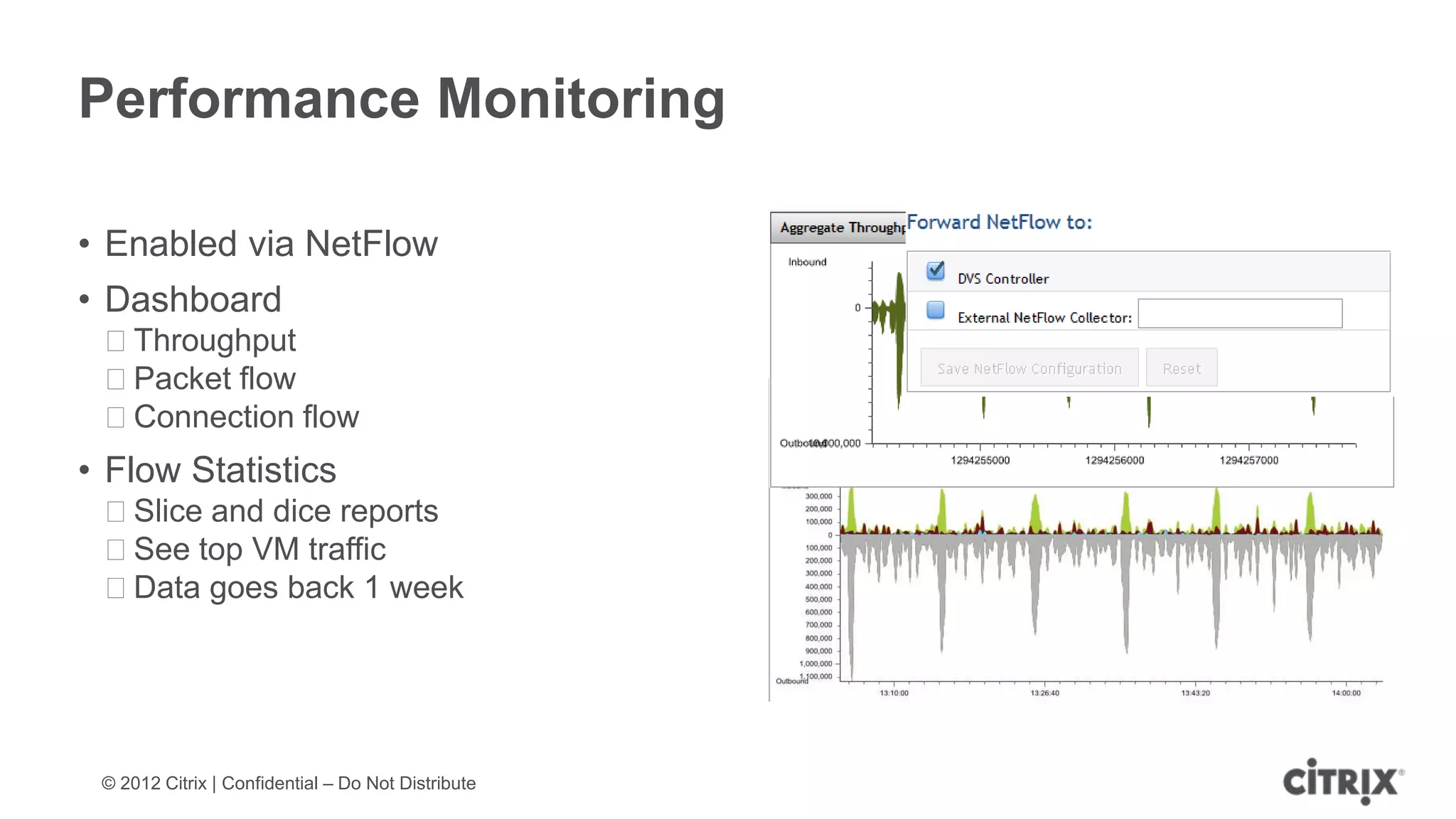
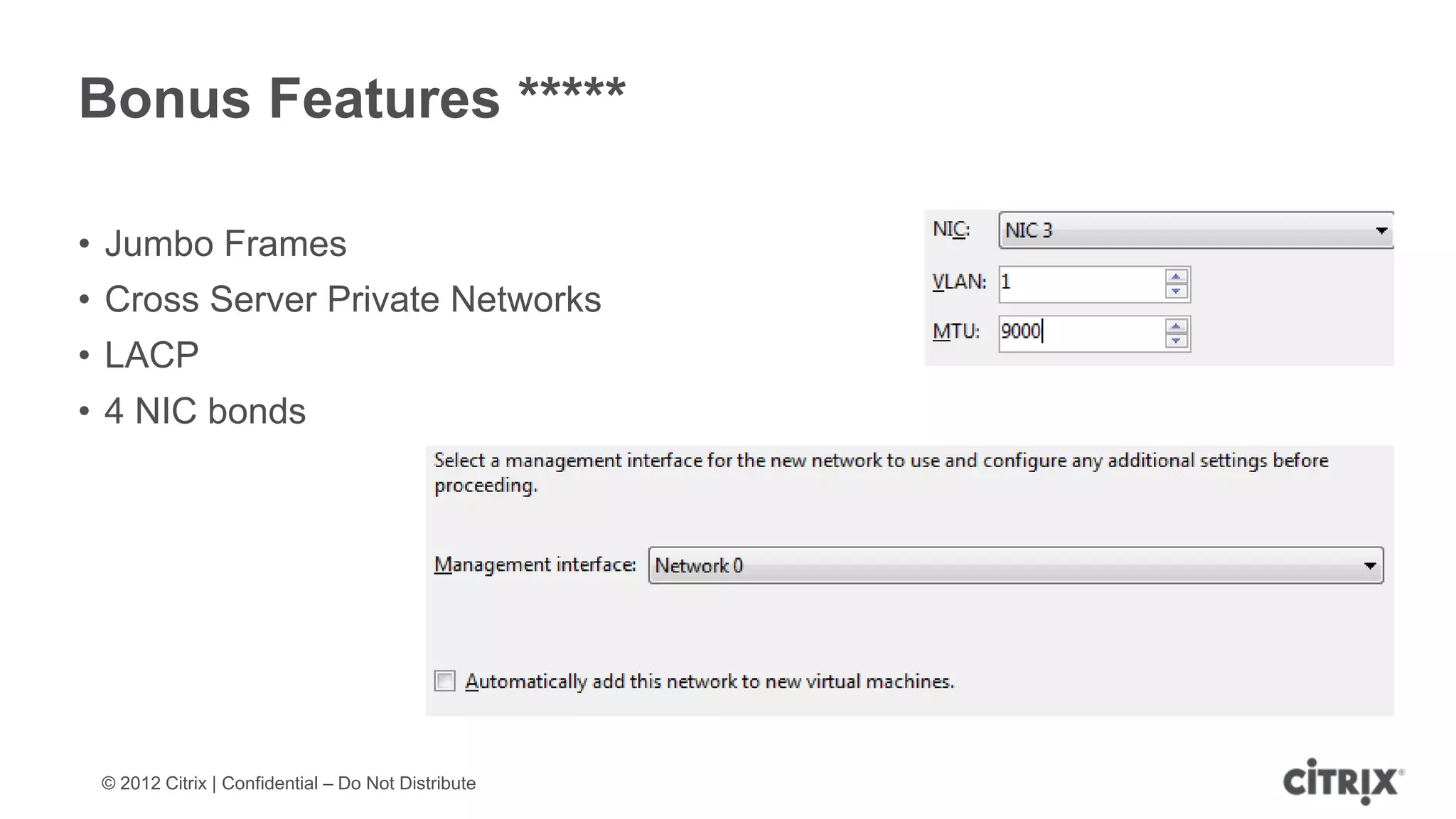



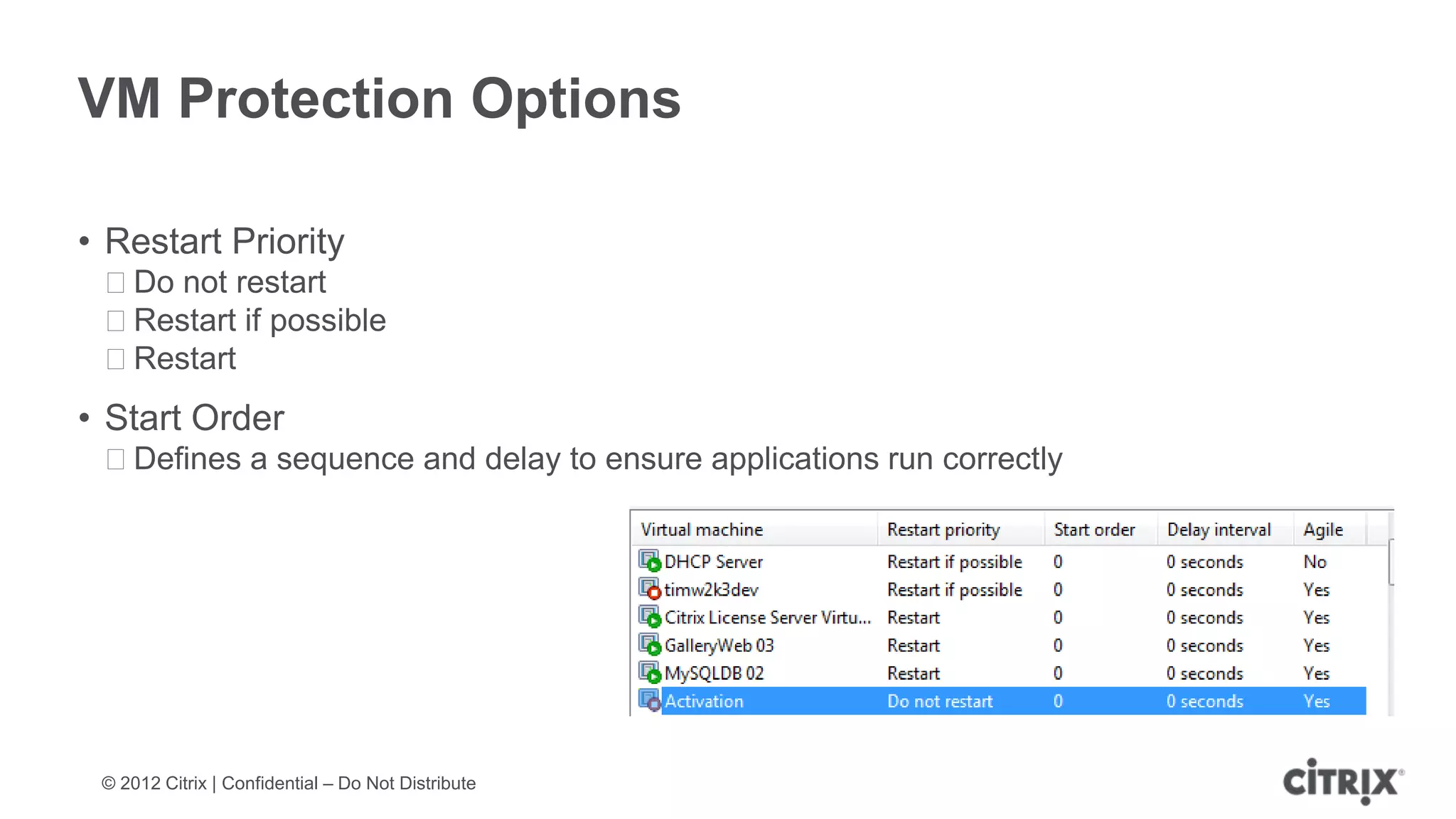


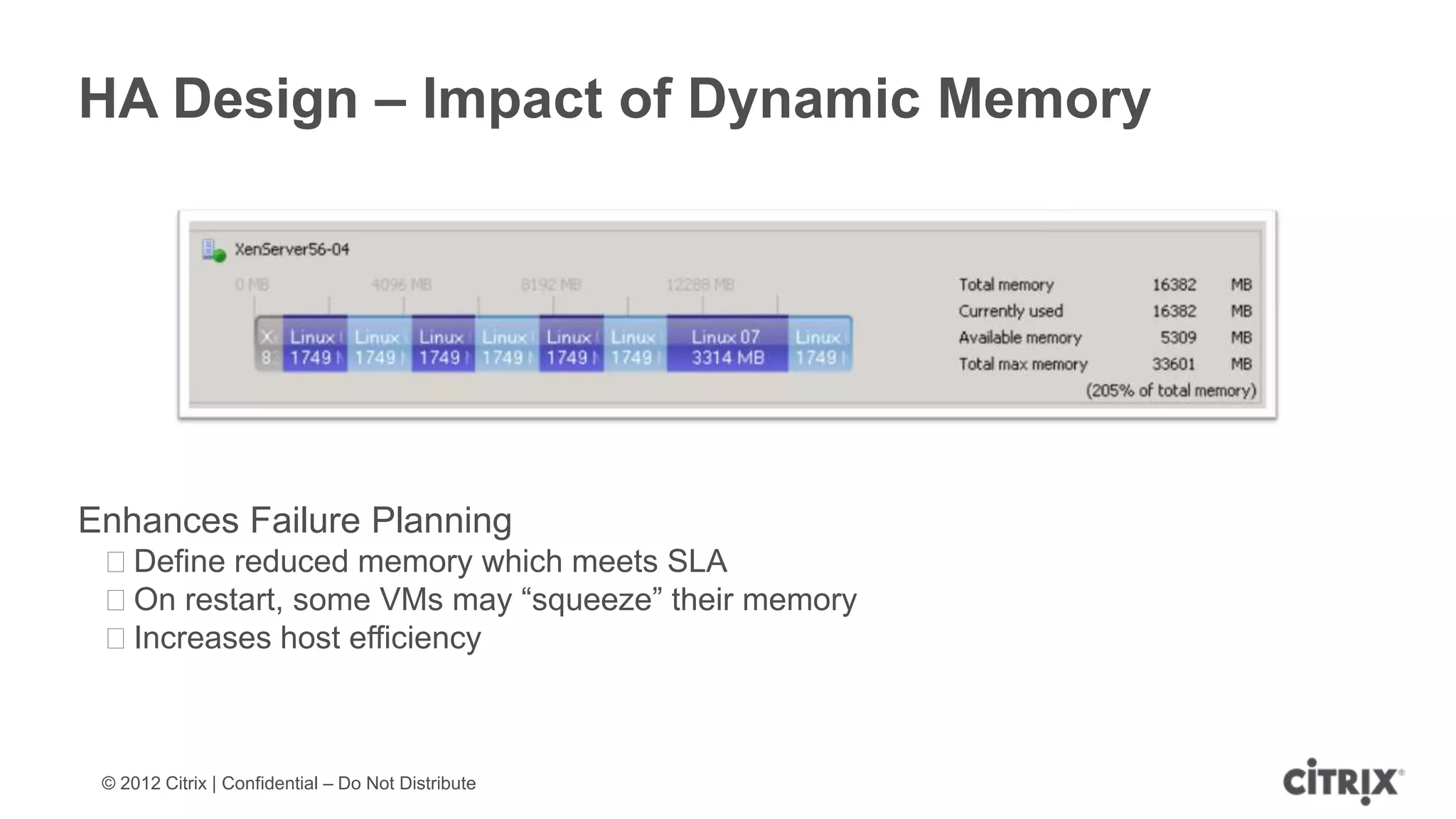




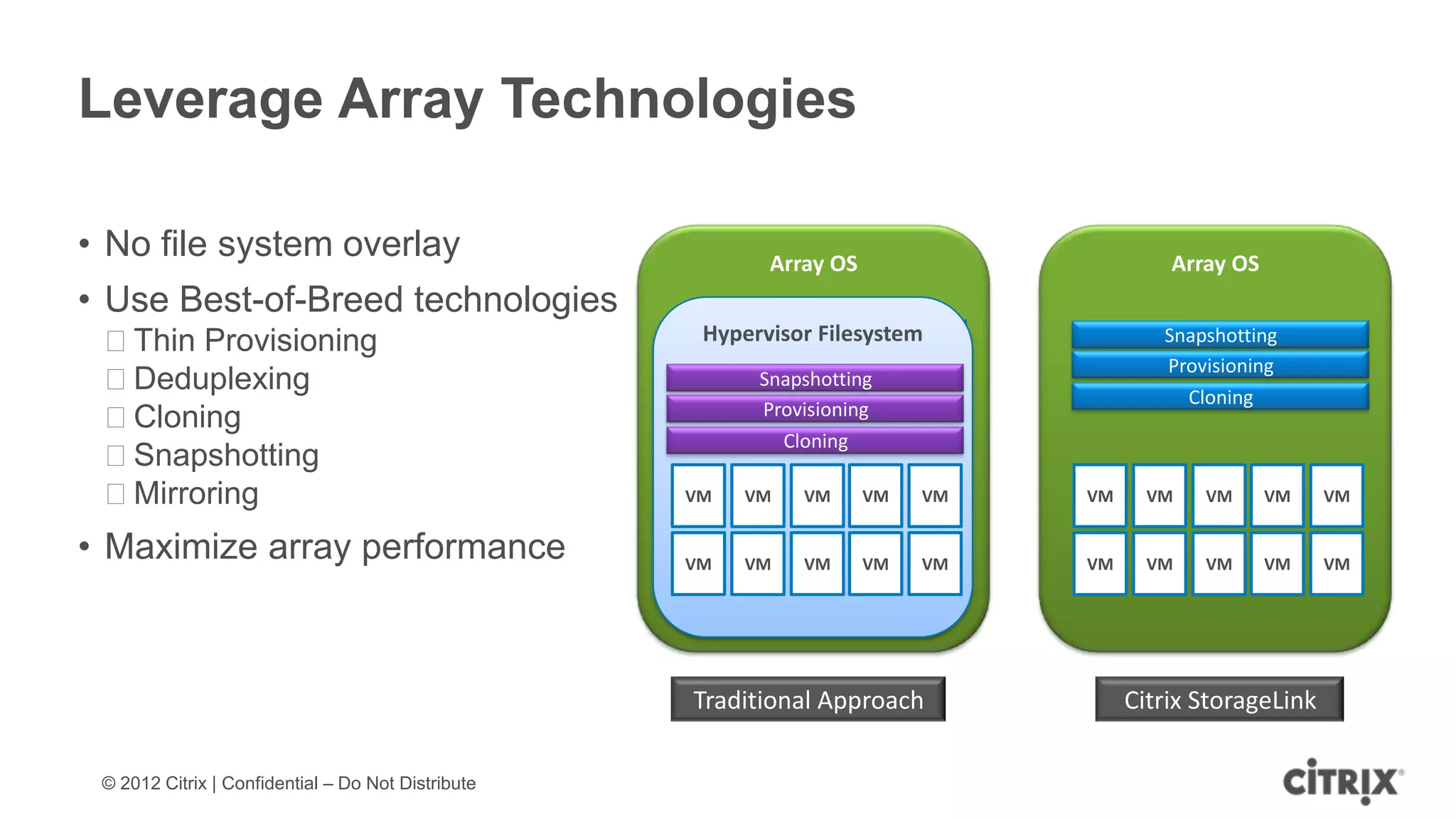

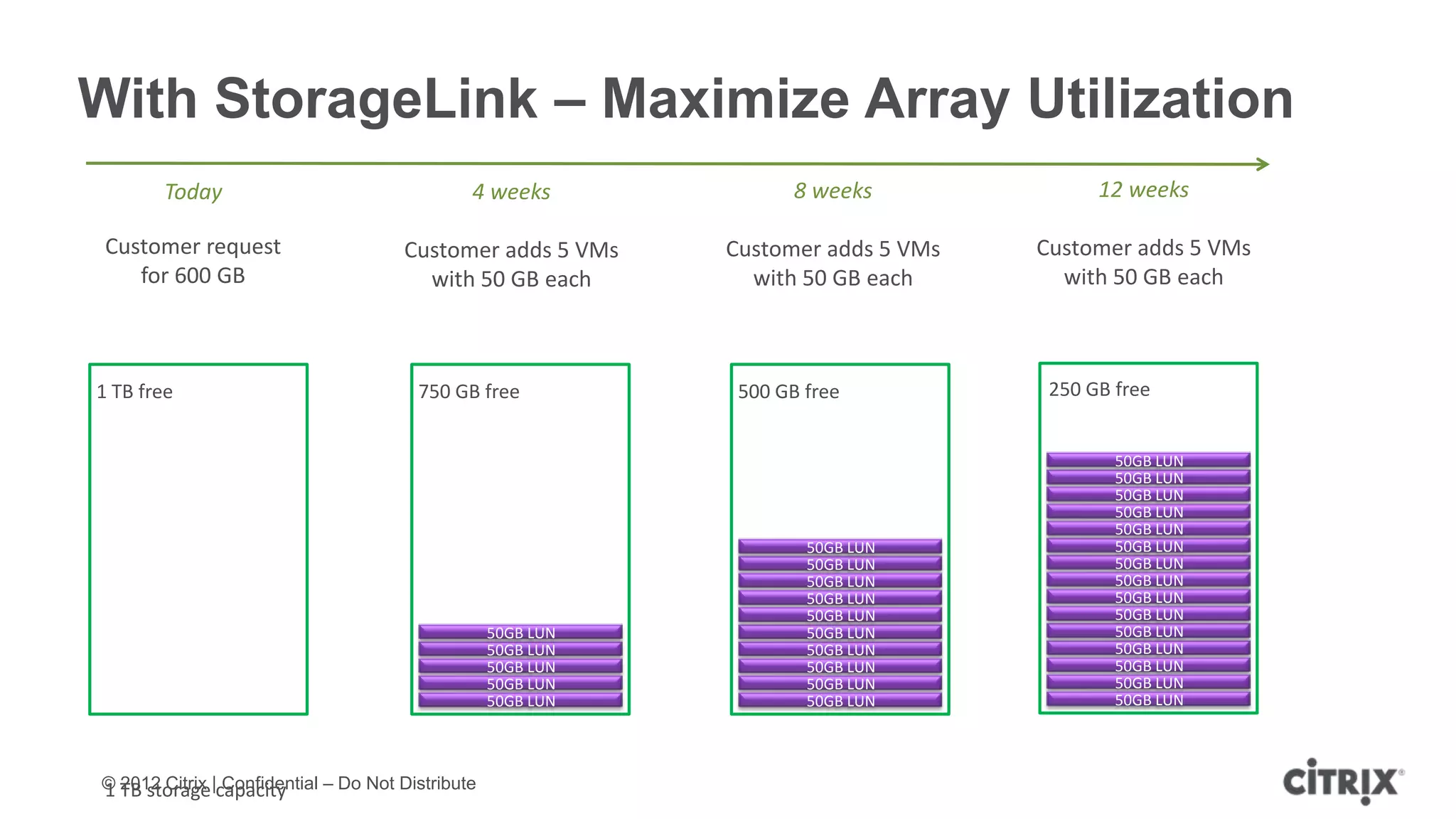

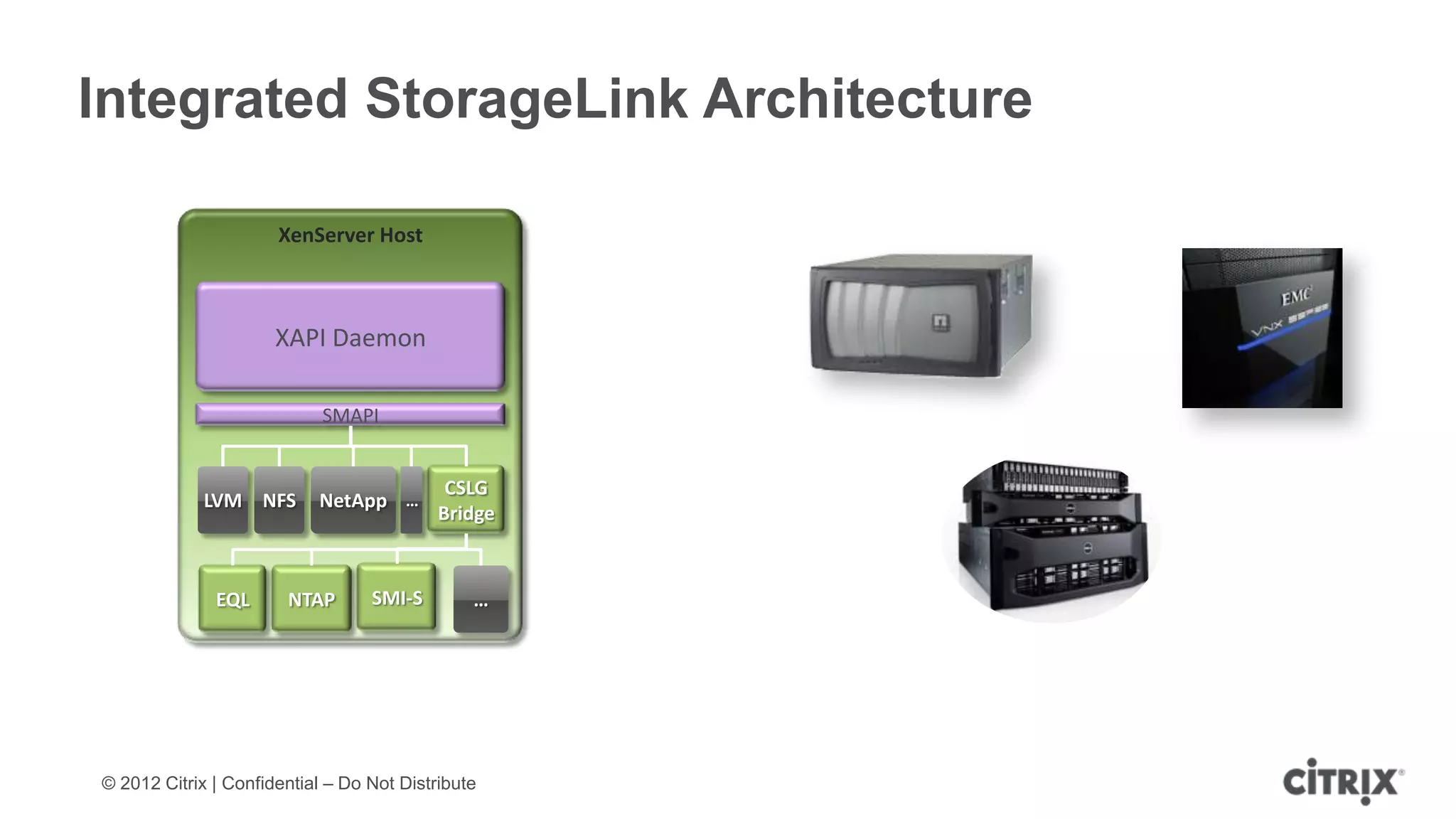

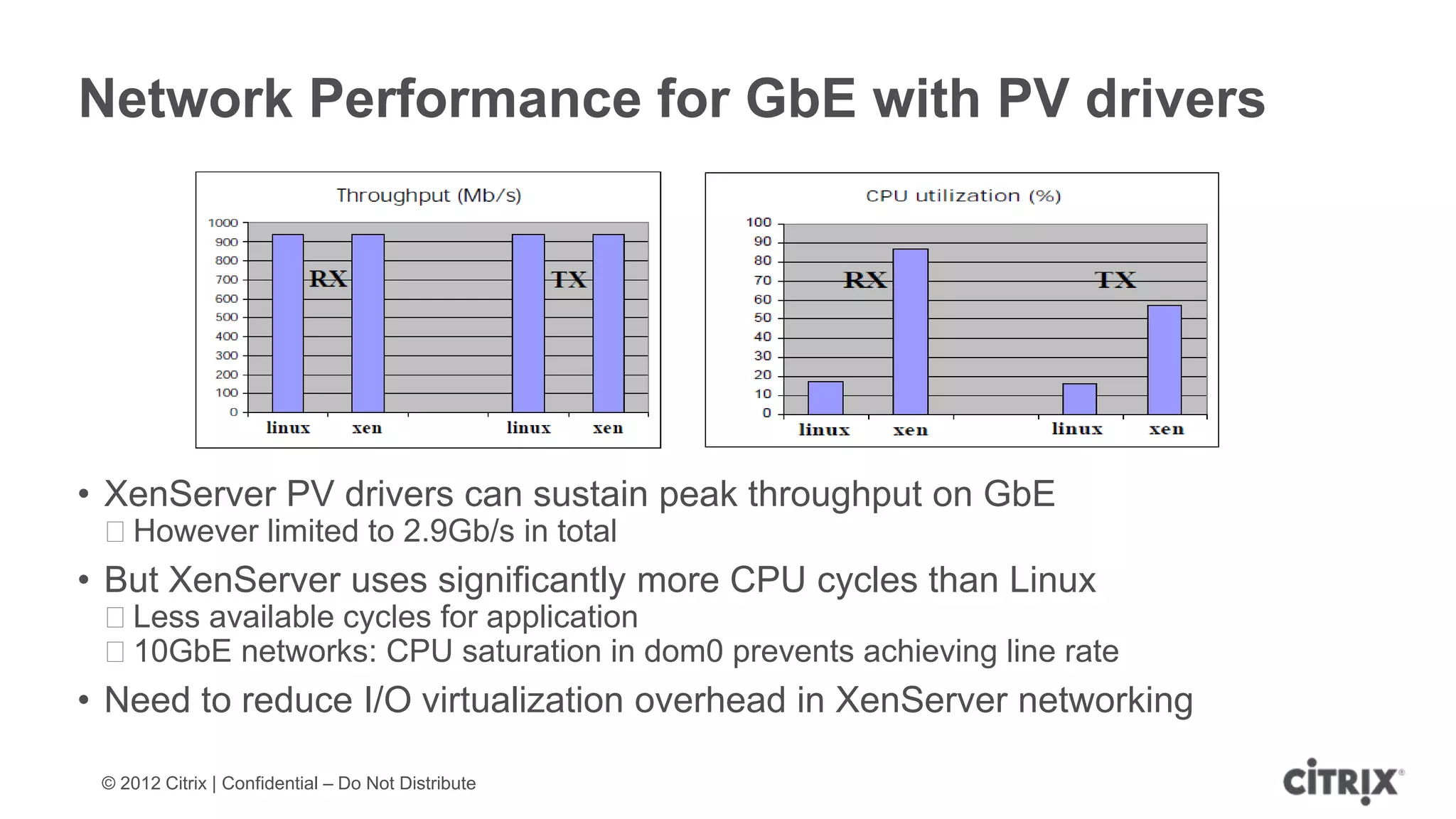
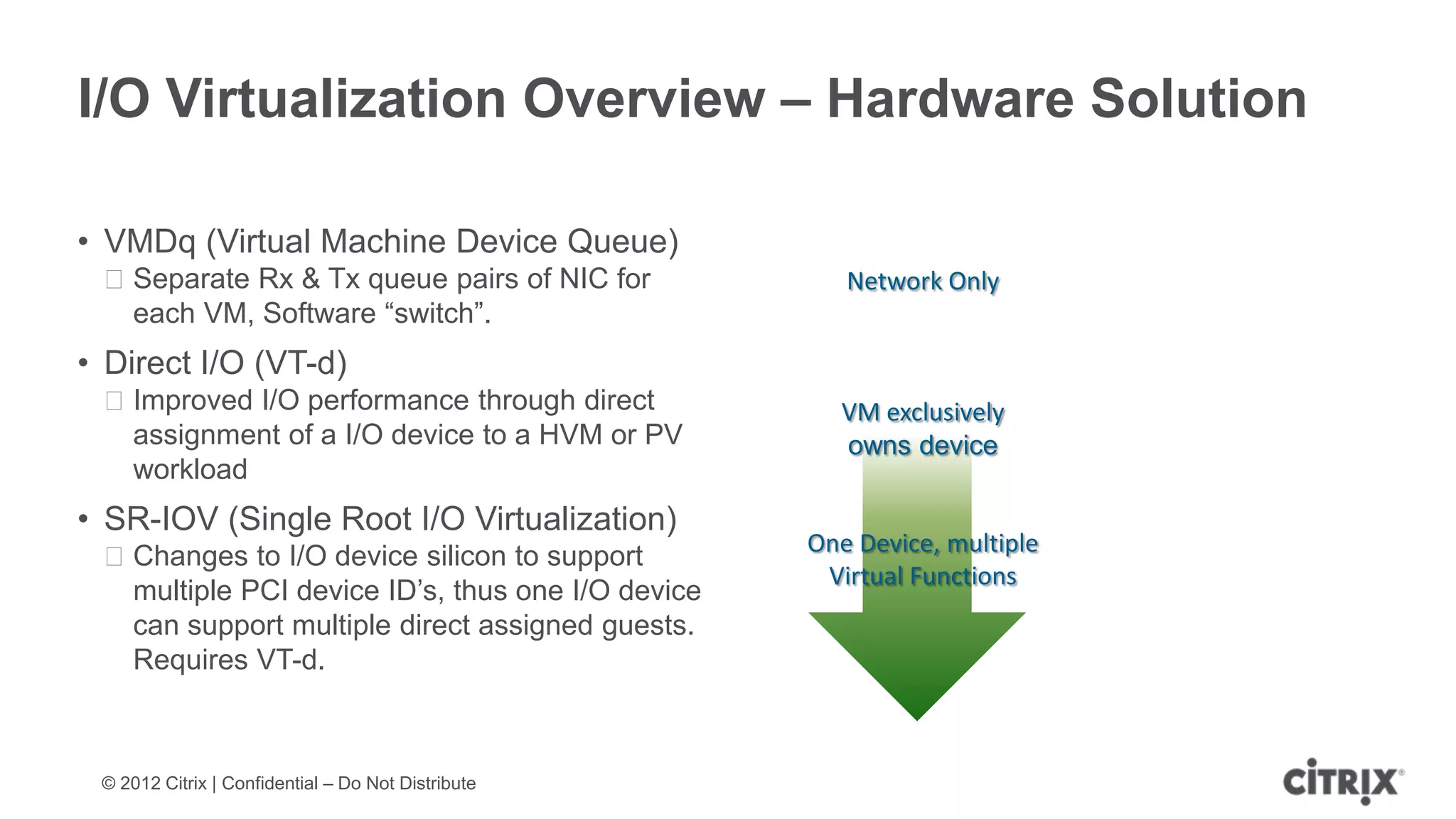
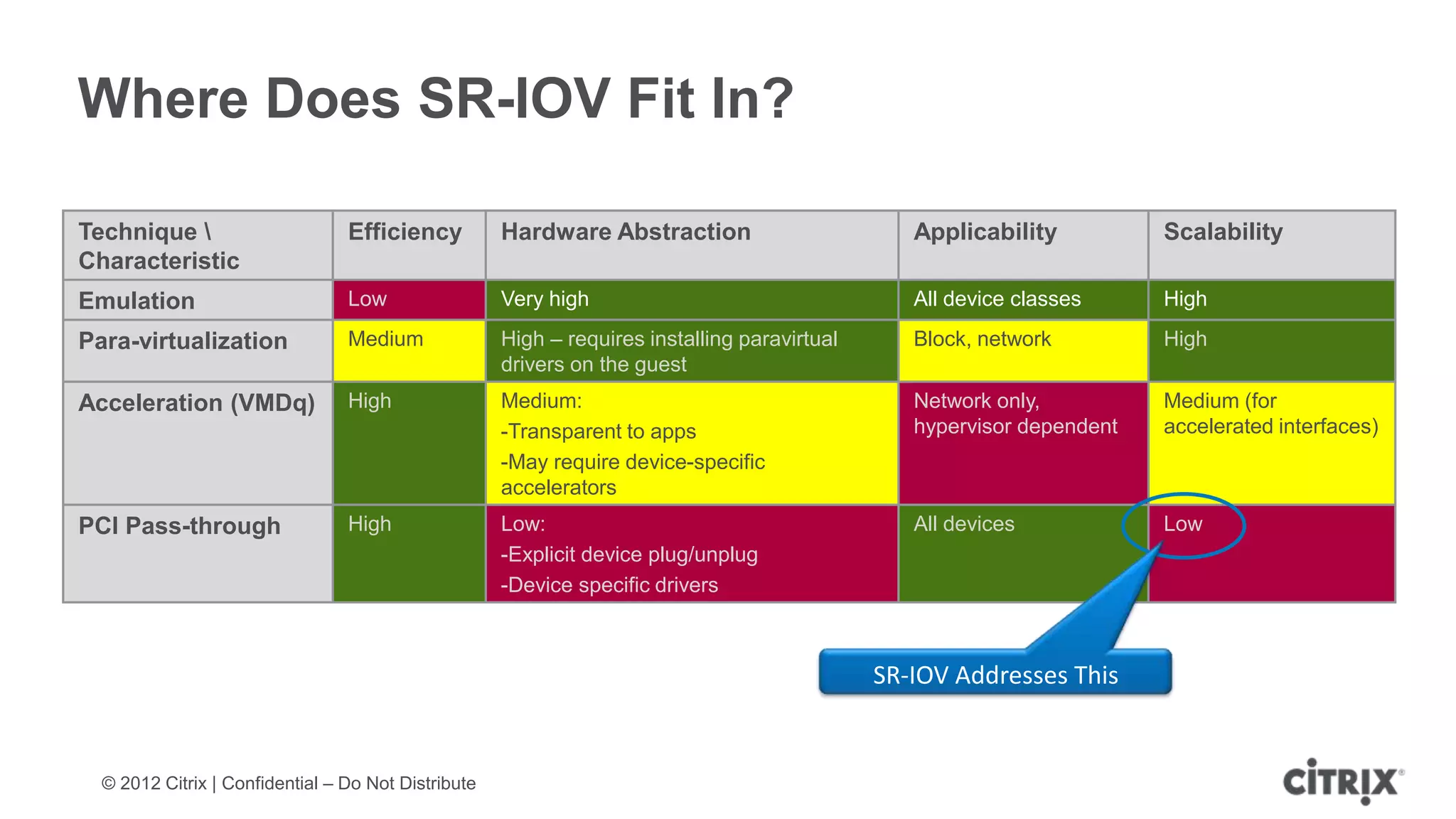
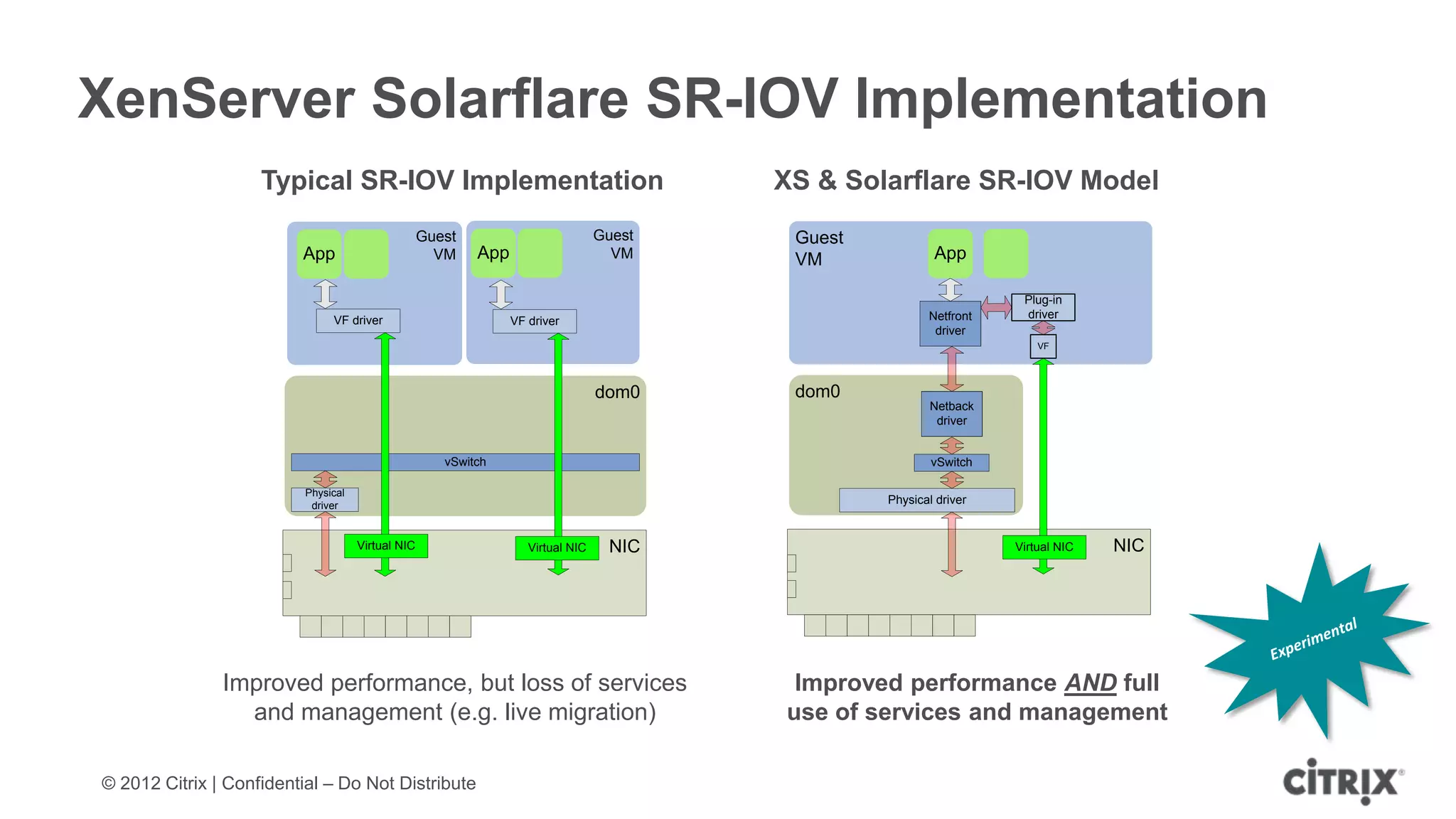



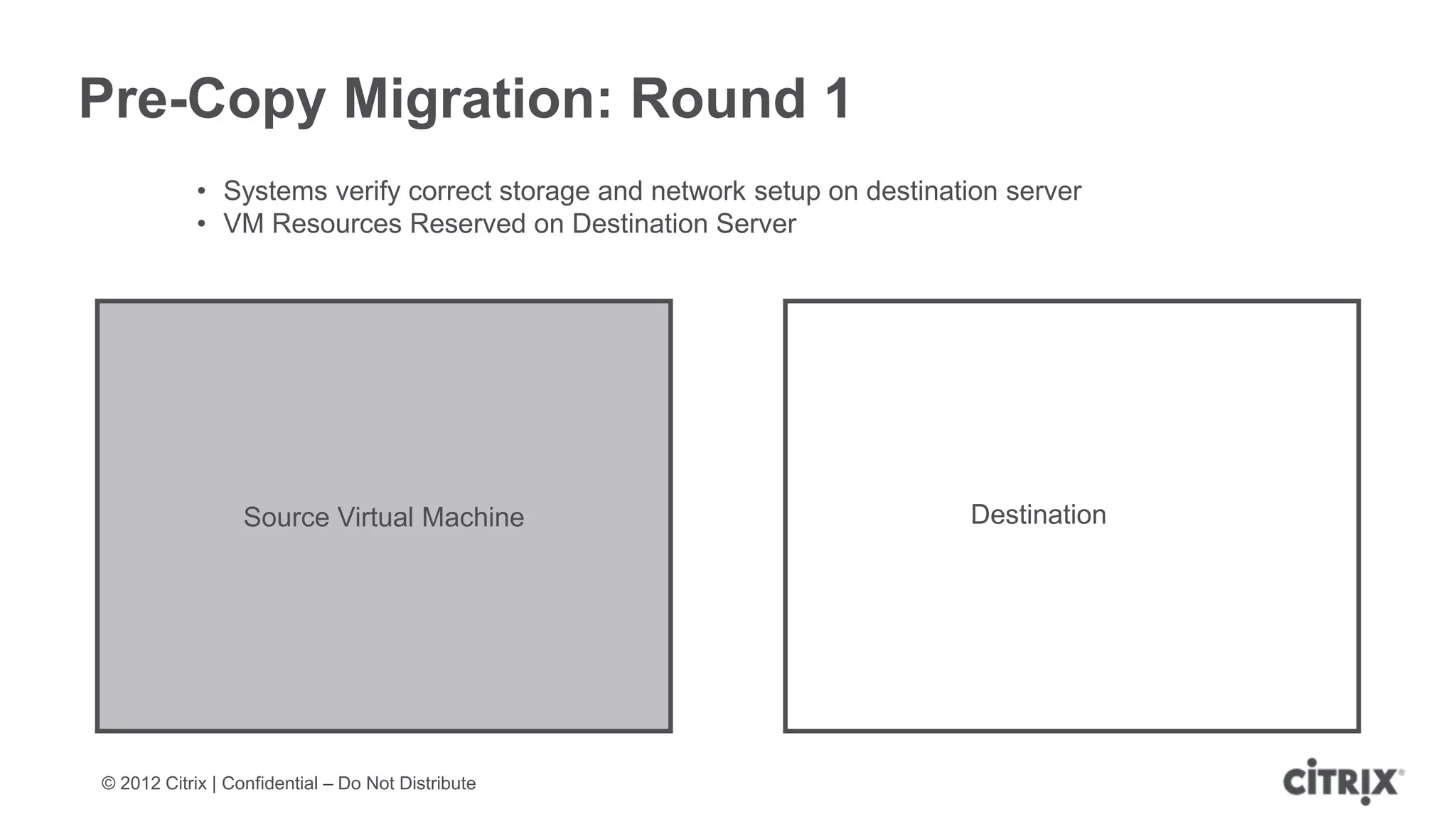
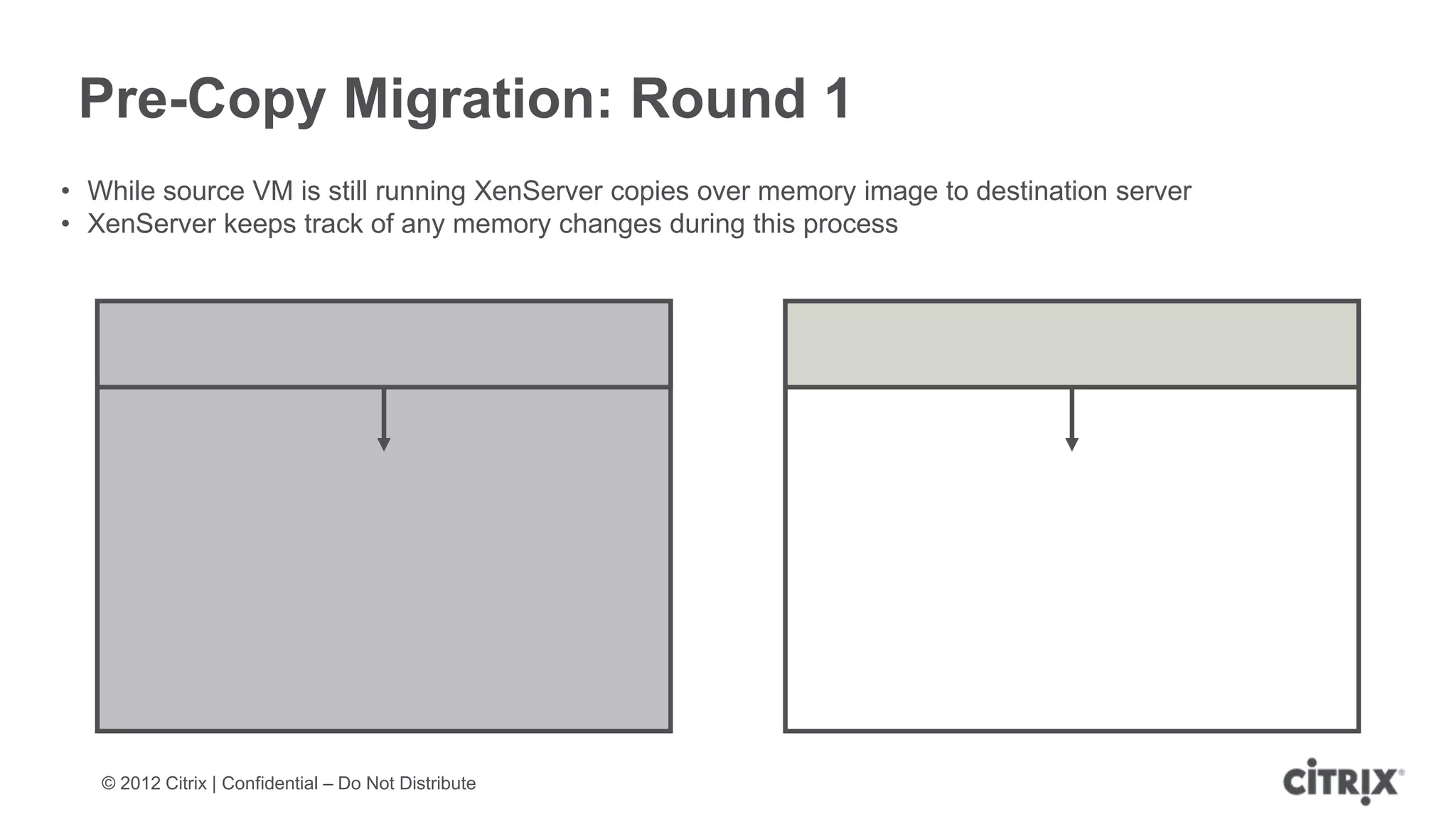
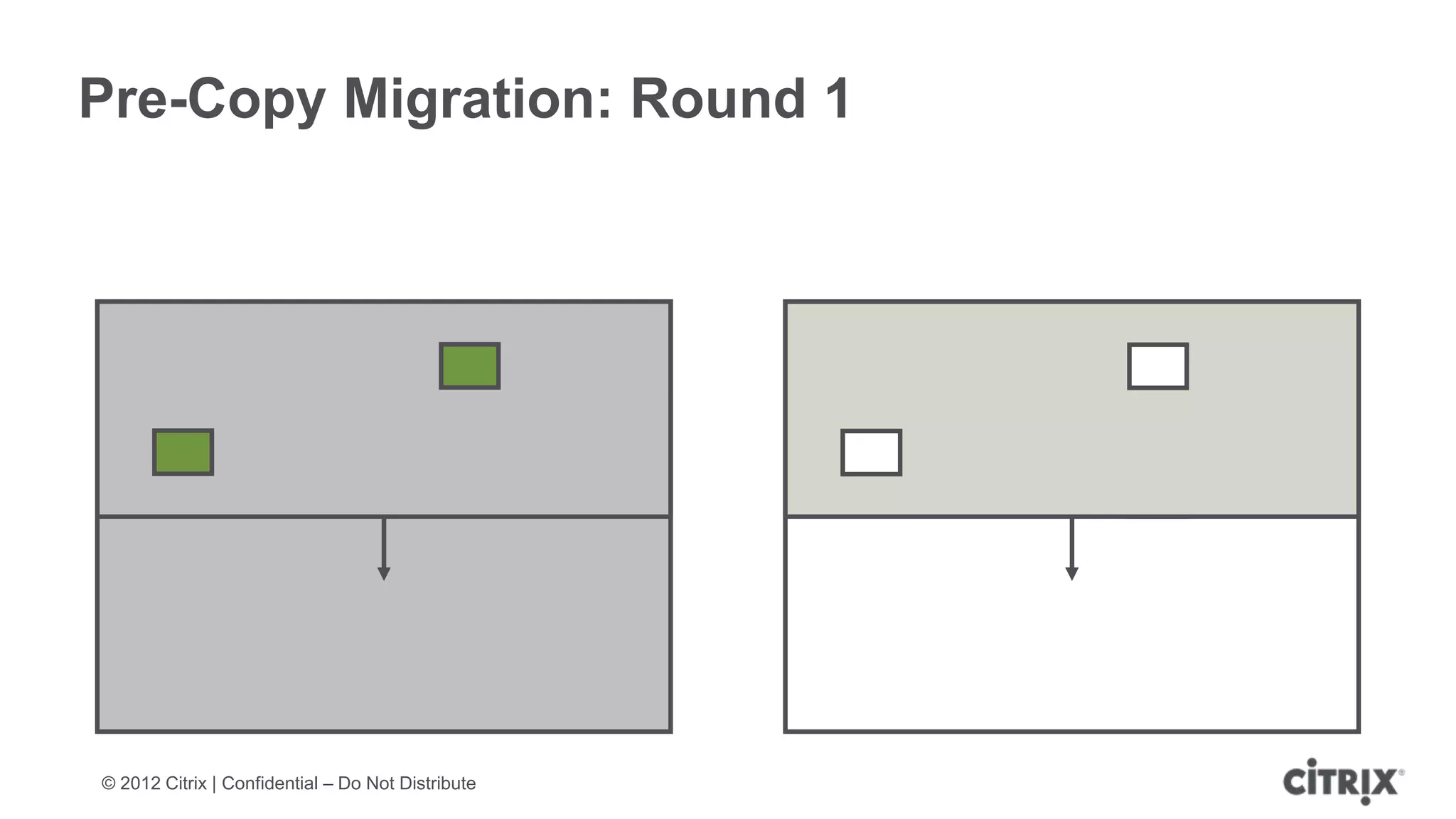
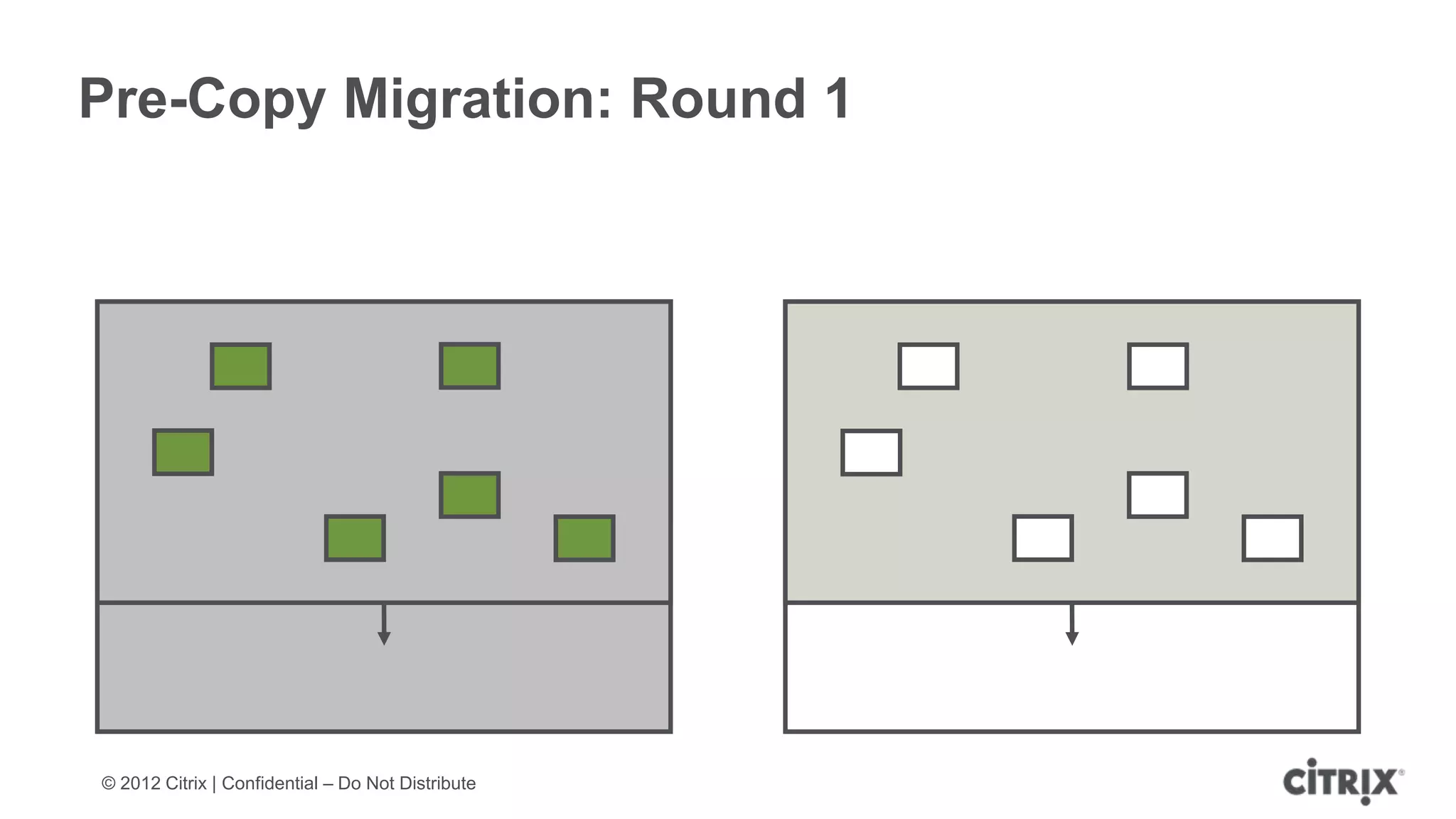
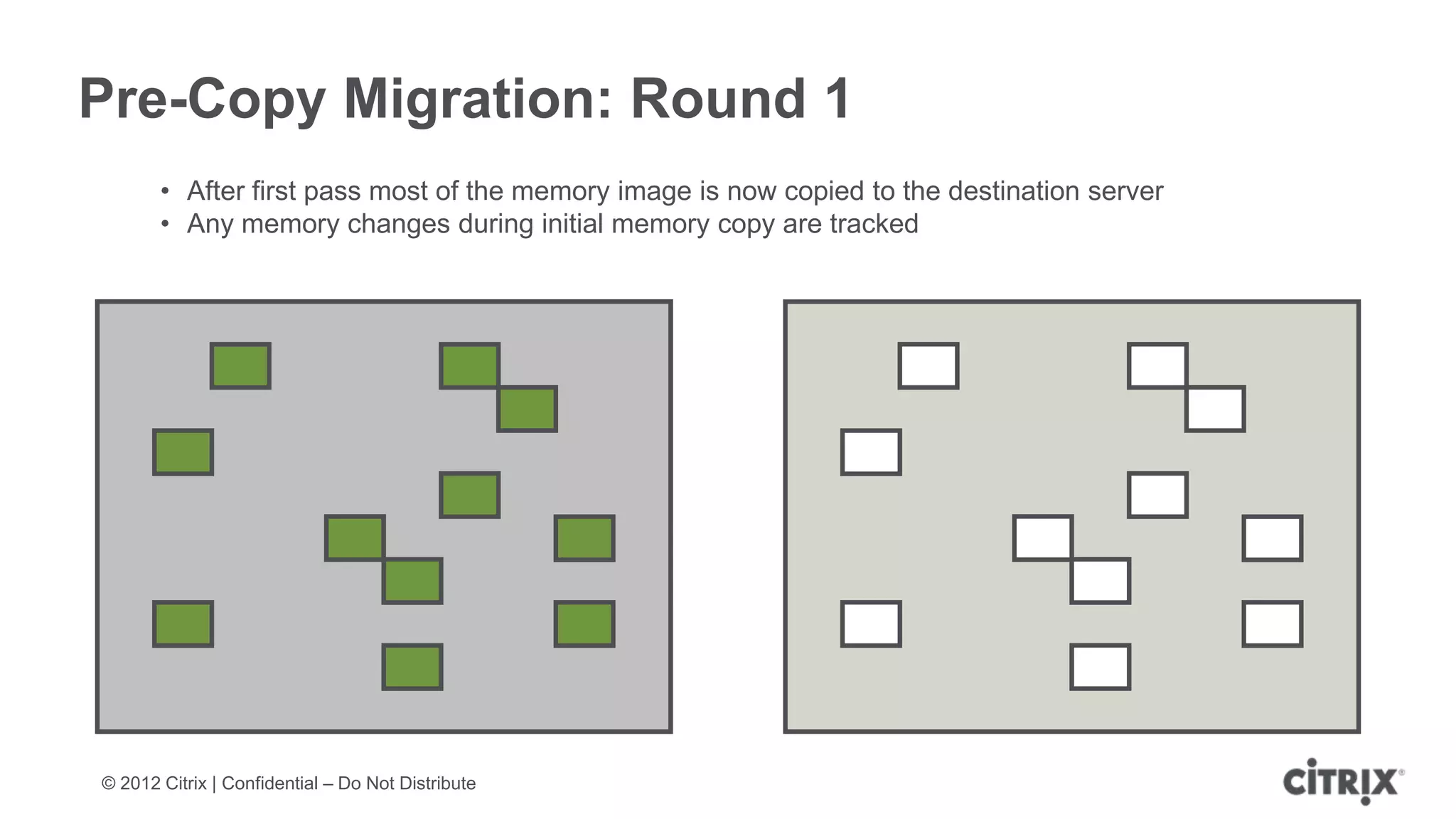
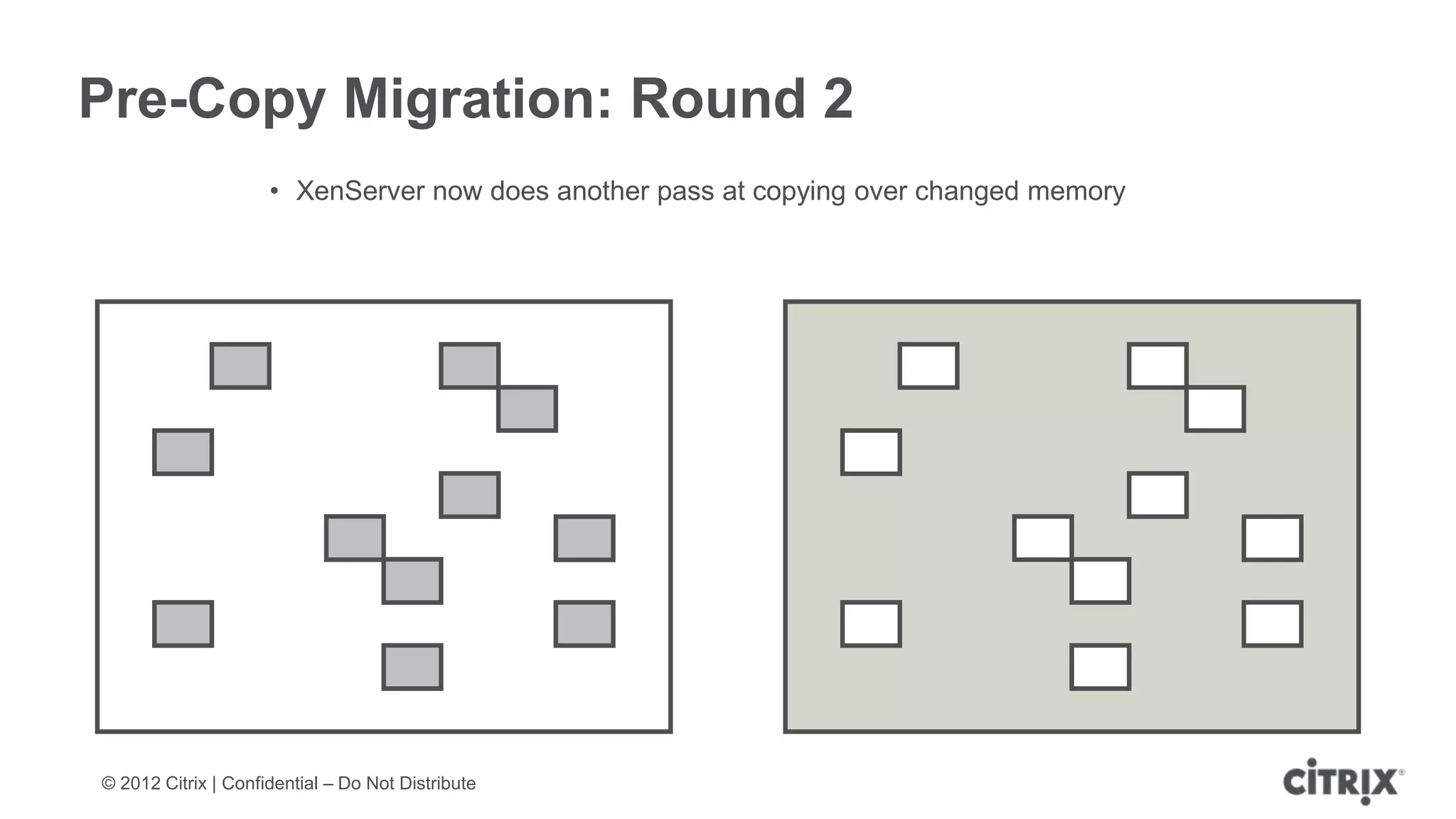
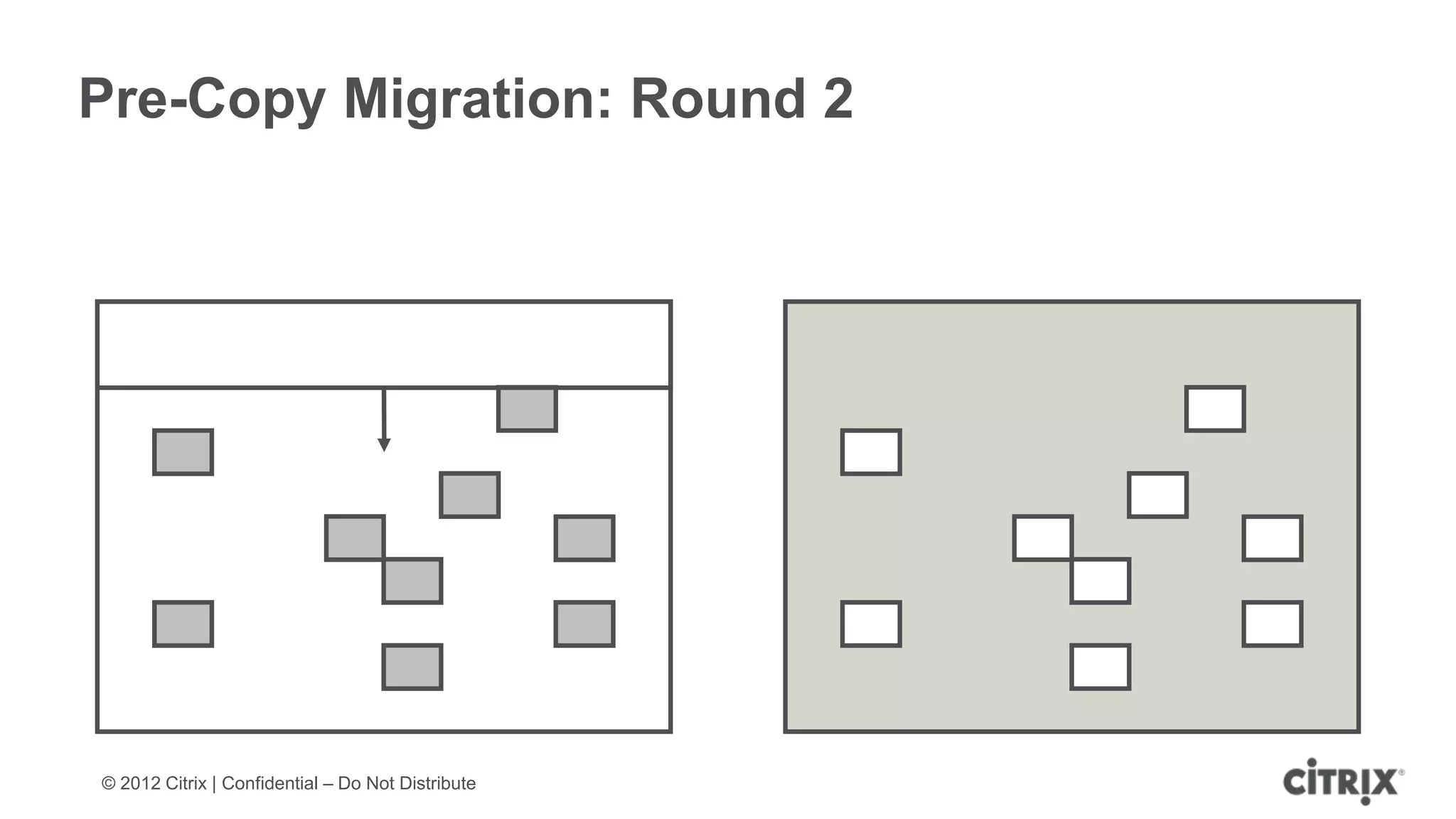
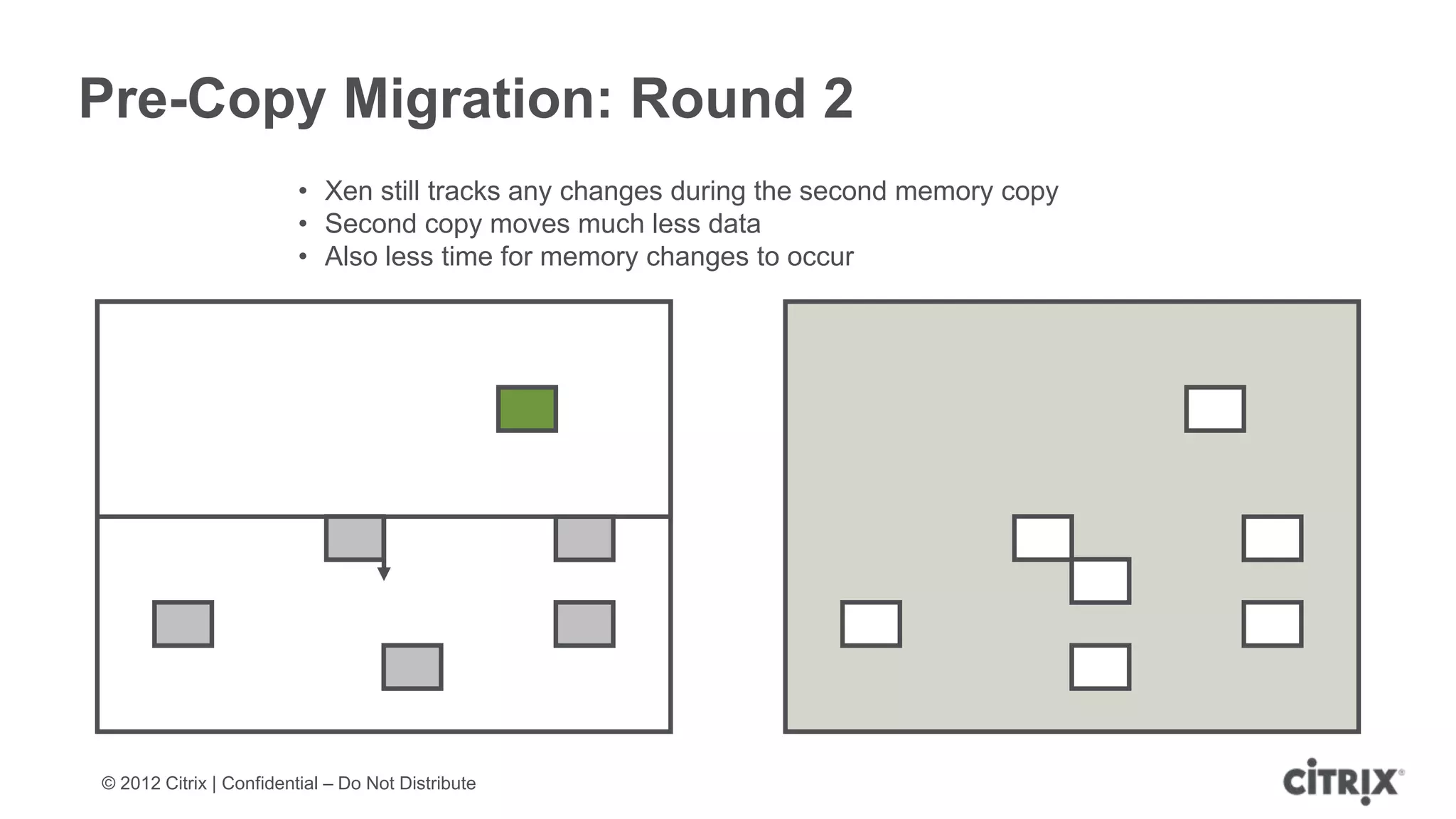
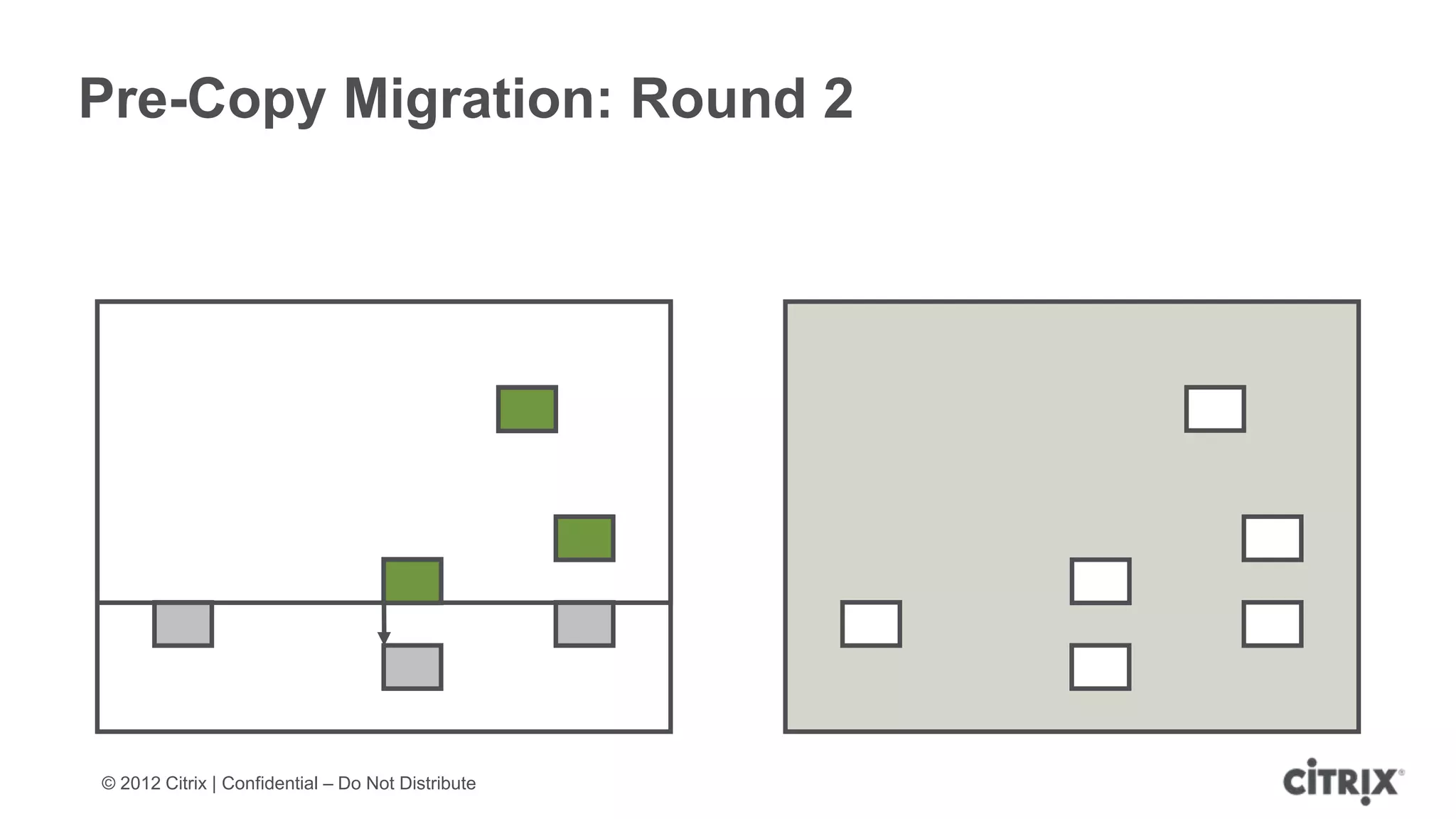
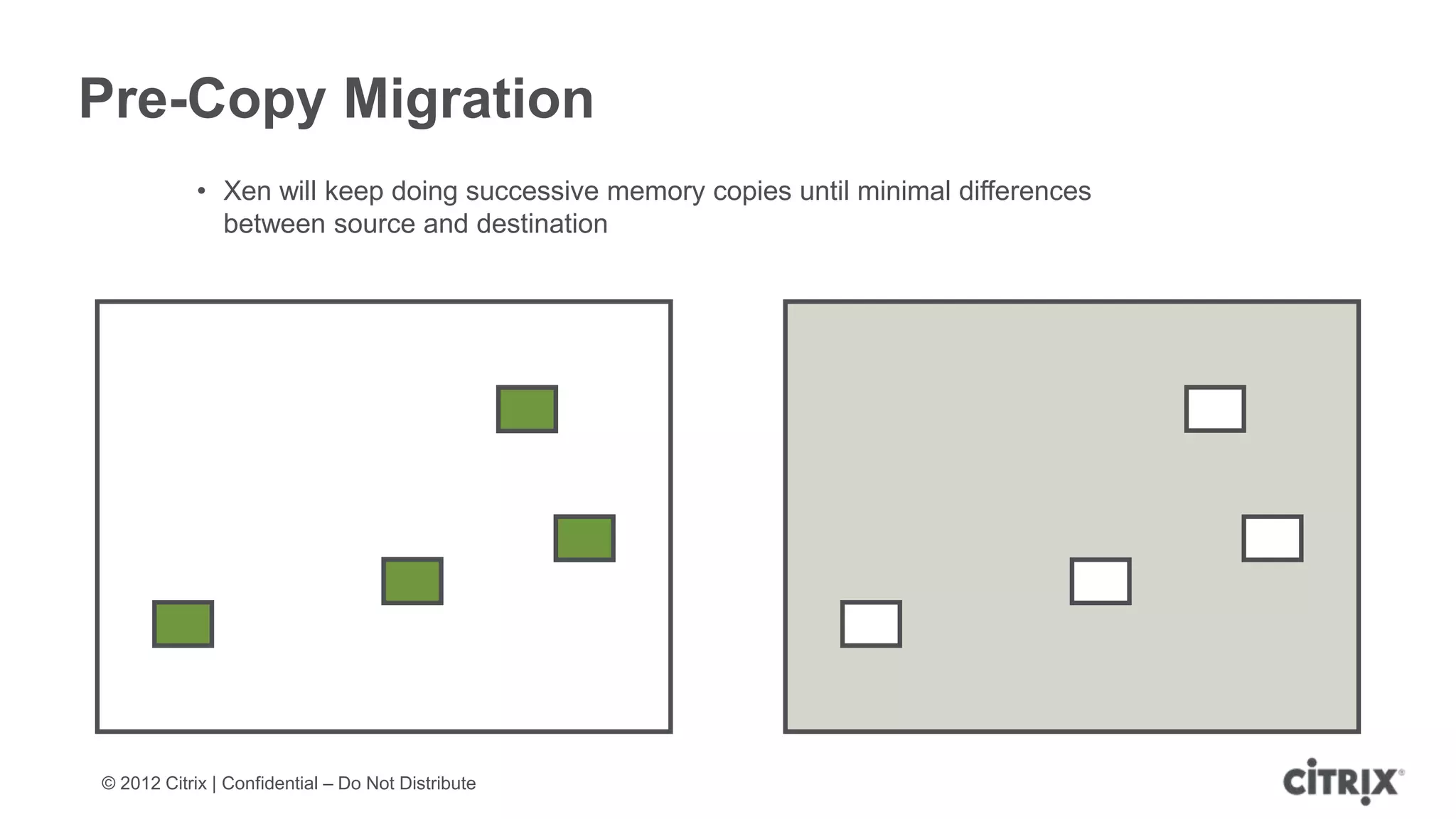
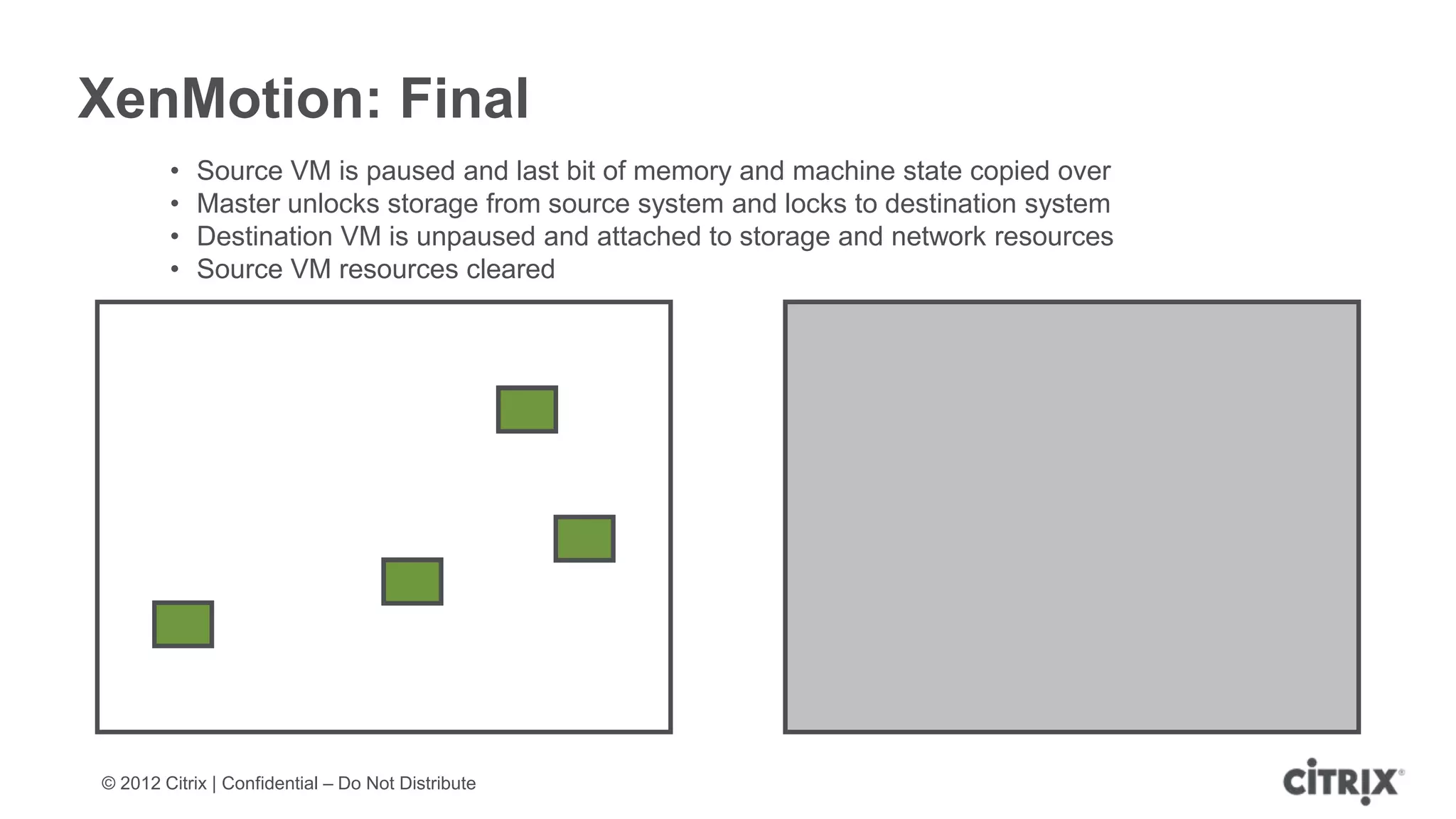

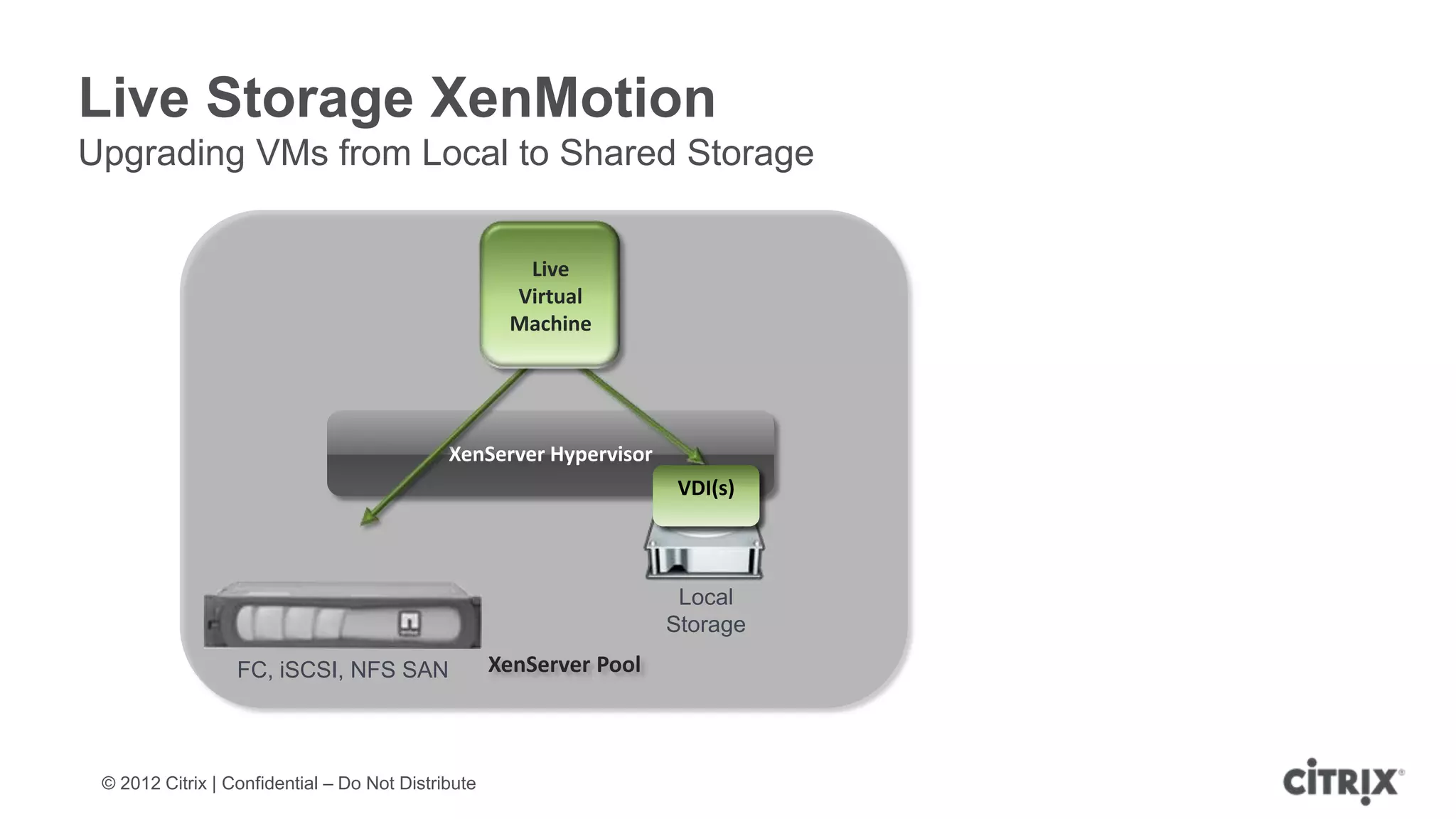
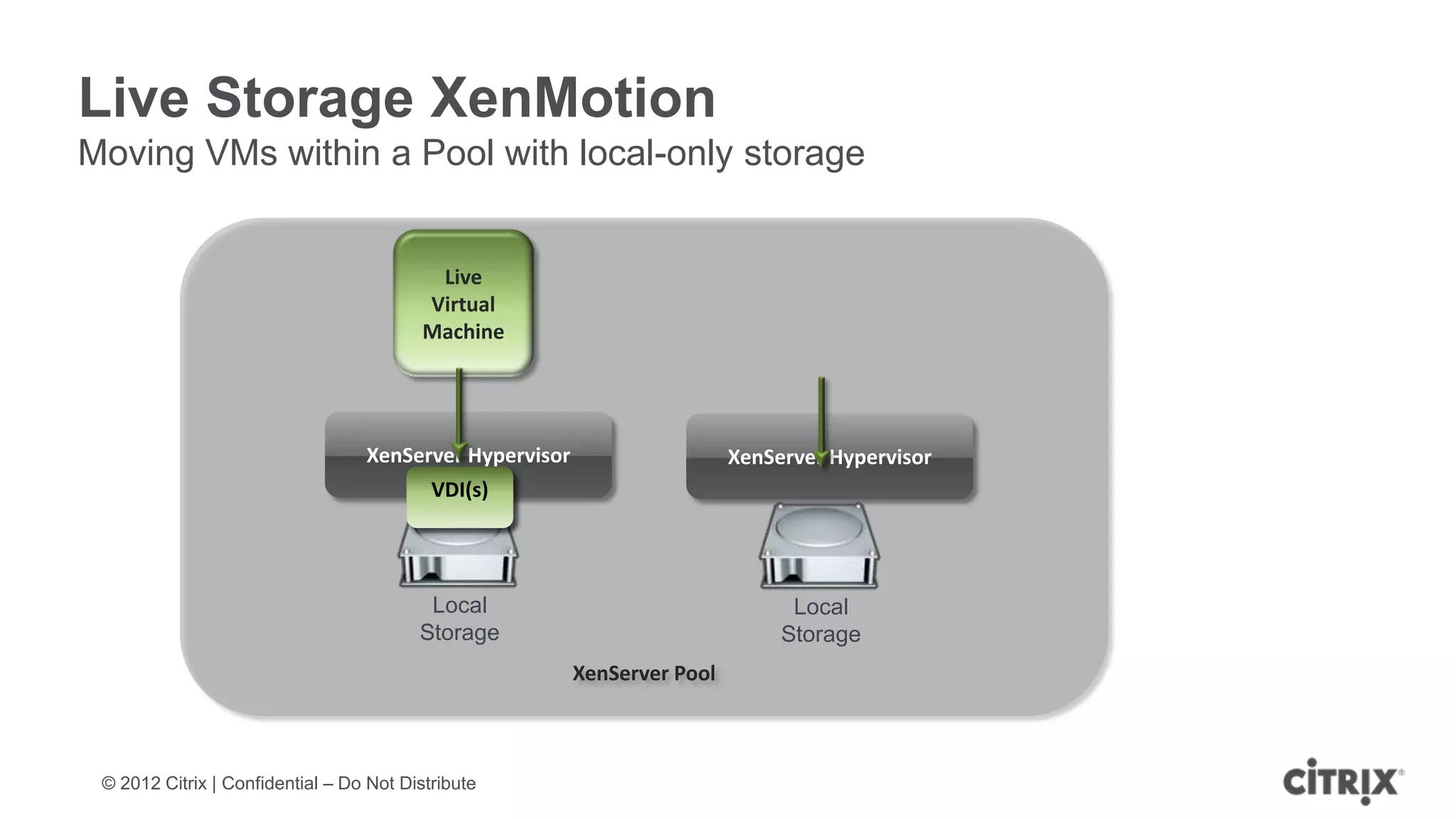
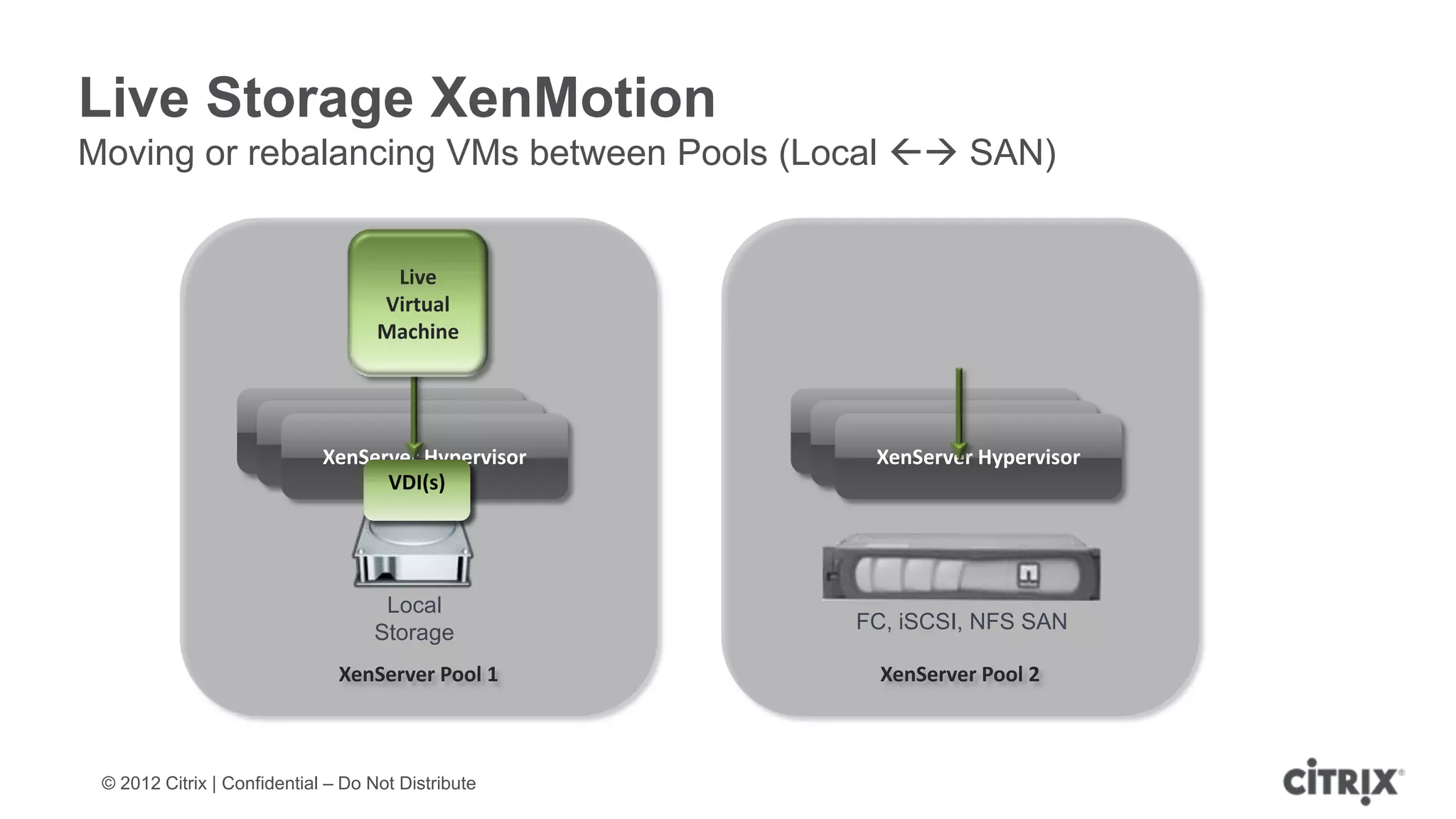
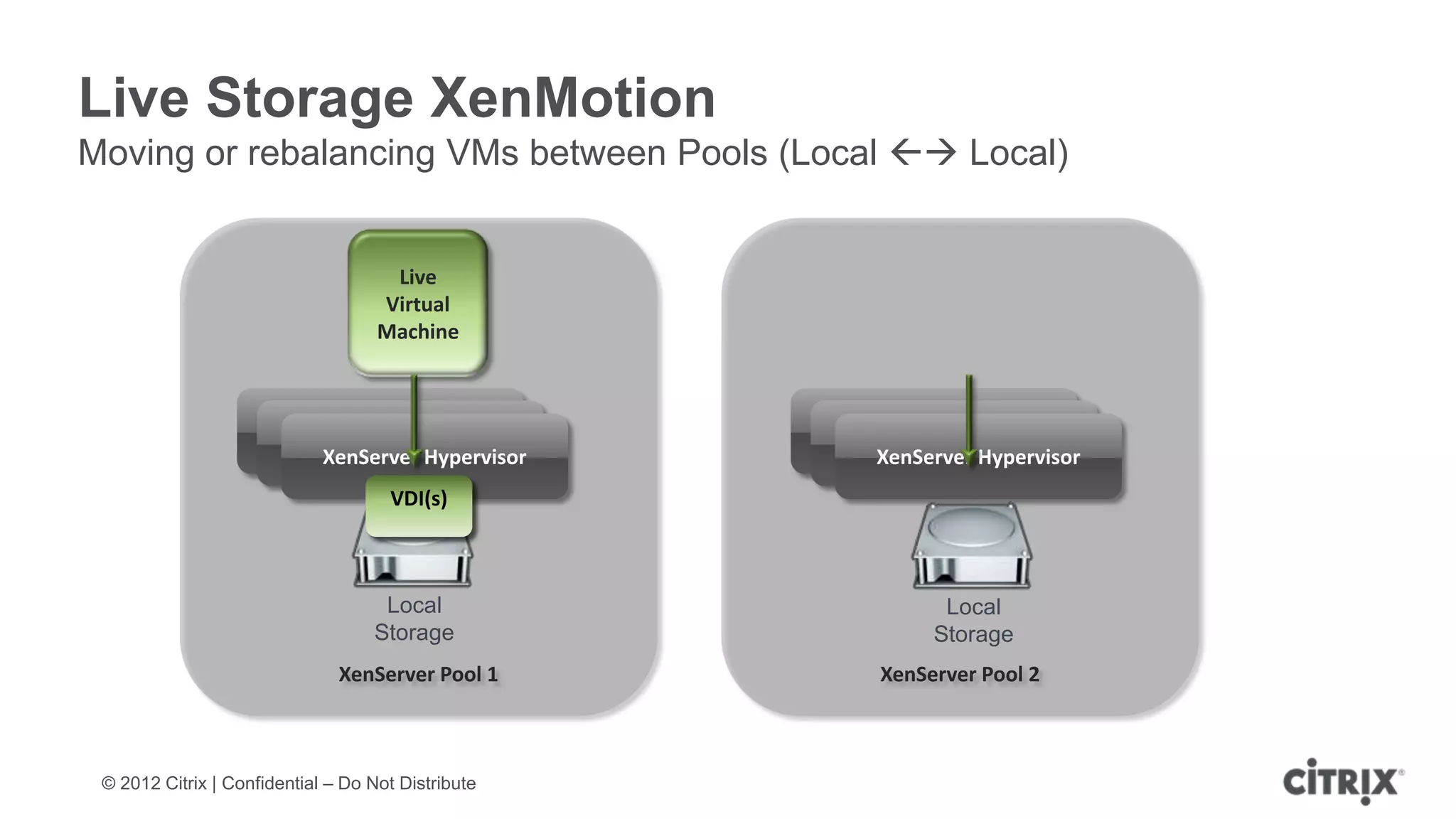
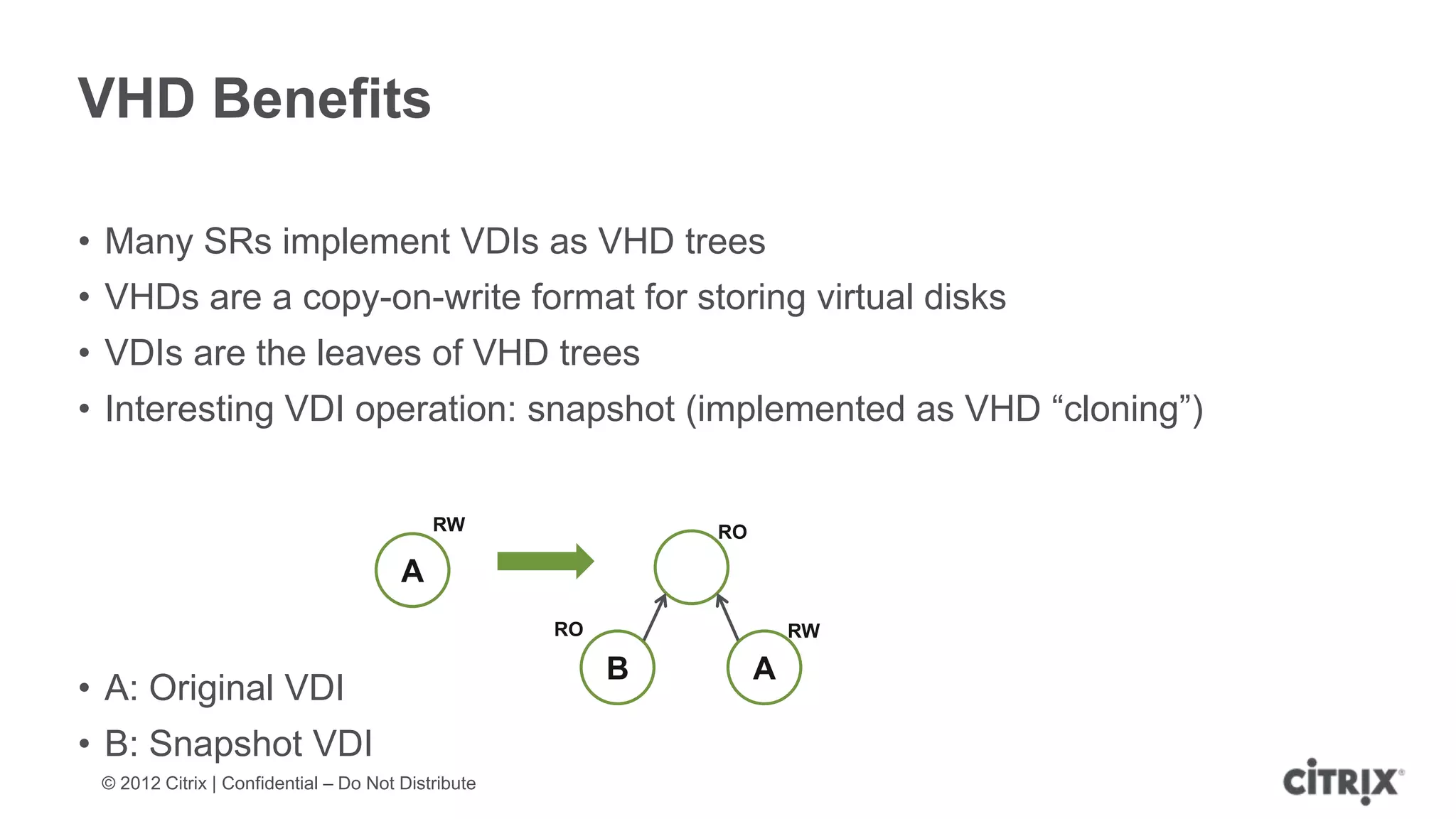
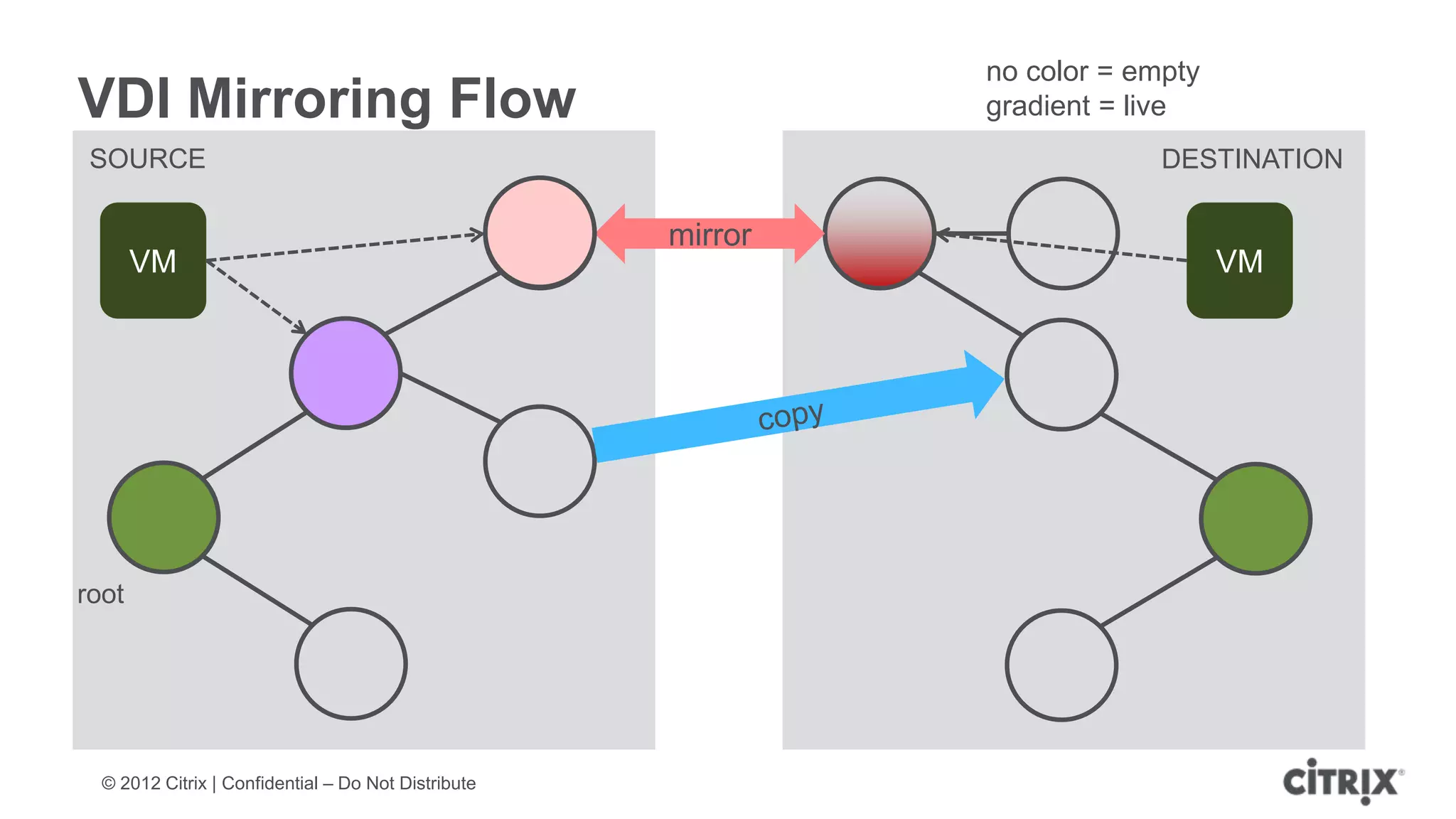



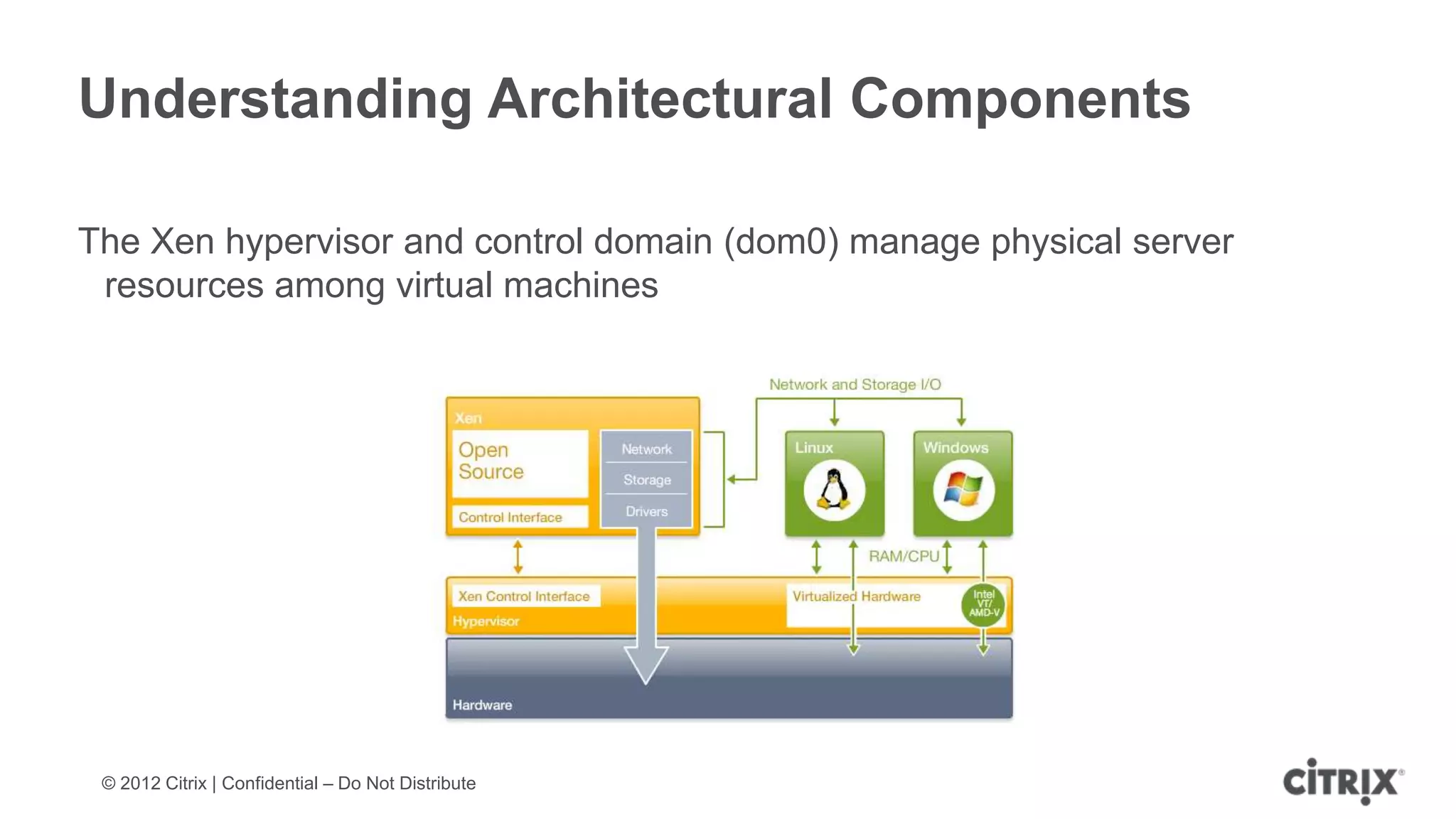
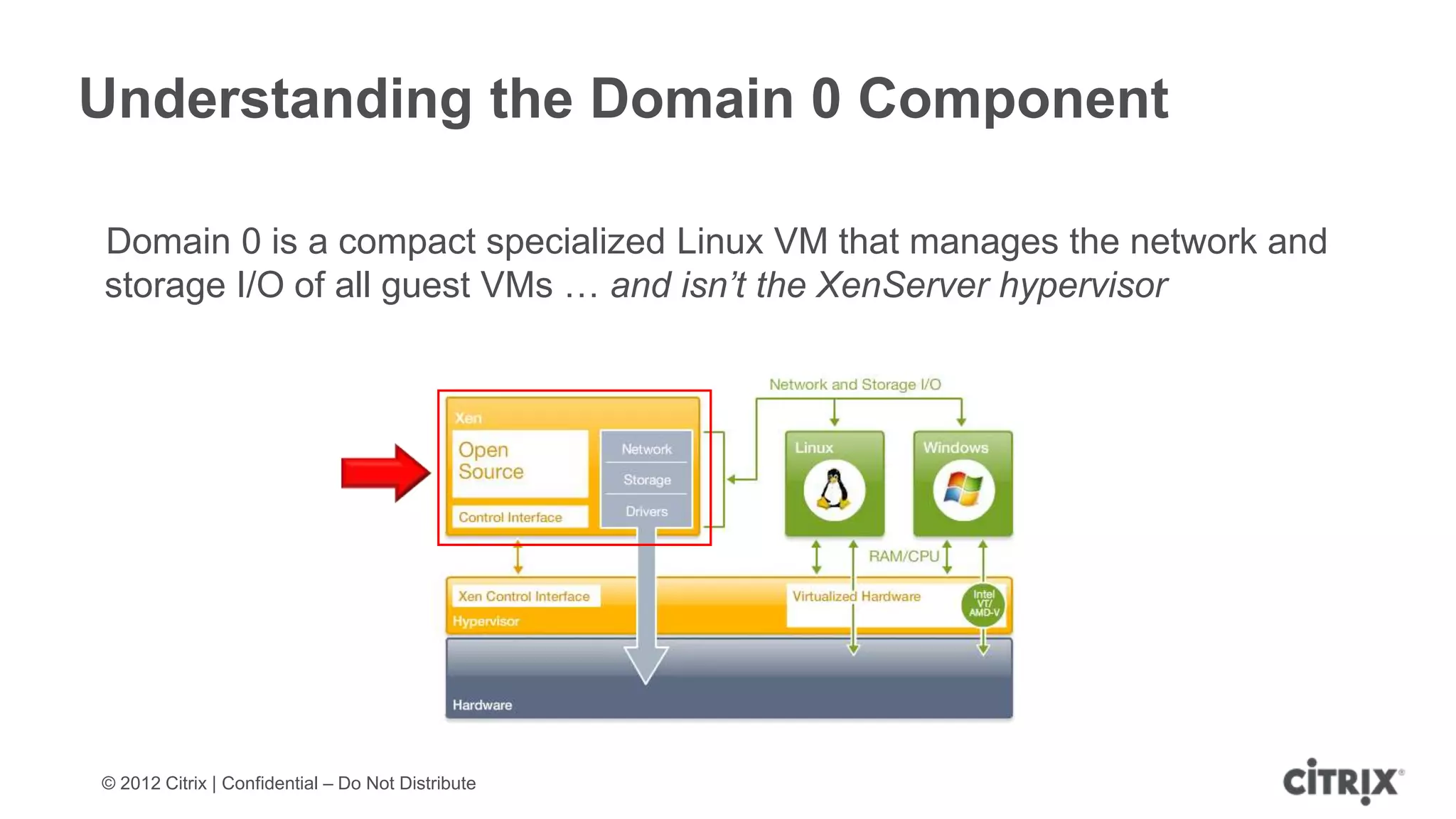
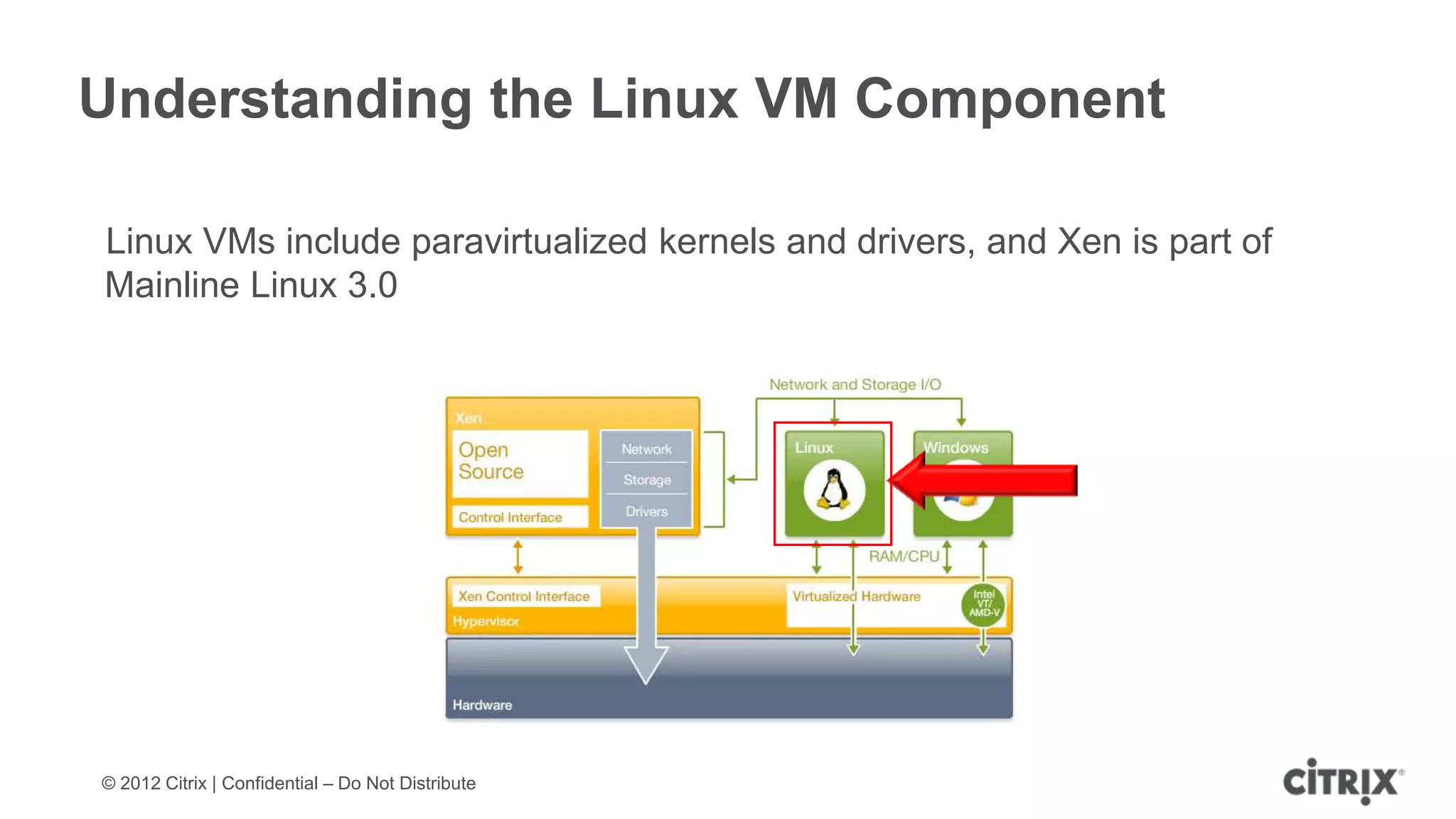
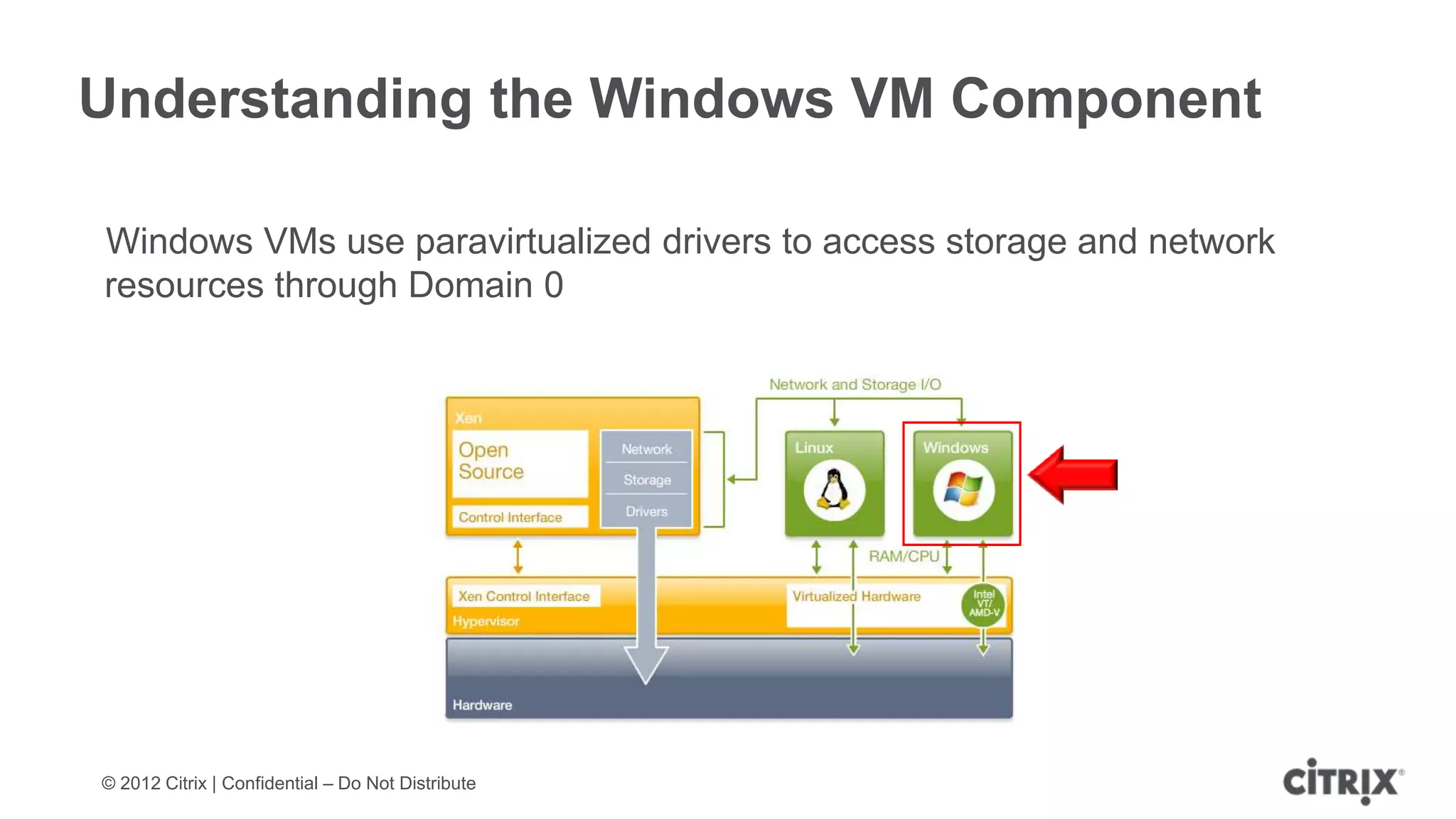
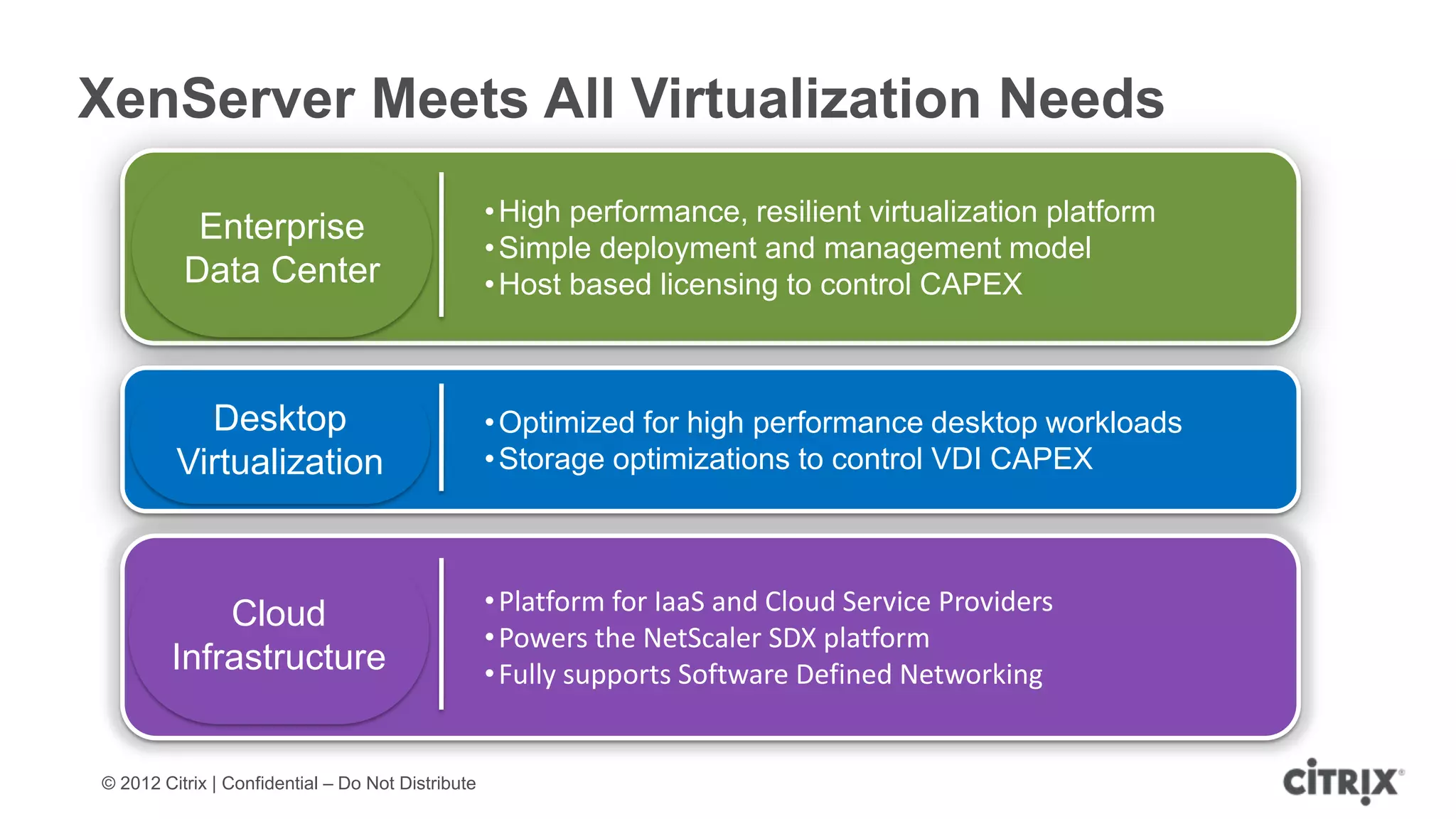
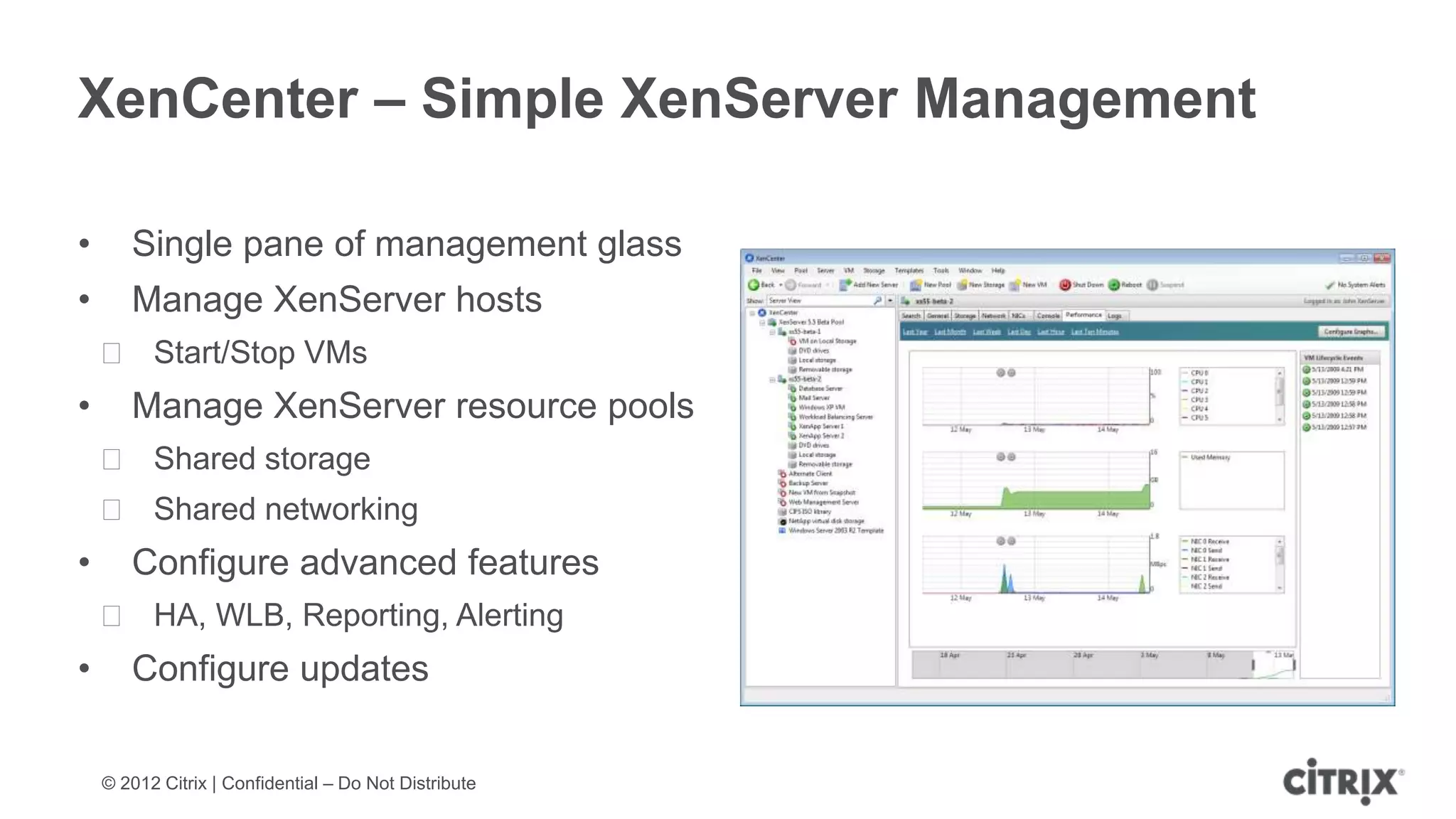
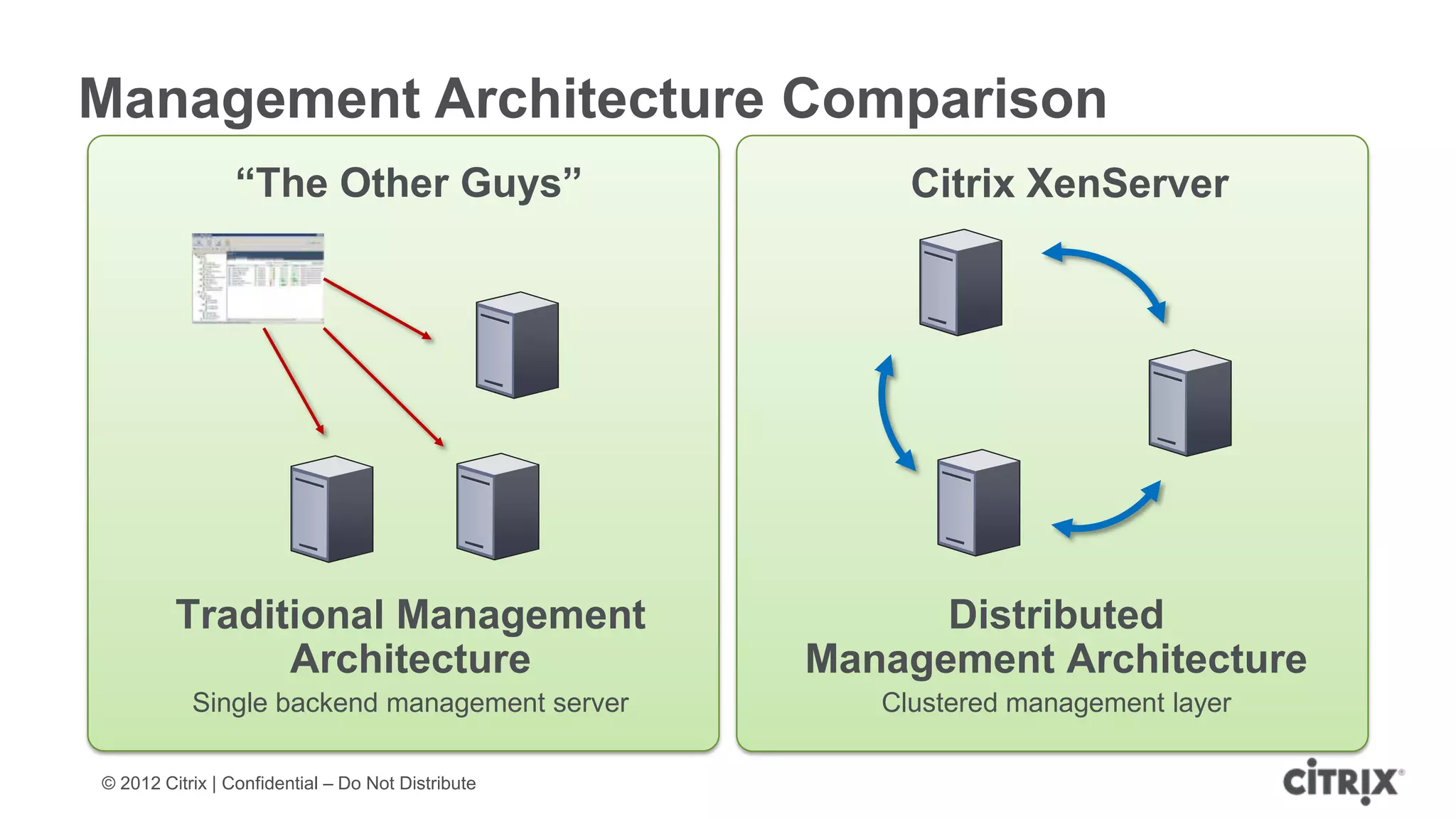
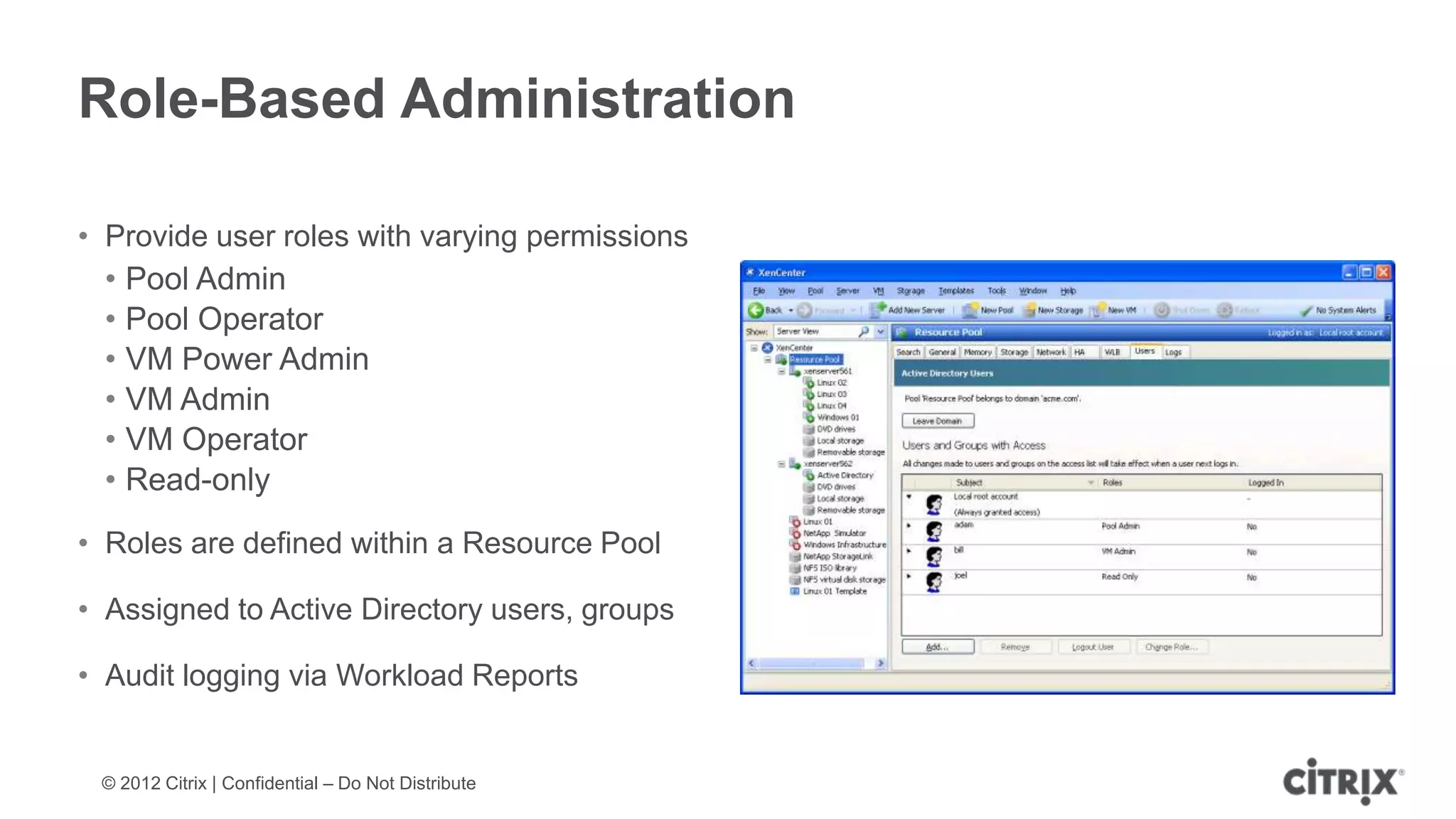
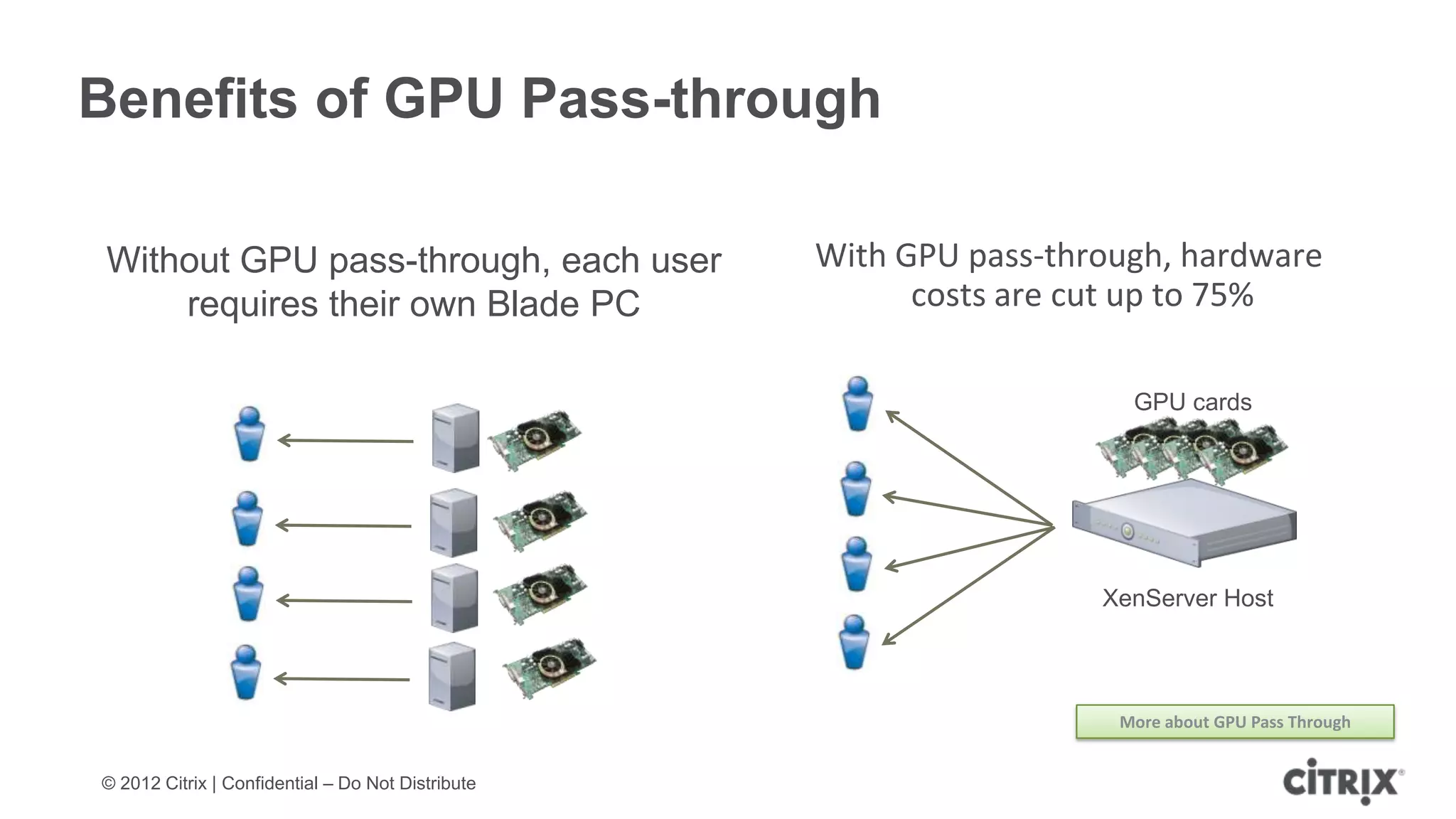
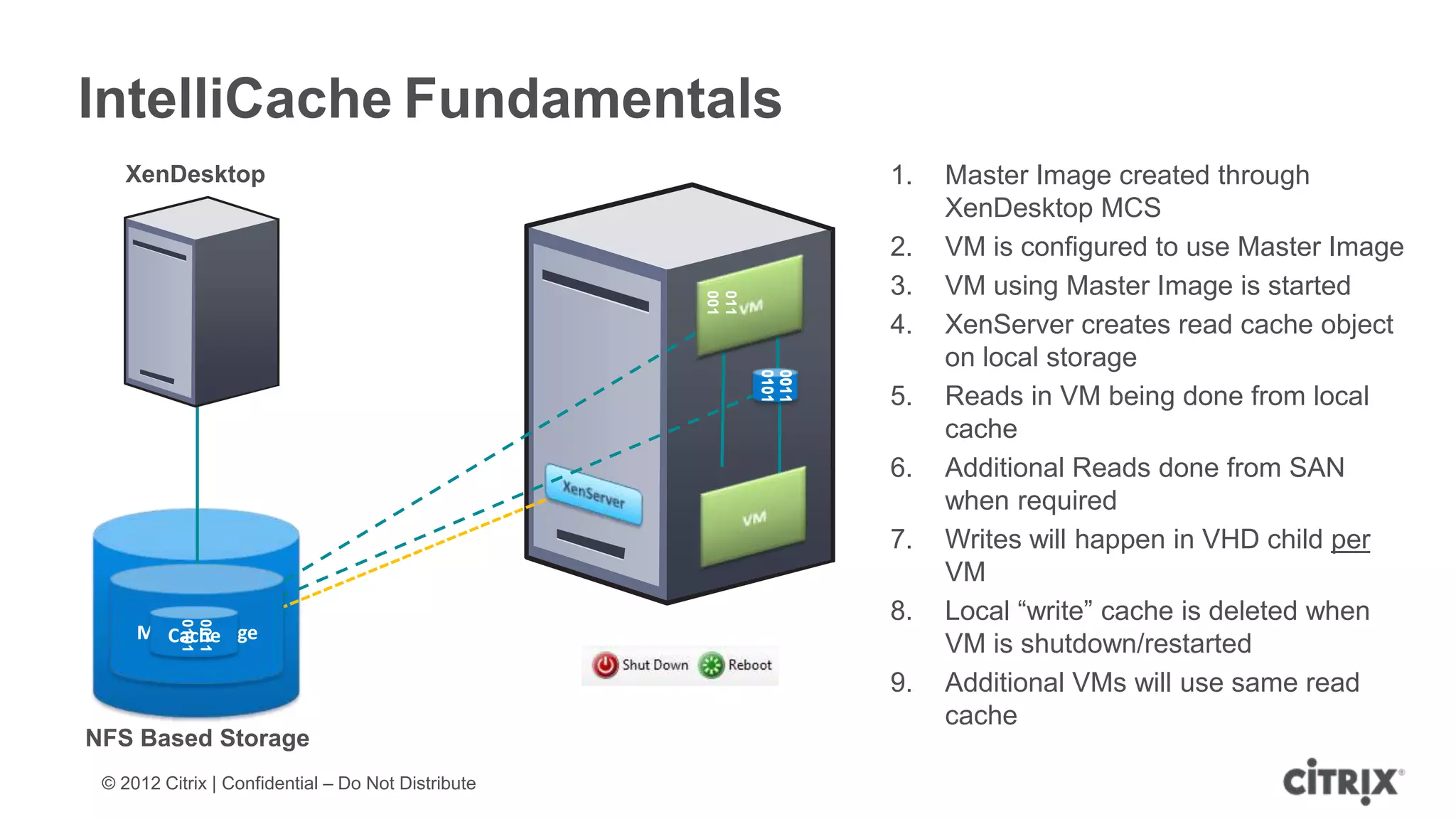
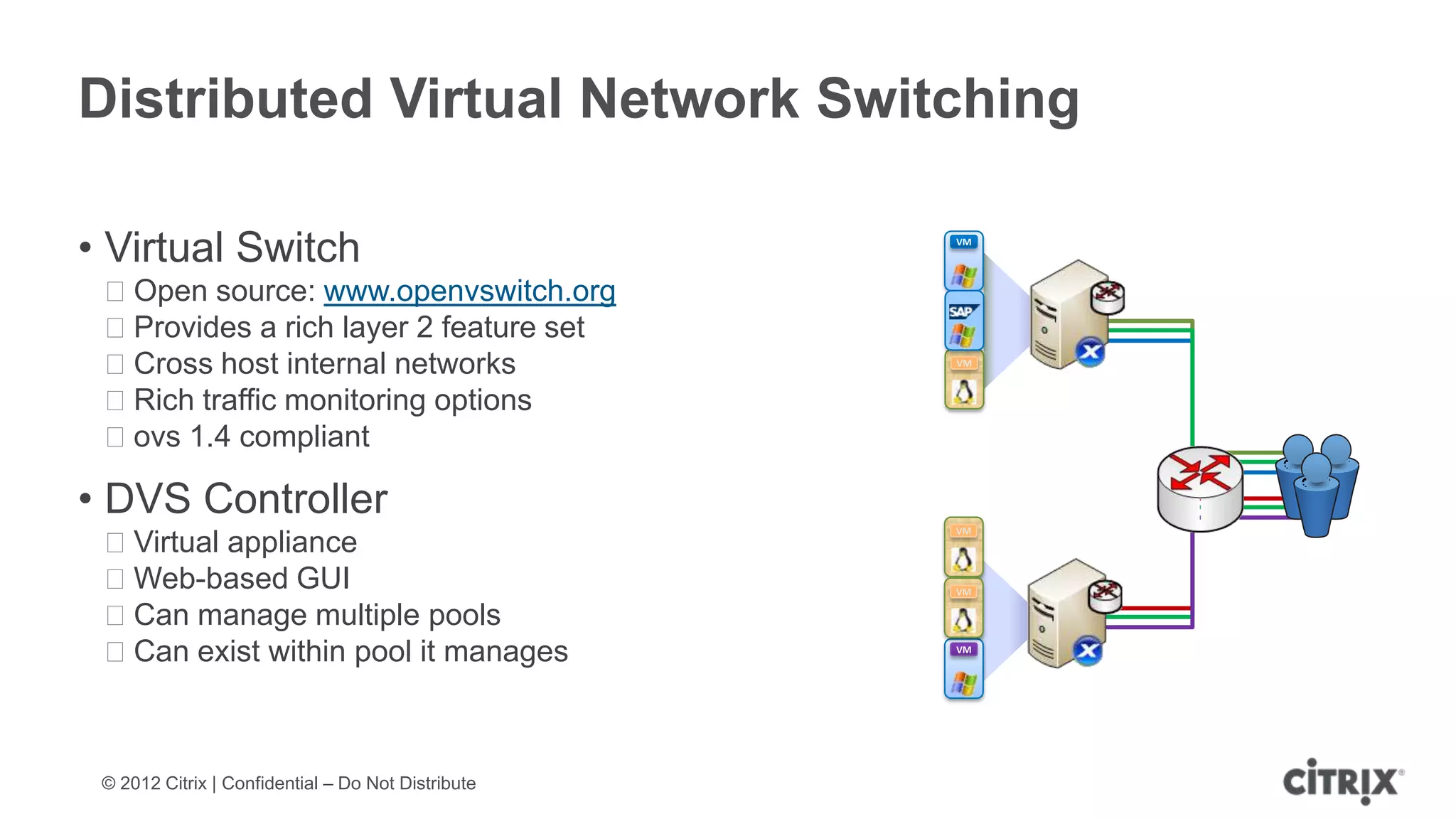
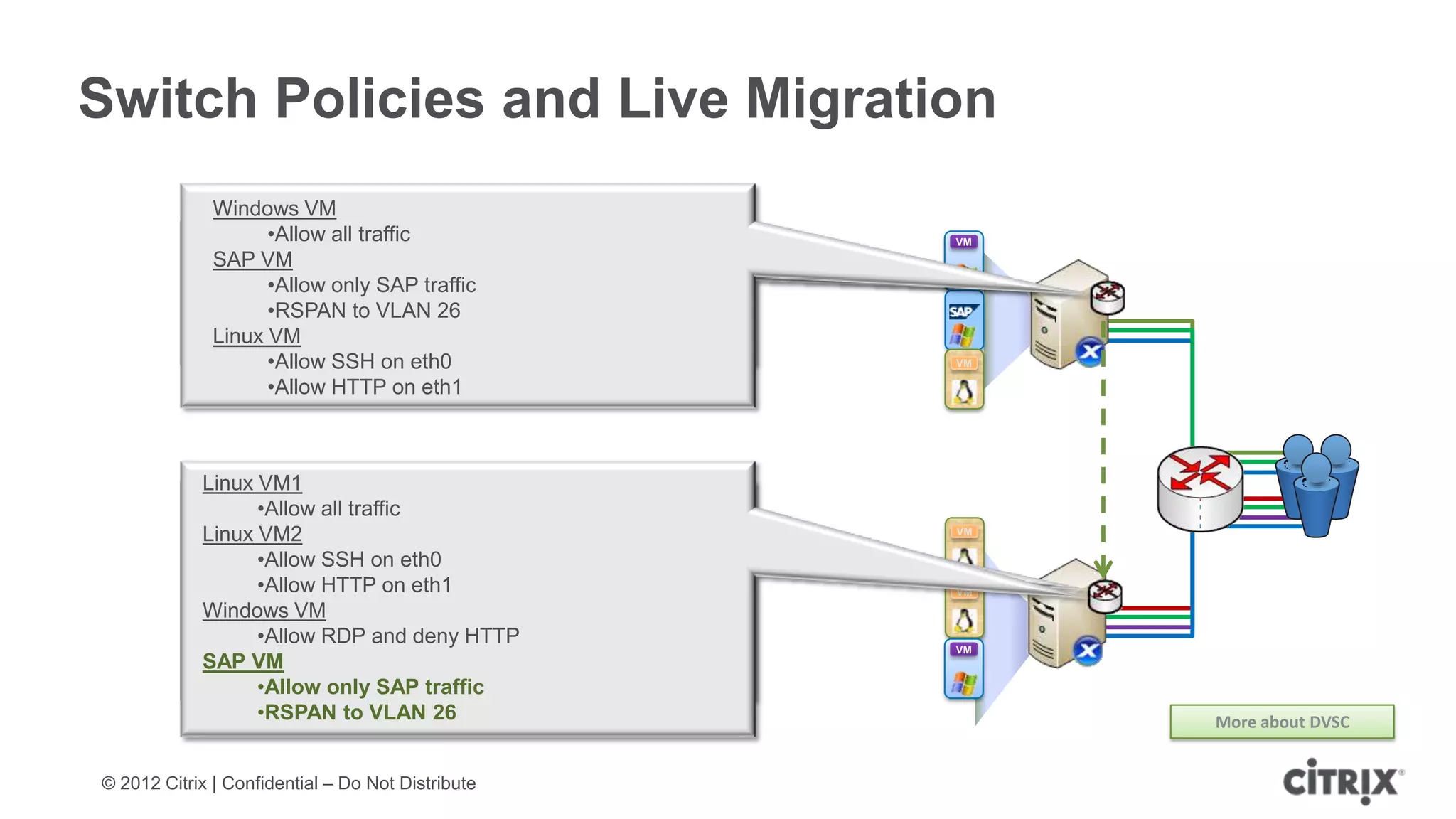
XenServer 6.1 is a powerful and widely-deployed 64-bit hypervisor solution that leverages CPU hardware for enhanced virtualization. It offers features like high availability, live VM migration, role-based administration, GPU pass-through for high-performance graphics, and optimized storage management. Designed for enterprise data centers, desktops, and cloud services, XenServer facilitates simple deployment and management with robust capabilities for automation and resource optimization.























































































