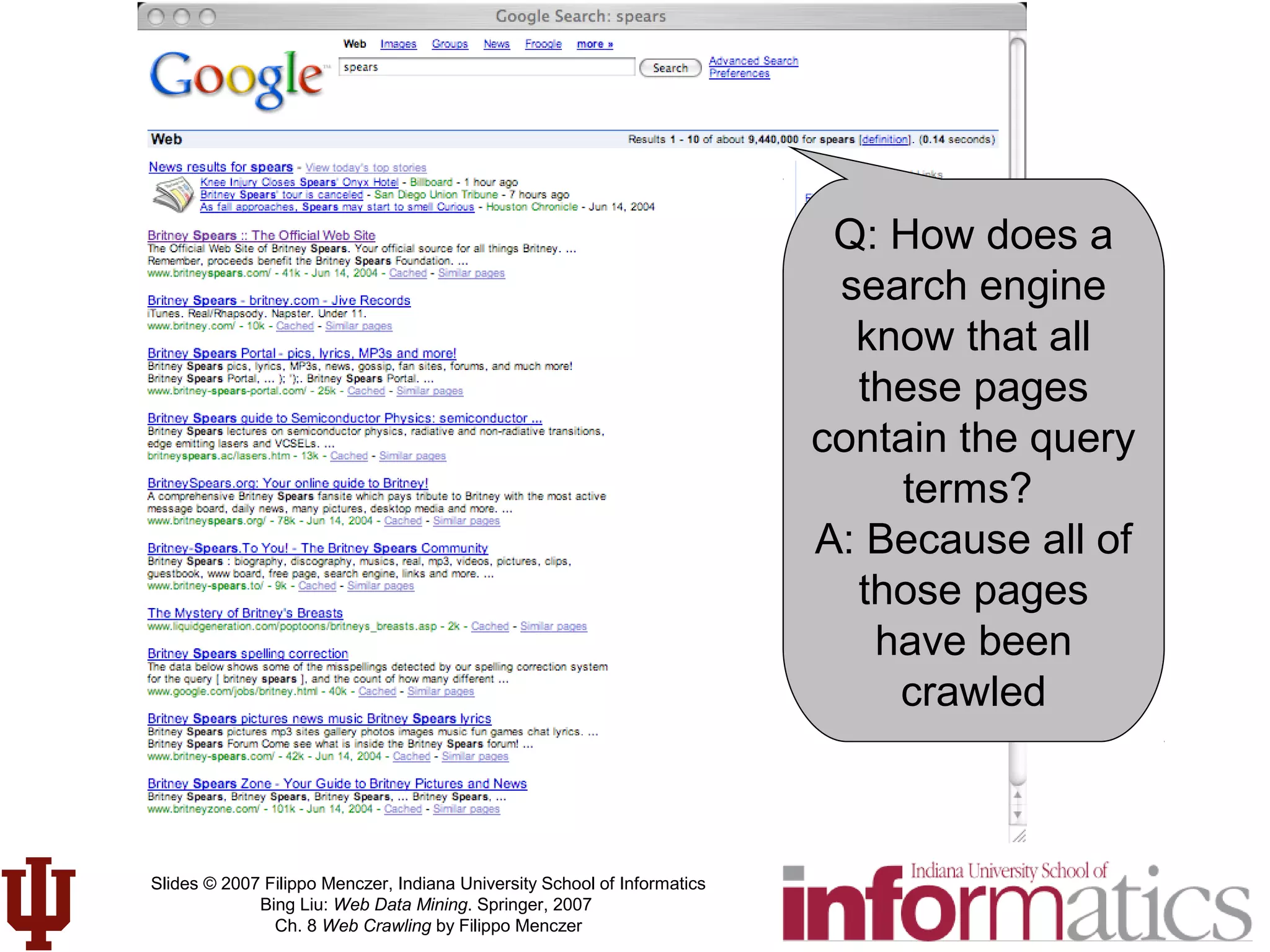
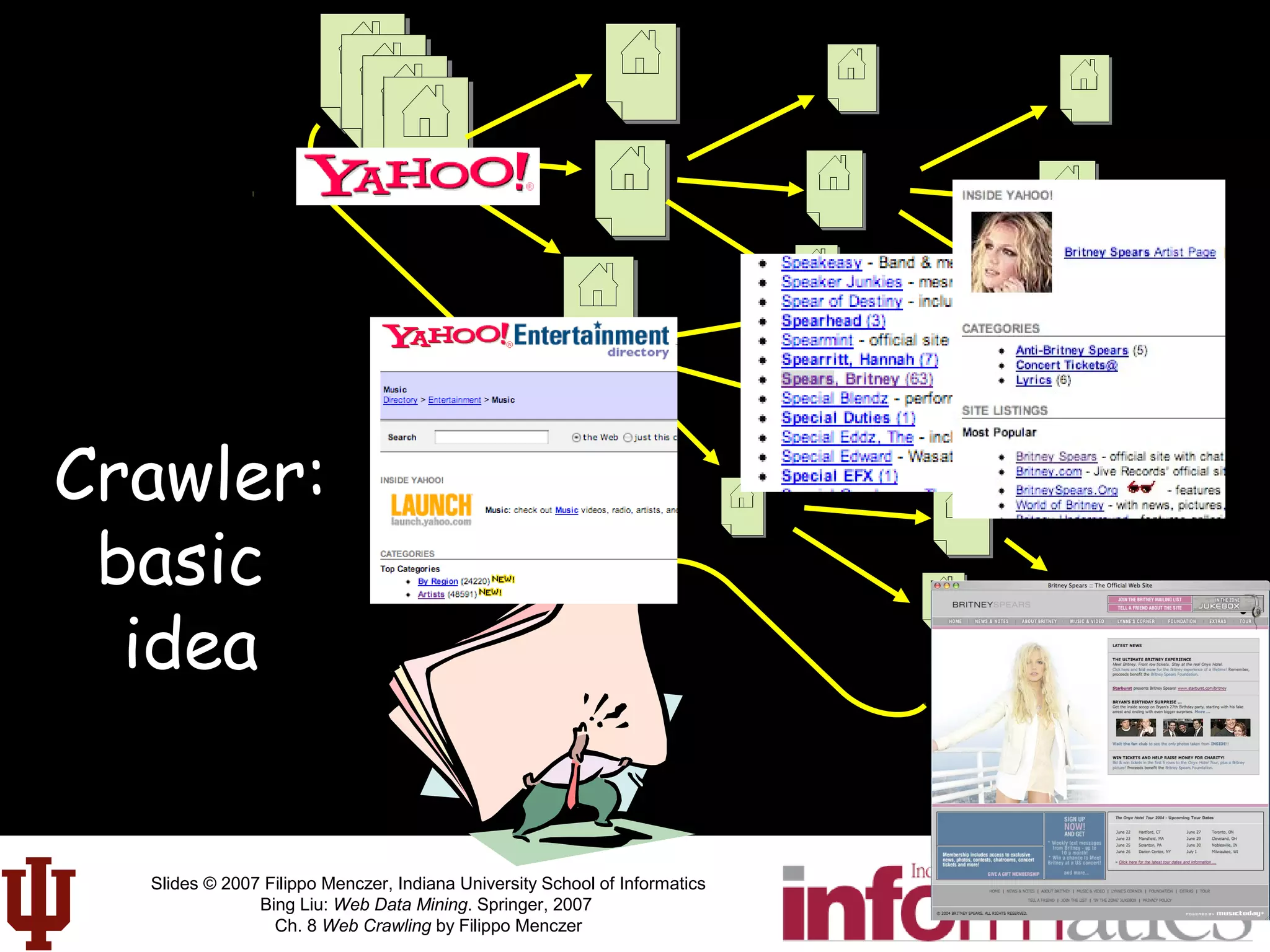
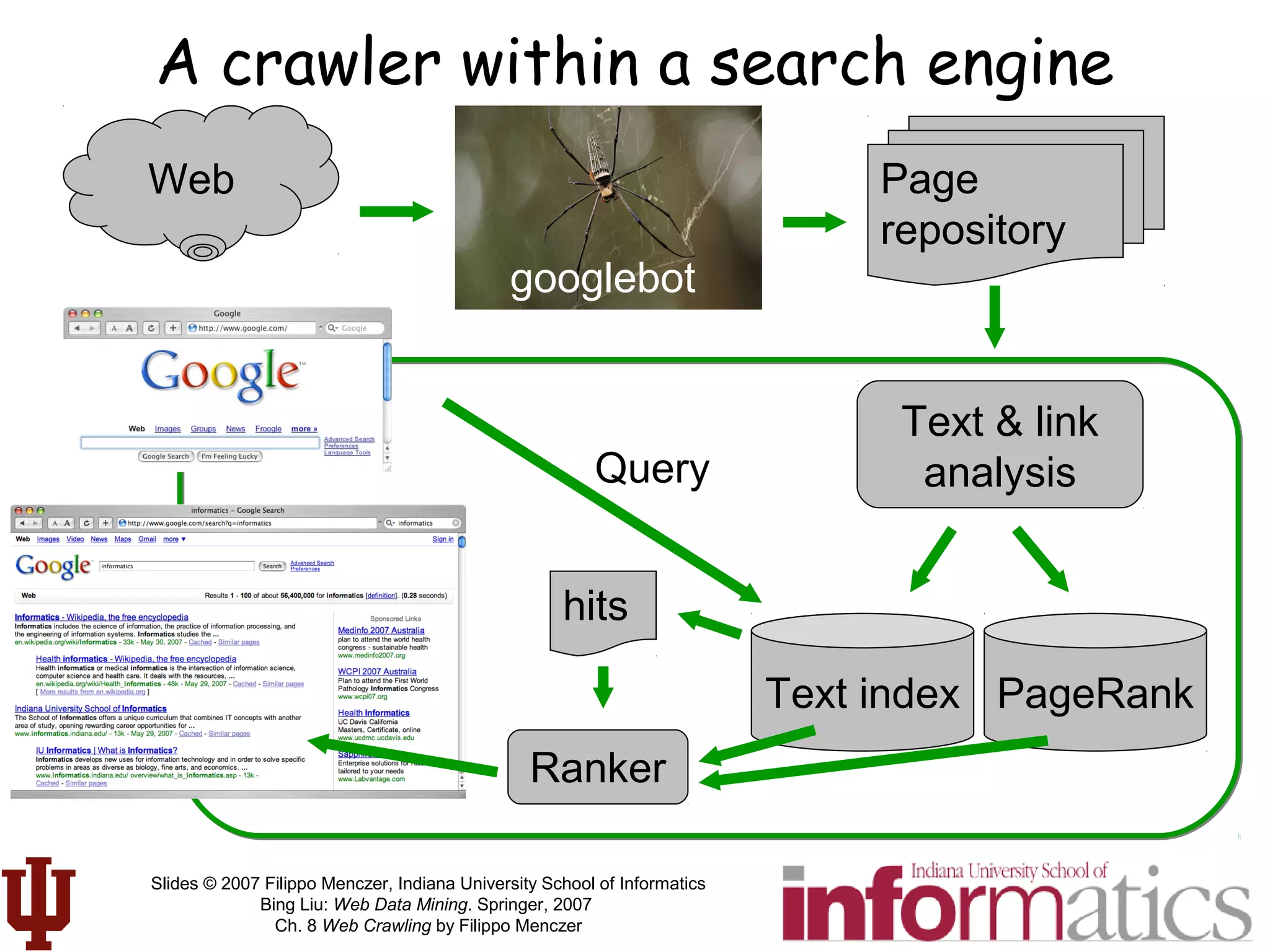
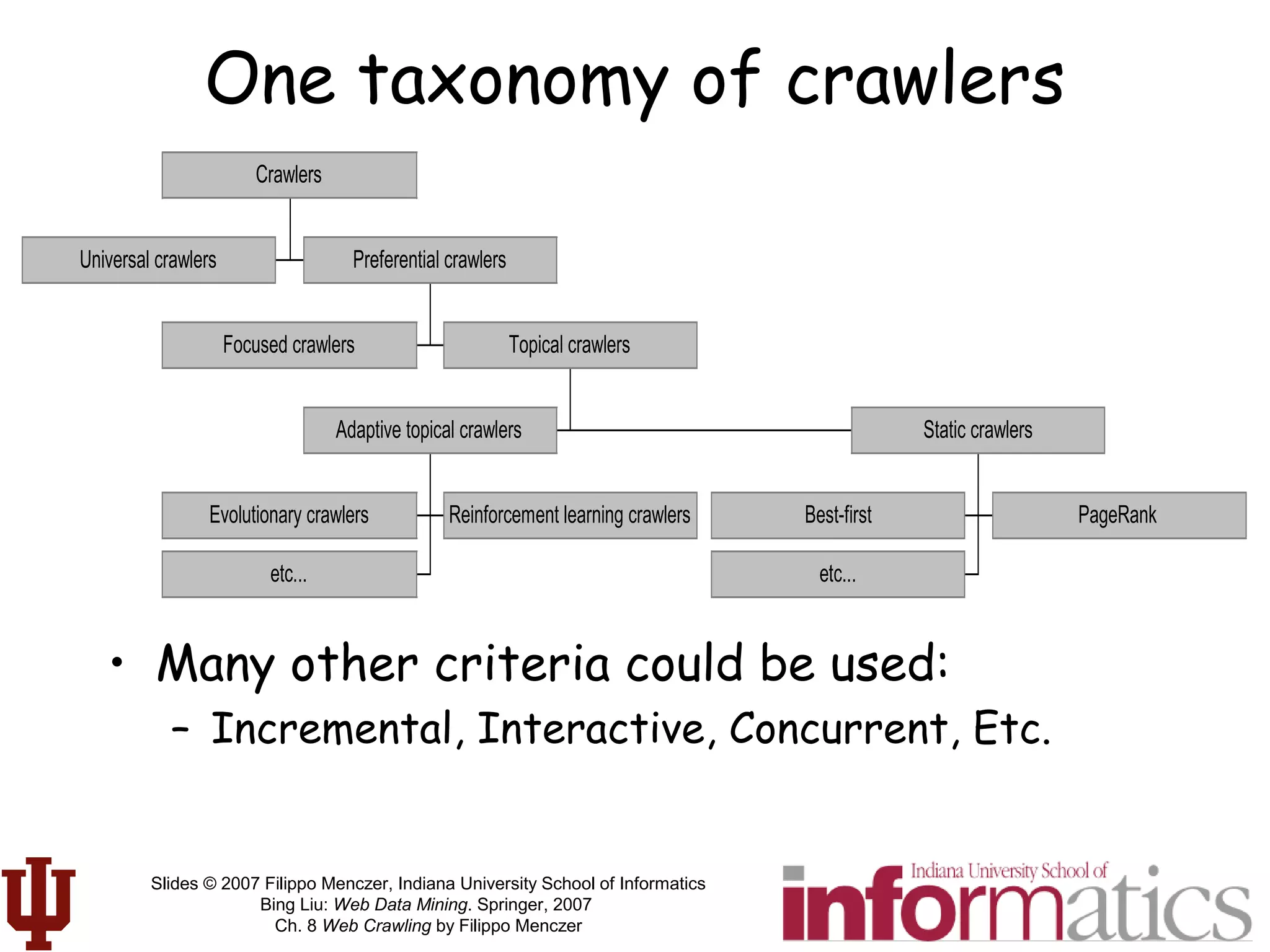
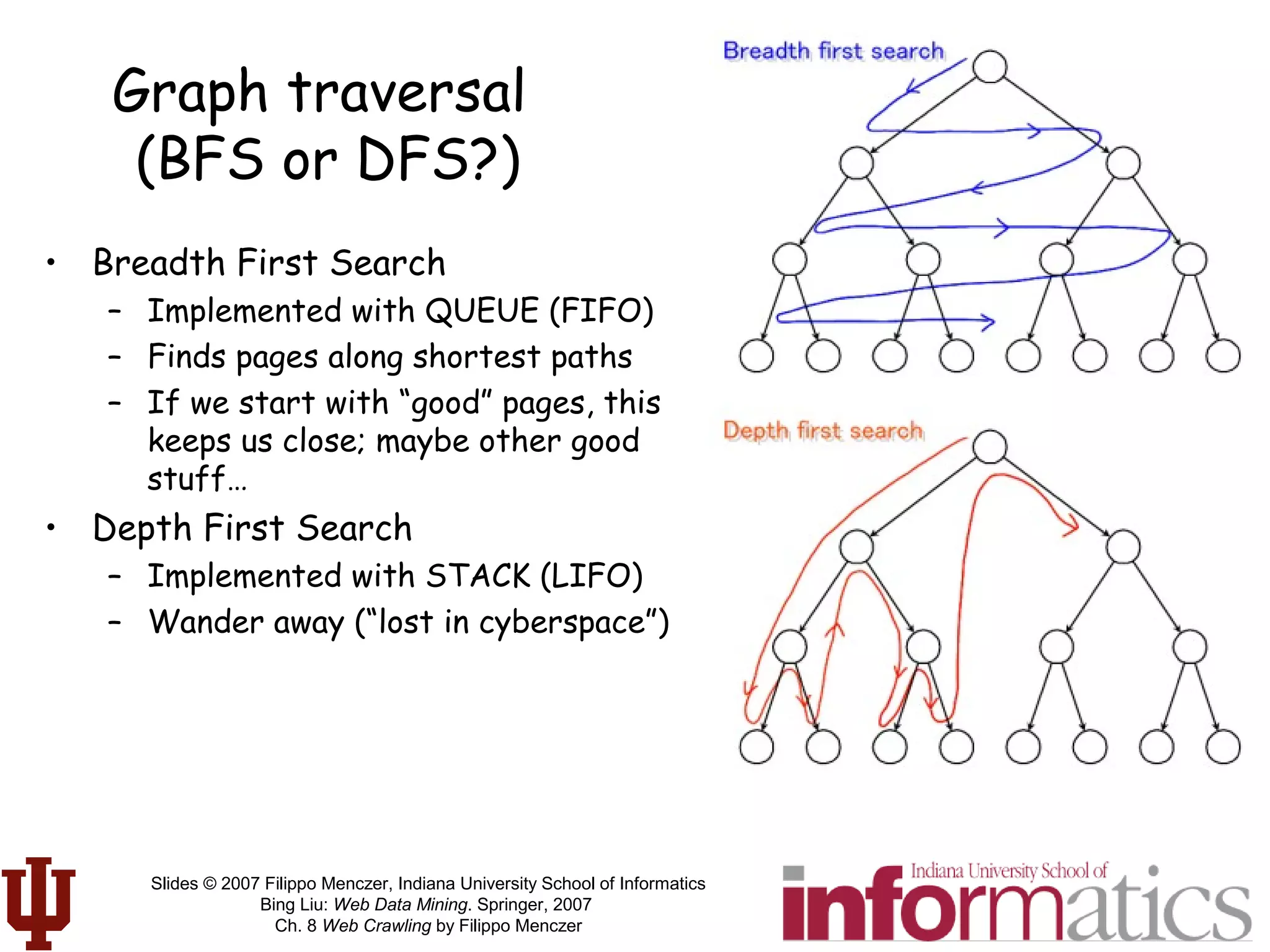
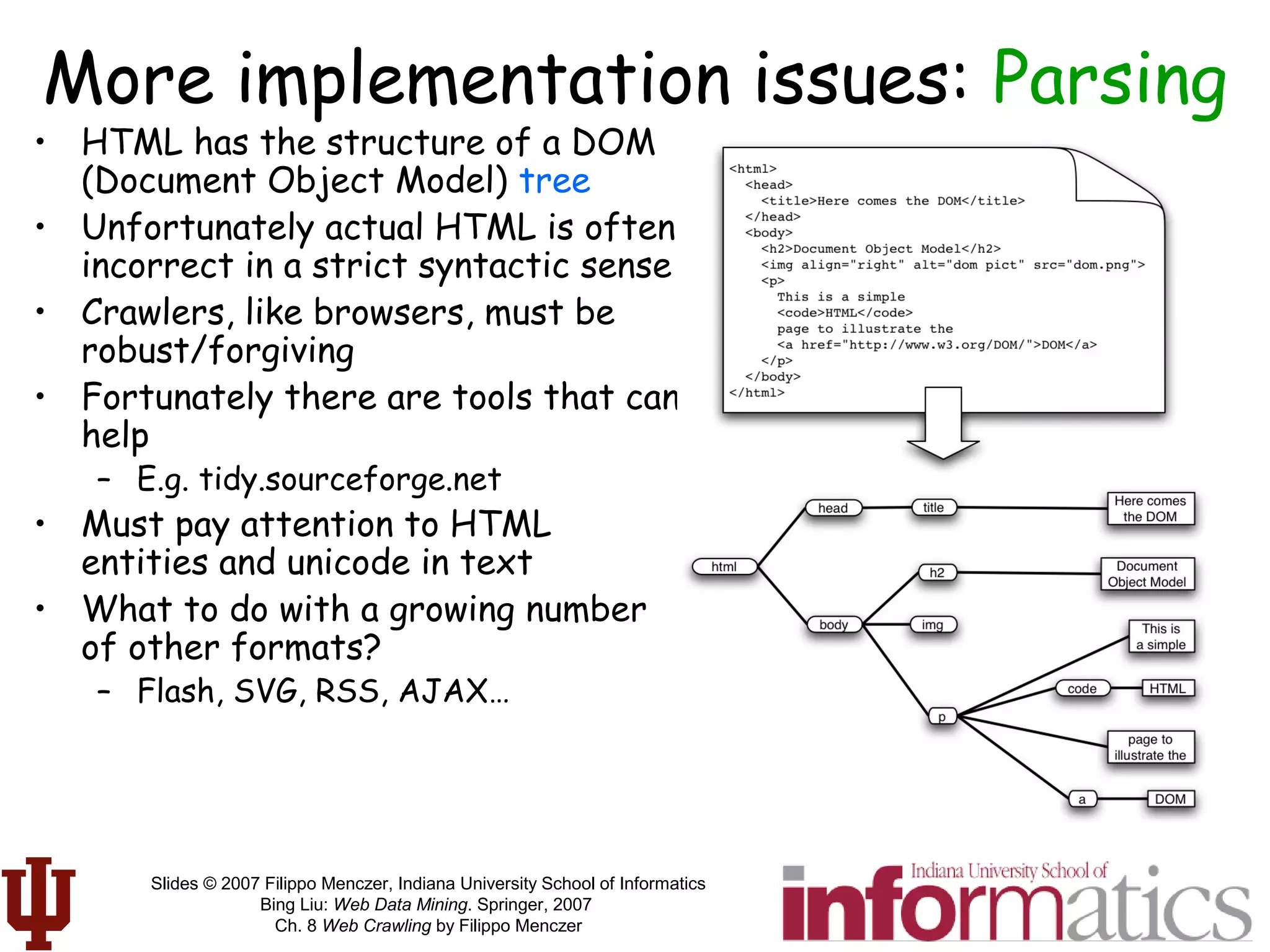
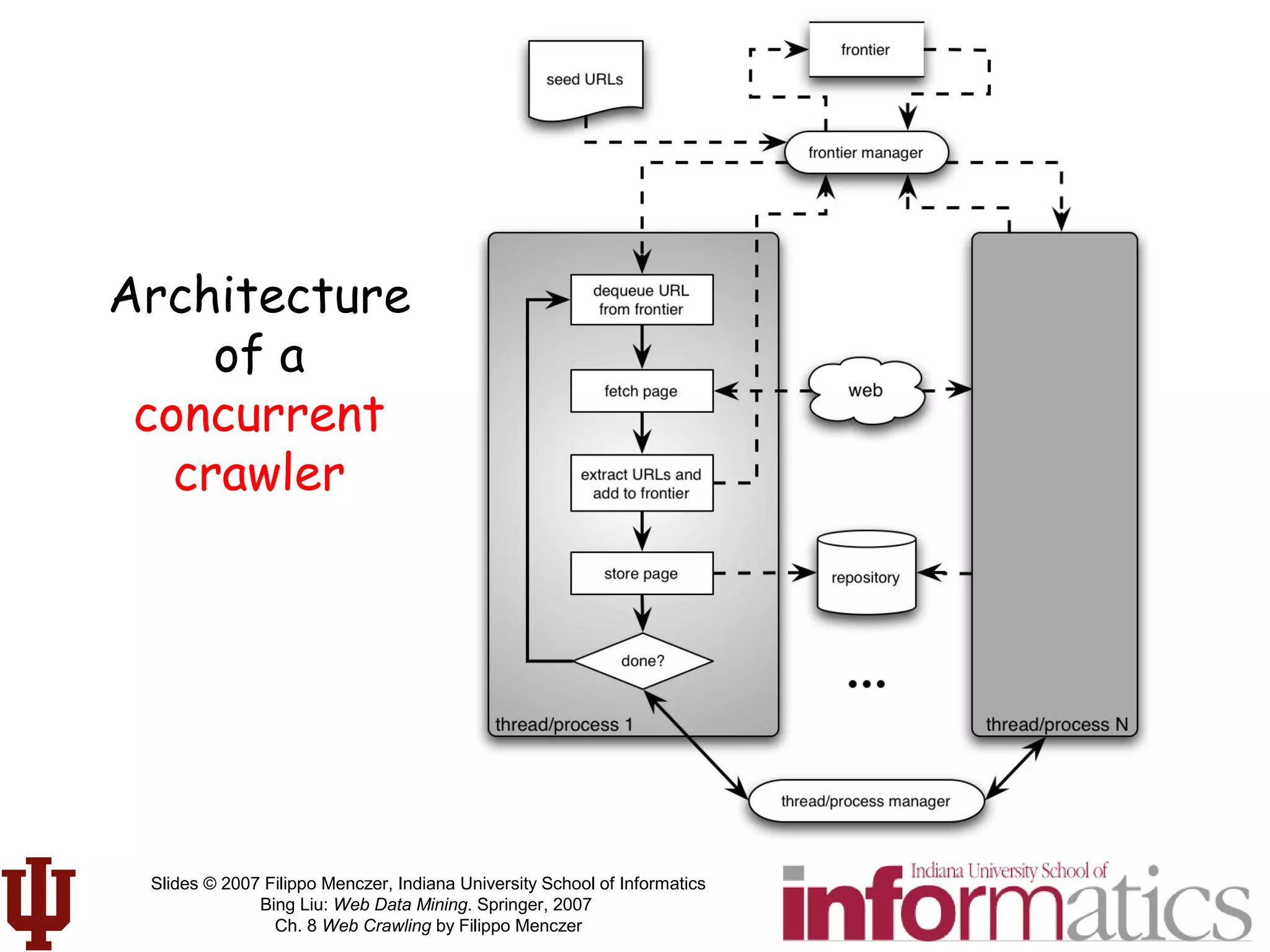
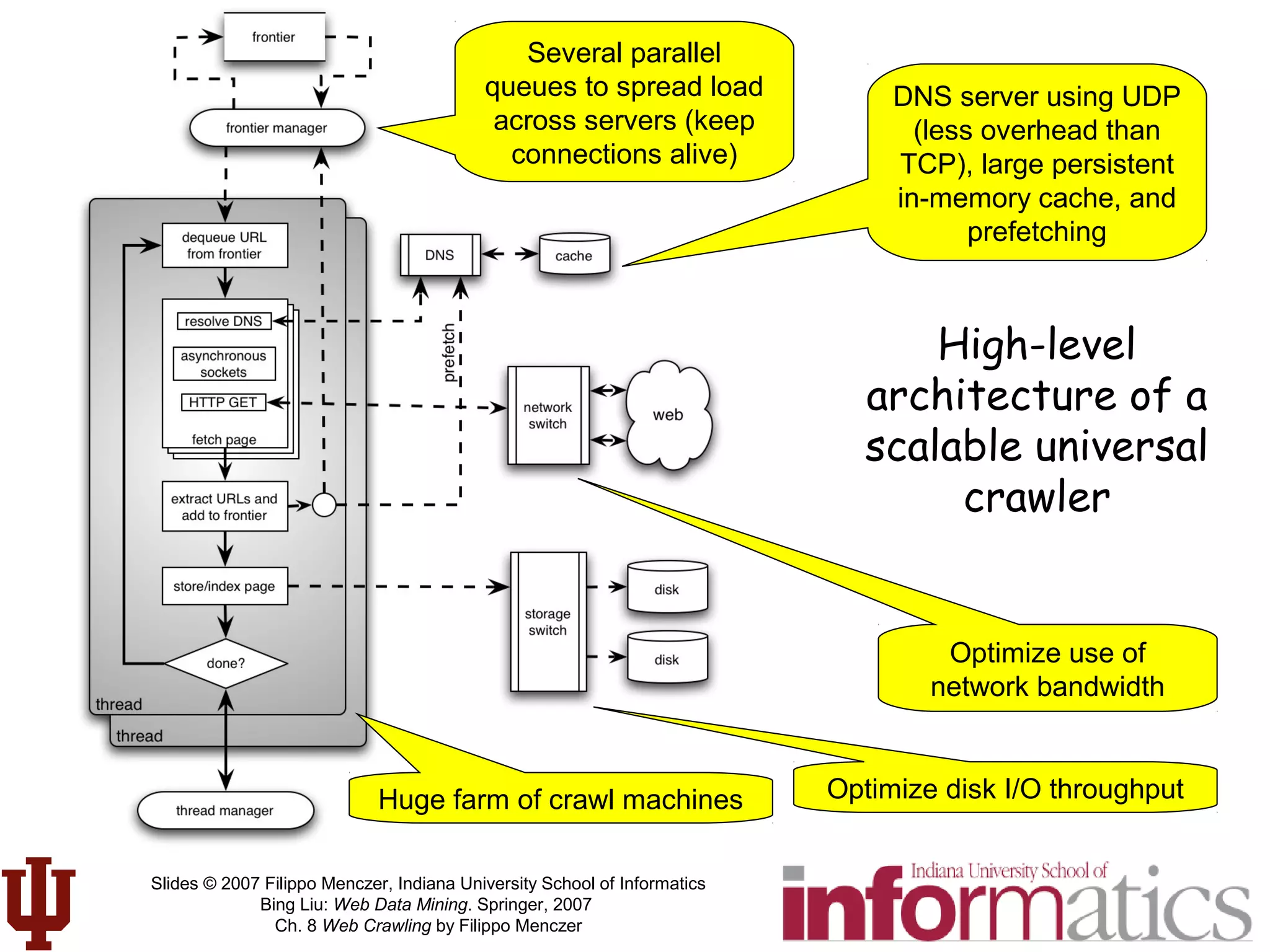
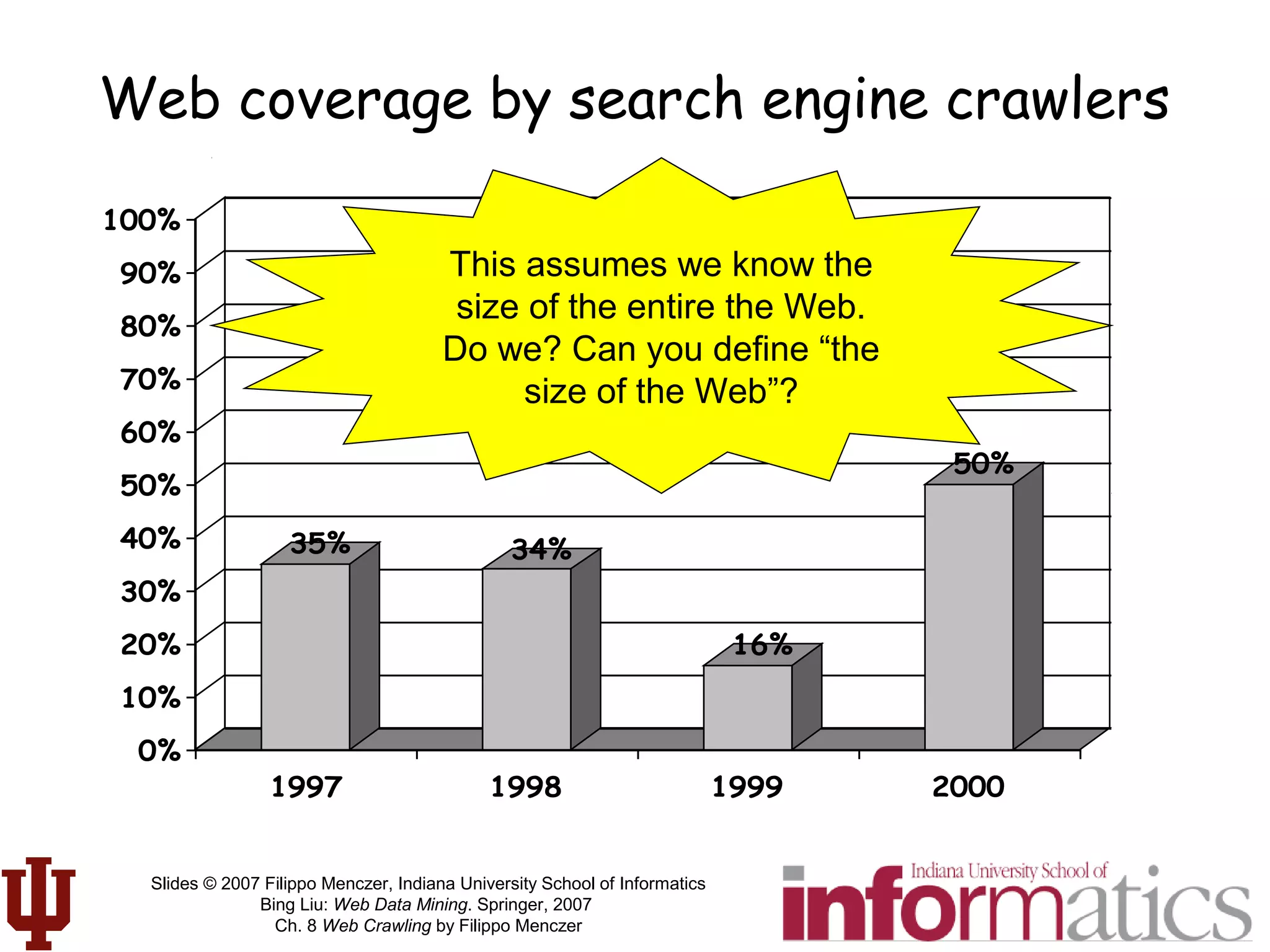
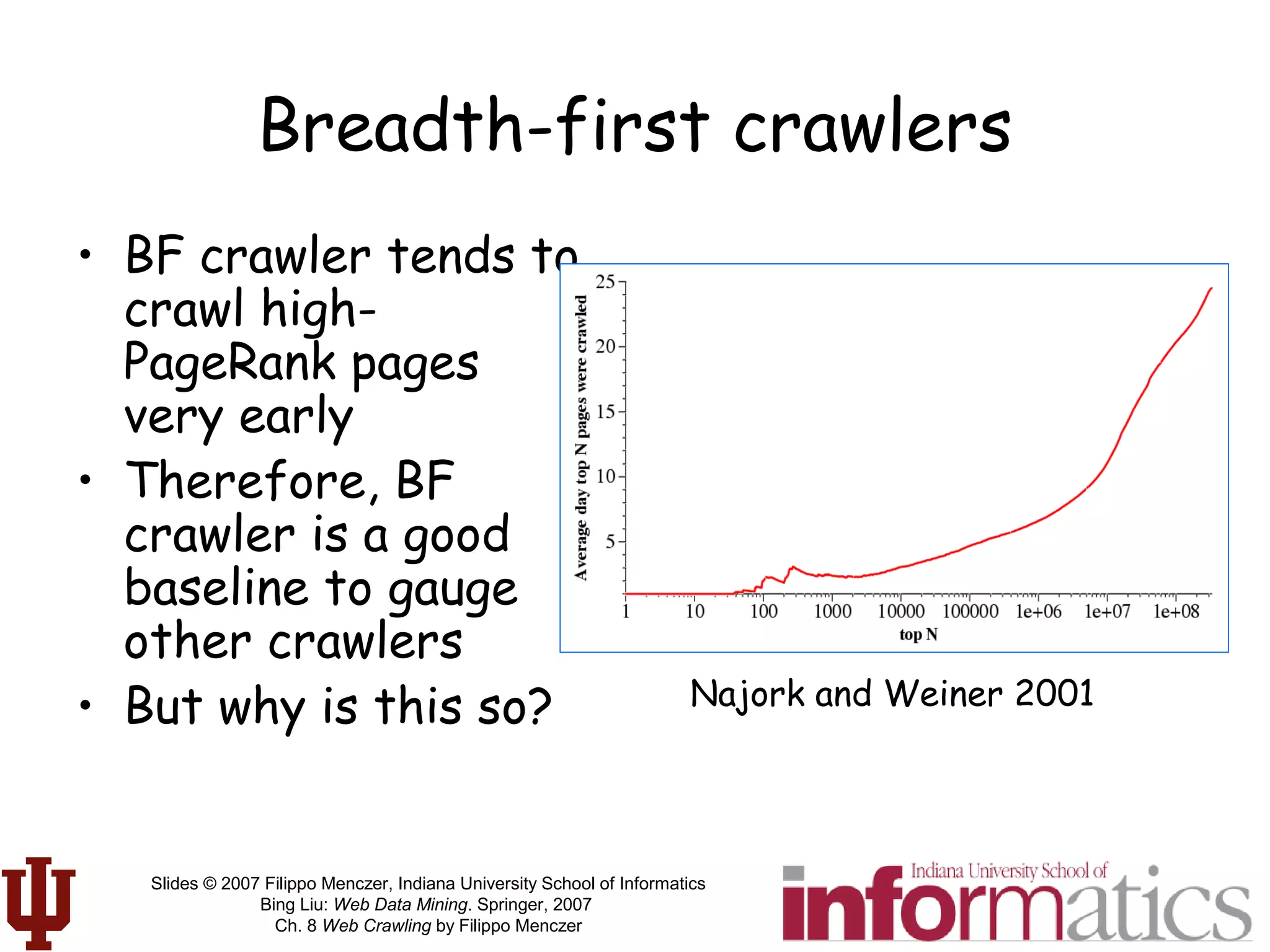
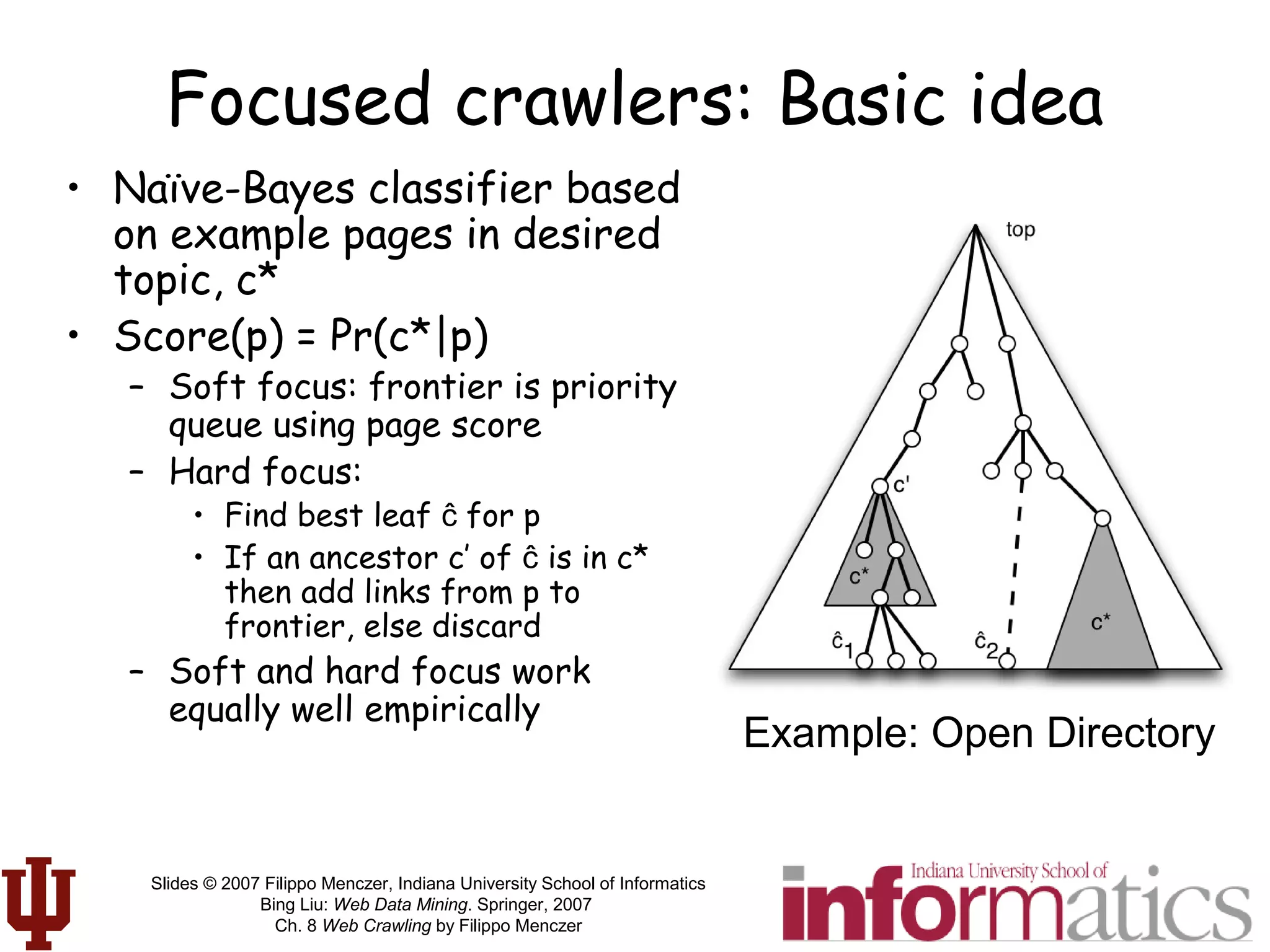
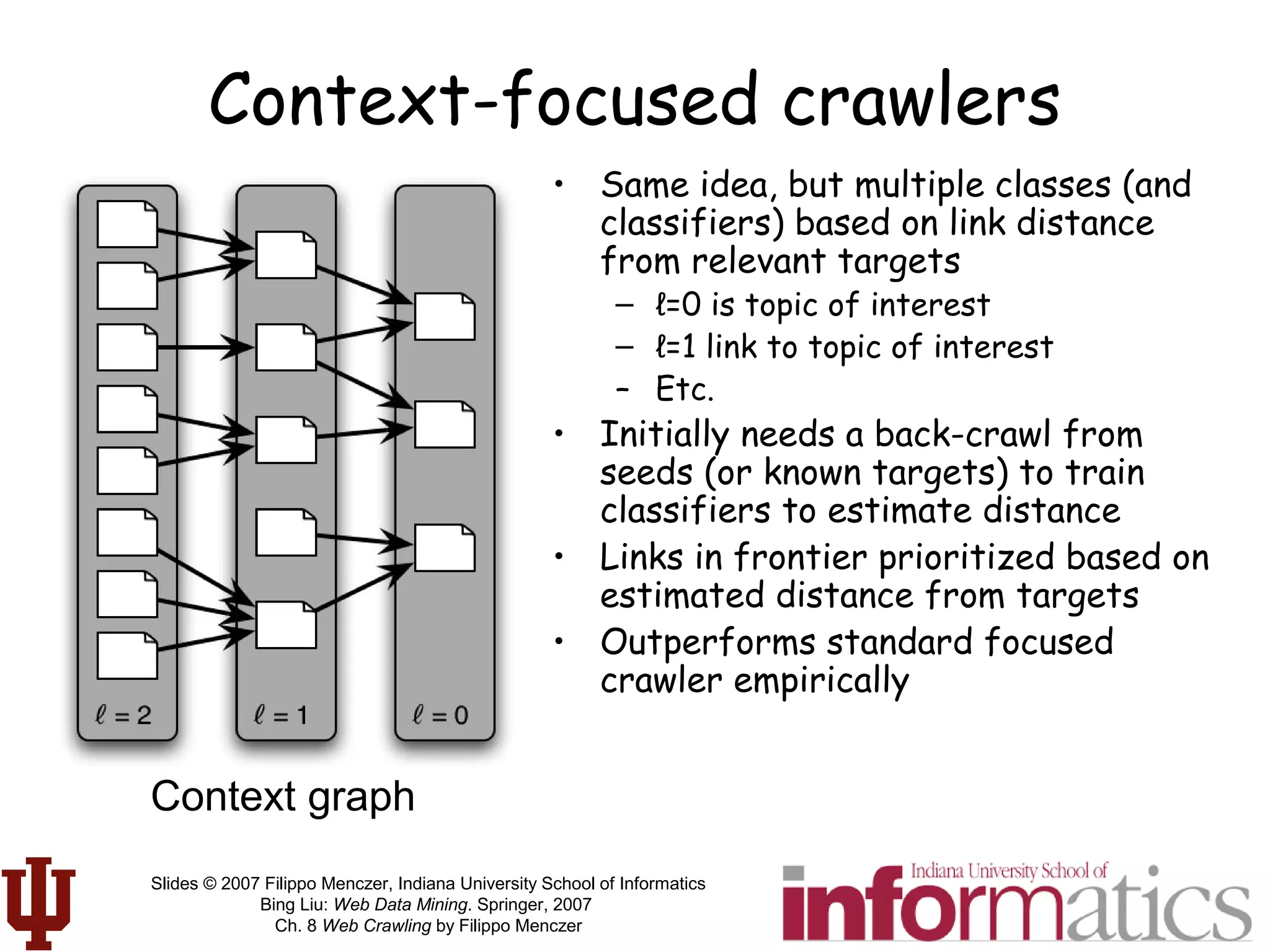
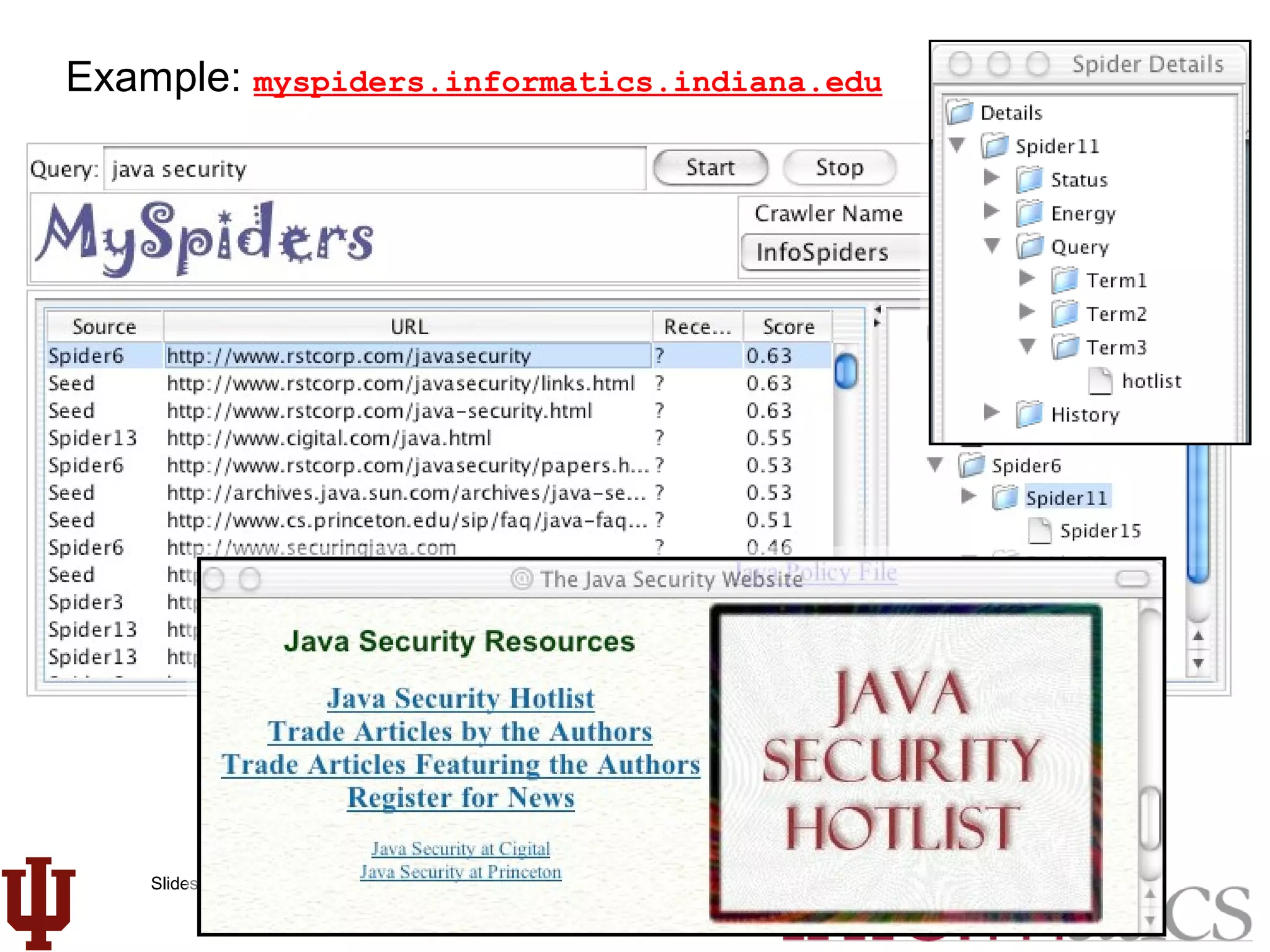
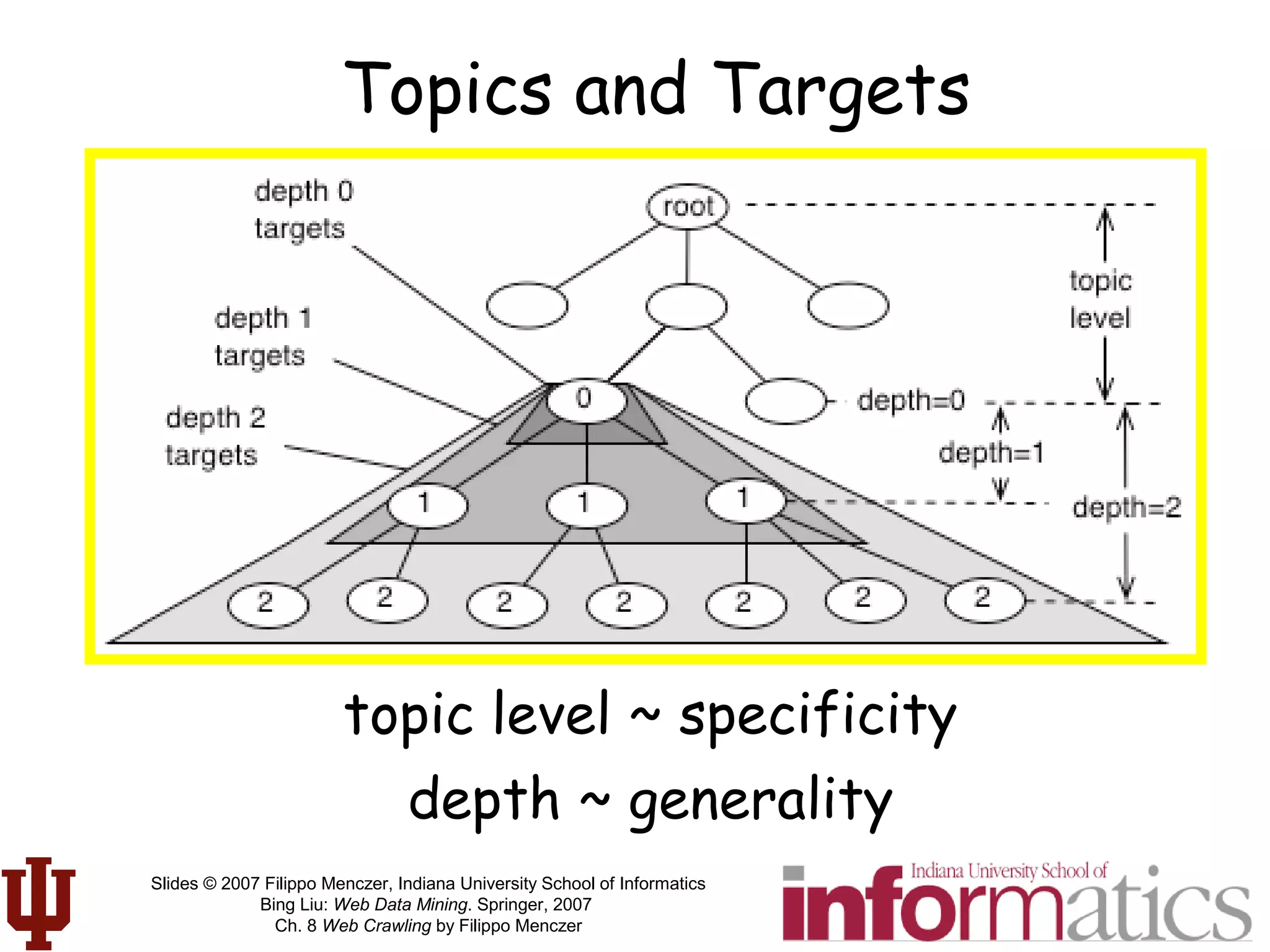
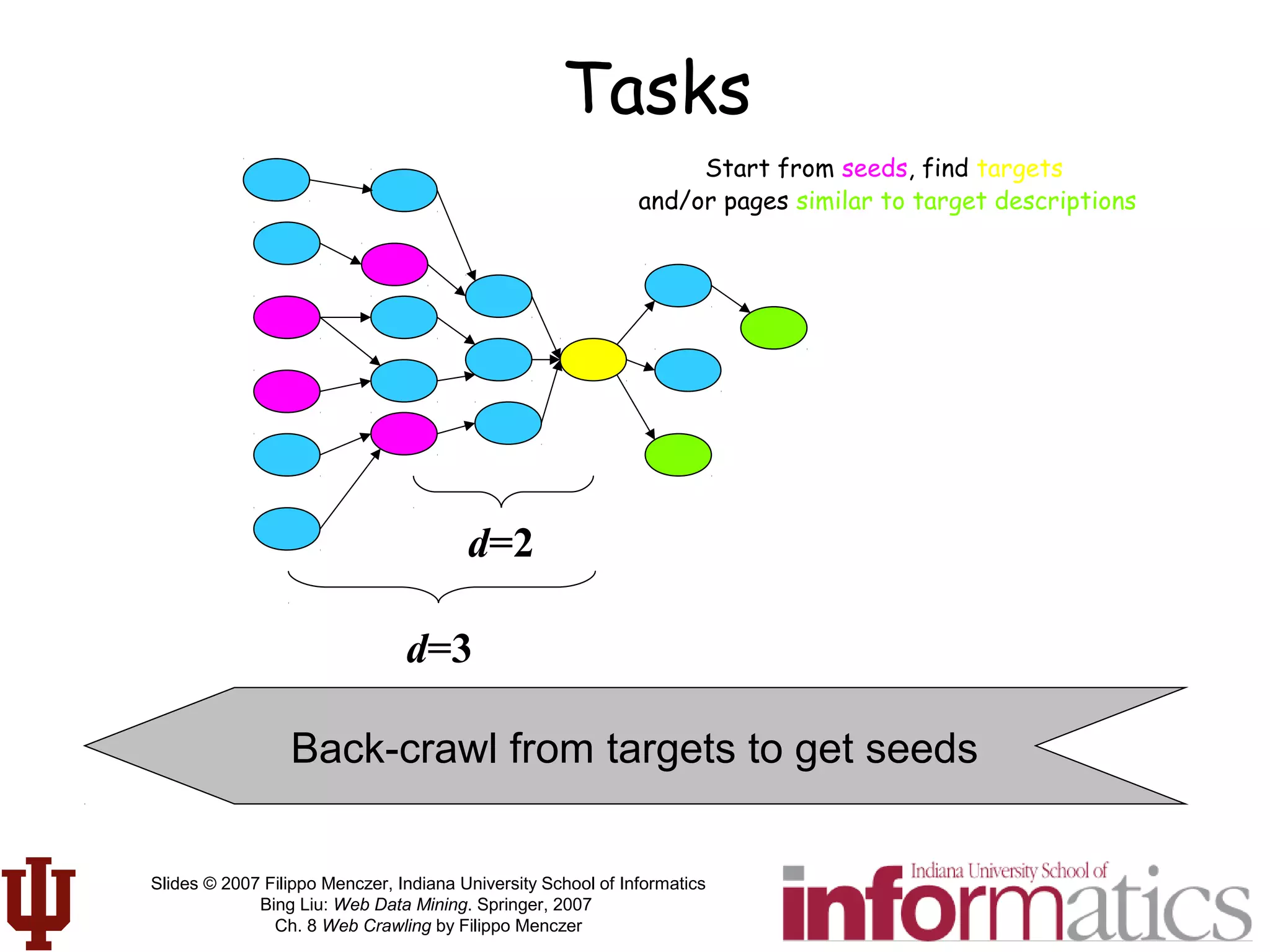
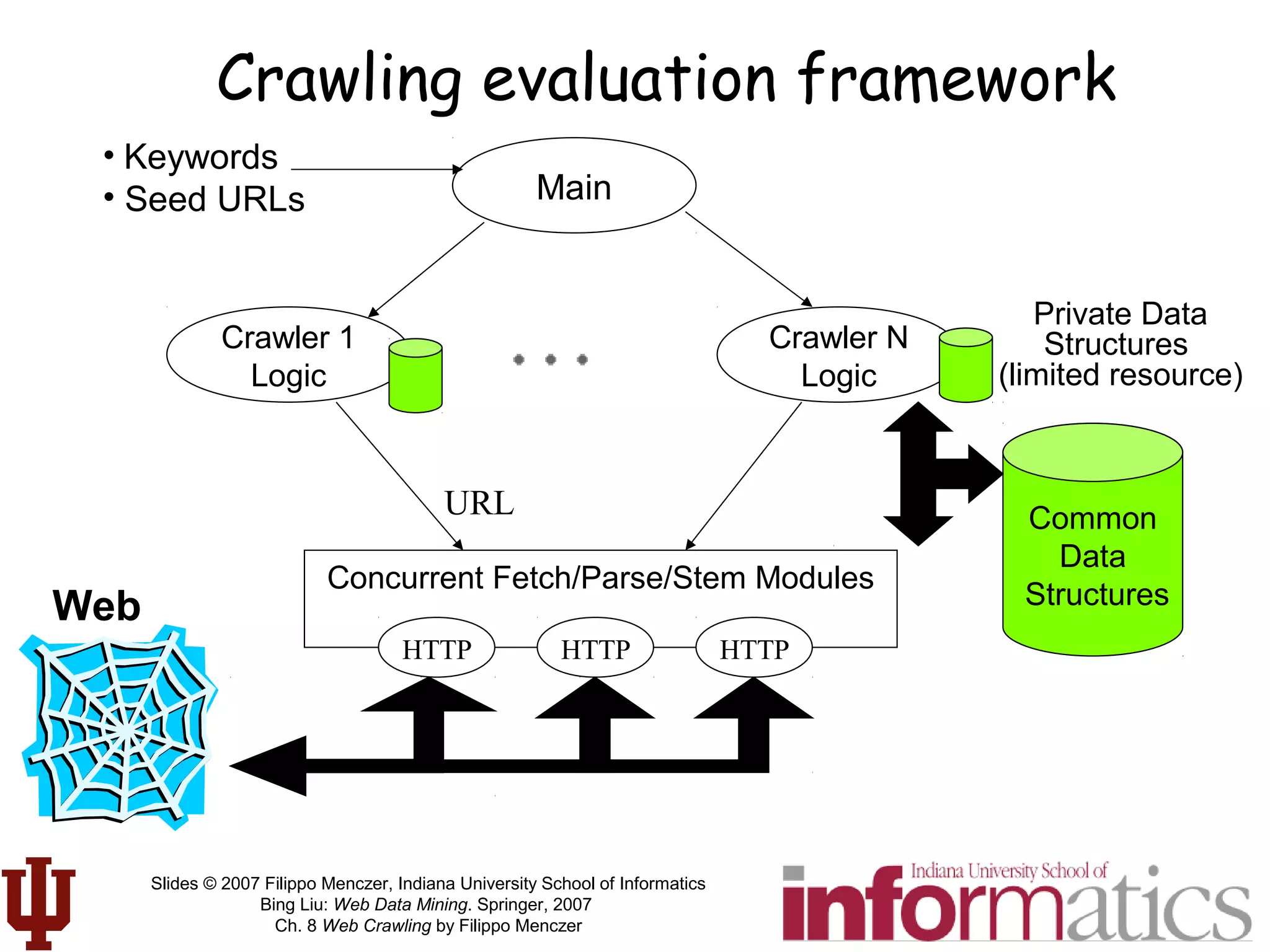
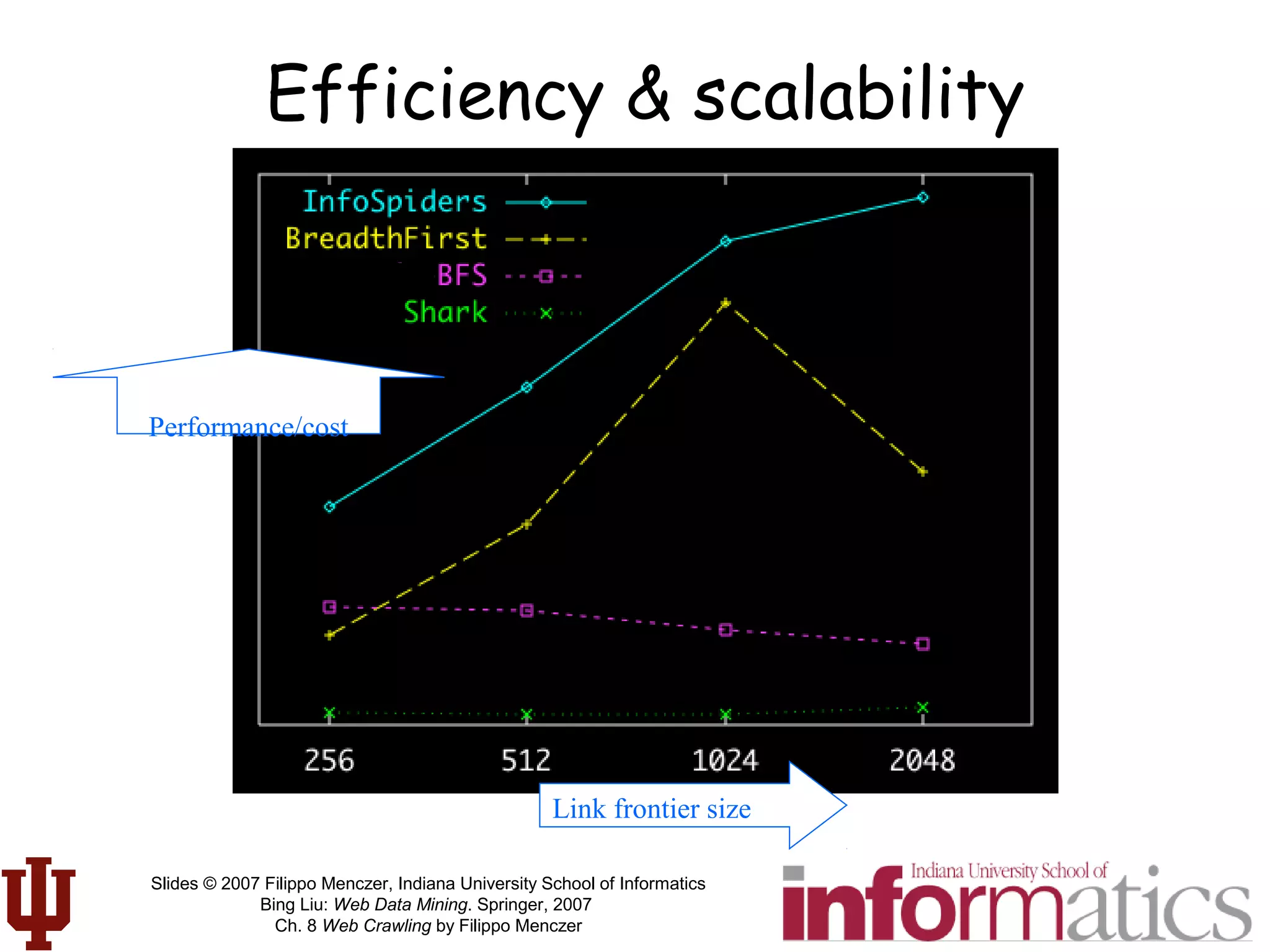
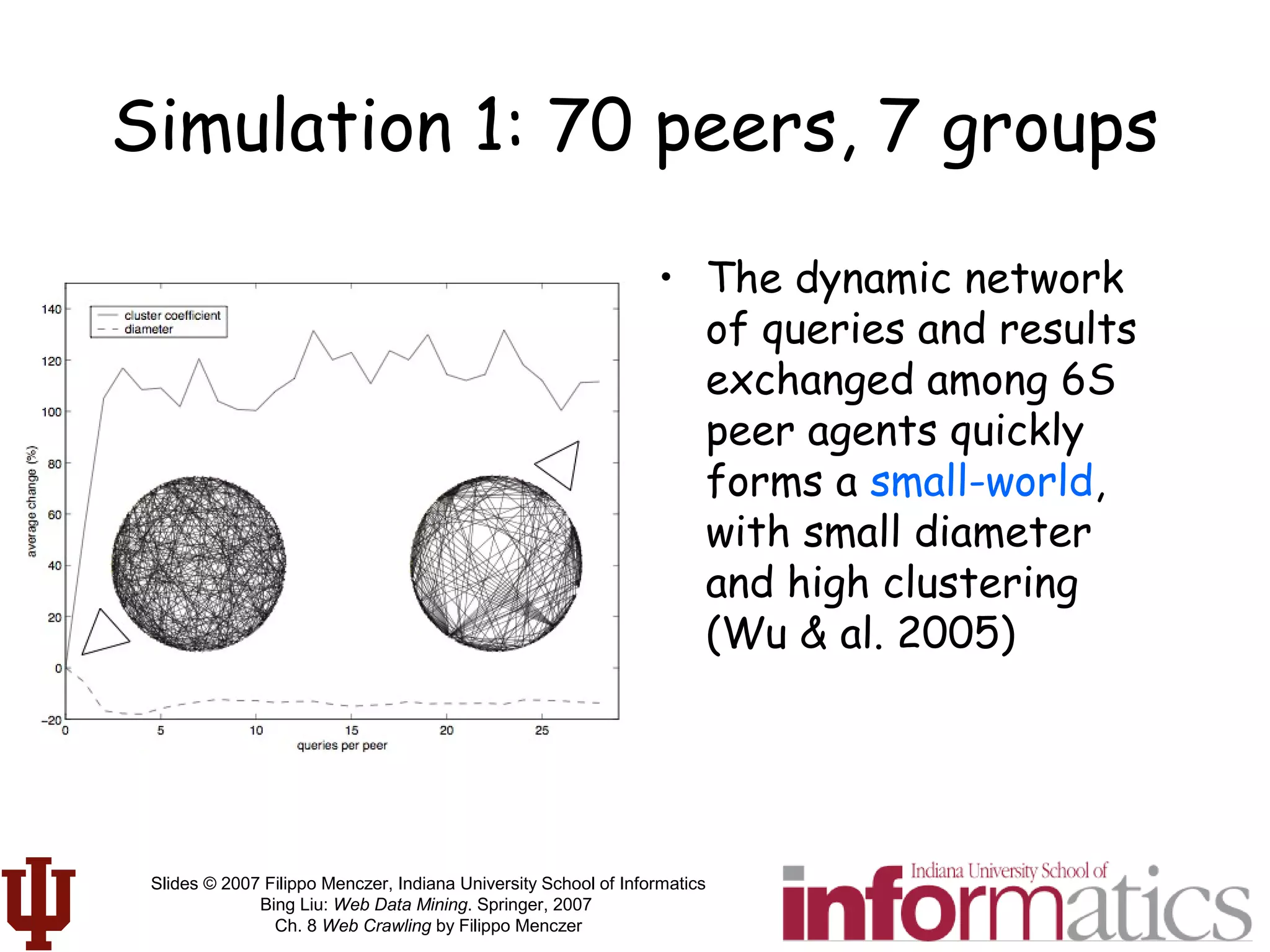
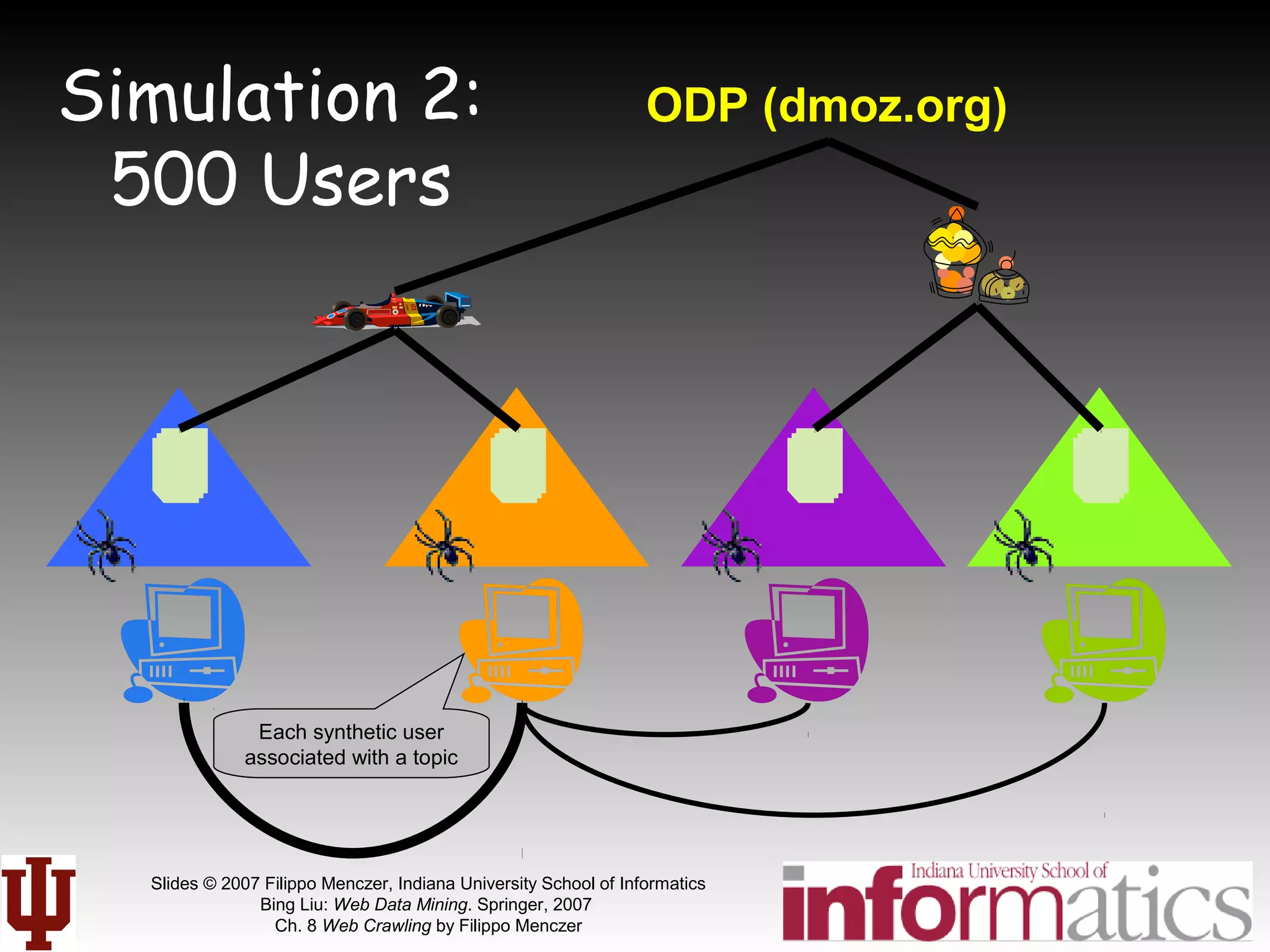
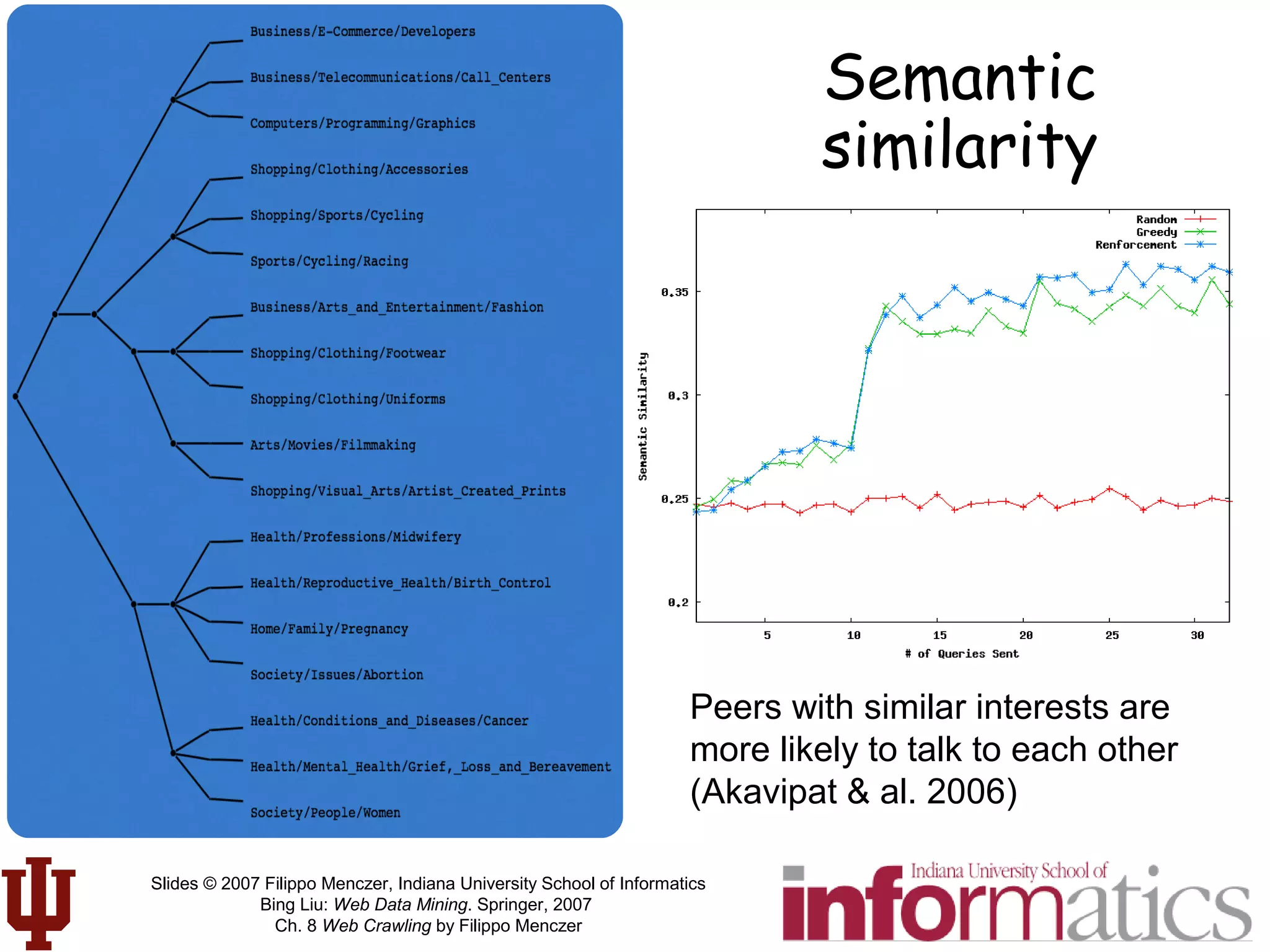
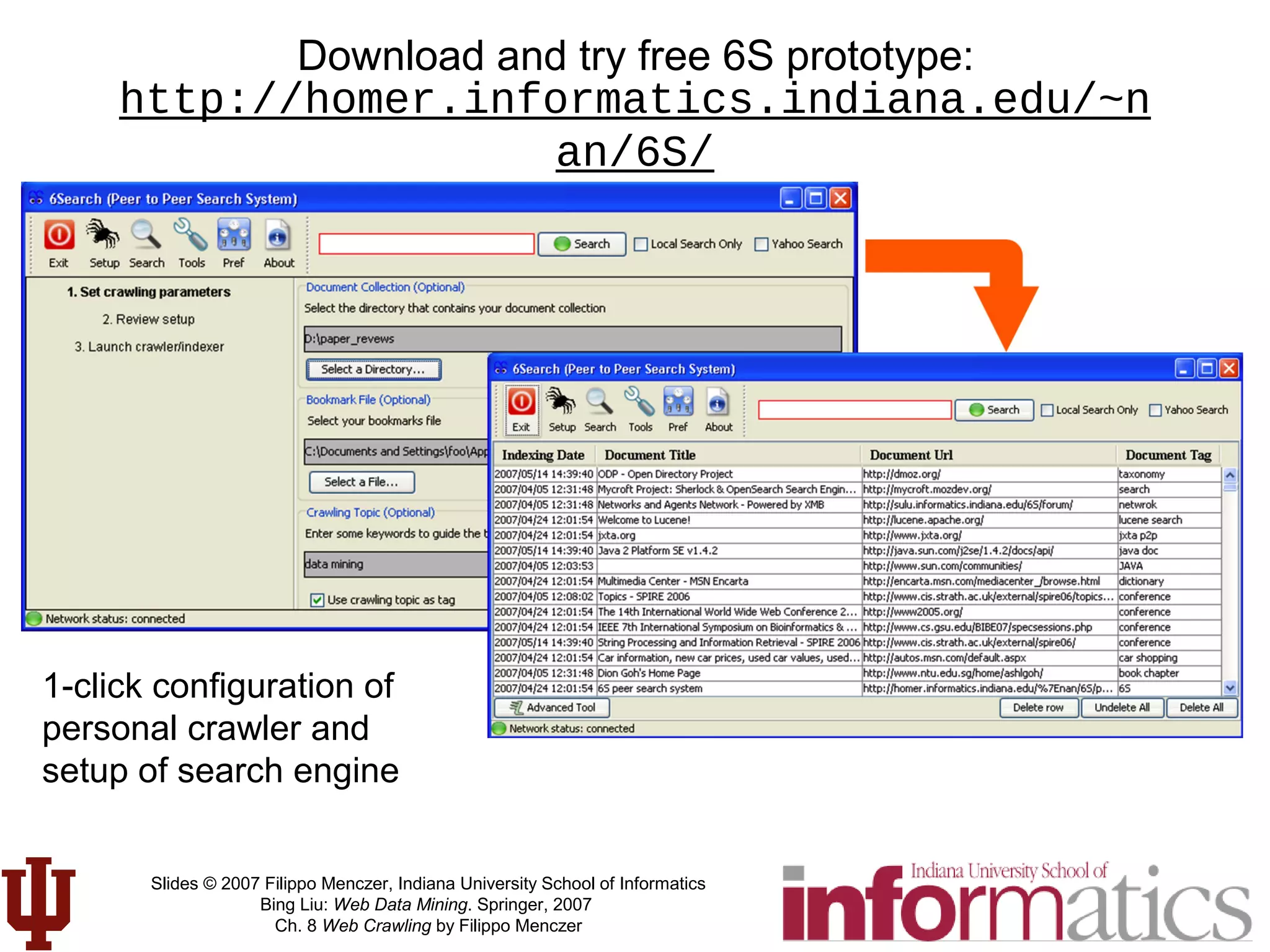
This document discusses web crawling techniques. It begins with an outline of topics covered, including the motivation and taxonomy of crawlers, basic crawlers and implementation issues, universal crawlers, preferential crawlers, crawler evaluation, ethics, and new developments. It then covers basic crawlers and their implementation, including graph traversal techniques, a basic crawler code example in Perl, and various implementation issues around fetching, parsing, indexing text, dealing with dynamic content, relative URLs, and URL canonicalization.








































![Slides © 2007 Filippo Menczer, Indiana University School of Informatics
Bing Liu: Web Data Mining. Springer, 2007
Ch. 8 Web Crawling by Filippo Menczer
G = 5/15
C = 2
R = 3/6
= 2/4
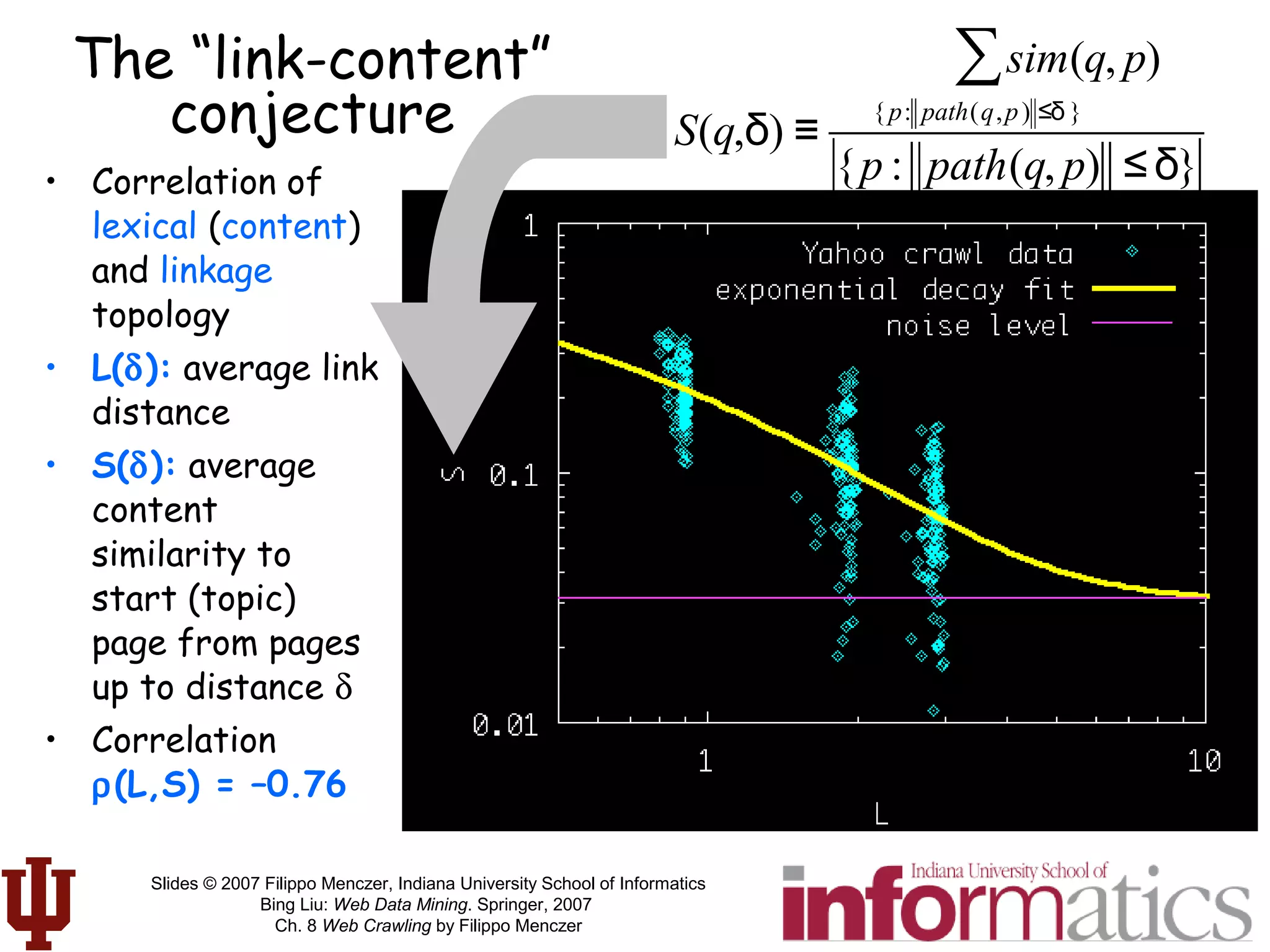
The “link-cluster” conjecture
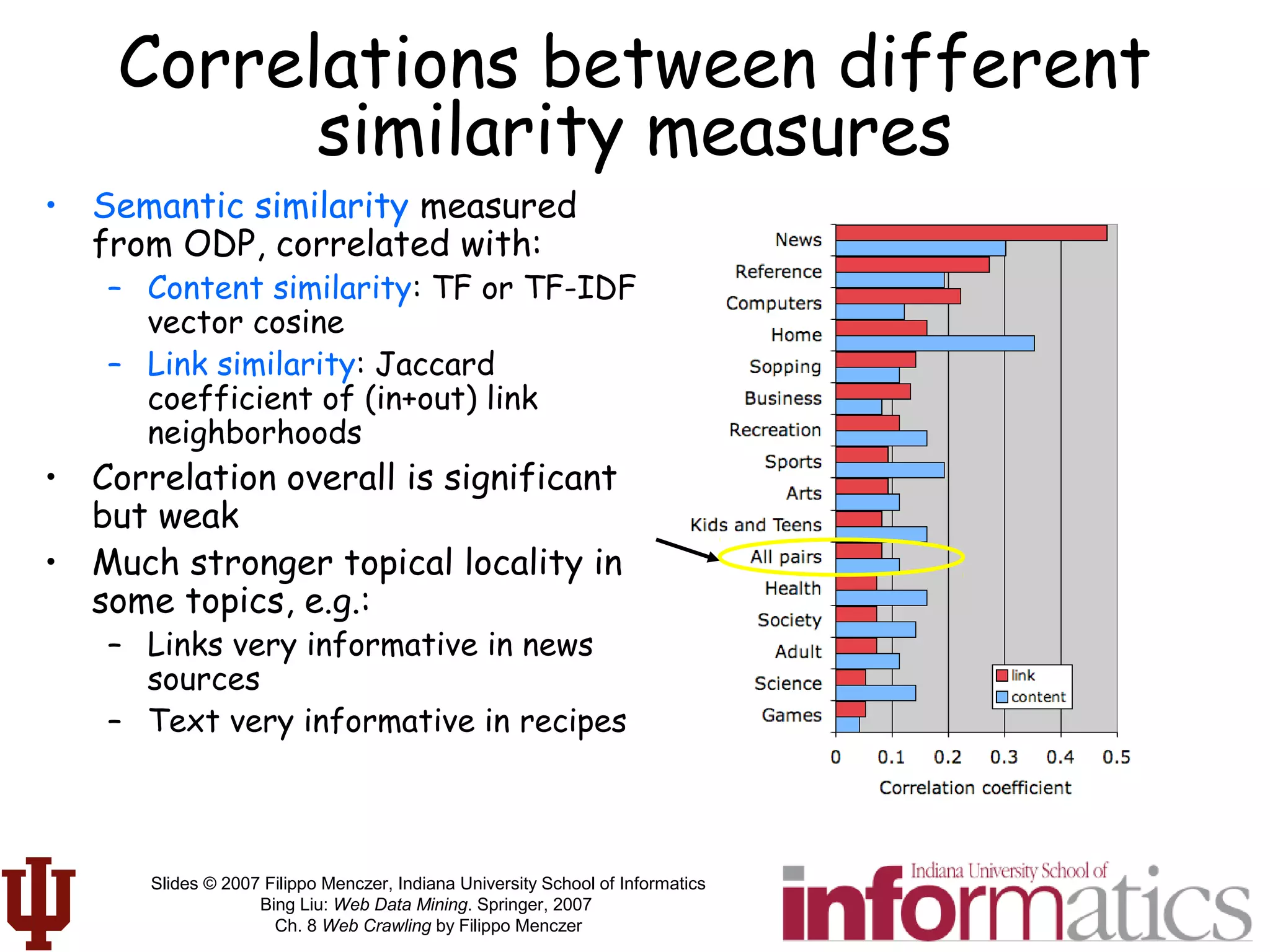
• Connection between semantic topology (relevance) and
link topology (hypertext)
– G = Pr[rel(p)] ~ fraction of relevant/topical pages (topic generality)
– R = Pr[rel(p) | rel(q) AND link(q,p)] ~ cond. prob. Given neighbor on topic
• Related nodes are clustered if R > G
– Necessary and
sufficient
condition for a
random crawler
to find pages related
to start points
– Example:
2 topical clusters
with stronger
modularity within
each cluster than outside](https://image.slidesharecdn.com/webcrawlingchapter-190227092242/75/Web-crawlingchapter-54-2048.jpg)

![Slides © 2007 Filippo Menczer, Indiana University School of Informatics
Bing Liu: Web Data Mining. Springer, 2007
Ch. 8 Web Crawling by Filippo Menczer
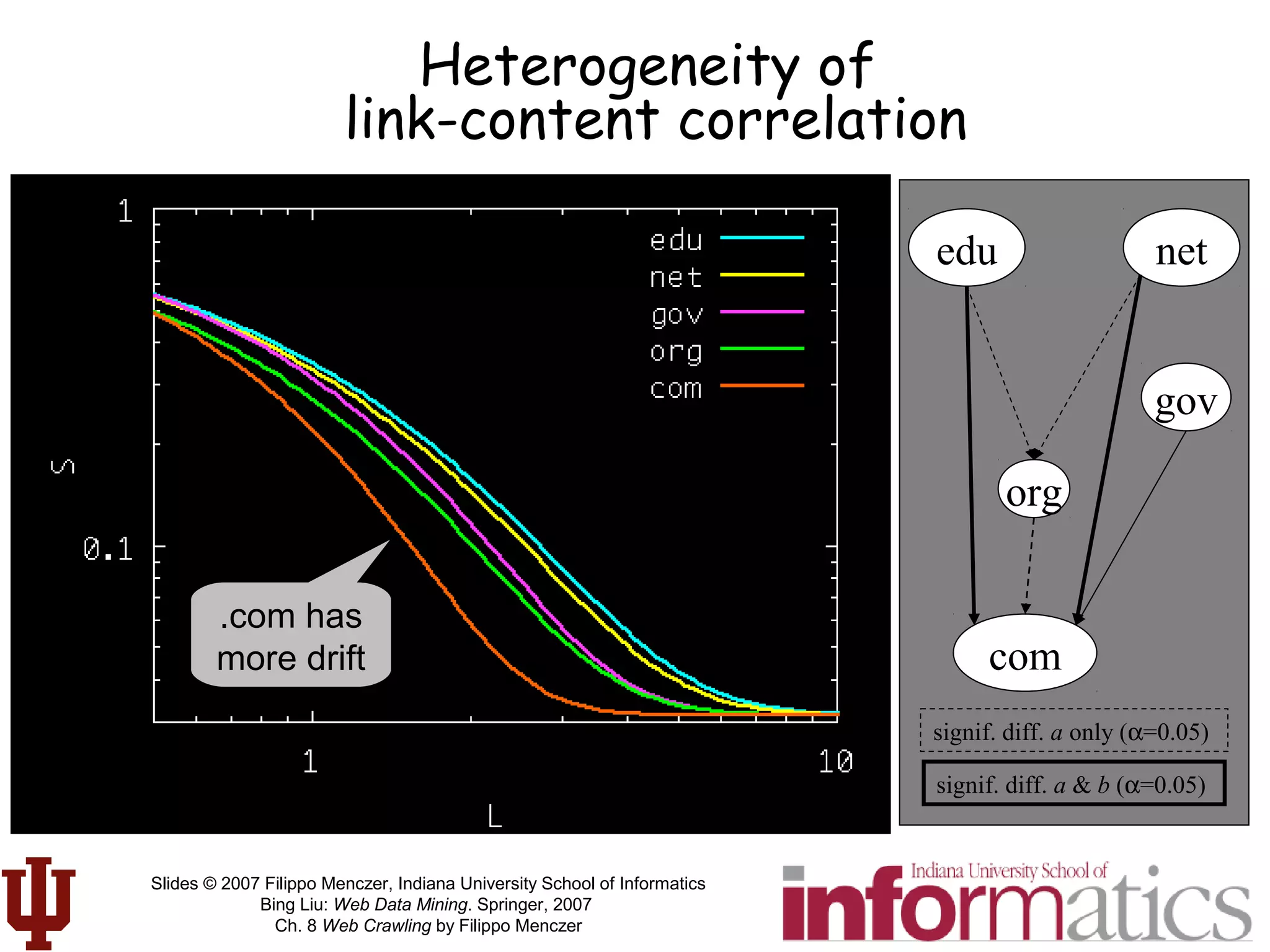
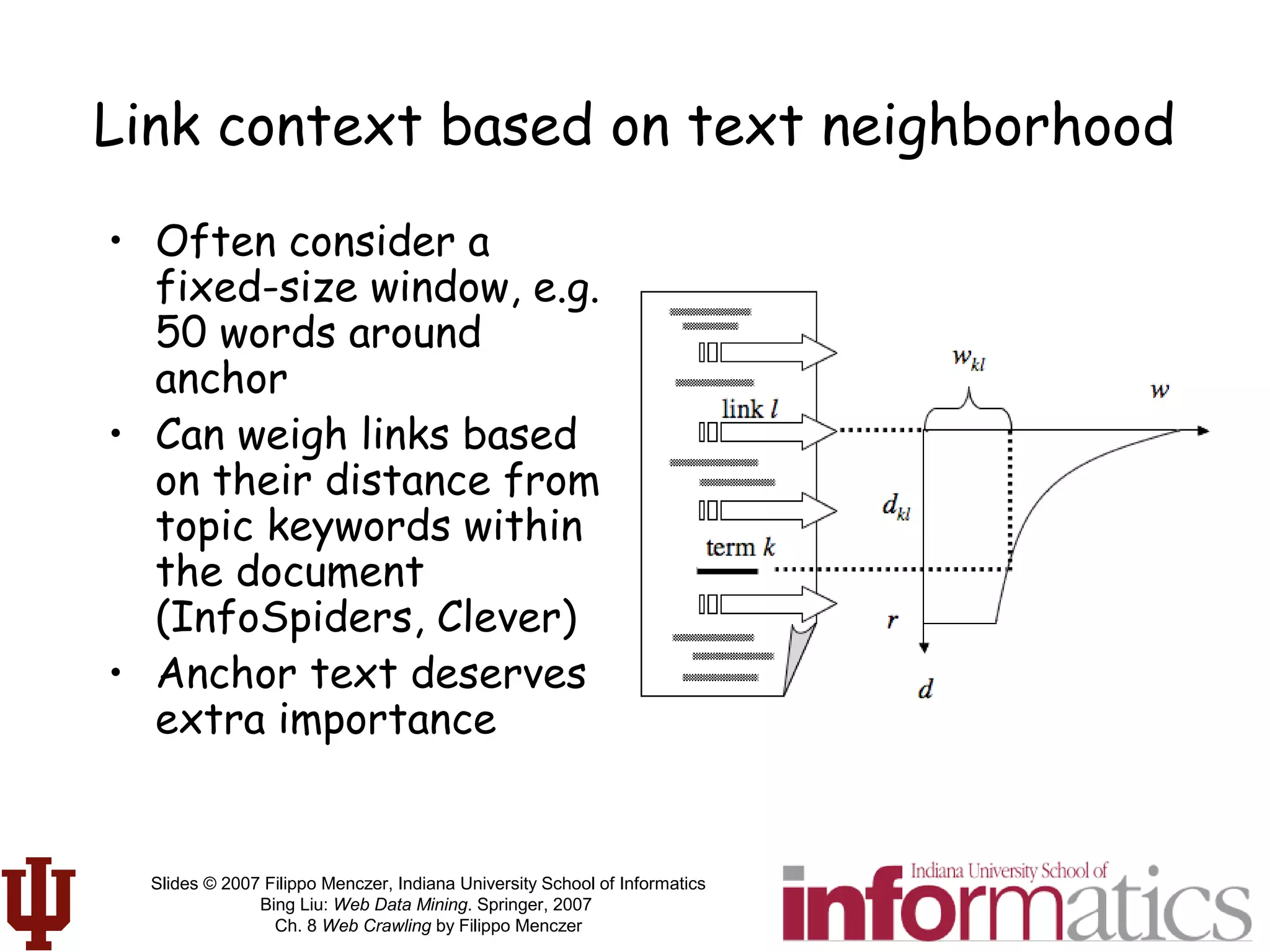
• Preservation of
semantics (meaning)
across links
• 1000 times more
likely to be on topic
if near an on-topic
page!
Link-cluster
conjecture
R(q,δ)
G(q)
≡
Pr rel(p) | rel(q)∧ path(q, p) ≤δ[ ]
Pr[rel(p)]
L(q,δ) ≡
path(q, p)
{ p: path(q,p) ≤δ }
∑
{p : path(q, p) ≤δ}](https://image.slidesharecdn.com/webcrawlingchapter-190227092242/75/Web-crawlingchapter-56-2048.jpg)




![Slides © 2007 Filippo Menczer, Indiana University School of Informatics
Bing Liu: Web Data Mining. Springer, 2007
Ch. 8 Web Crawling by Filippo Menczer
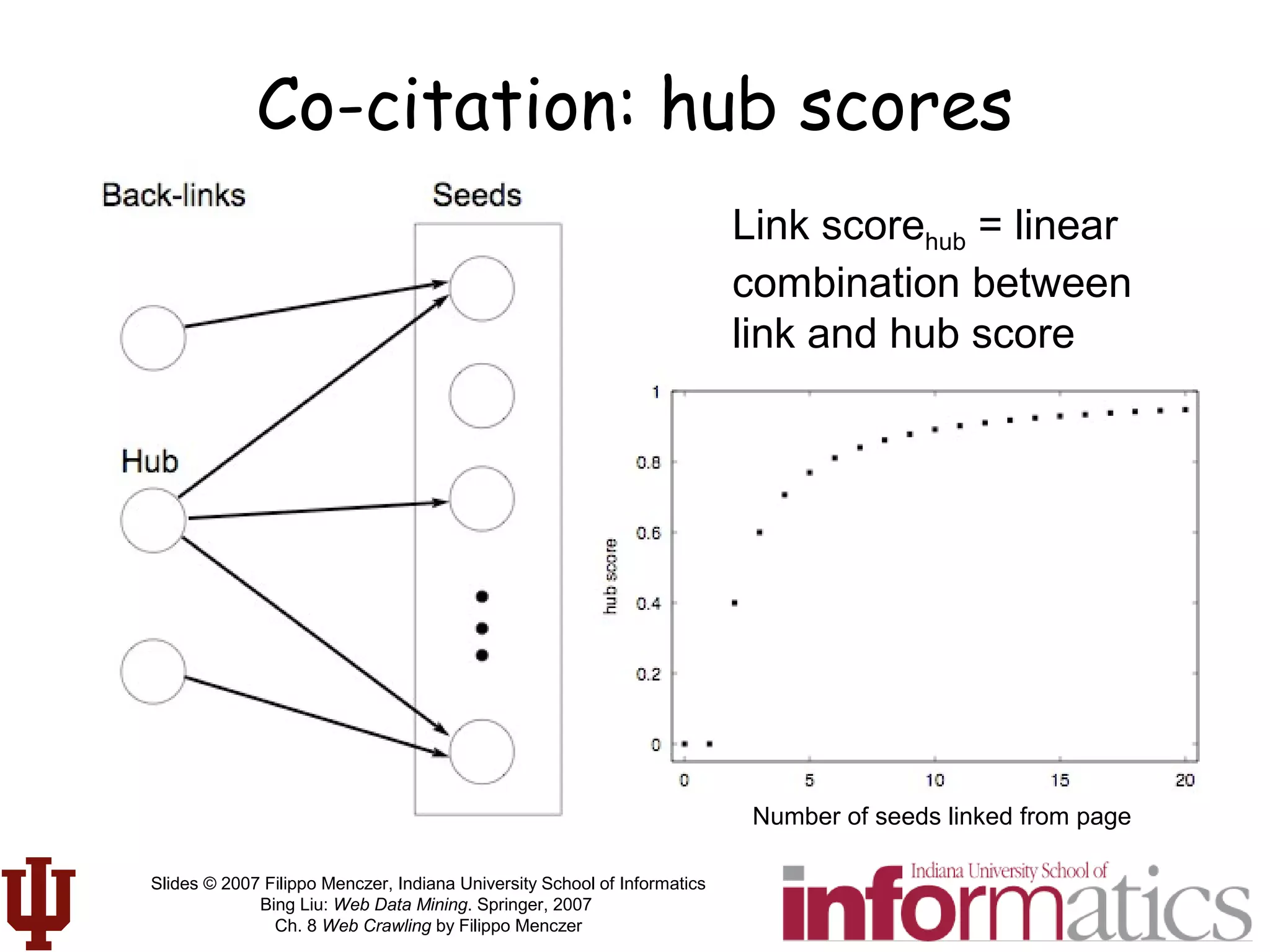
Pr l[ ] =
εβλλ
εβλλ∋
λ∋
∑
λλ= ννετ ιν1,...,ινΝ( )
ινκ =
δ κ,ω( )
διστω,λ( )ω∈∆
∑
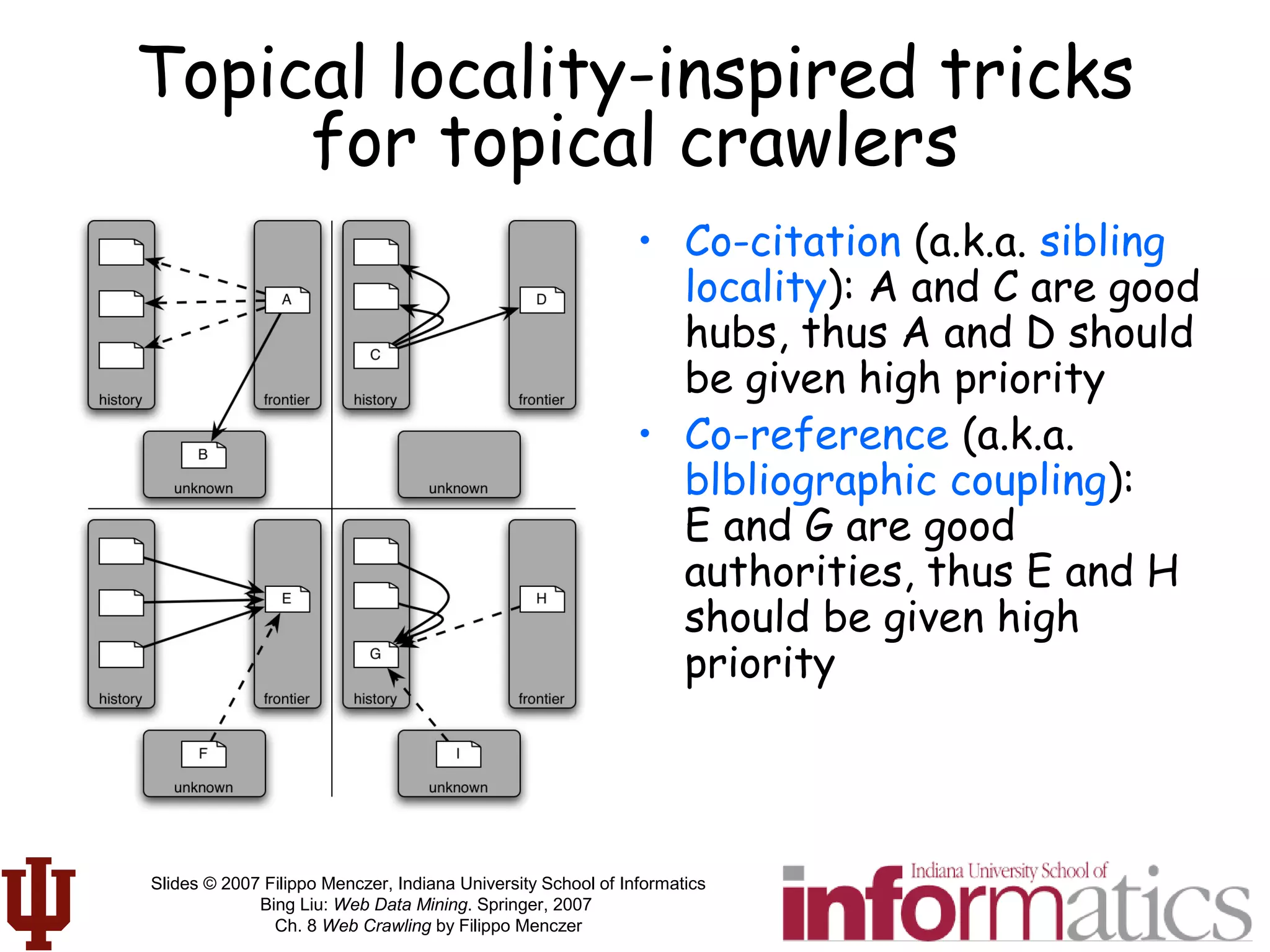
link l instances of ki
λl
k1
kn
ki
agent's neural net
sum of matches
with
inverse-distance
weighting
link l Instances
of ki
Agent’s neural net
Stochastic
selector
Link scoring and
selection by each
crawling agent](https://image.slidesharecdn.com/webcrawlingchapter-190227092242/75/Web-crawlingchapter-70-2048.jpg)



![Slides © 2007 Filippo Menczer, Indiana University School of Informatics
Bing Liu: Web Data Mining. Springer, 2007
Ch. 8 Web Crawling by Filippo Menczer
Reinforcement Learning
• In general, reward function R: S A ℜ
• Learn policy (π: S A) to maximize reward
over time, typically discounted in the
future:
• Q-learning: optimal policy
V = γt
r(t),
t
∑ 0 ≤ γ <1
π*
(s) = argmax
a
Q(s,a)
= argmax
a
R(s,a) + γV*
(s')[ ]
s
s2a2
a1 s1
Value of following optimal policy in future](https://image.slidesharecdn.com/webcrawlingchapter-190227092242/75/Web-crawlingchapter-76-2048.jpg)






















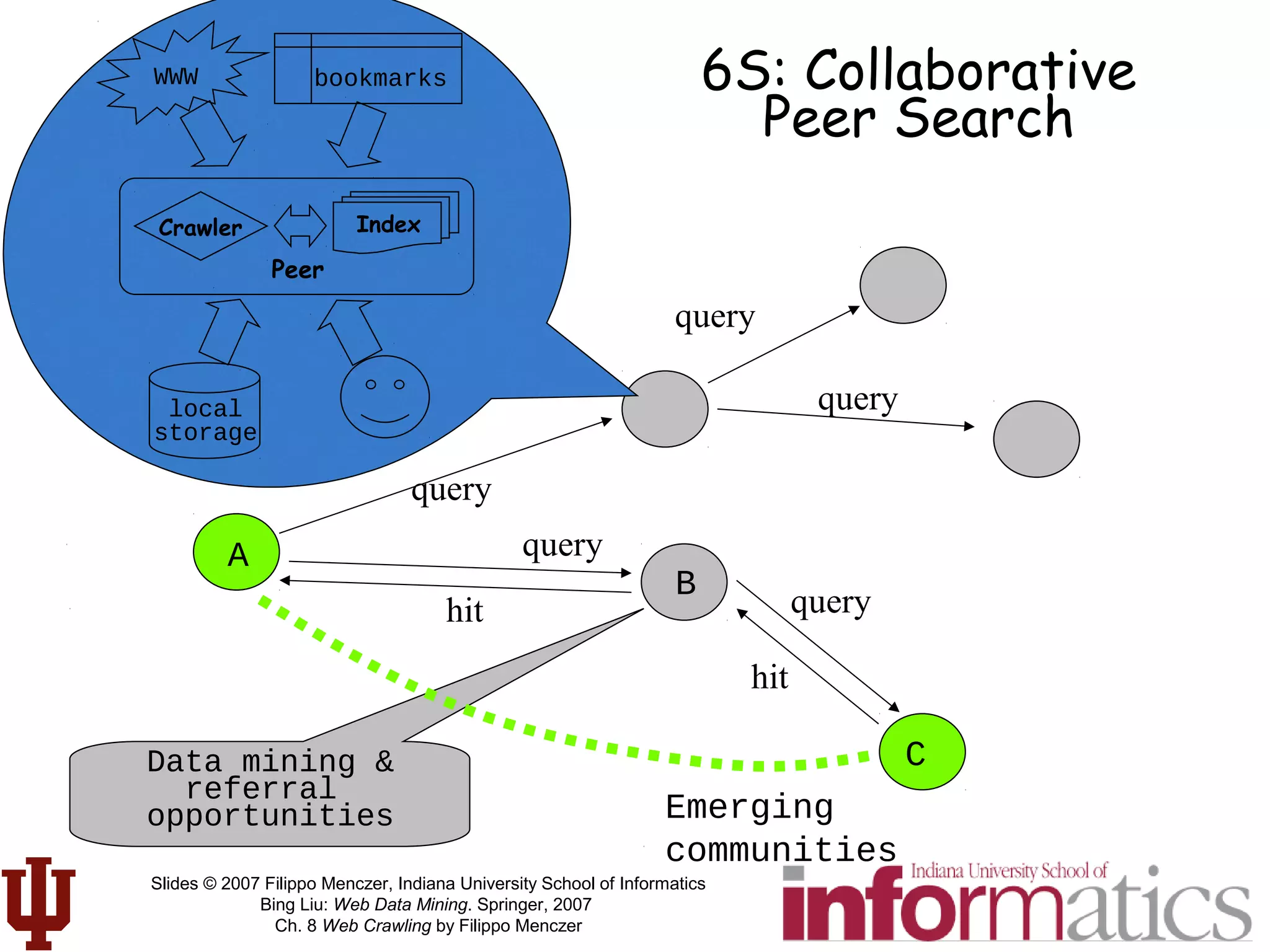
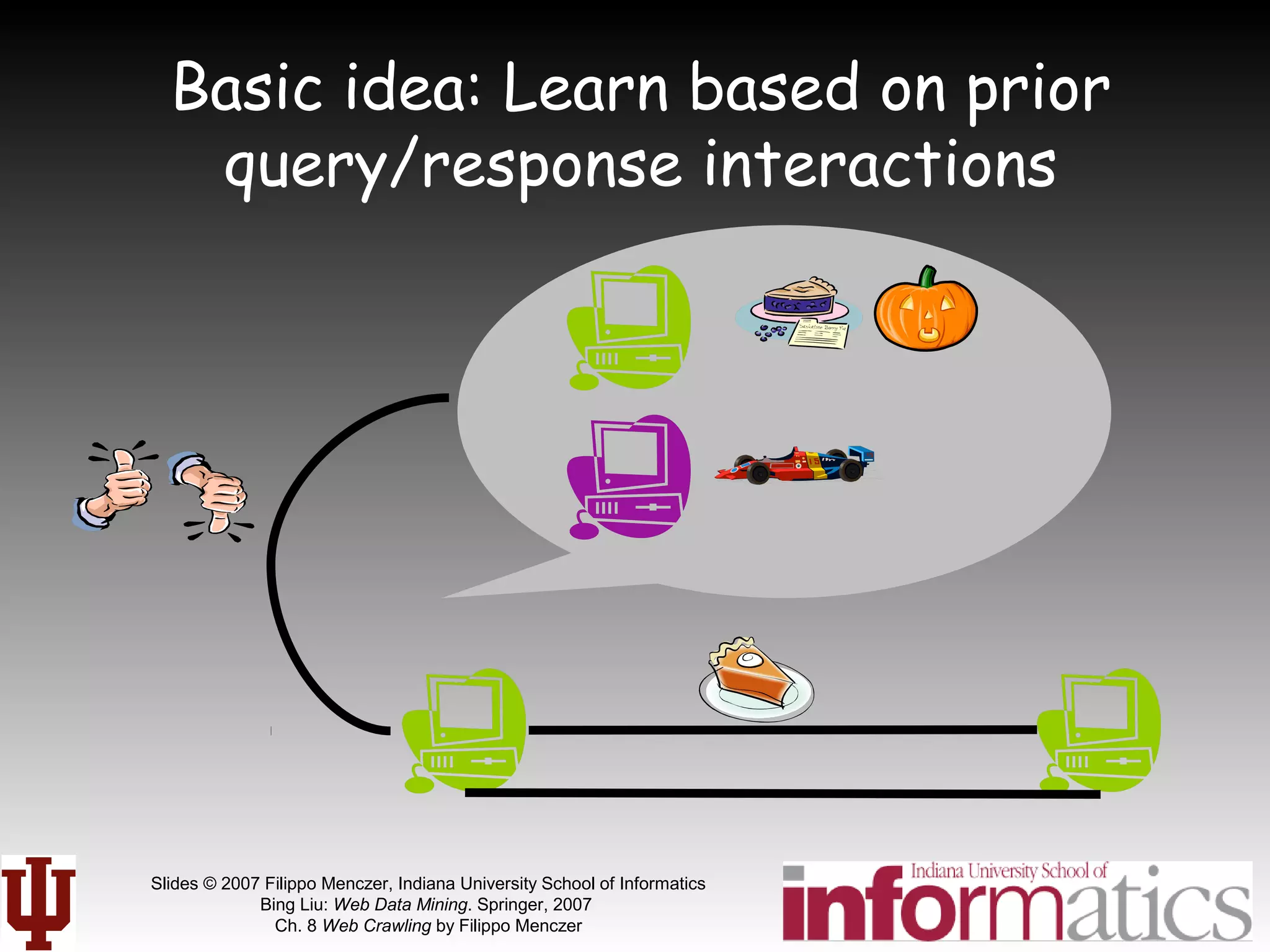

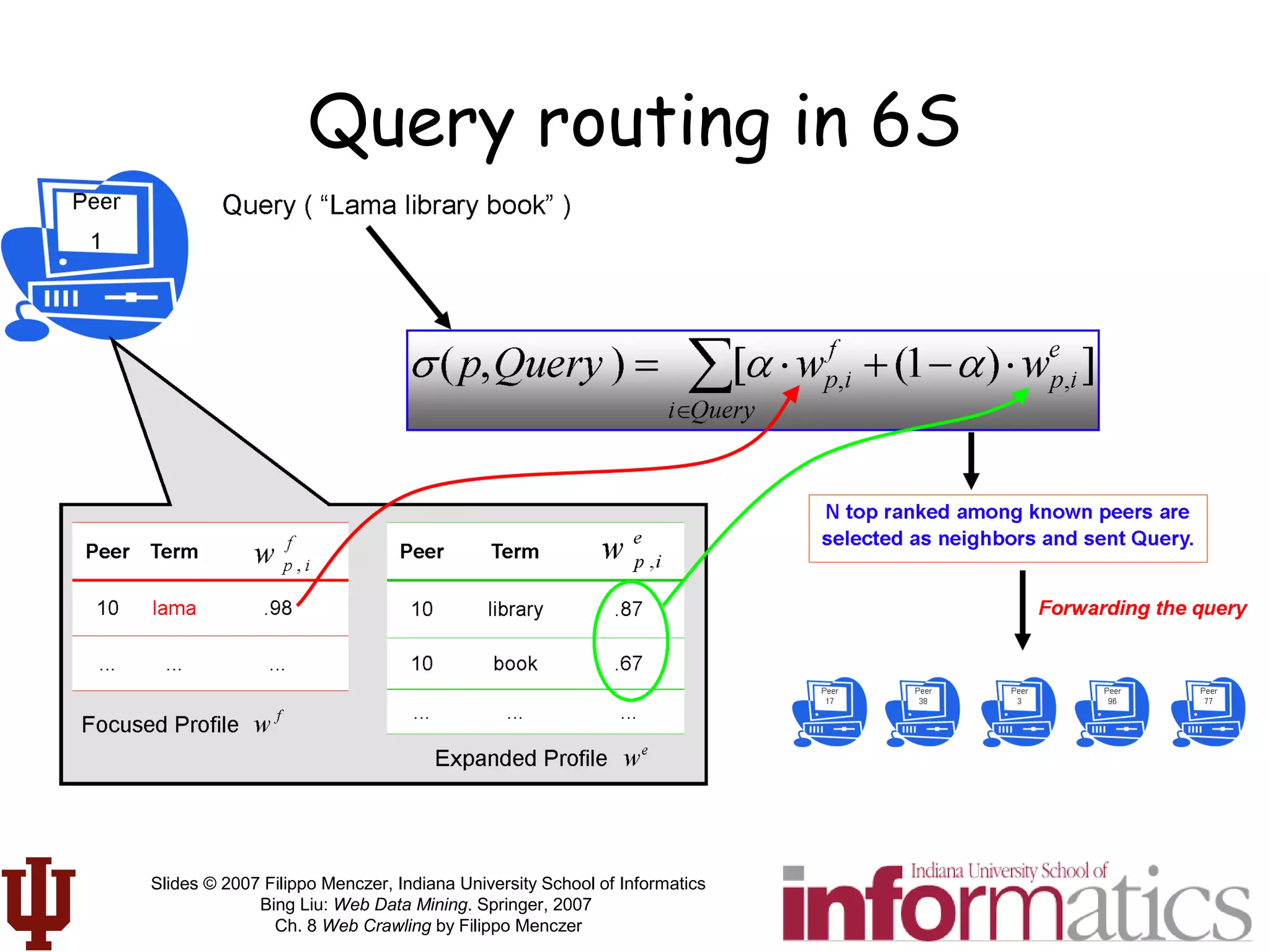
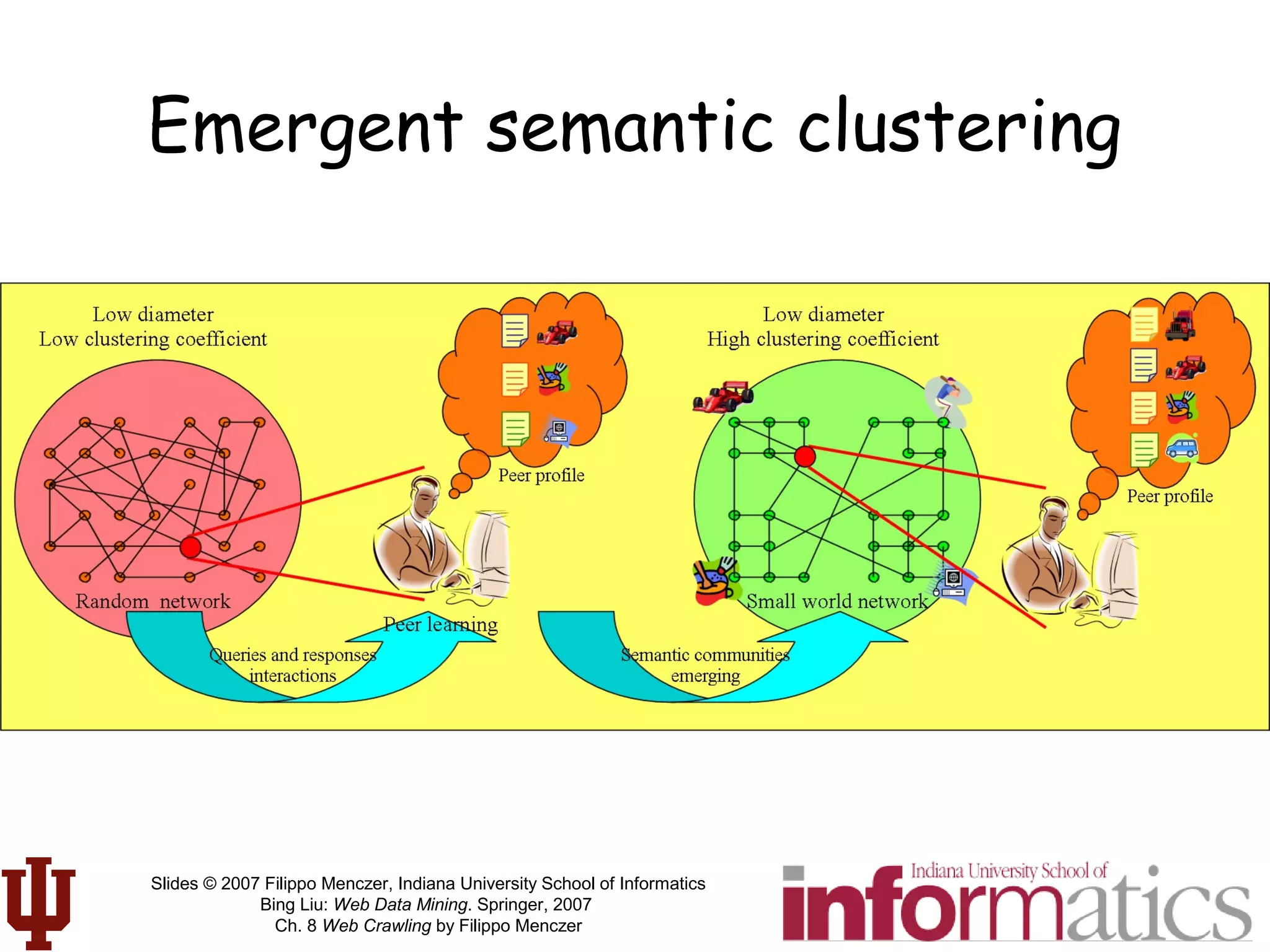

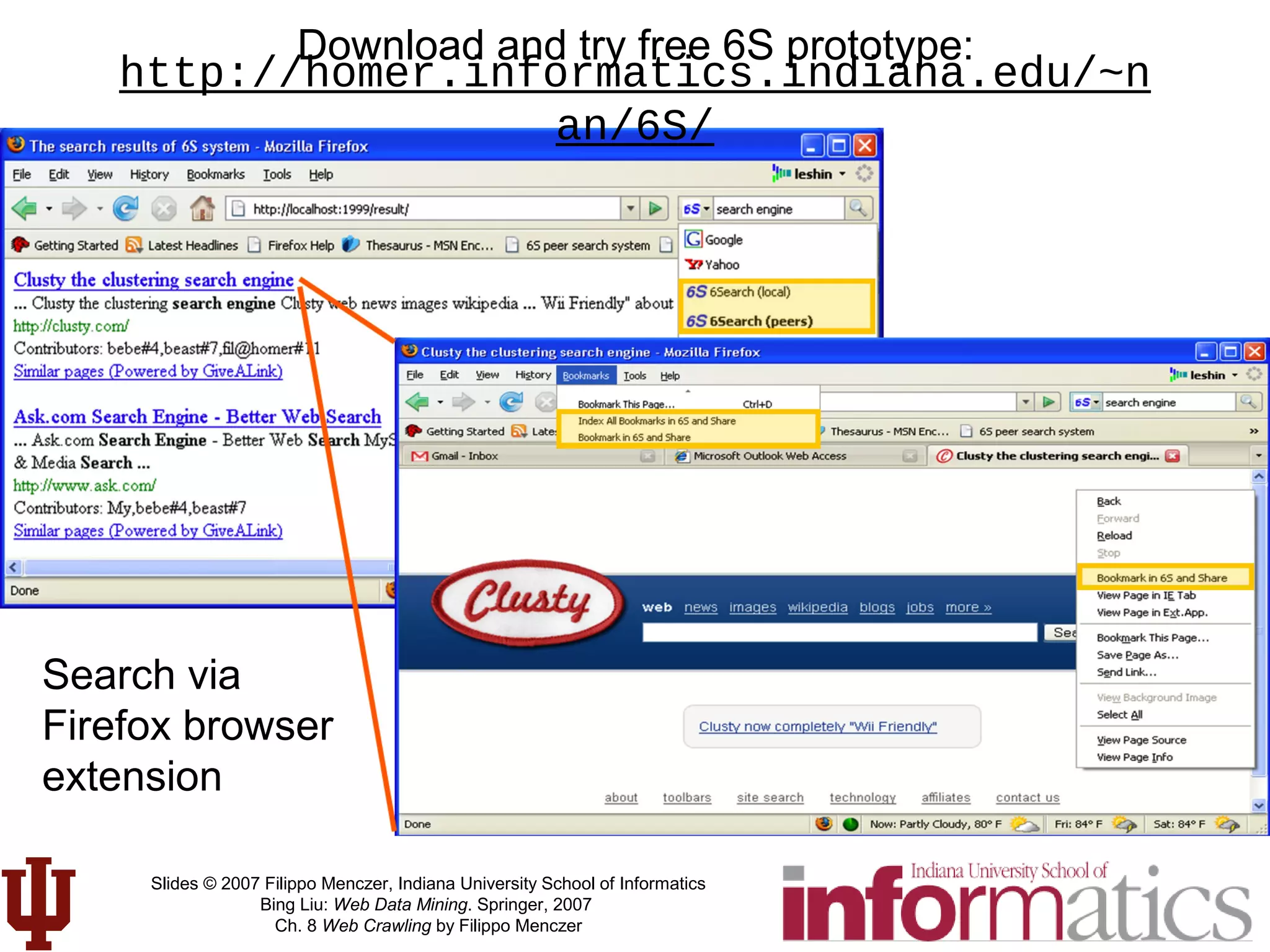






































![[LvDuit//Lab] Crawling the web](https://cdn.slidesharecdn.com/ss_thumbnails/crawlingtheweb-140901103920-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




































