Downloaded 29 times












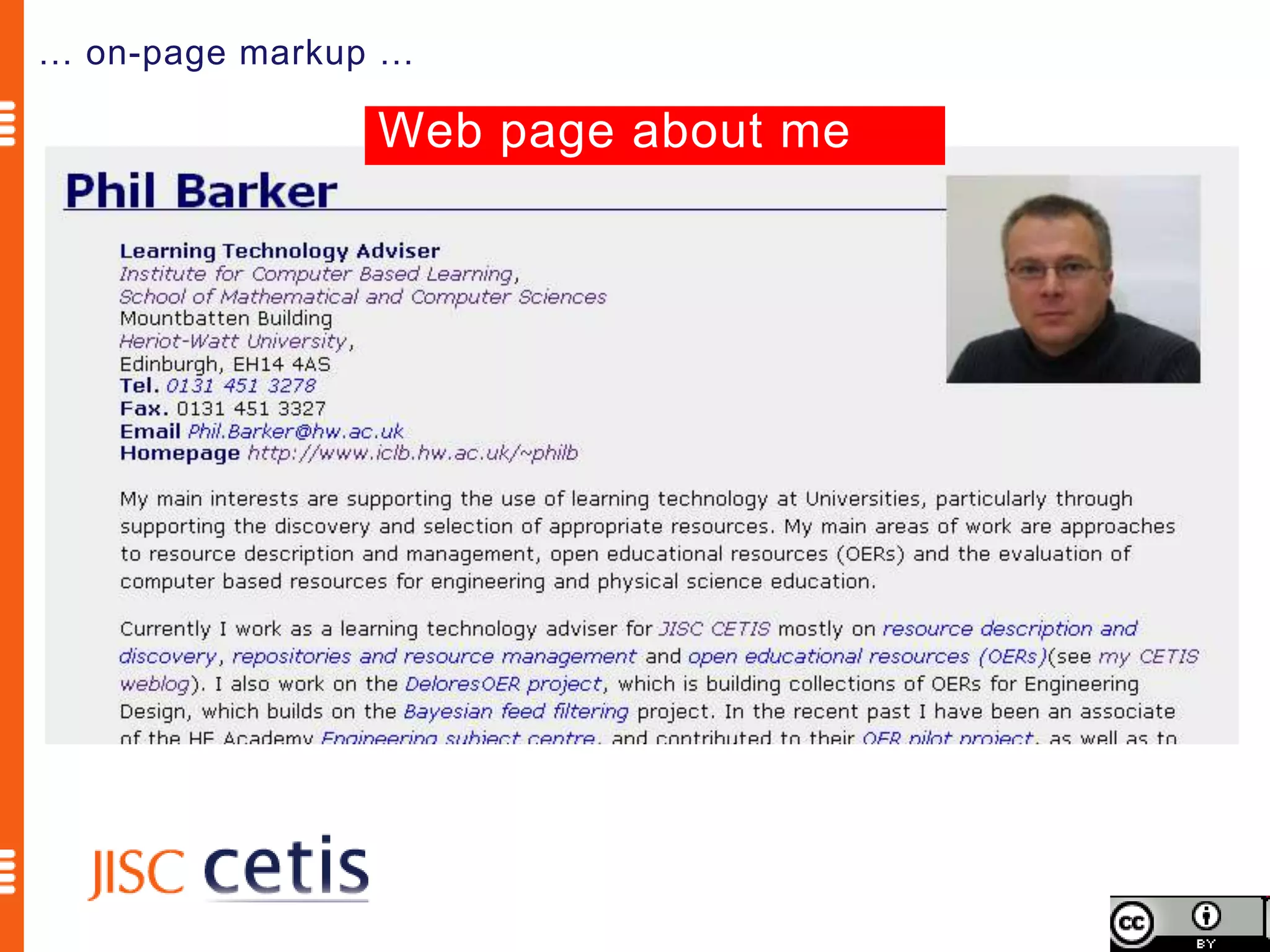
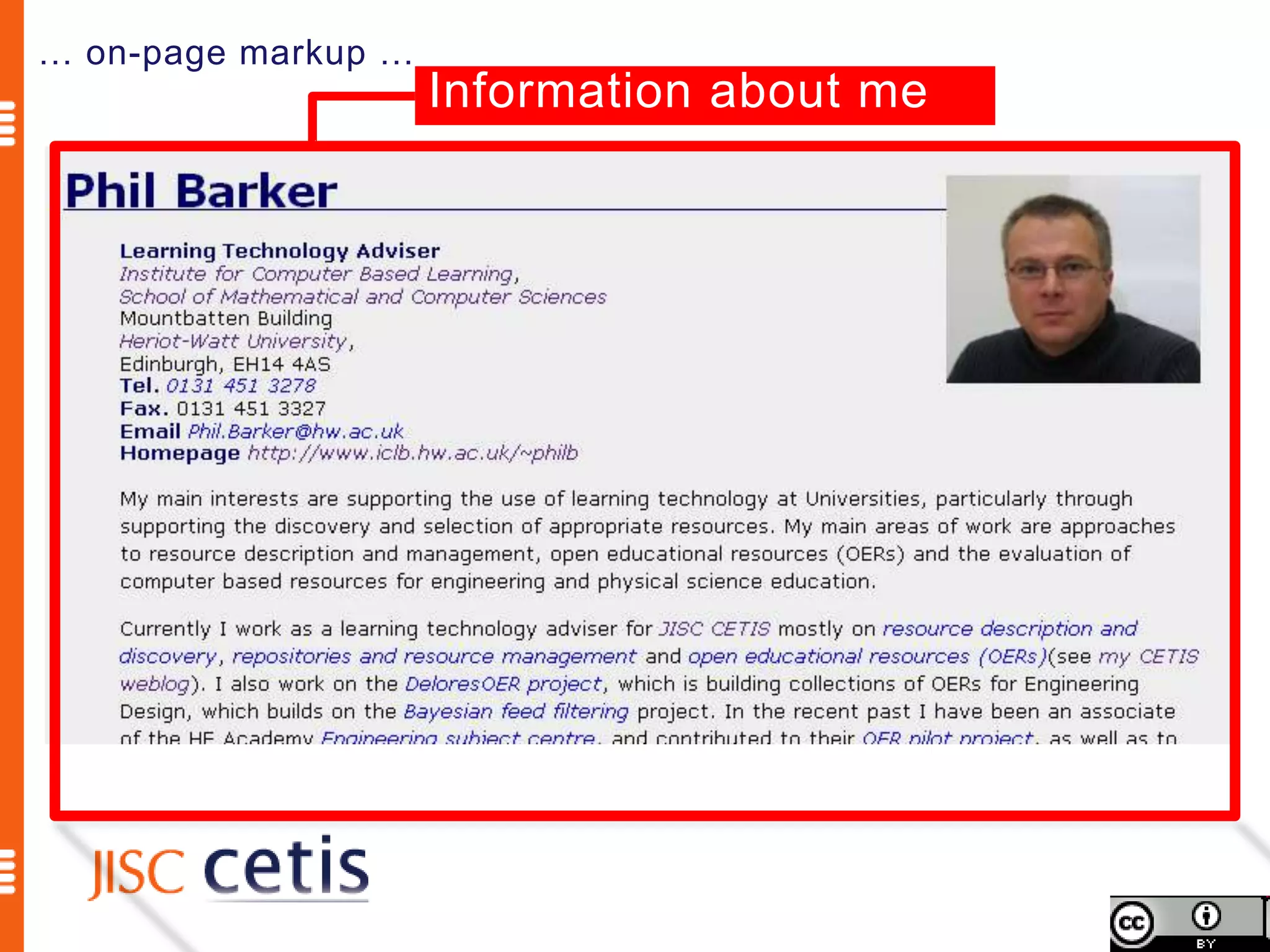
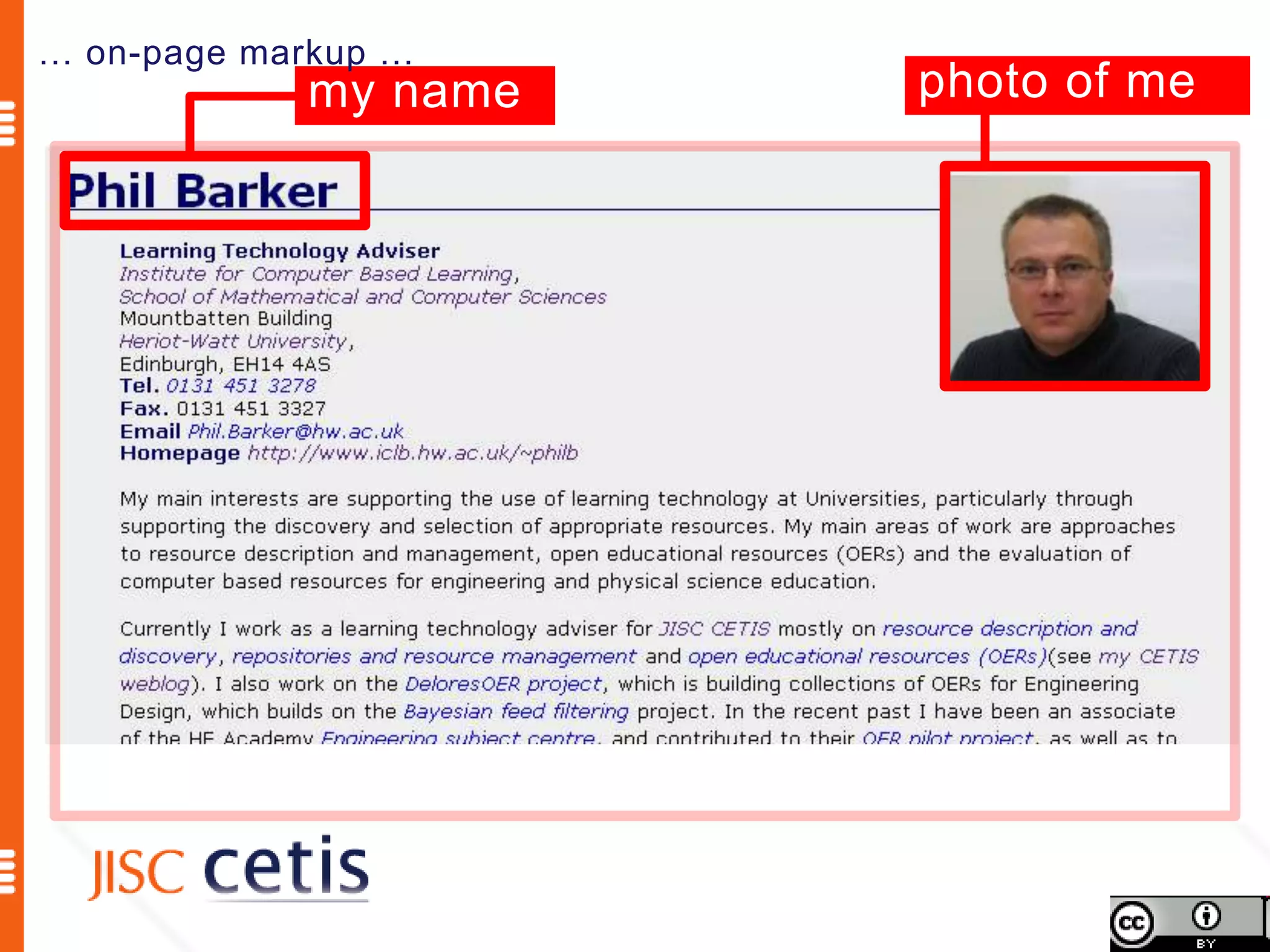
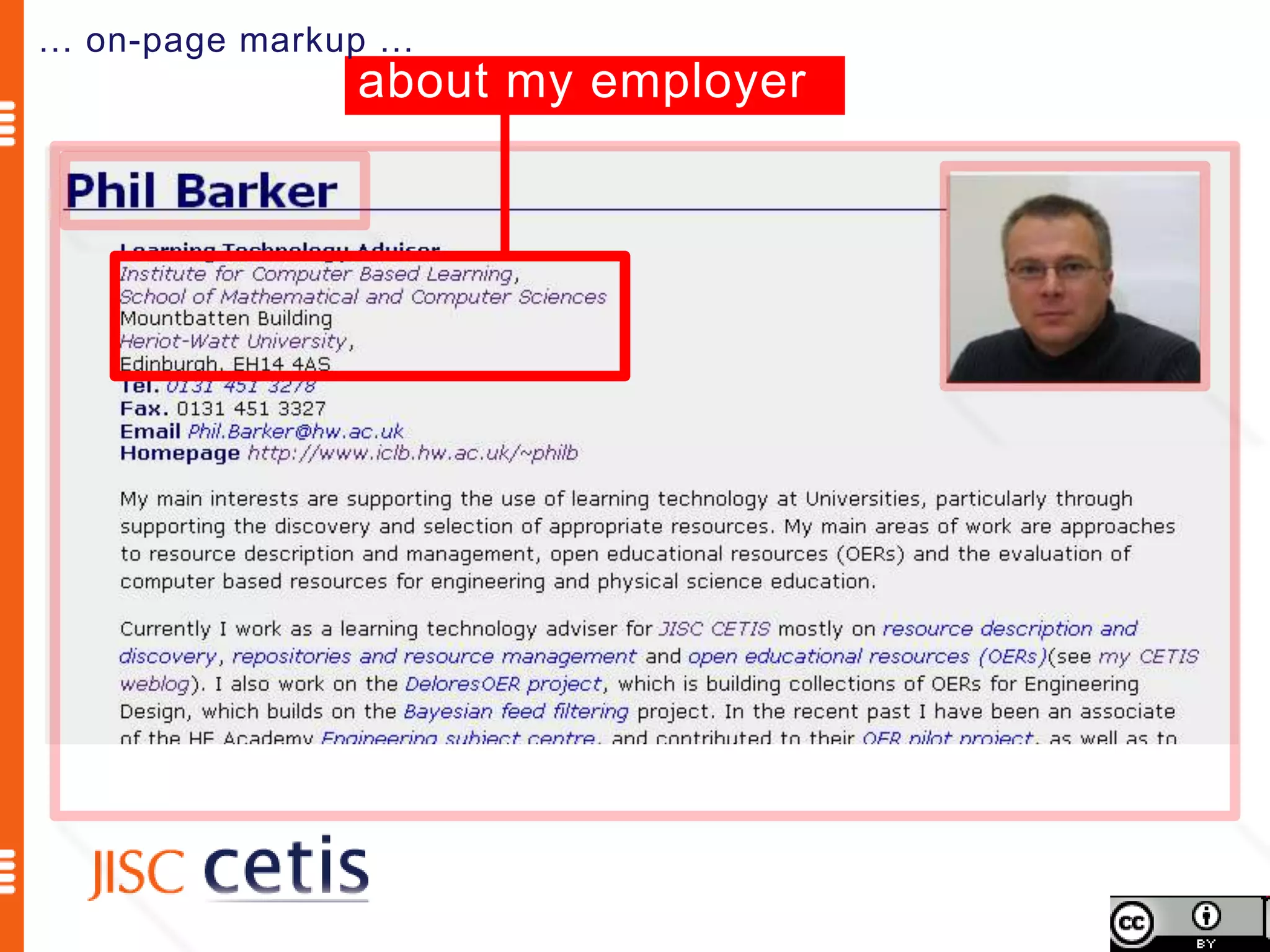
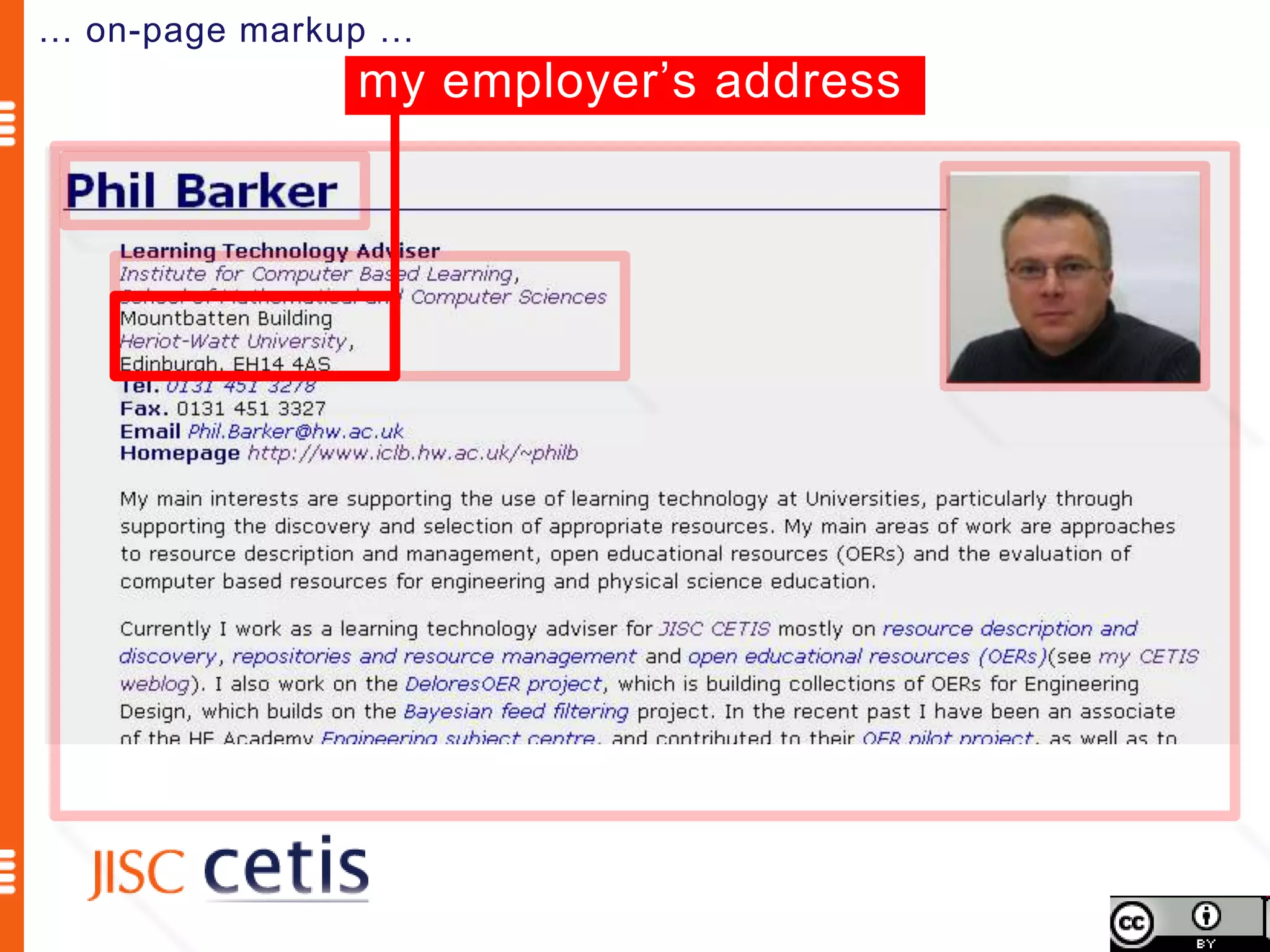
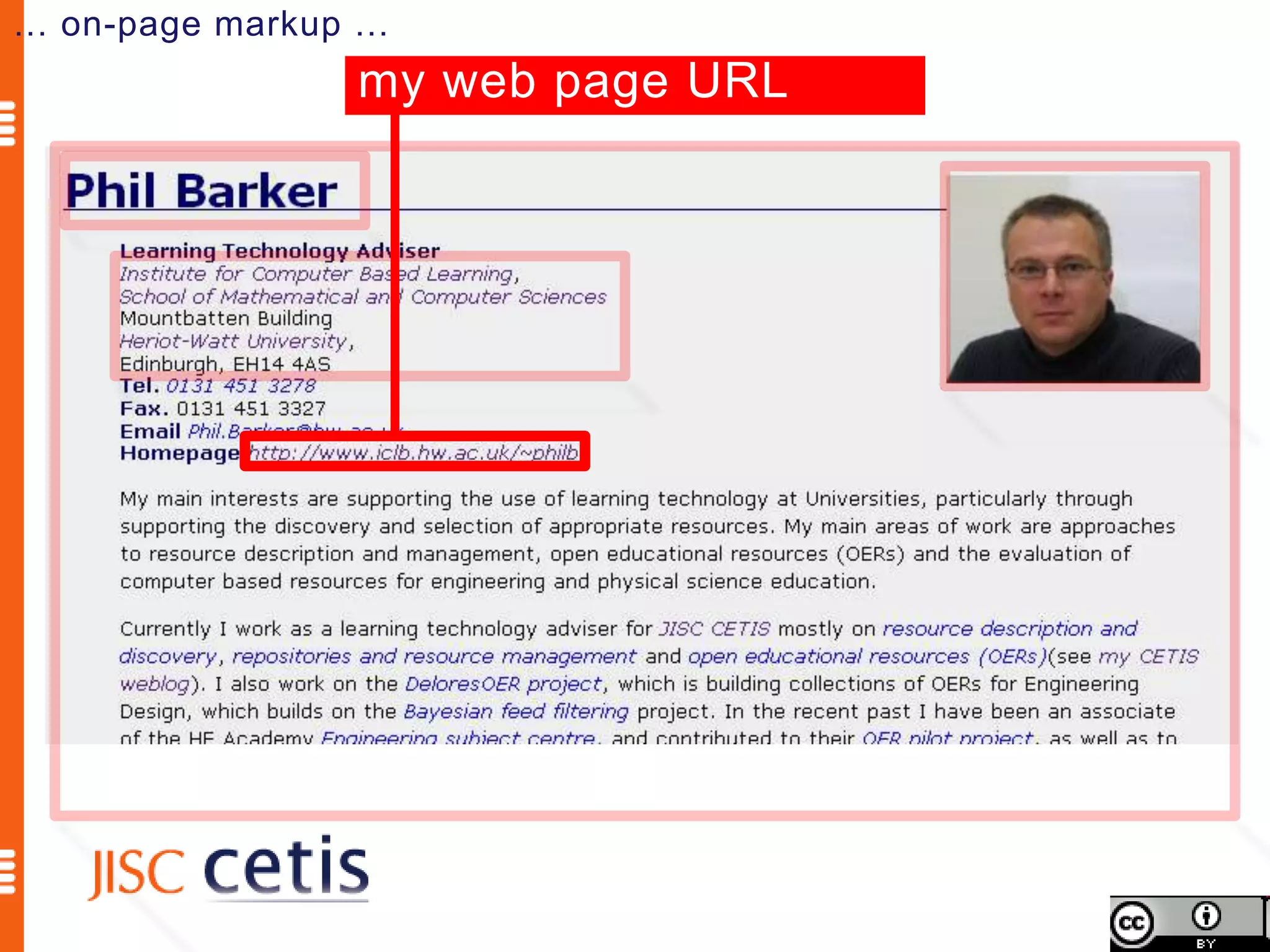





































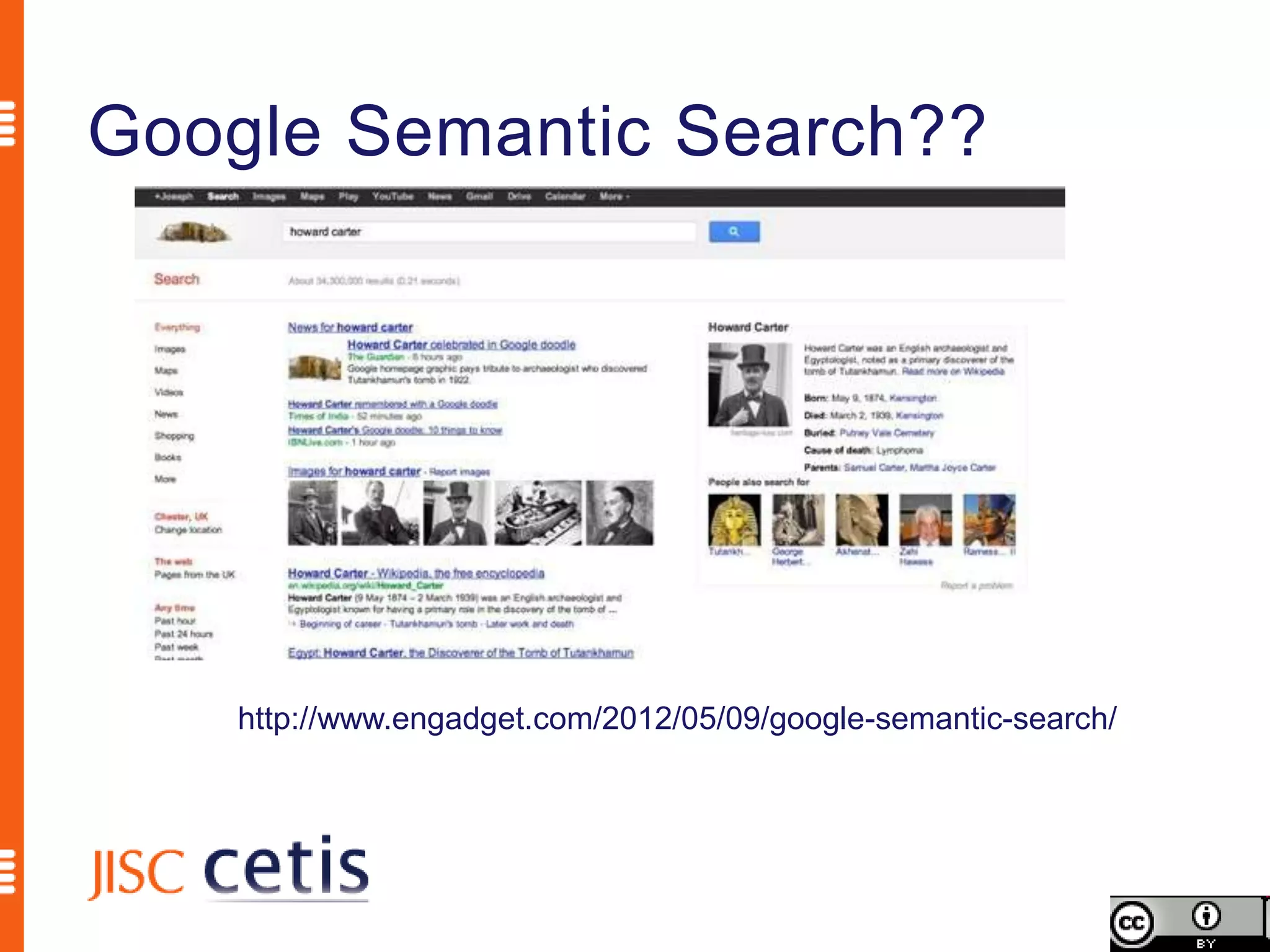



Schema.org offers web managers the ability to add structured markup to web pages to help search engines understand the information and provide richer search results. A shared markup vocabulary from Schema.org makes it easier for webmasters to decide on a schema and get maximum benefits. Schema.org markup can also enable new tools and applications by making use of the structured data.























































































