Downloaded 11 times












![Ontologies
• An ontology is an “explicit [formal] specification of a [shared]
conceptualization.” (Gruber, 1993)
• RDF is the data model.
• RDF, RDFS and OWL are ontology languages.
• RDF à Declare types and relations;
• RDFS à Declare type- & role hierarchies, domains and rages, etc.
• OWL à Properties of relations, Disjointness, etc.
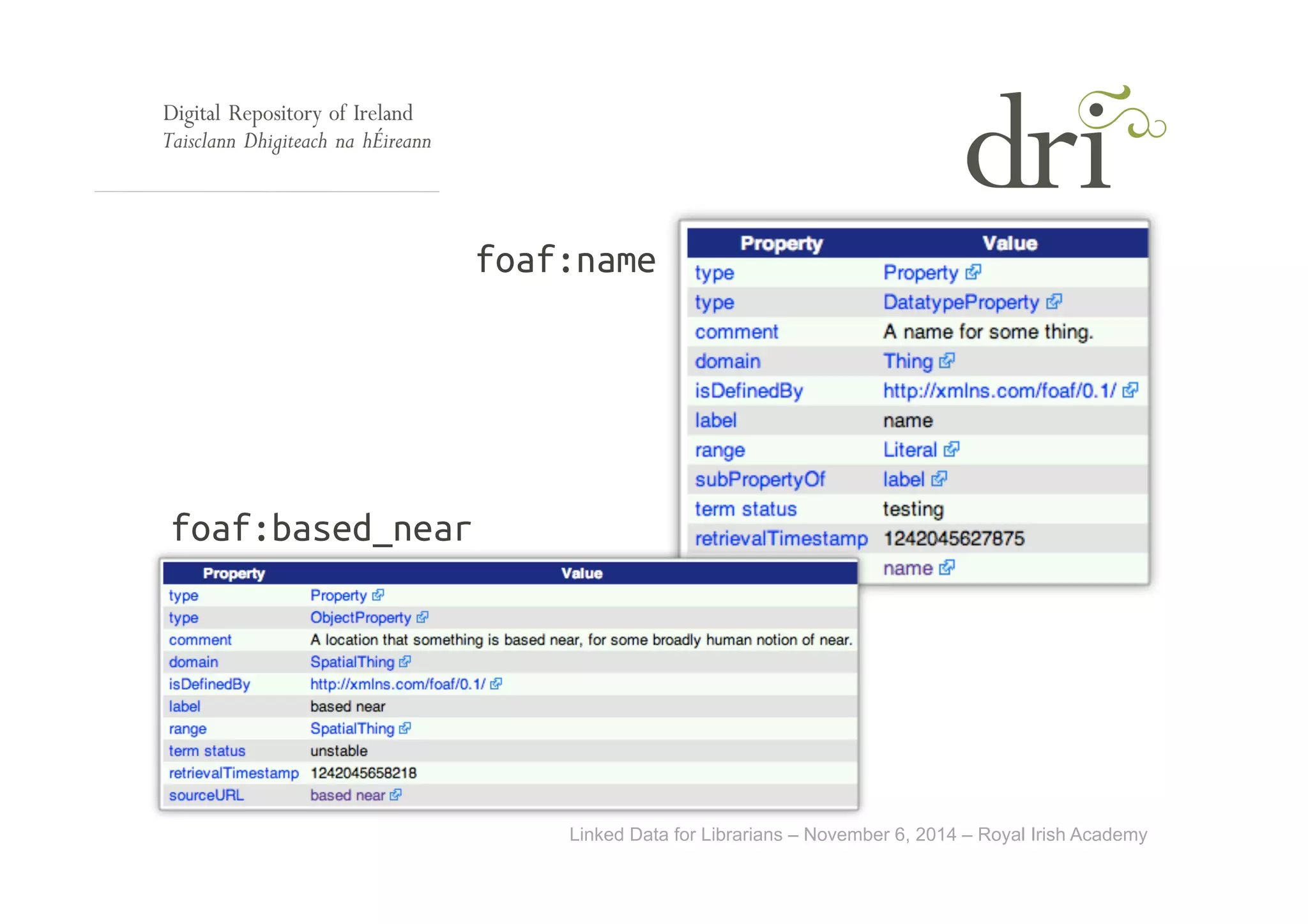
• Popular ontologies for instance are Friend-of-a-Friend (FOAF),
Simple Knowledge Organization System (SKOS), Dublin Core terms
• Ontologies allows us to describe resources.
Linked Data for Librarians – November 6, 2014 – Royal Irish Academy](https://image.slidesharecdn.com/2014-141109071904-conversion-gate01/75/What-is-Linked-Data-14-2048.jpg)


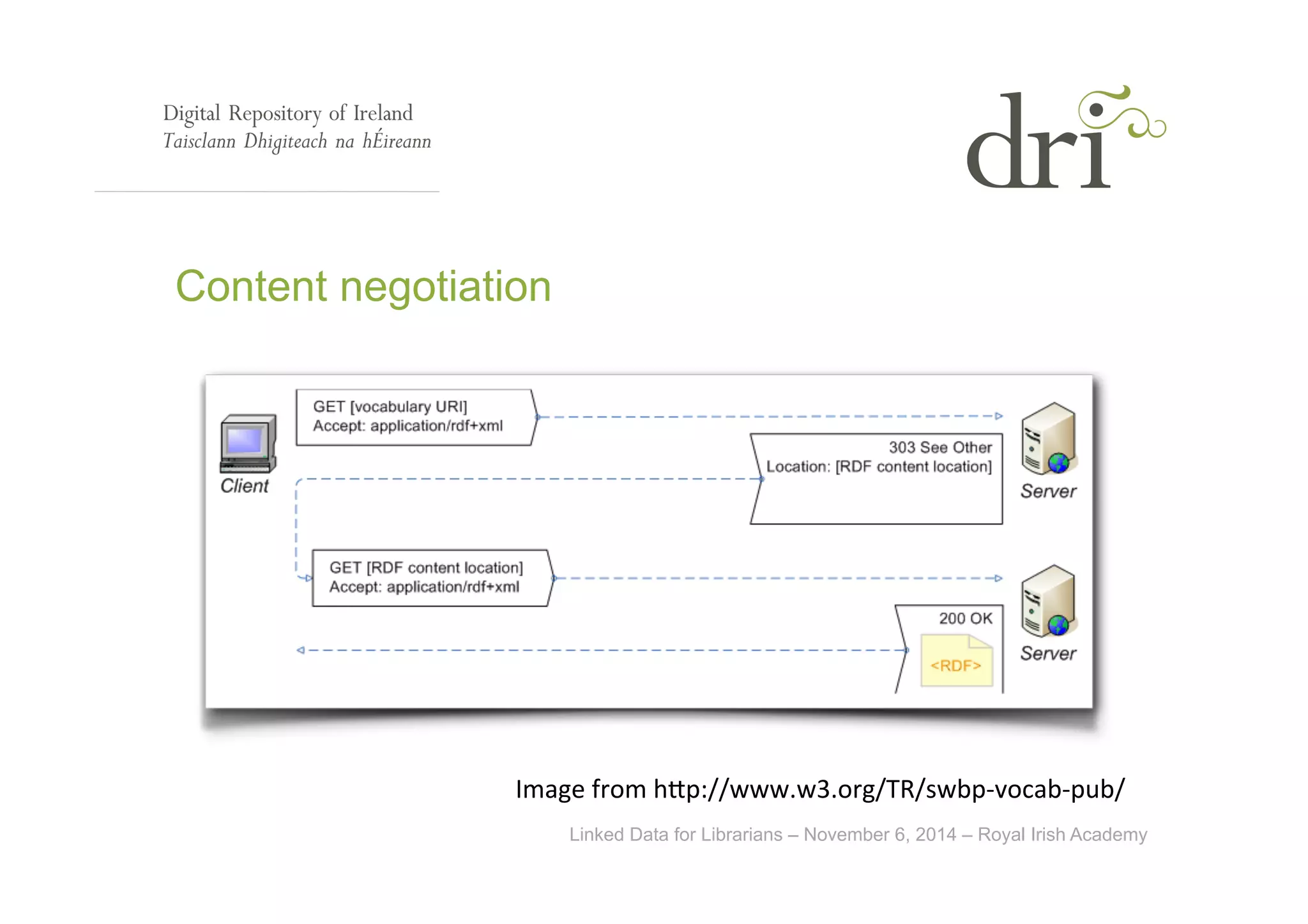


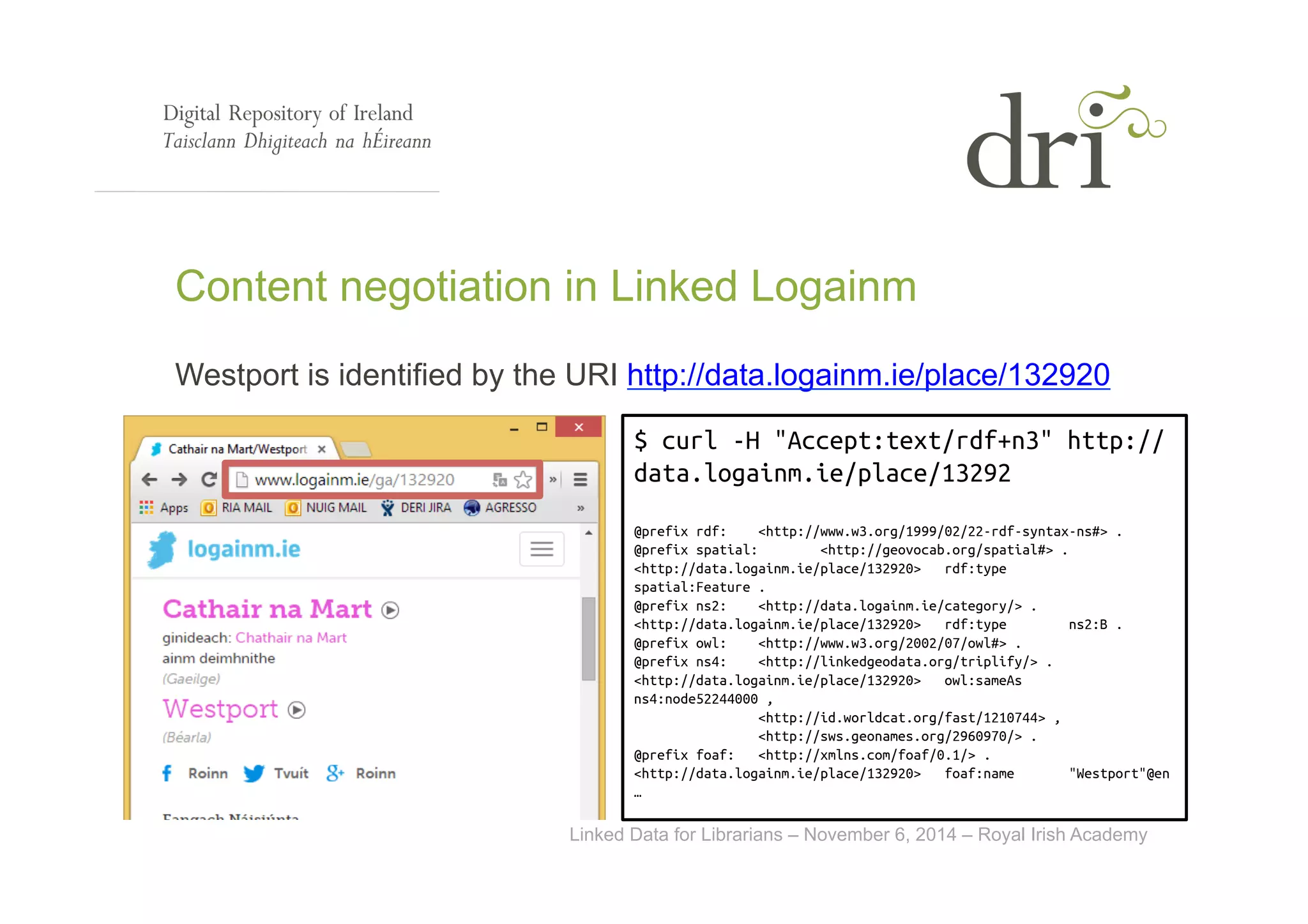


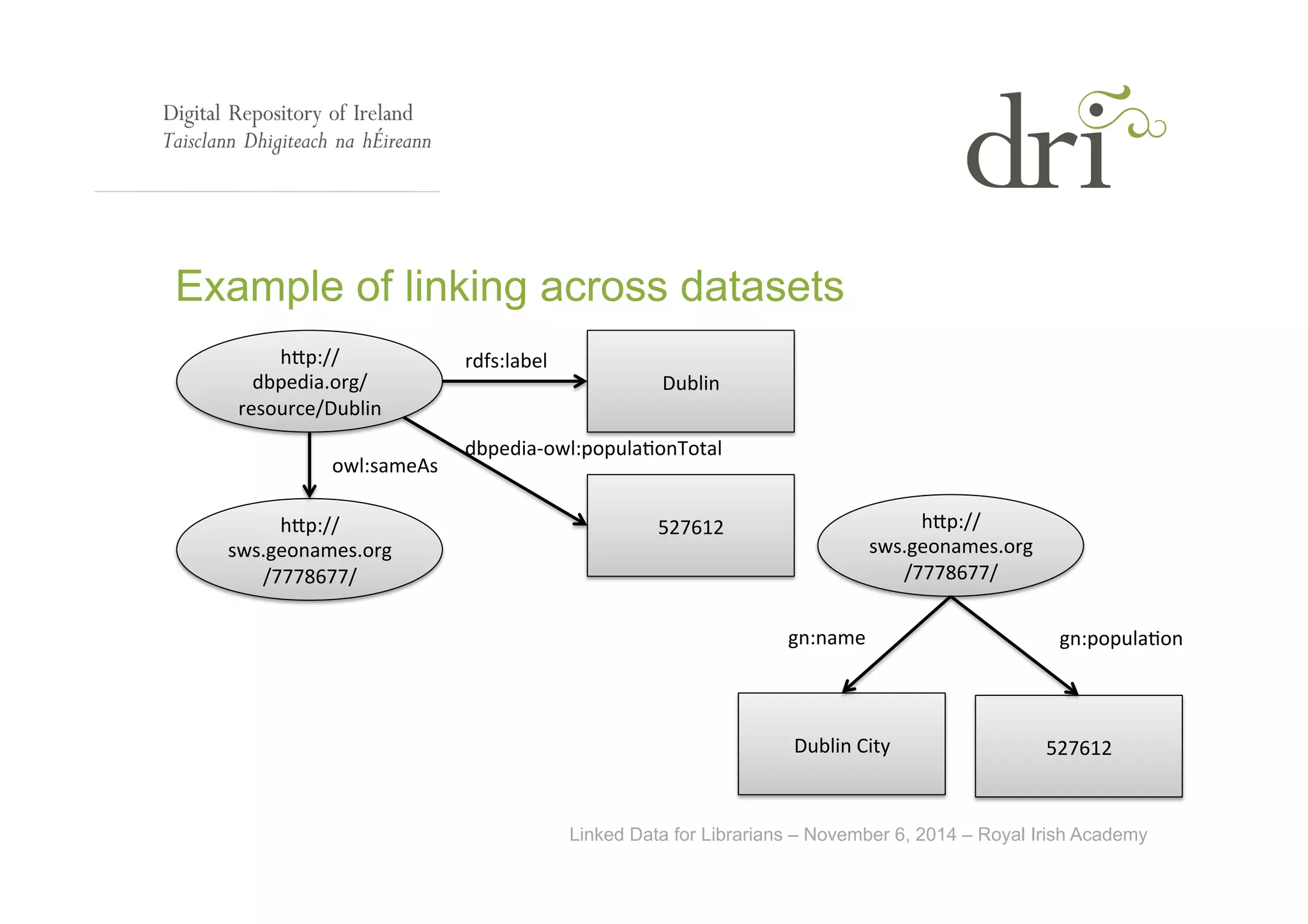
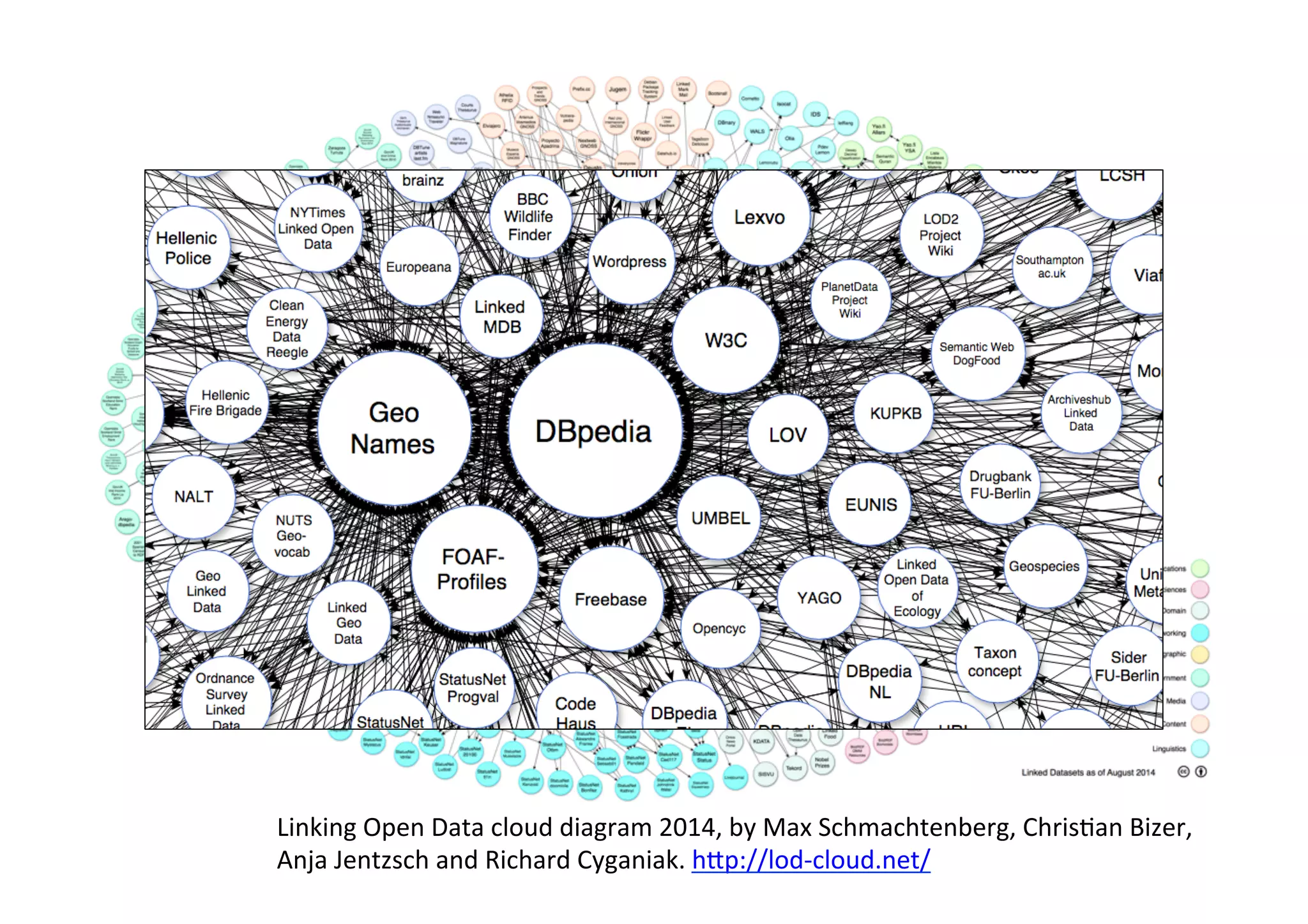


The document provides an overview of linked data, an initiative aimed at publishing and interlinking structured data on the web using well-established technologies like URIs and RDF. It outlines the four principles of linked data, emphasizing the importance of using HTTP URIs for easy data lookup, supplying useful information when URIs are accessed, and including links to other URIs for broader discovery. Additionally, it discusses the role of ontologies in data description and presents examples of linked data applications in library and information science.






























































































