Download to read offline




















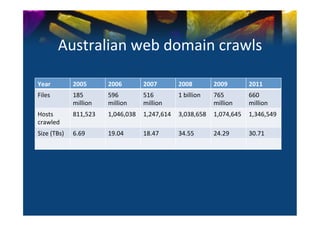
























This document provides an overview of existing web archives and their use for research. It discusses several major web archives including the Internet Archive, Common Crawl, Pandora Archive, and national archives. For each, it describes their size and collection strategies, as well as positives and negatives for research use. The talk concludes with examples of how existing web archives in Australia are being used for research.





































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)





