Download to read offline




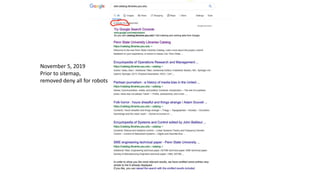



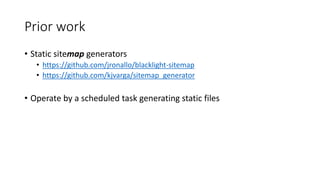




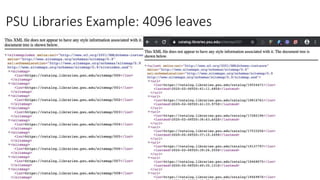
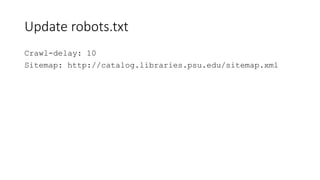
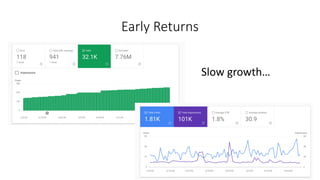
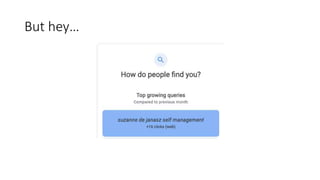
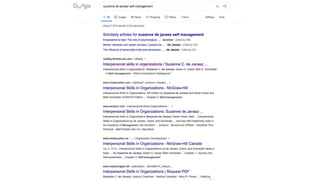
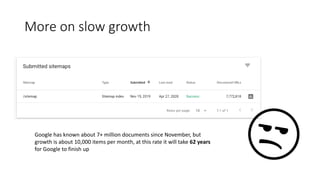
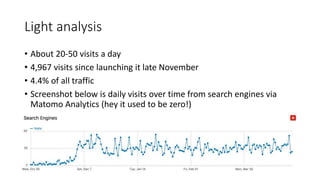



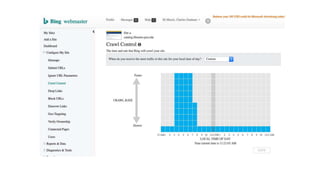



This document discusses the implementation of dynamic sitemaps for the Penn State University Libraries Blacklight catalog (BlackCat) in order to allow search engines like Google to index the catalog's over 7.5 million records. It describes generating a unique signature hash for each record, querying Solr for "signature starts with" values to create dynamic sitemap pages, and updating the robots.txt file. While Google is aware of all the records, indexing has been slow. Lessons learned include Google's mysterious indexing processes, problems with high traffic from Bing that required throttling, and the overall slow growth of search engine indexing for such a large dynamic repository.


























































