Download to read offline




















![Data Preparation
Industrial Datasets:
• The Cisco dataset is a test suite used for testing video-conferencing systems, provided by Cisco
Systems.
• The other two industrial datasets are used for testing industrial robotics applications provided by
ABB Robotics (Paint Control and Input/Output Control, noted as IOF/ROL)
Synthetic Datasets (Data Augmentation):
• The ratio of failed test executions is extremely low in industrial dataset
• To address the problem of insufficient representation of relevant test cases in the industrial
datasets, [4] performed data augmentation. Specifically, uses SMOGN which is a technique for
tackling imbalanced regression datasets by generating diverse new data points for the given data.
• The synthetic data generated was concatenated to the industrial datasets
• We have used this concatenated dataset from [4] for our use case](https://image.slidesharecdn.com/session10vivekpatleandjahnaviumarji-231220080408-1a6ecbad/75/Interactive-Session-by-Vivek-Patle-and-Jahnavi-Umarji-Empowering-Functional-Testing-with-Support-Vector-Machines-An-Experimental-Journey-at-ATAGTR2023-29-2048.jpg)



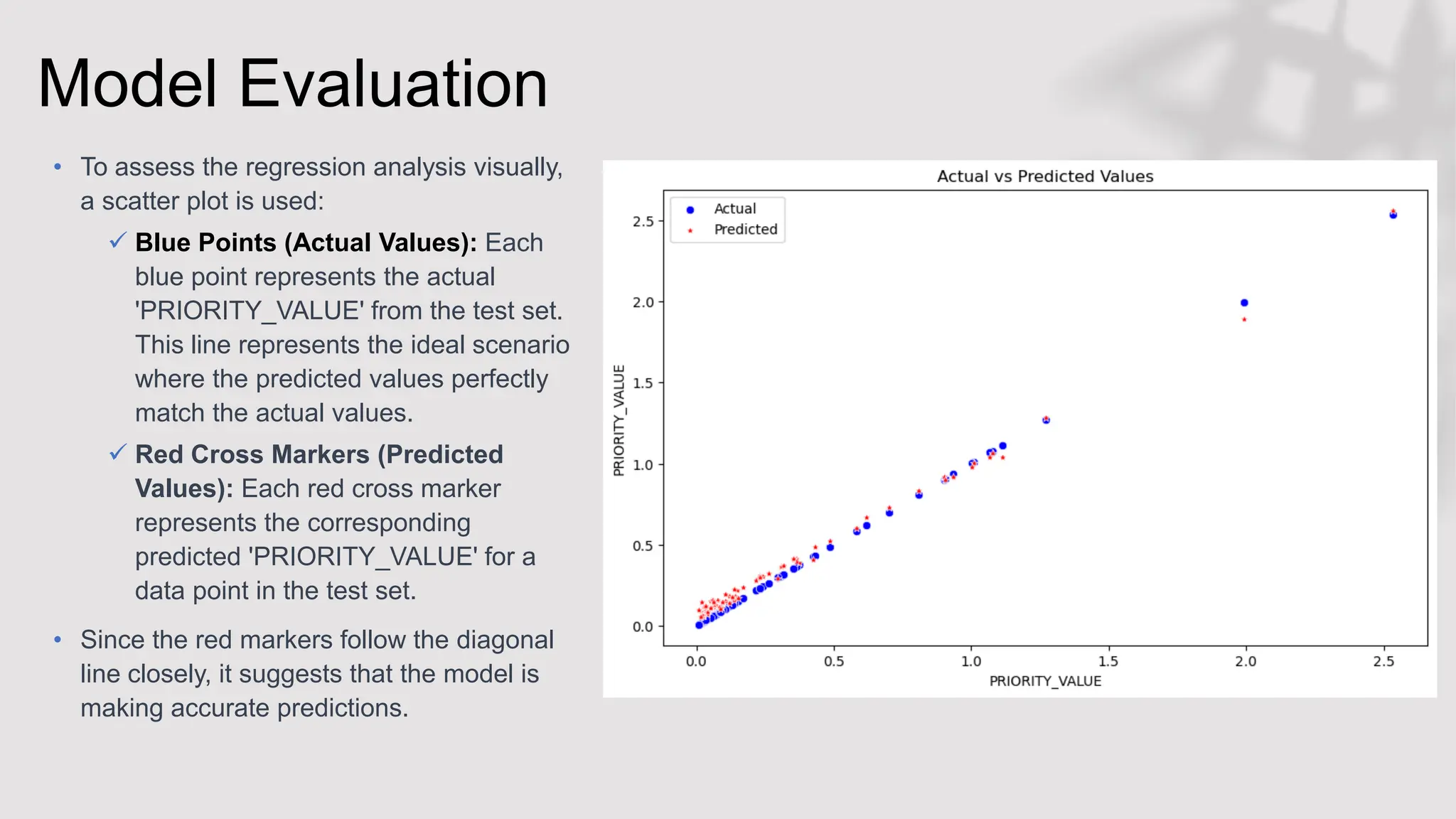



















This document discusses the application of Support Vector Machines (SVMs) in functional testing, particularly focusing on test case prioritization and defect prediction. It outlines the challenges in functional testing and describes how SVMs can optimize testing processes by using historical data to predict defects and prioritize test cases. Additionally, it covers the methodology for training SVM models, evaluates model performance through metrics like accuracy and precision, and highlights insights from the experimental results.
















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)


















