Download as PDF, PPTX



































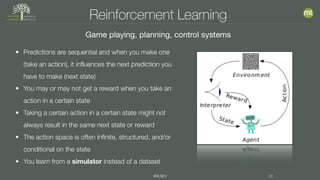




This document discusses the foundations of machine learning, including the differences between supervised and unsupervised learning. It emphasizes the importance of data preparation, feature engineering, and the selection of appropriate algorithms based on the nature of the problem and data available. Additionally, it explores various applications and considerations for implementing machine learning effectively.























































































