Downloaded 611 times



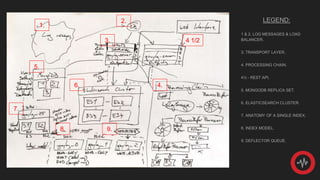







This document provides a technical overview of the Graylog data processing engine in 9 sections. It describes the key components, including the transport layer which uses an append-only journal to prevent message loss, a high speed processing chain using ring buffers, a REST API that allows building custom front ends, an embedded Elasticsearch cluster for fast writing, and an index aliasing system to seamlessly switch between indexes. The goal is to provide the fastest machine data processing through an optimized architecture and attention to small performance details.



































































