
![What are the risks of moving to the cloud?
IDC(Survey Q4 „09) Results from actual pilots (March 2010)
Perception Primary Benefits Biggest Issues
Before Reduced IT costs Security
“The Maturing Cloud: What It
Will Take to Win” (Published Mar After Scalability Performance
2010)
What are the major risks in the Agility SLA Management
Cloud?
• Security – 87.5%
• Availability – 83.3%
• Performance – 82.9%
(88.6% stated that cloud
“All About The Cloud” Conference (May 2010)
service providers need to
“Security in the Cloud isn‟t any harder than it is in the
provide SLAs)
Enterprise – it‟s just different” (Unisys)
“[Application] Performance Management in the Cloud is
becoming the hot topic” (THINKstrategies)
Projects fail to deliver acceptable performance
Moving Legacy Applications is harder than thought](https://image.slidesharecdn.com/cloudexpo2011santaclara-whatdoesperformancemeaninthecloud-111121041205-phpapp02/75/What-does-performance-mean-in-the-cloud-2-2048.jpg)






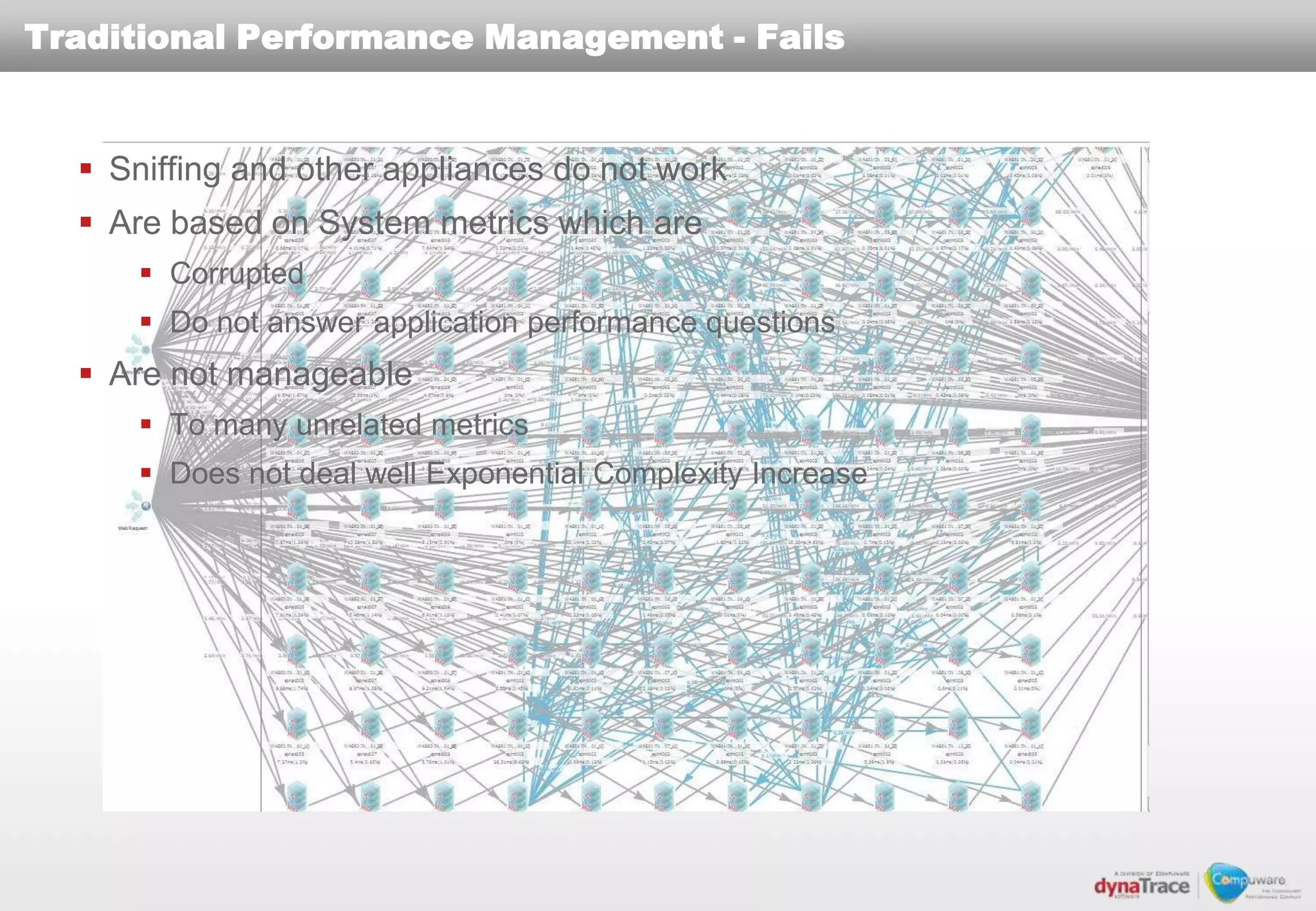
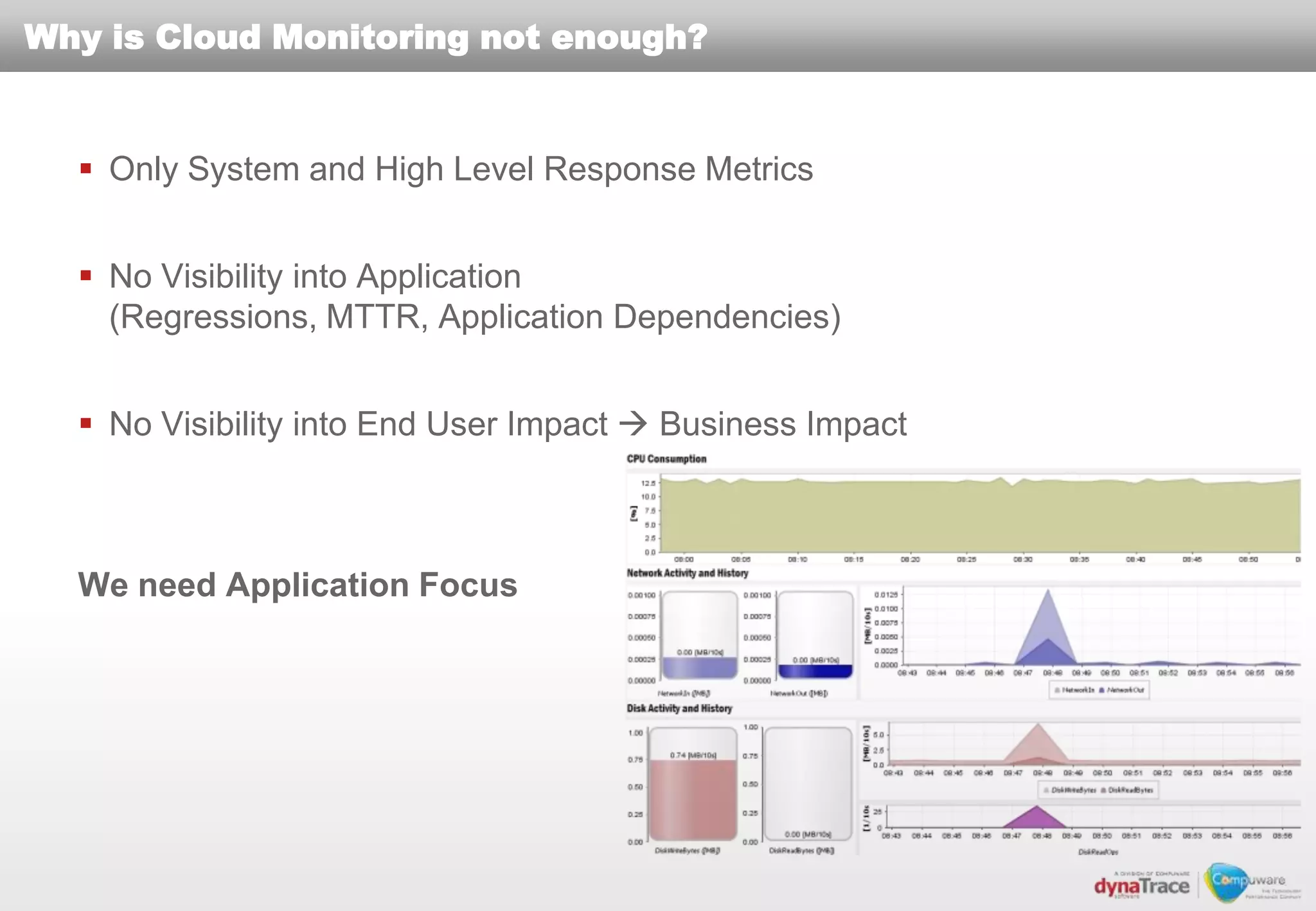
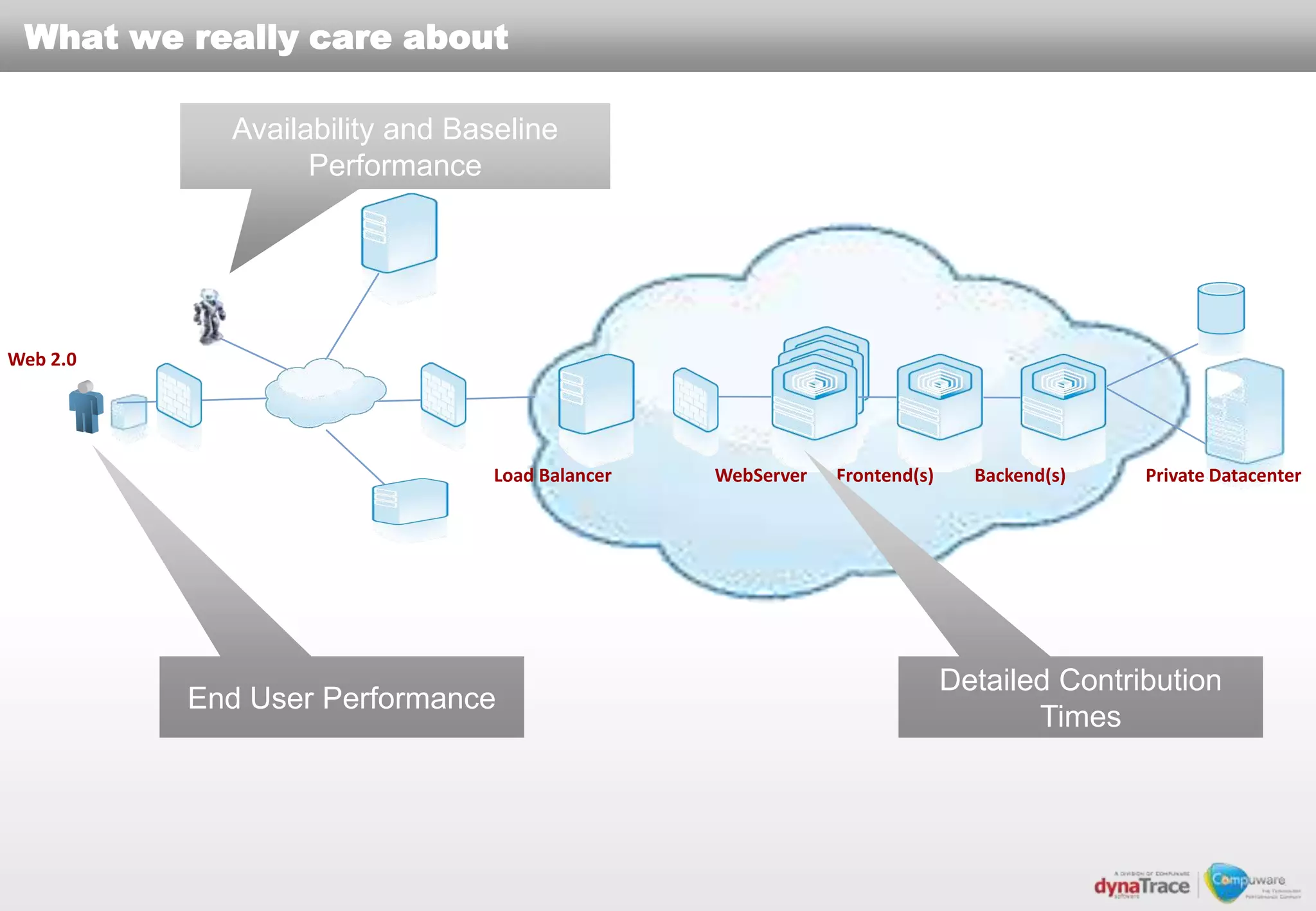
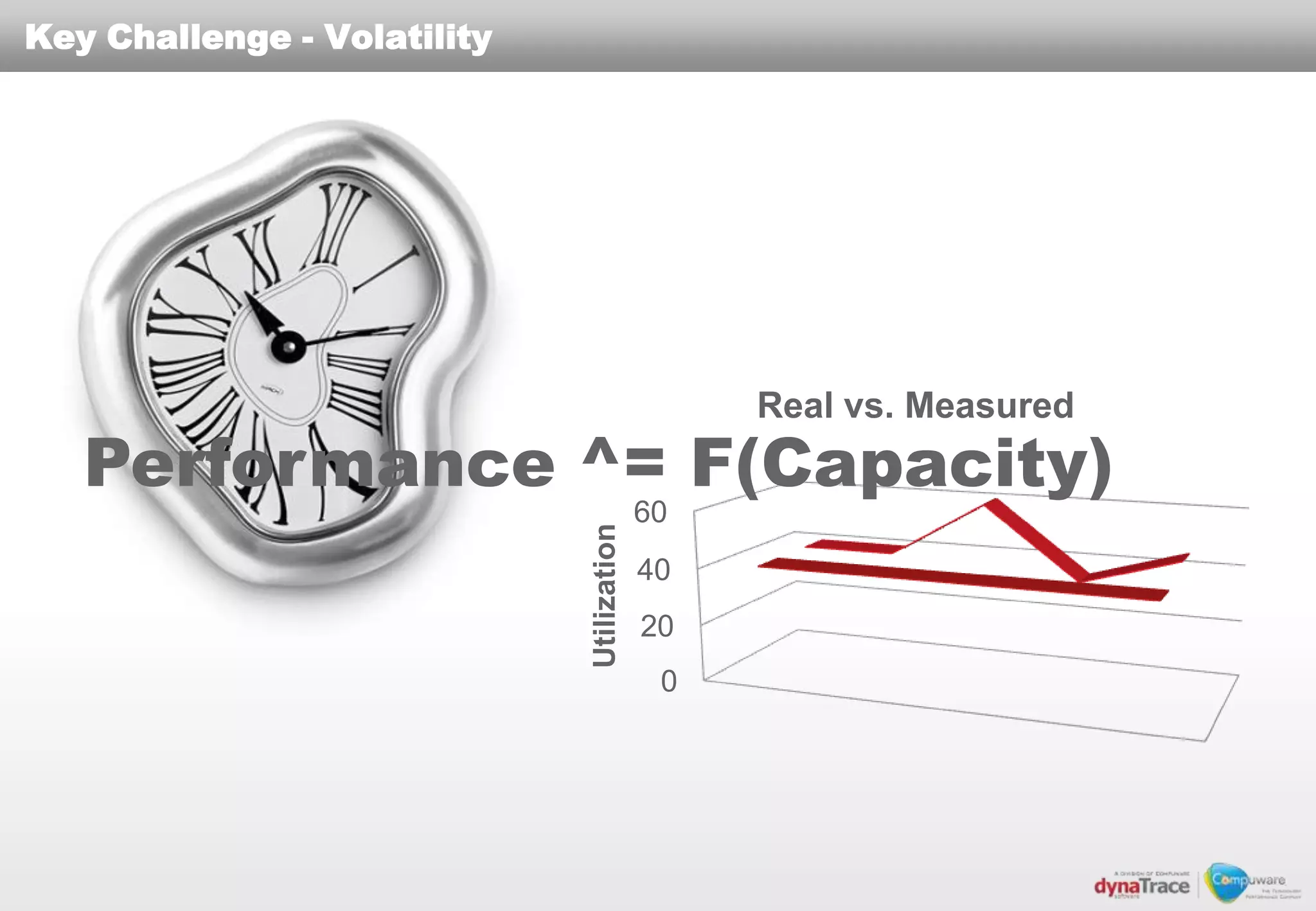
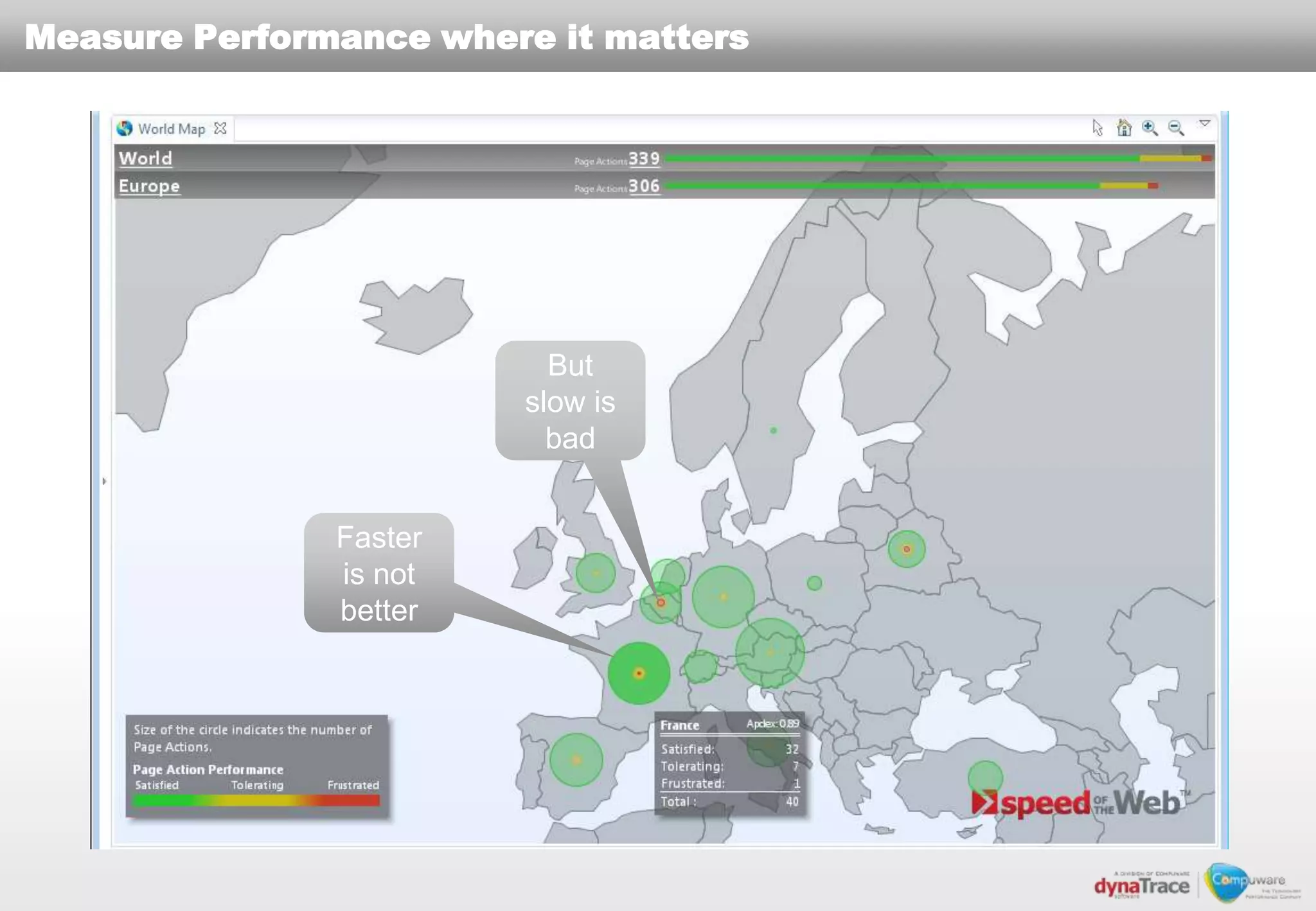
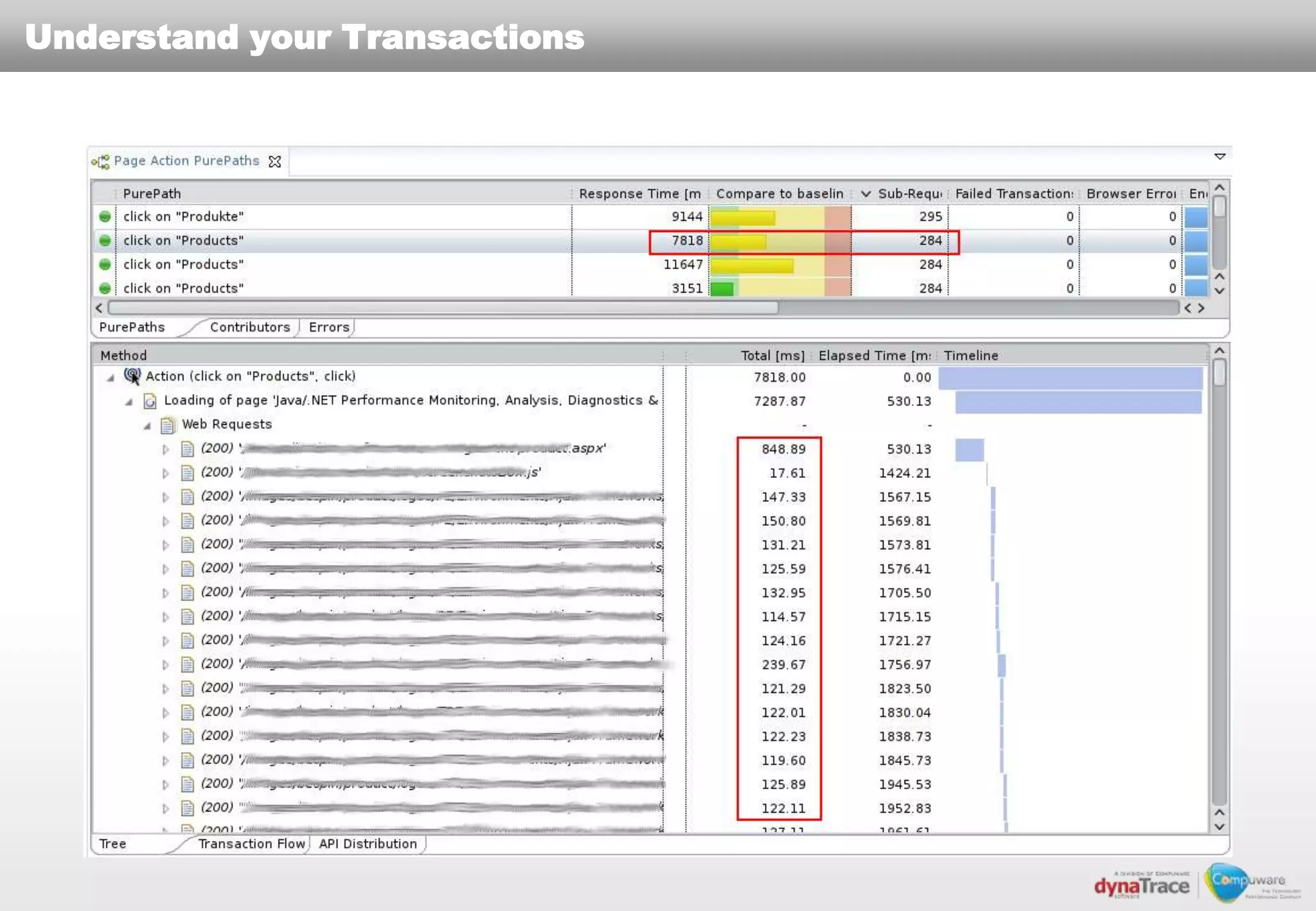
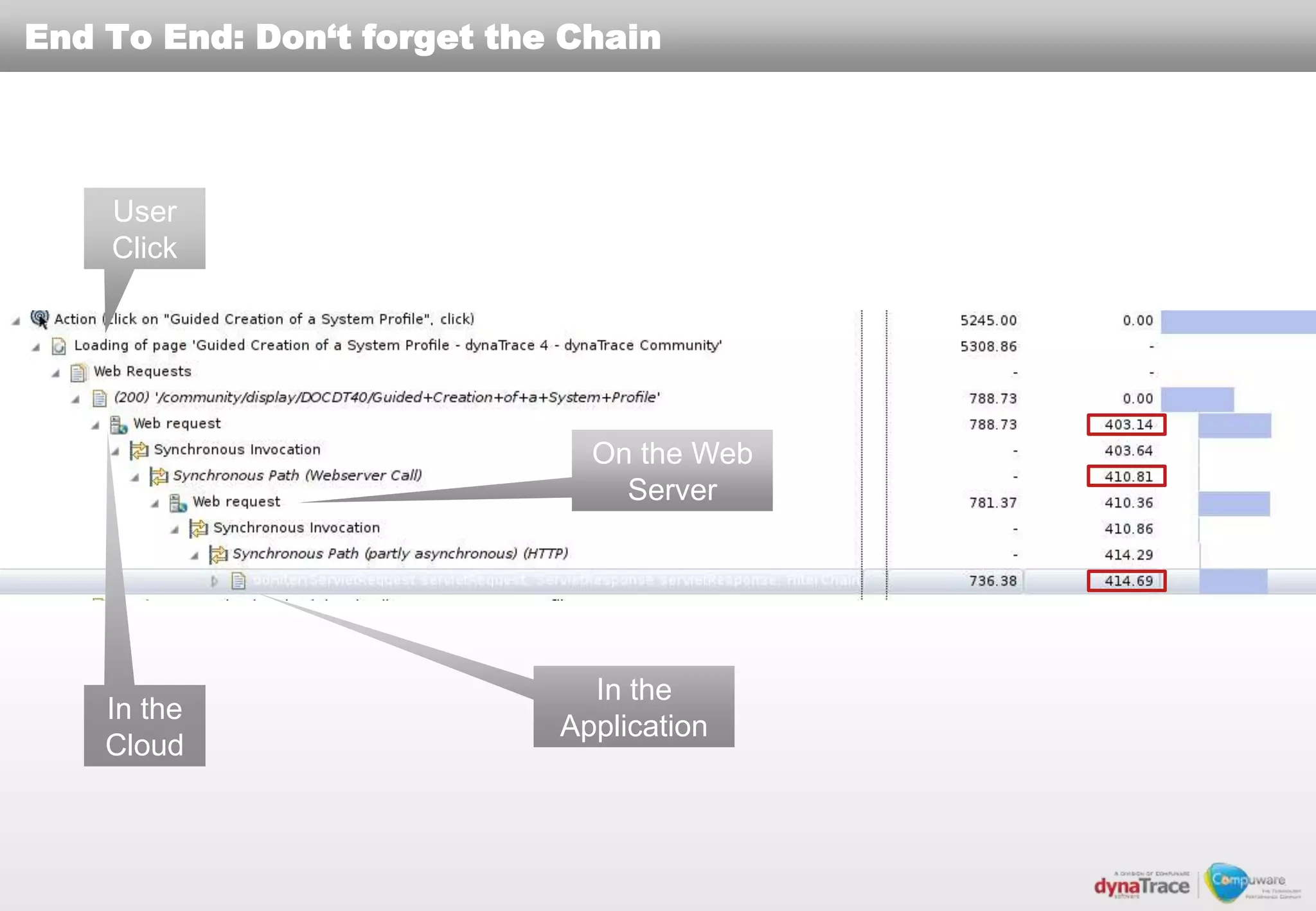
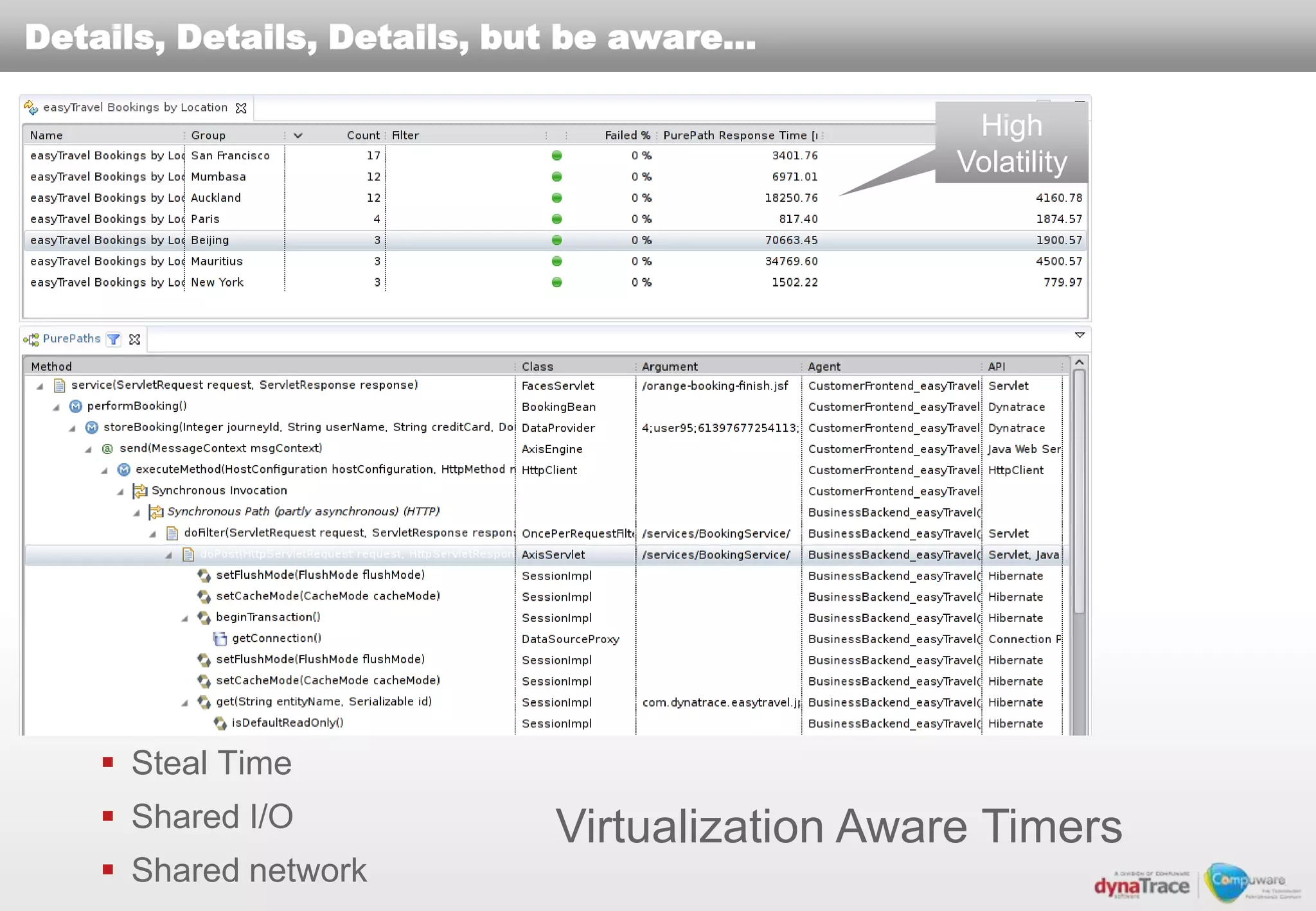

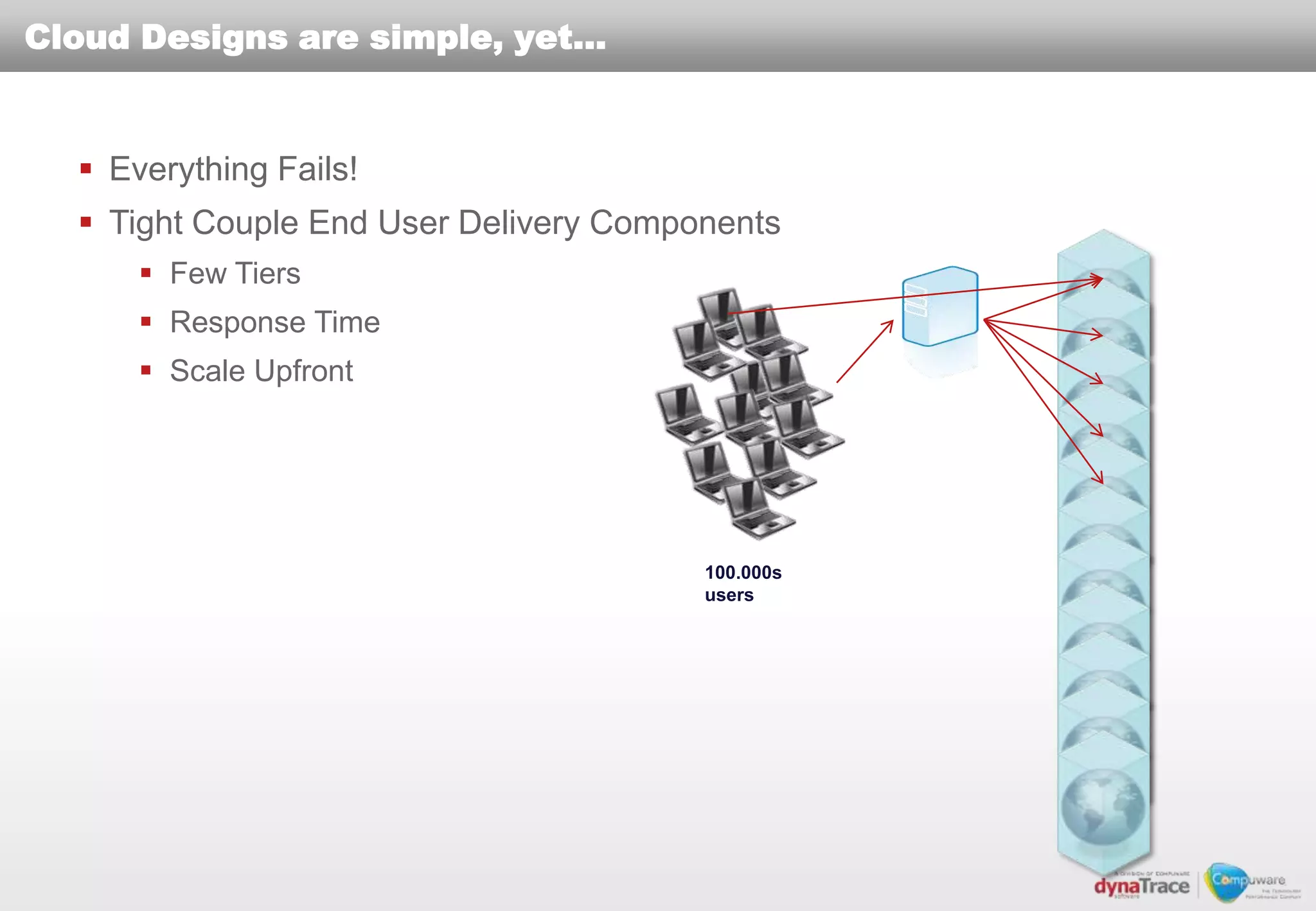

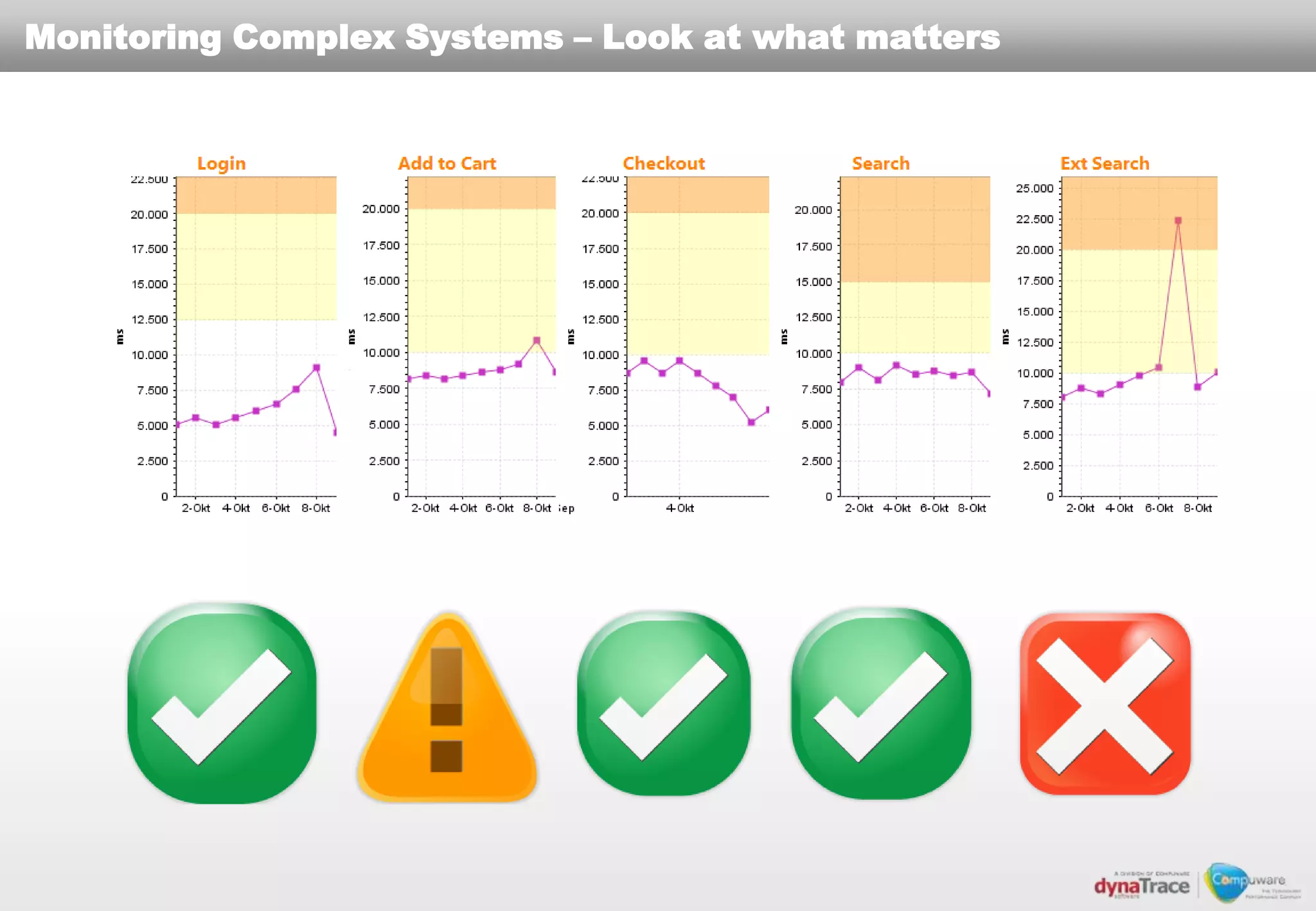
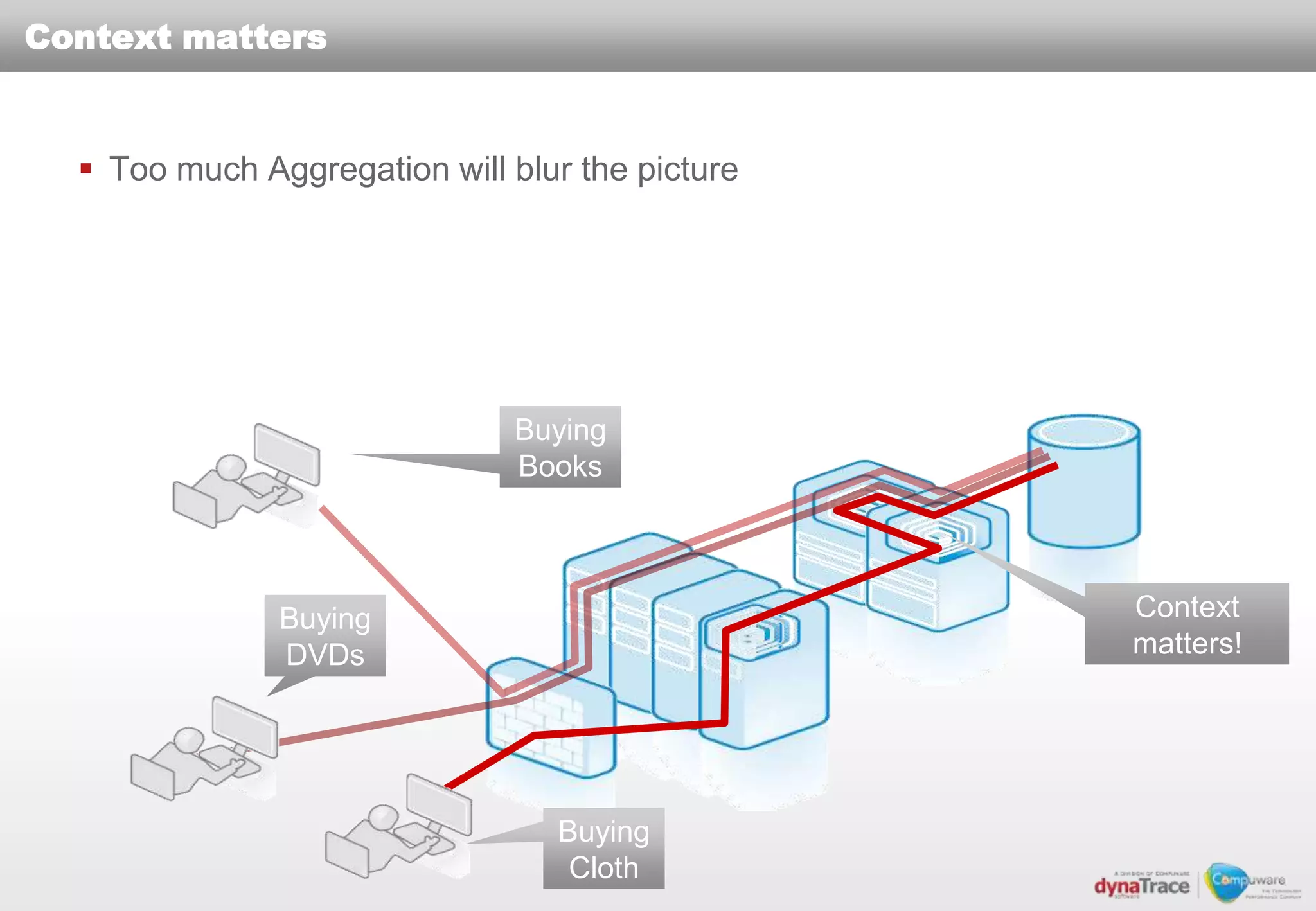

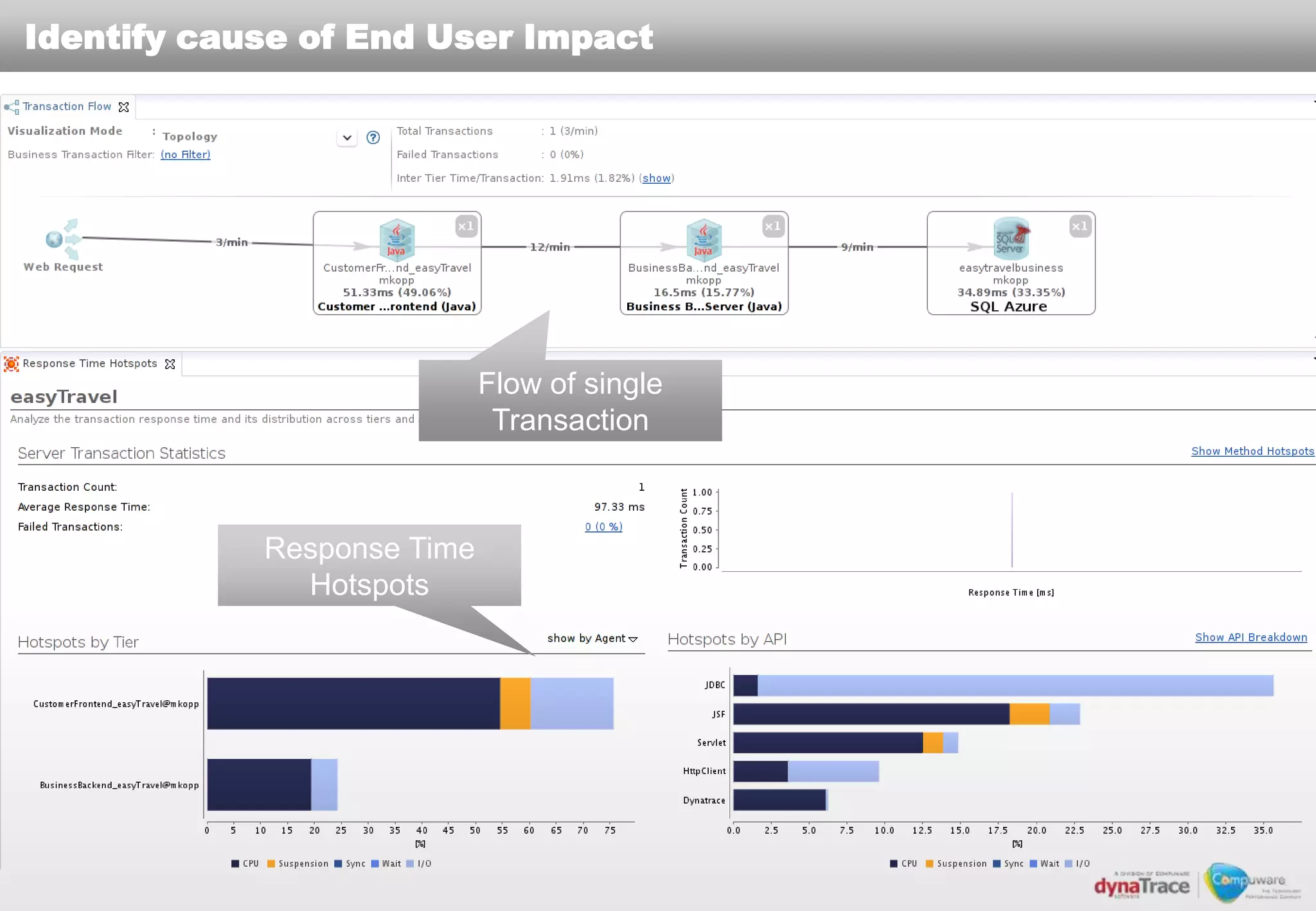
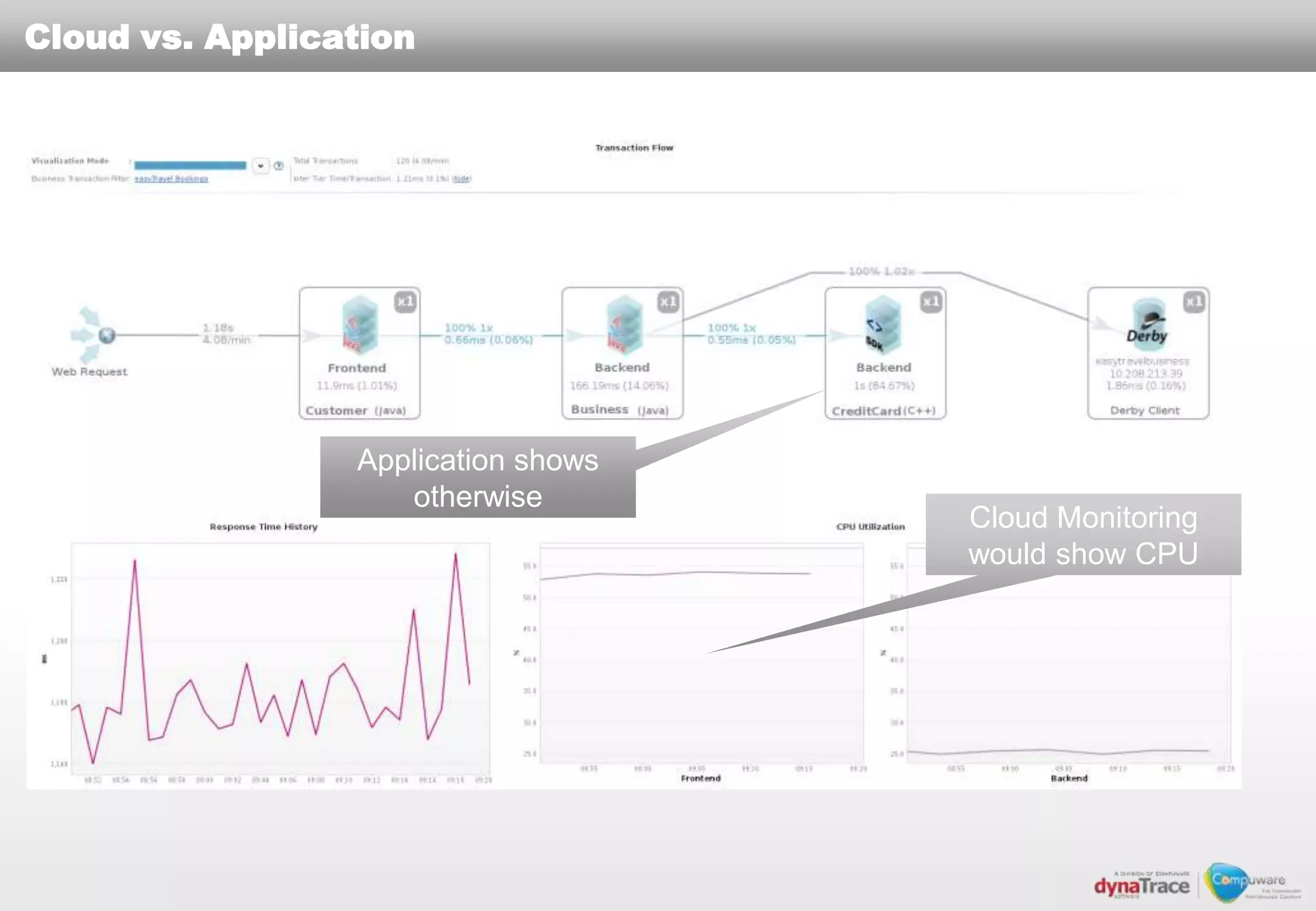
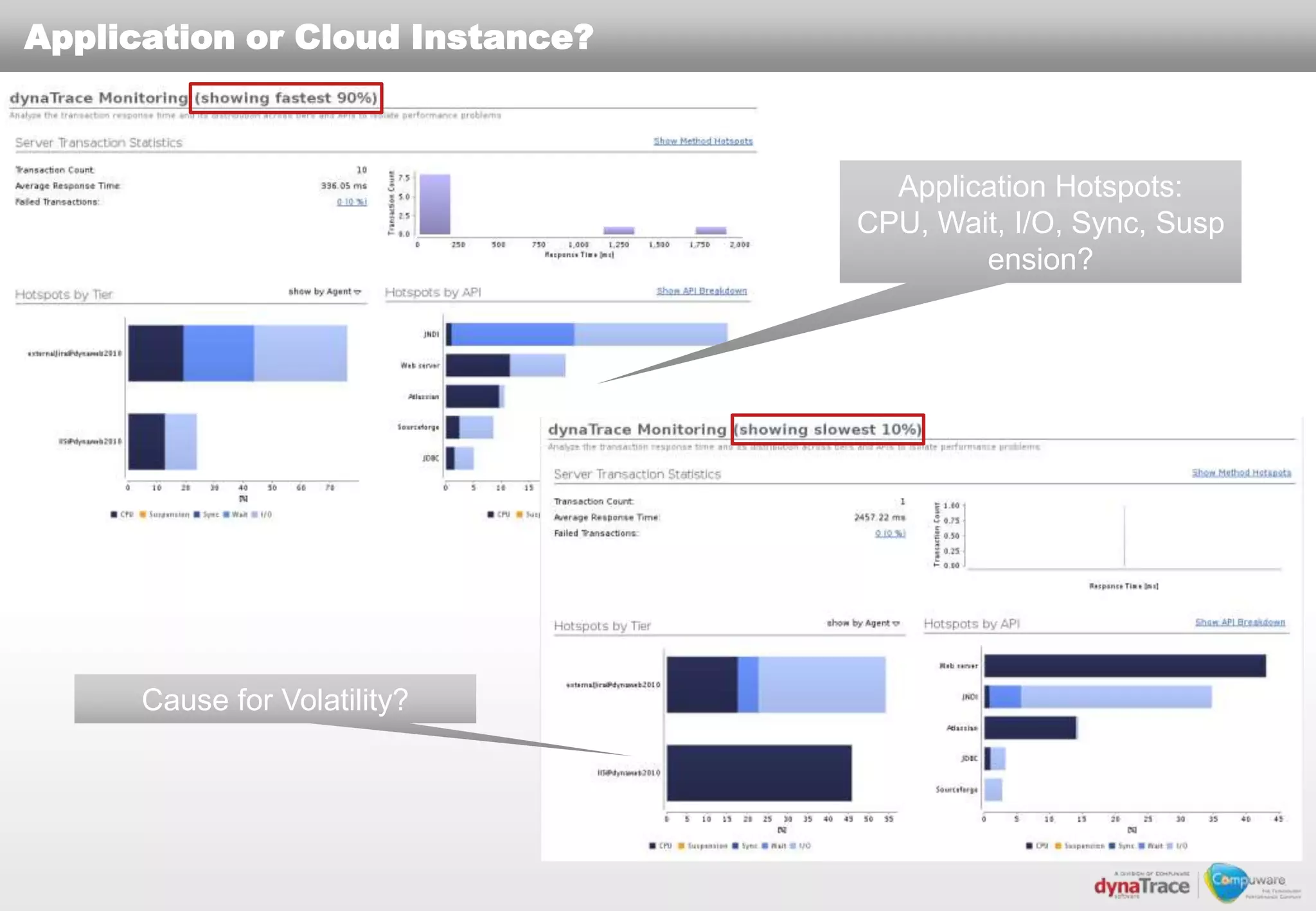
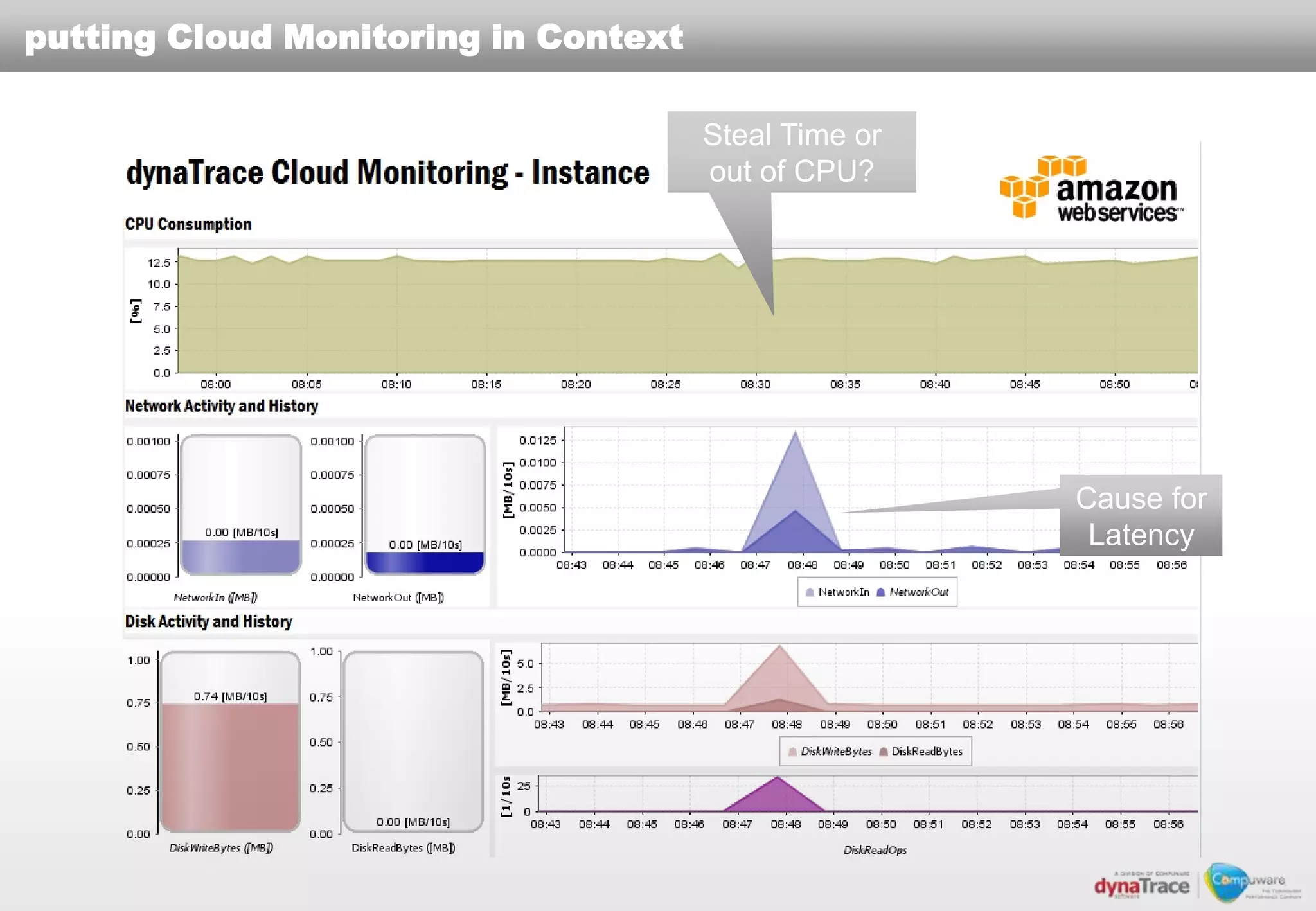


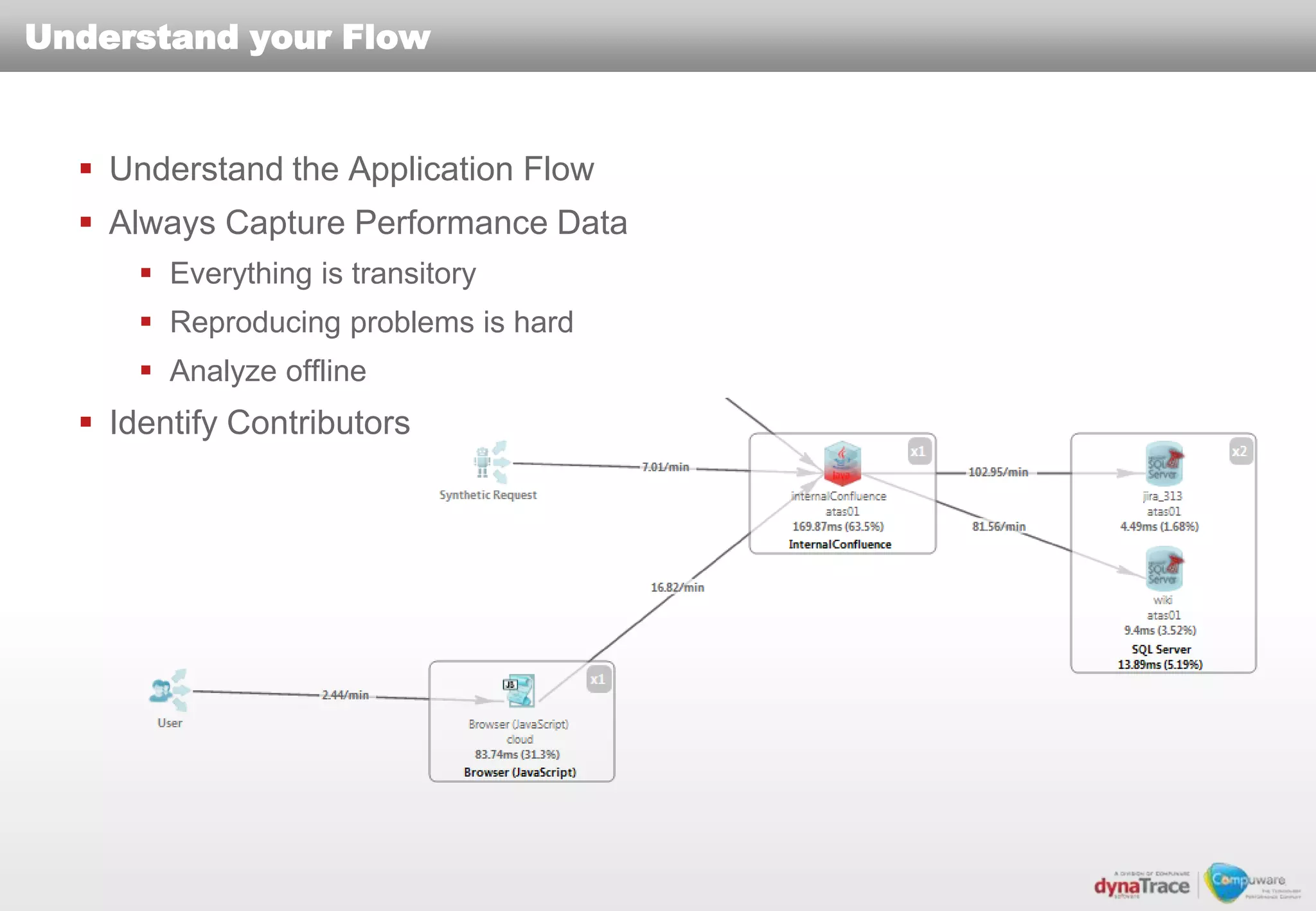
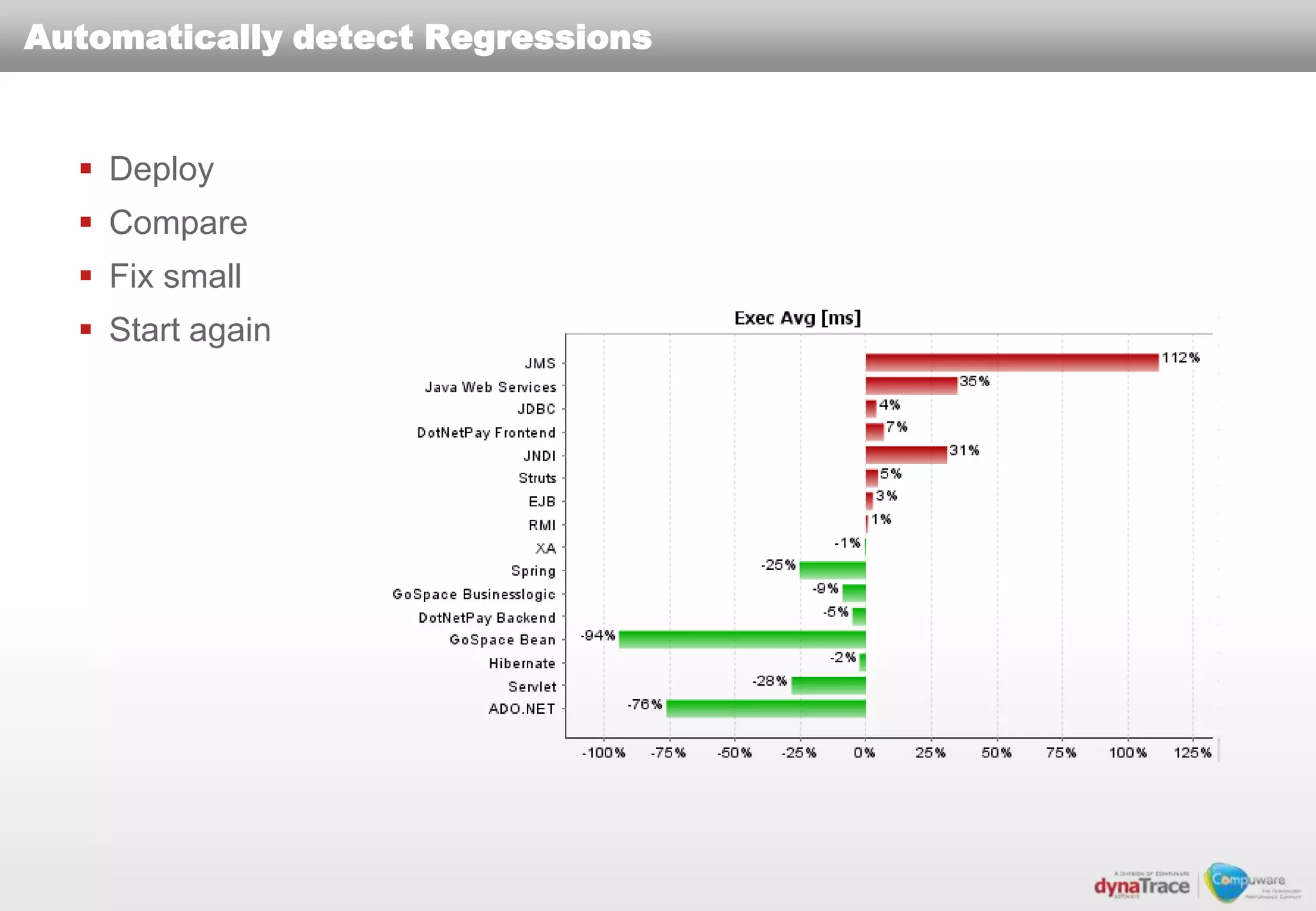
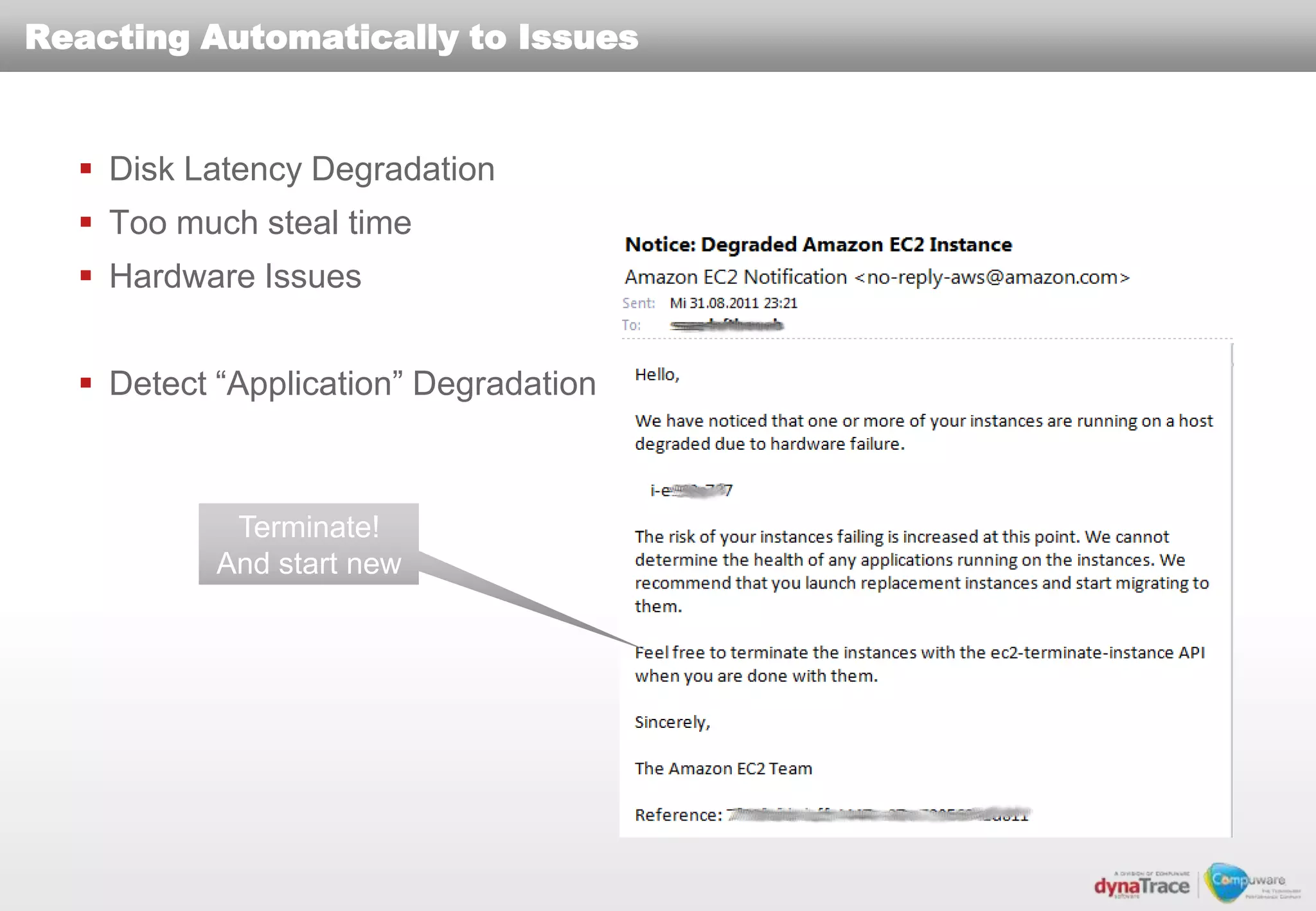

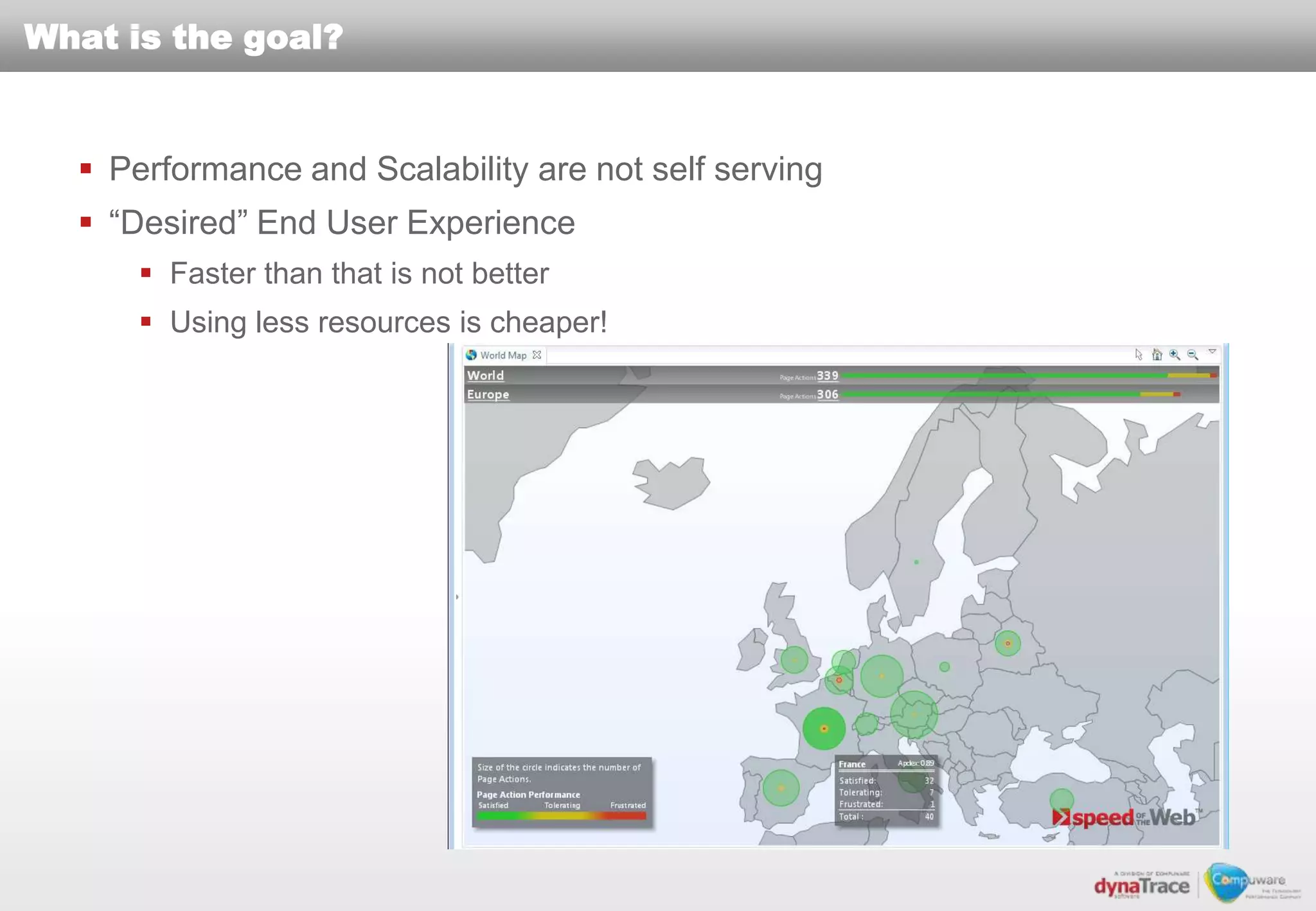



The document discusses the complexities and risks of performance management in cloud computing, emphasizing that cloud performance is not synonymous with scalability. Key issues include security, availability, and performance challenges, particularly with legacy applications and the unique monitoring requirements for cloud environments. It stresses the importance of measuring precise metrics and understanding transaction flows to ensure effective application performance, while also noting that traditional performance management approaches may fall short in cloud scenarios.





















































![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)

