Downloaded 19 times










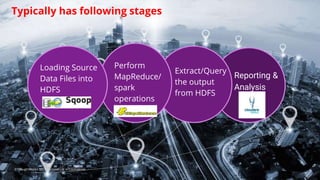



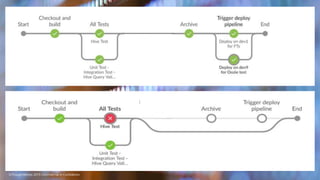




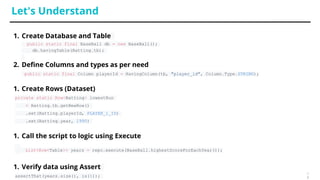





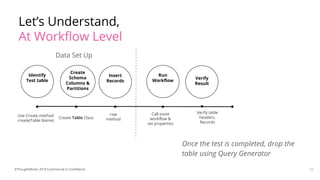






This document discusses testing of big data applications. It describes various types of tests including unit tests, integration tests, functional tests and tests of workflows like Oozie tests. It also discusses automation tools and frameworks for testing like Mockito, Worker Bee and Cucumber. Challenges in big data testing mentioned include long test run times, need for dedicated test clusters and maintaining large test data sets.








![[Webinar] Automating Developer Workspace Construction for the Nuxeo Platform ...](https://cdn.slidesharecdn.com/ss_thumbnails/nuxeo-codenvywebinar-26-jan-2015-150205140757-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)














































































