







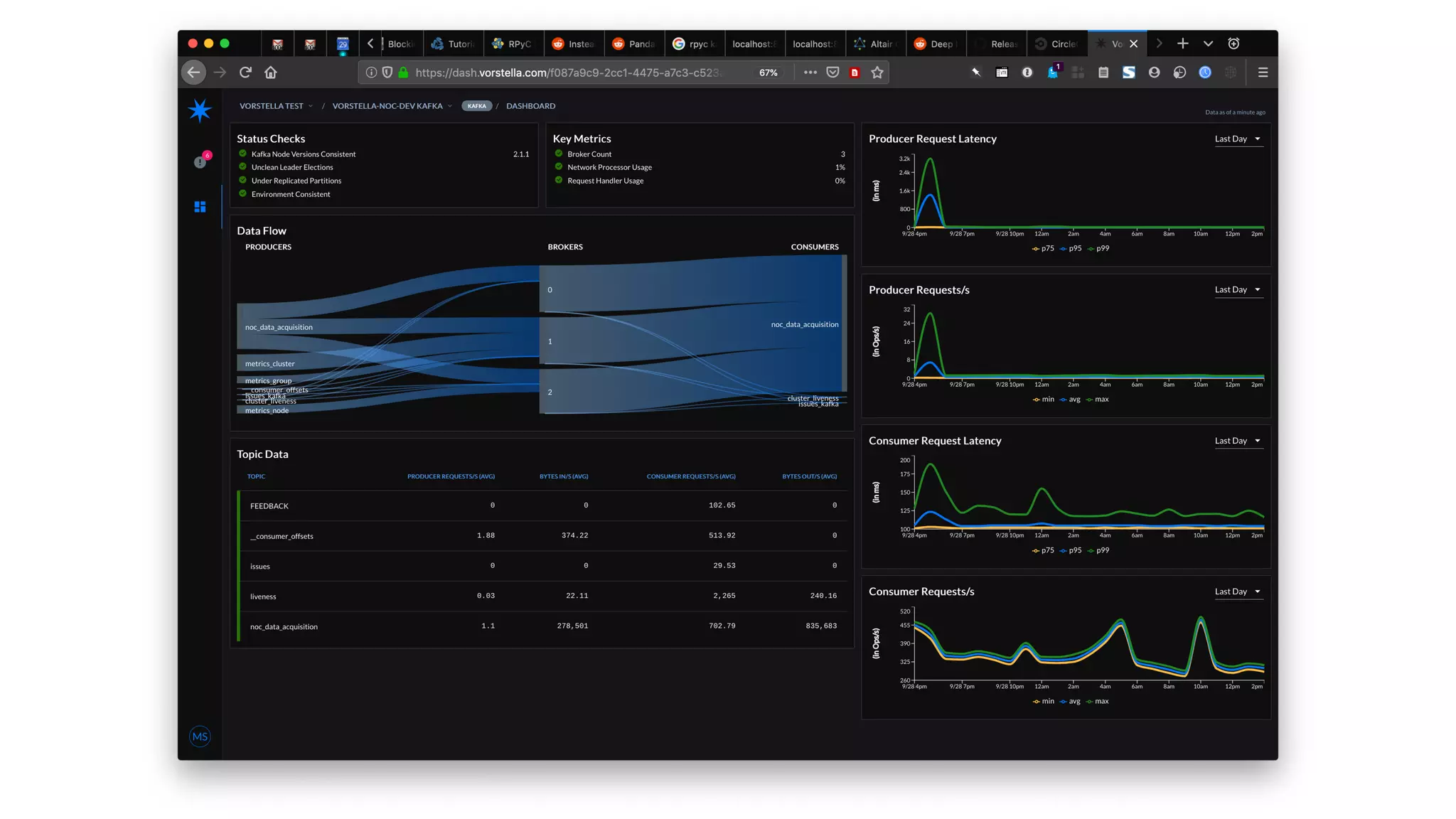
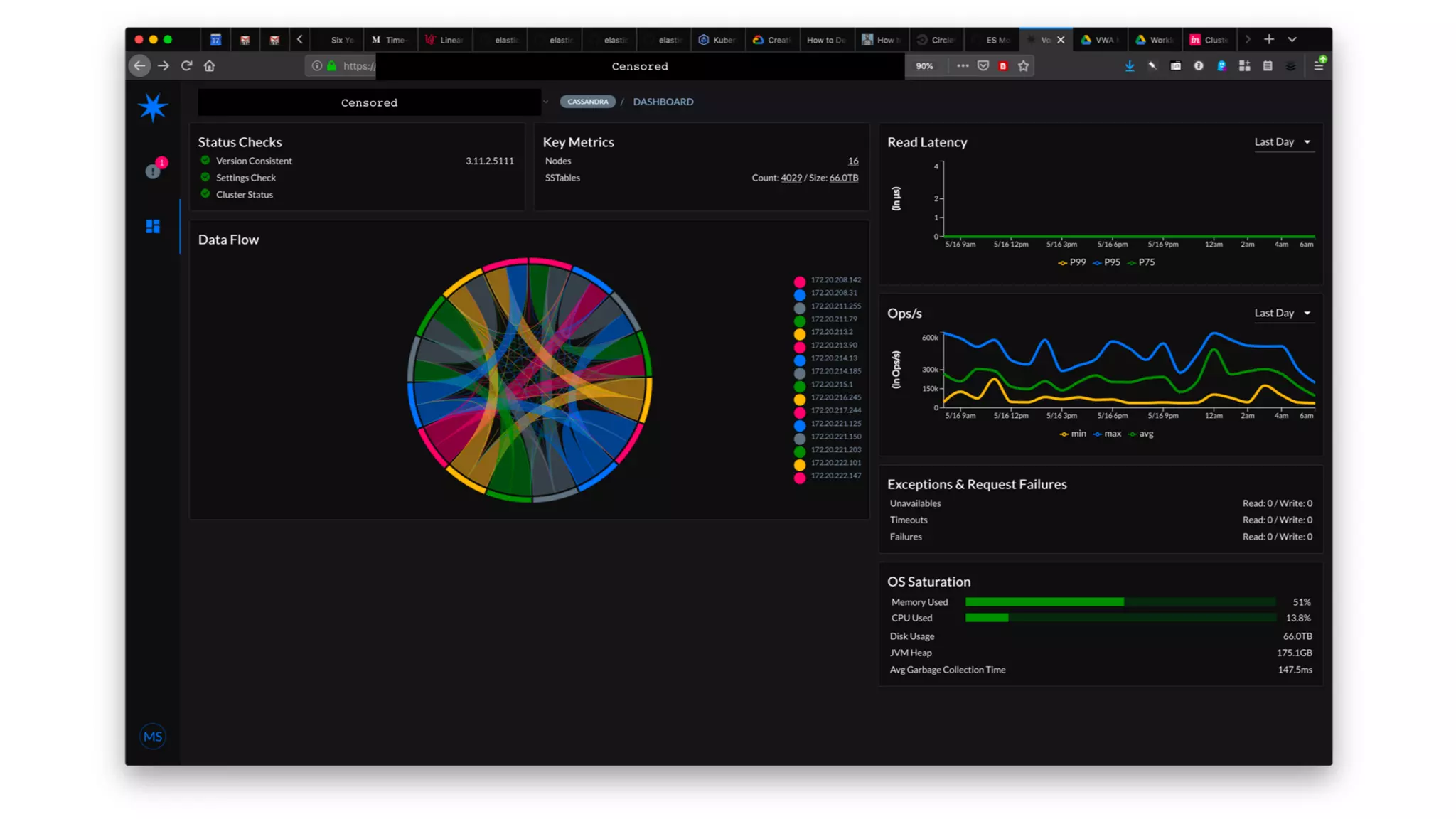
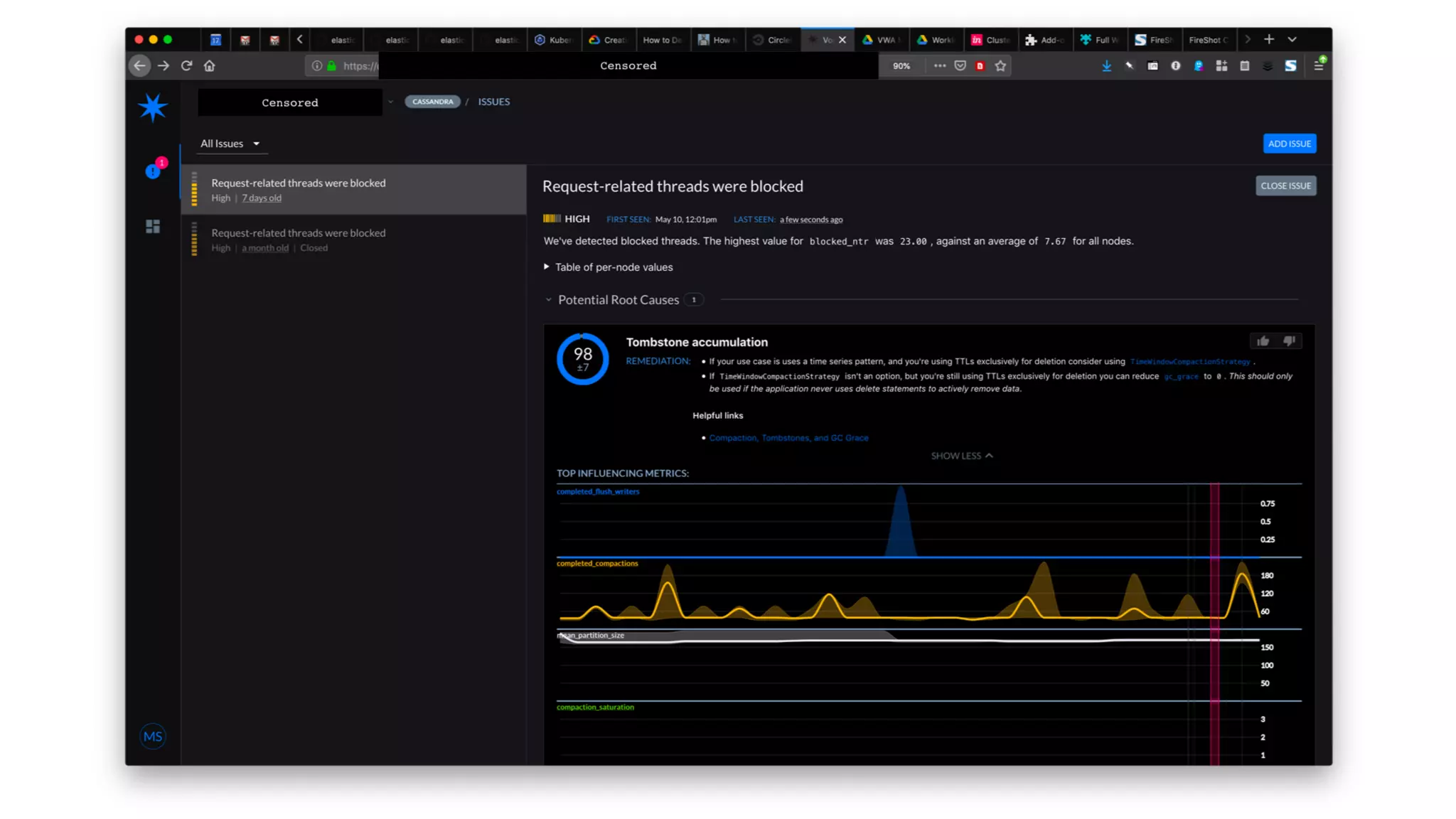
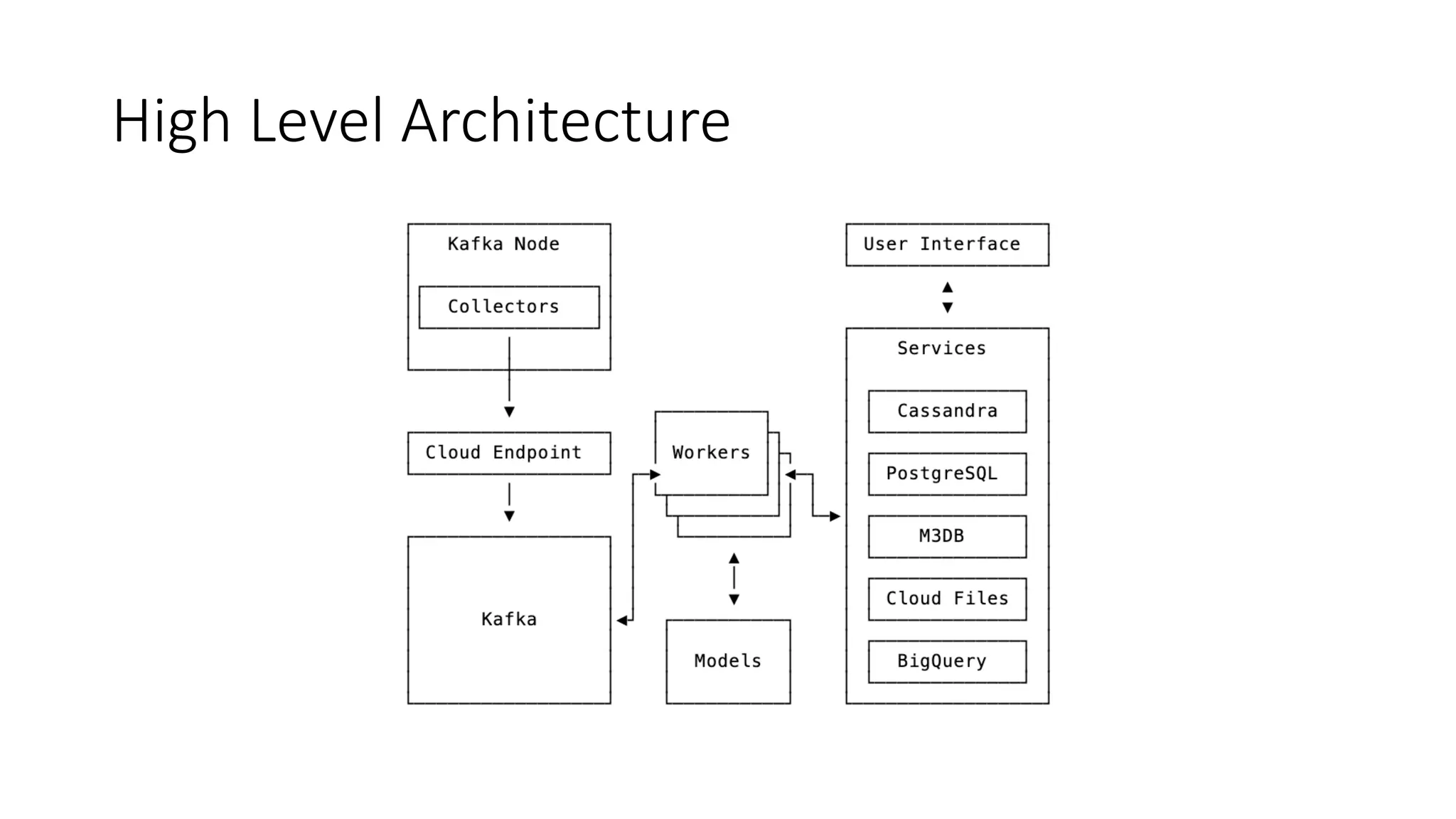
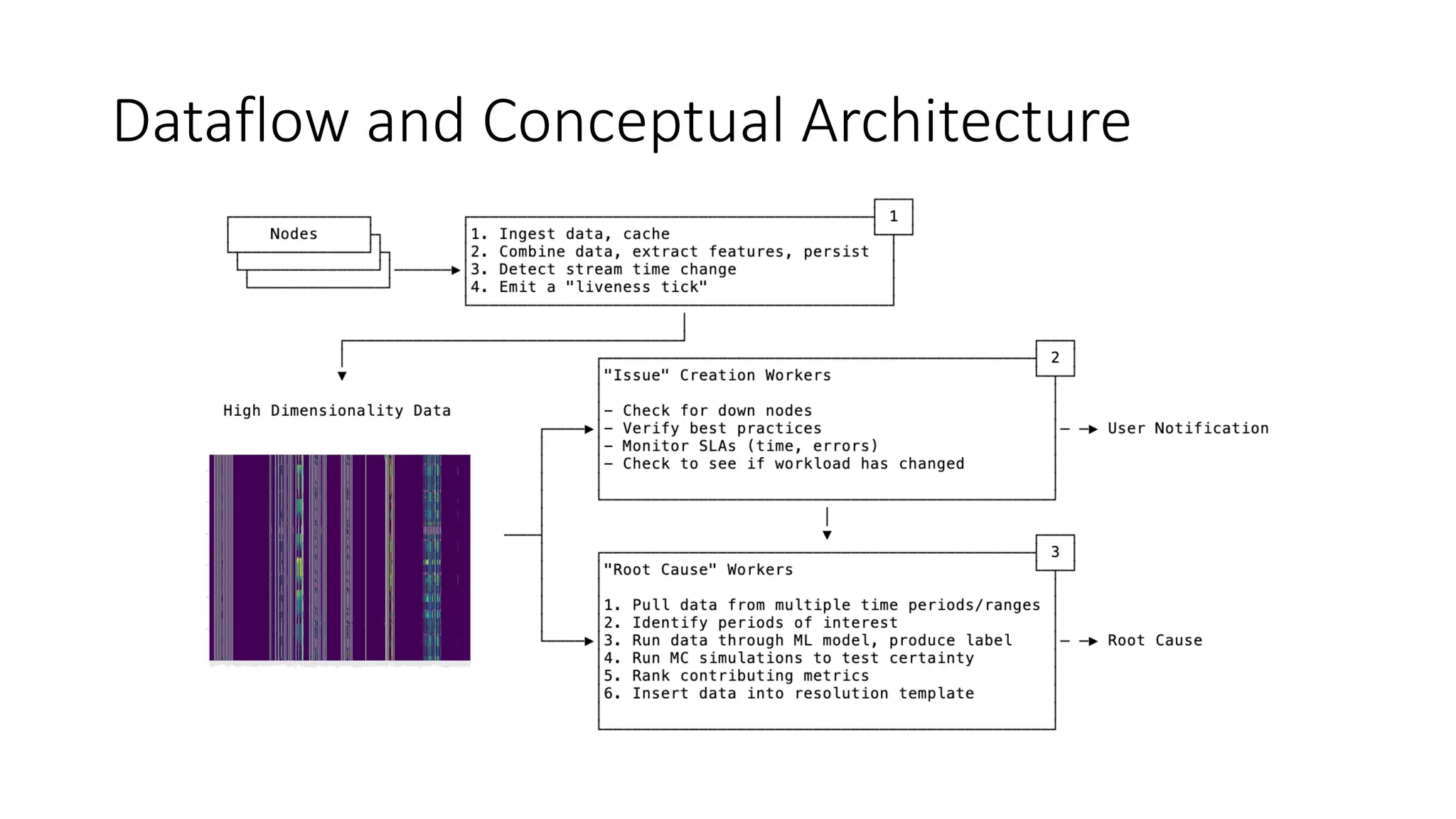










The document discusses the challenges and strategies associated with using Kafka in large-scale deployments, highlighting its architecture, machine learning models, and tuning recommendations for handling large message sizes. It addresses common issues like replication groups and cascading failures, providing solutions based on the authors' experiences with Kafka's limitations. The presentation emphasizes the need for effective documentation and improved monitoring tools to manage complex distributed systems.























































































