Download as PDF, PPTX








![Three Ways Of Doing Anything Faster
[Pfister]
■ Work harder
(clock speed)
□ Hardware solution
□ No longer feasible
■ Work smarter
(optimization, caching)
□ Hardware solution
□ No longer feasible
as only solution
■ Get help
(parallelization)
□ Hardware + Software
in cooperation
Application
Instructions
t
9
OpenHPI | Parallel Programming Concepts | Dr. Peter Tröger](https://image.slidesharecdn.com/week1-140612015206-phpapp01/85/OpenHPI-Parallel-Programming-Concepts-Week-1-9-320.jpg)

![Moore’s Law
■ “...the number of transistors that can be inexpensively placed on
an integrated circuit is increasing exponentially, doubling
approximately every two years. ...” (Gordon Moore, 1965)
□ CPUs contain different hardware parts, such as logic gates
□ Parts are built from transistors
□ Rule of exponential growth for the number
of transistors on one CPU chip
□ Meanwhile a self-fulfilling prophecy
□ Applied not only in processor industry,
but also in other areas
□ Sometimes misinterpreted as
performance indication
□ May still hold for the next 10-20 years
[Wikipedia]
12
OpenHPI | Parallel Programming Concepts | Dr. Peter Tröger](https://image.slidesharecdn.com/week1-140612015206-phpapp01/85/OpenHPI-Parallel-Programming-Concepts-Week-1-12-320.jpg)
![Moore’s Law
[Wikimedia]
13
OpenHPI | Parallel Programming Concepts | Dr. Peter Tröger](https://image.slidesharecdn.com/week1-140612015206-phpapp01/85/OpenHPI-Parallel-Programming-Concepts-Week-1-13-320.jpg)

![Processor Performance Development
Transistors)#)
Clock)Speed)(MHz))
Power)(W))
Perf/Clock)(ILP))
“Work harder”
“Work smarter”
[HerbSutter,2009]
15
OpenHPI | Parallel Programming Concepts | Dr. Peter Tröger](https://image.slidesharecdn.com/week1-140612015206-phpapp01/85/OpenHPI-Parallel-Programming-Concepts-Week-1-15-320.jpg)

![Processor Supply Voltage
1
10
100
1970 1980 1990 2000 2010
PowerSupply(Volt)
Processor Supply VoltageProcessor Supply Voltage
[Moore,ISSCC]
17
OpenHPI | Parallel Programming Concepts | Dr. Peter Tröger](https://image.slidesharecdn.com/week1-140612015206-phpapp01/85/OpenHPI-Parallel-Programming-Concepts-Week-1-17-320.jpg)
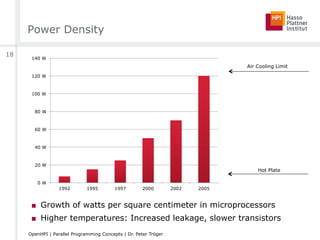
![Power Density
[Kevin Skadron, 2007]
“Cooking-Aware” Computing?
19
OpenHPI | Parallel Programming Concepts | Dr. Peter Tröger](https://image.slidesharecdn.com/week1-140612015206-phpapp01/85/OpenHPI-Parallel-Programming-Concepts-Week-1-19-320.jpg)
![Second Problem: Leakage Increase
0.001
0.01
0.1
1
10
100
1000
1960 1970 1980 1990 2000 2010
Power(W)
Processor Power (Watts)Processor Power (Watts) -- Active & LeakageActive & Leakage
ActiveActive
LeakageLeakage
[www.ieeeghn.org]
■ Static leakage today: Up to 40% of CPU power consumption
20
OpenHPI | Parallel Programming Concepts | Dr. Peter Tröger](https://image.slidesharecdn.com/week1-140612015206-phpapp01/85/OpenHPI-Parallel-Programming-Concepts-Week-1-20-320.jpg)

![The Free Lunch Is Over
■ Clock speed curve
flattened in 2003
□ Heat, power,
leakage
■ Speeding up the serial
instruction execution
through clock speed
improvements no
longer works
■ Additional issues
□ ILP wall
□ Memory wall
[HerbSutter,2009]
22
OpenHPI | Parallel Programming Concepts | Dr. Peter Tröger](https://image.slidesharecdn.com/week1-140612015206-phpapp01/85/OpenHPI-Parallel-Programming-Concepts-Week-1-22-320.jpg)

![Three Ways Of Doing Anything Faster
[Pfister]
■ Work harder
(clock speed)
□ Hardware solution
! Power wall problem
■ Work smarter
(optimization, caching)
□ Hardware solution
■ Get help
(parallelization)
□ Hardware + Software
Application
Instructions
24
OpenHPI | Parallel Programming Concepts | Dr. Peter Tröger](https://image.slidesharecdn.com/week1-140612015206-phpapp01/85/OpenHPI-Parallel-Programming-Concepts-Week-1-24-320.jpg)

![The ILP Wall
■ No longer cost-effective to dedicate
new transistors to ILP mechanisms
■ Deeper pipelines make the
power problem worse
■ High ILP complexity effectively
reduces the processing
speed for a given frequency
(e.g. misprediction)
■ More aggressive ILP
technologies too risky due to
unknown real-world workloads
■ No ground-breaking new ideas
■ " “ILP wall”
■ Ok, let’s use the transistors for better caching
[Wikipedia]
26
OpenHPI | Parallel Programming Concepts | Dr. Peter Tröger](https://image.slidesharecdn.com/week1-140612015206-phpapp01/85/OpenHPI-Parallel-Programming-Concepts-Week-1-26-320.jpg)

![Caching for Performance
■ Well established optimization technique for performance
■ Caching relies on data locality
□ Some instructions are often used (e.g. loops)
□ Some data is often used (e.g. local variables)
□ Hardware keeps a copy of the data in the faster cache
□ On read attempts, data is taken directly from the cache
□ On write, data is cached and eventually written to memory
■ Similar to ILP, the potential is limited
□ Larger caches do not help automatically
□ At some point, all data locality in the
code is already exploited
□ Manual vs. compiler-driven optimization
[arstechnica.com]
30
OpenHPI | Parallel Programming Concepts | Dr. Peter Tröger](https://image.slidesharecdn.com/week1-140612015206-phpapp01/85/OpenHPI-Parallel-Programming-Concepts-Week-1-30-320.jpg)
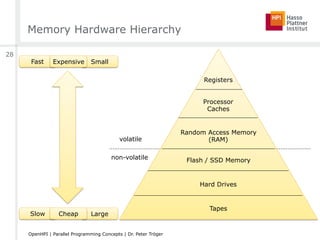
![Memory Wall
■ If caching is limited, we simply need faster memory
■ The problem: Shared memory is ‘shared’
□ Interconnect contention
□ Memory bandwidth
◊ Memory transfer speed is limited by the power wall
◊ Memory transfer size is limited by the power wall
■ Transfer technology cannot
keep up with GHz processors
■ Memory is too slow, effects
cannot be hidden through
caching completely
" “Memory wall”
[dell.com]
31
OpenHPI | Parallel Programming Concepts | Dr. Peter Tröger](https://image.slidesharecdn.com/week1-140612015206-phpapp01/85/OpenHPI-Parallel-Programming-Concepts-Week-1-31-320.jpg)

![Three Ways Of Doing Anything Faster
[Pfister]
■ Work harder
(clock speed)
! Power wall problem
! Memory wall problem
■ Work smarter
(optimization, caching)
! ILP wall problem
! Memory wall problem
■ Get help
(parallelization)
□ More cores per single CPU
□ Software needs to exploit
them in the right way
! Memory wall problem
Problem
CPU
Core
Core
Core
Core
Core
33
OpenHPI | Parallel Programming Concepts | Dr. Peter Tröger](https://image.slidesharecdn.com/week1-140612015206-phpapp01/85/OpenHPI-Parallel-Programming-Concepts-Week-1-33-320.jpg)

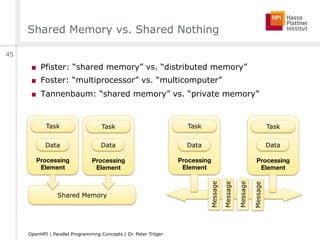
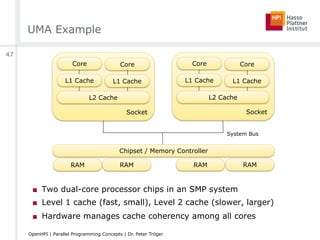
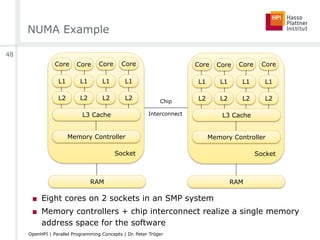
![Parallelism [Mattson et al.]
■ Task
□ Parallel program breaks a problem into tasks
■ Execution unit
□ Representation of a concurrently running task (e.g. thread)
□ Tasks are mapped to execution units
■ Processing element (PE)
□ Hardware element running one execution unit
□ Depends on scenario - logical processor vs. core vs. machine
□ Execution units run simultaneously on processing elements,
controlled by some scheduler
■ Synchronization - Mechanism to order activities of parallel tasks
■ Race condition - Program result depends on the scheduling order
35
OpenHPI | Parallel Programming Concepts | Dr. Peter Tröger](https://image.slidesharecdn.com/week1-140612015206-phpapp01/85/OpenHPI-Parallel-Programming-Concepts-Week-1-35-320.jpg)
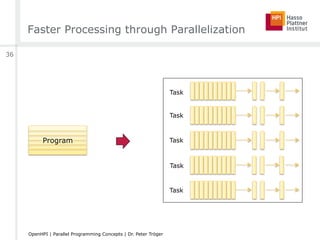
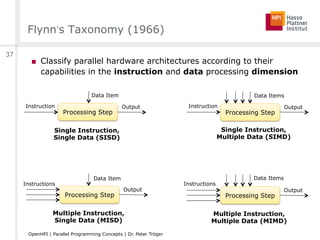

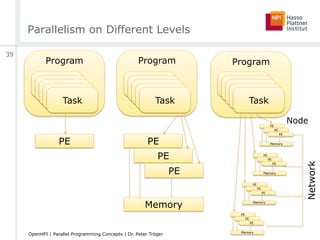

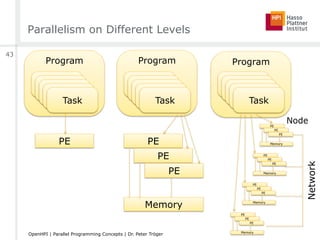
![Parallelism on Different Levels
[arstechnica.com]
ILP, SMT ILP, SMTILP, SMTILP, SMT
ILP, SMT ILP, SMT ILP, SMT ILP, SMT
CMPArchitecture
41
OpenHPI | Parallel Programming Concepts | Dr. Peter Tröger](https://image.slidesharecdn.com/week1-140612015206-phpapp01/85/OpenHPI-Parallel-Programming-Concepts-Week-1-41-320.jpg)



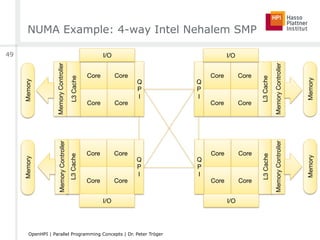

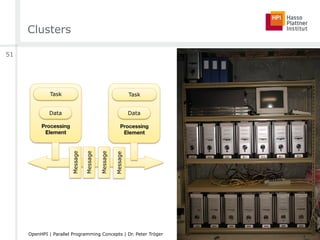
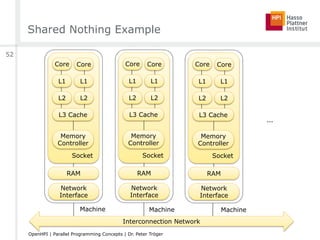
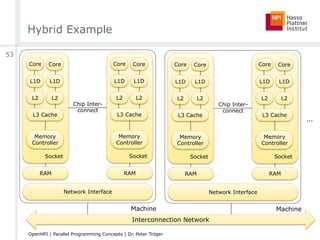


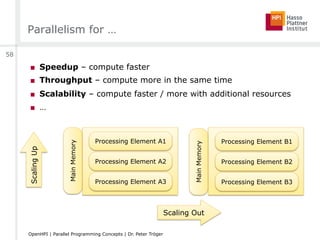


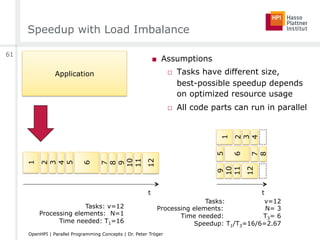


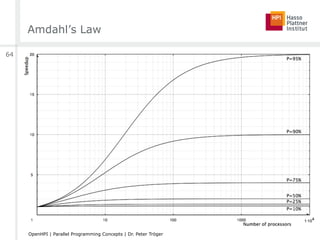

![Amdahl’s Law
■ “Everyone knows Amdahl’s law, but quickly forgets it.”
[Thomas Puzak, IBM]
■ 90% parallelizable code leads to not more than 10x speedup
□ Regardless of the number of processing elements
■ Parallelism is only useful …
□ … for small number of processing elements
□ … for highly parallelizable code
■ What’s the sense in big parallel / distributed hardware setups?
■ Relevant assumptions
□ Put the same problem on different hardware
□ Assumption of fixed problem size
□ Only consideration of execution time for one problem
66
OpenHPI | Parallel Programming Concepts | Dr. Peter Tröger](https://image.slidesharecdn.com/week1-140612015206-phpapp01/85/OpenHPI-Parallel-Programming-Concepts-Week-1-66-320.jpg)



The OpenHPI course on Parallel Programming Concepts introduces fundamental terminology, key concepts like Moore's Law, and classifications of parallel hardware, aiming to equip individuals with software development skills to explore parallelization techniques. It consists of six weeks of lectures, assignments, and discussions focused on various forms of parallelism, including shared memory and distributed memory systems. The course is designed for those with some software experience who seek a broad understanding of parallel computing, rather than in-depth knowledge of a specific tool or language.



































































