Downloaded 27 times



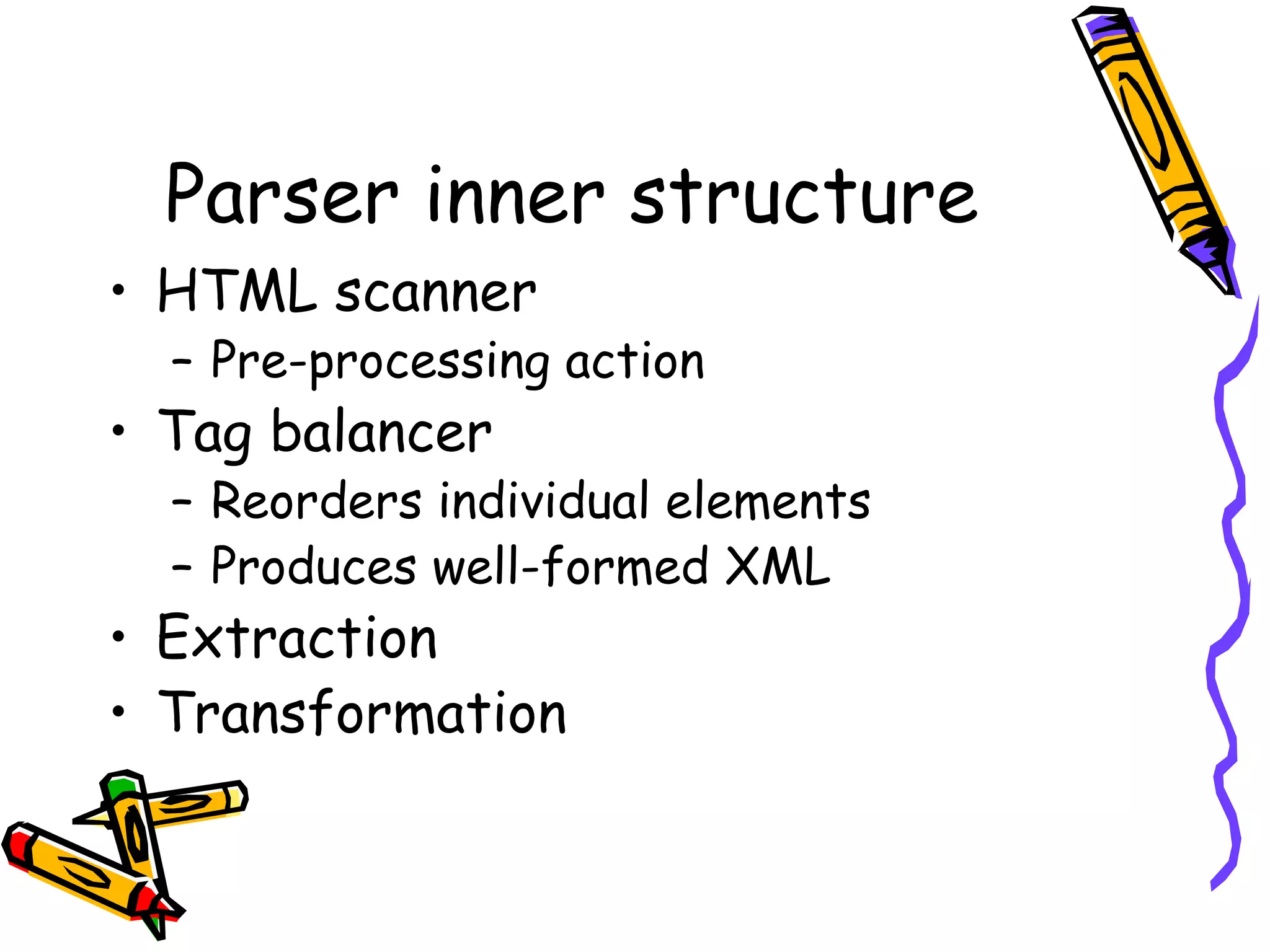



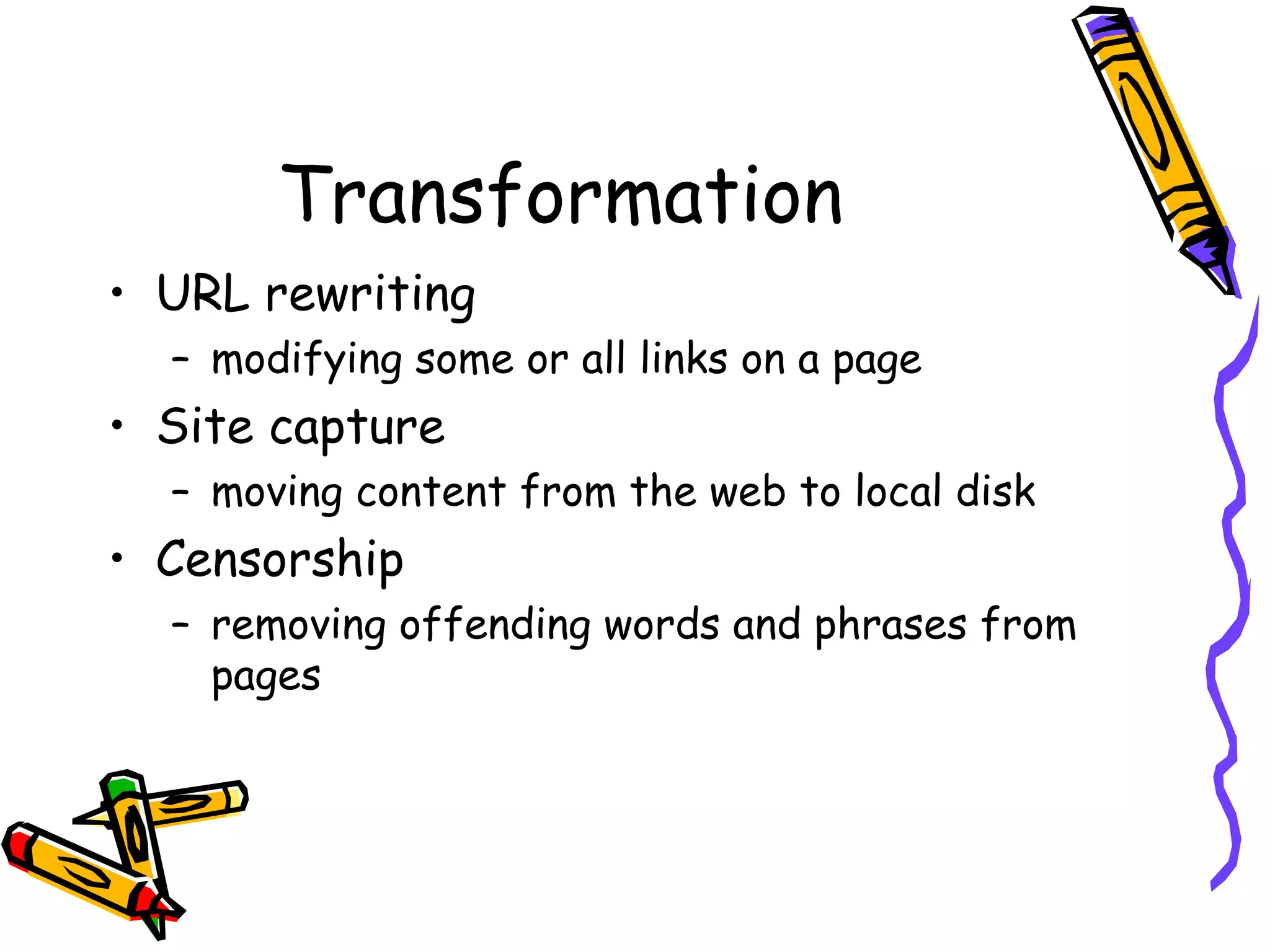




This document discusses an overview of how a web crawler works including parsing HTML, common parsers used, the structure of parsers, examples of extraction and transformation, and concludes with uses of web crawlers and a question and answer session.




























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















