This document provides an overview of a VLDB 2009 tutorial on column-oriented database systems. The tutorial will consist of three parts:
Part 1 will provide an introduction to column-oriented databases, including their key features, performance tradeoffs compared to row-oriented databases, and architecture.
Part 2 will focus on column-oriented query execution techniques.
Part 3 will discuss optimizations in the MonetDB/X100 column-store for improving CPU efficiency when operating on columns.











![Re-use permitted when acknowledging the original © Stavros Harizopoulos, Daniel Abadi, Peter Boncz (2009)
From DSM to Column-stores
70s -1985:
TOD: Time Oriented Database – Wiederhold et al.
"A Modular, Self-Describing Clinical Databank
System," Computers and Biomedical Research, 1975
More 1970s: Transposed files, Lorie, Batory,
Svensson.
“An overview of cantor: a new system for data analysis”
Karasalo, Svensson, SSDBM 1983
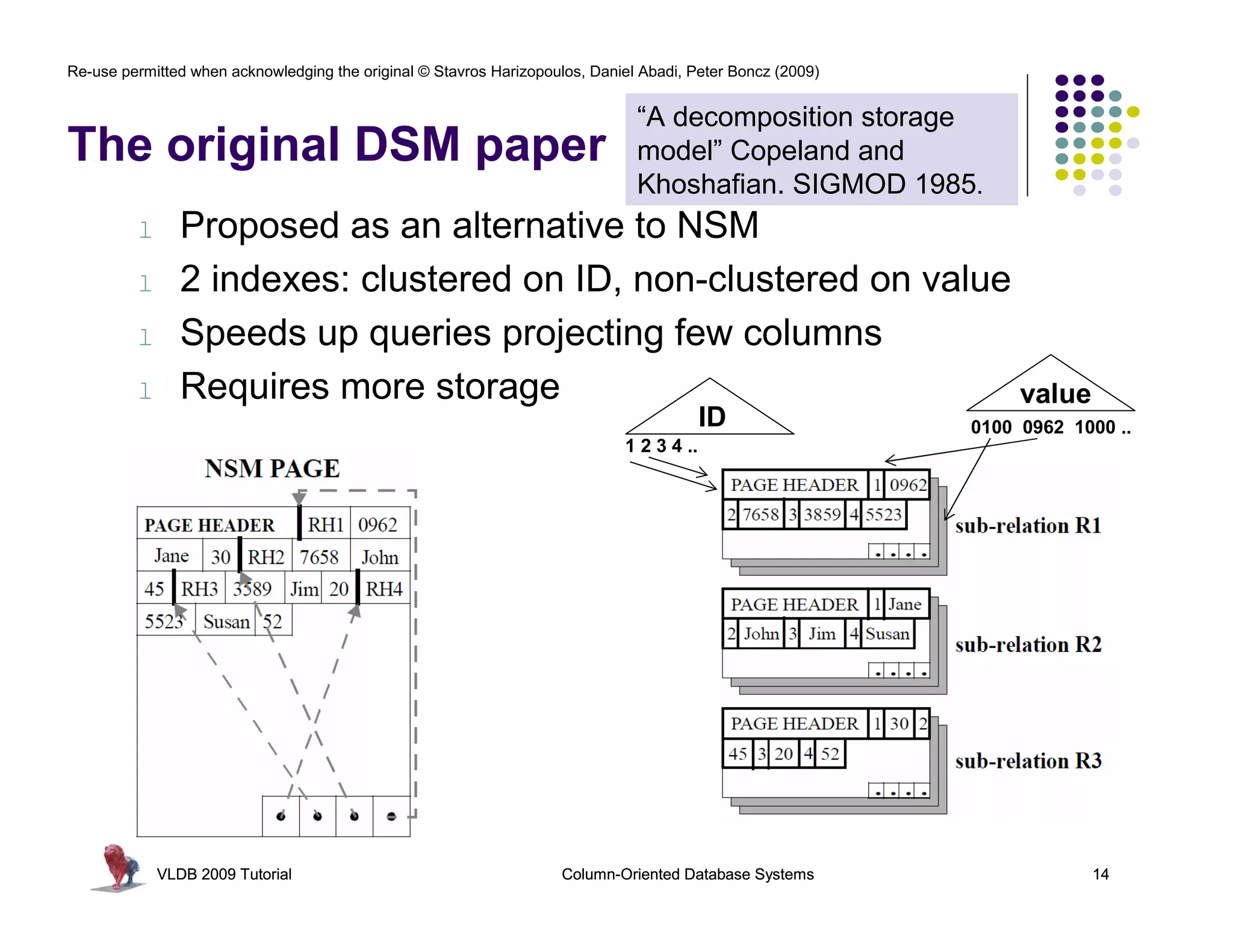
1985: DSM paper
“A decomposition storage model”
Copeland and Khoshafian. SIGMOD 1985.
1990s: Commercialization through SybaseIQ
Late 90s – 2000s: Focus on main-memory performance
l DSM “on steroids” [1997 – now]
l Hybrid DSM/NSM [2001 – 2004]
CWI: MonetDB
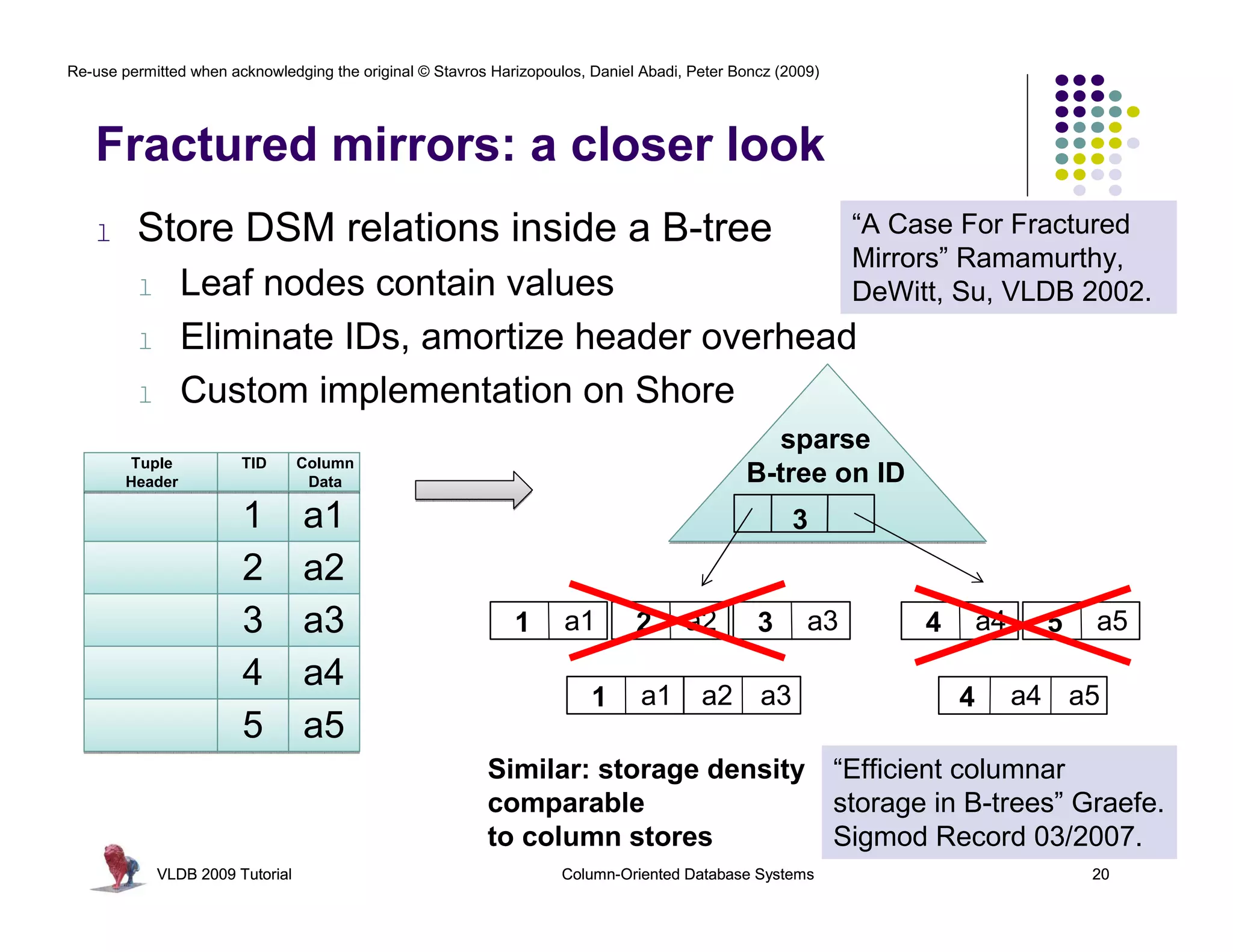
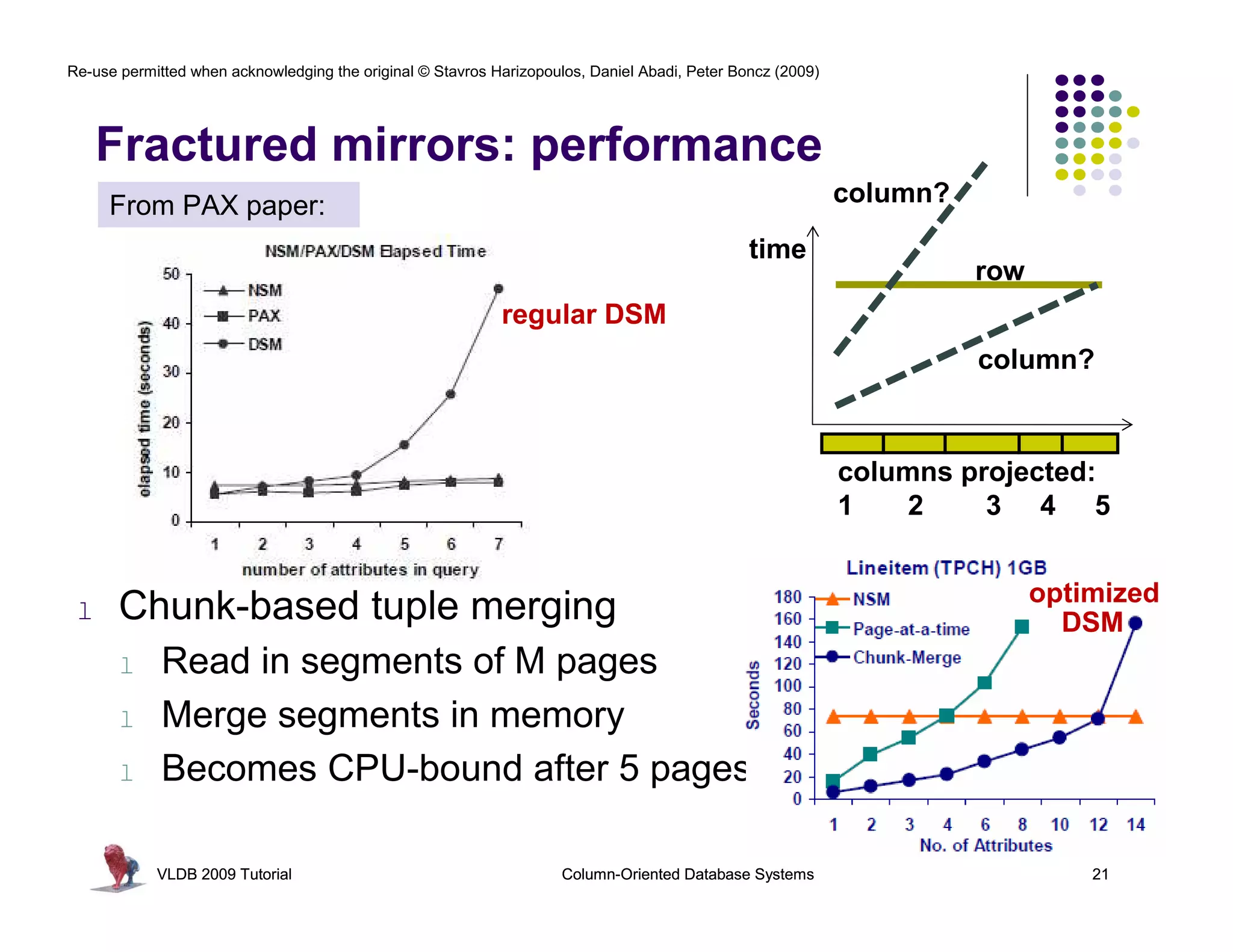
Wisconsin: PAX, Fractured Mirrors
Michigan: Data Morphing CMU: Clotho
2005 – : Re-birth of read-optimized DSM as “column-store”
MIT: C-Store CWI: MonetDB/X100 10+ startups
VLDB 2009 Tutorial Column-Oriented Database Systems 13](https://image.slidesharecdn.com/databasesystem-140901161805-phpapp01/75/Database-system-13-2048.jpg)






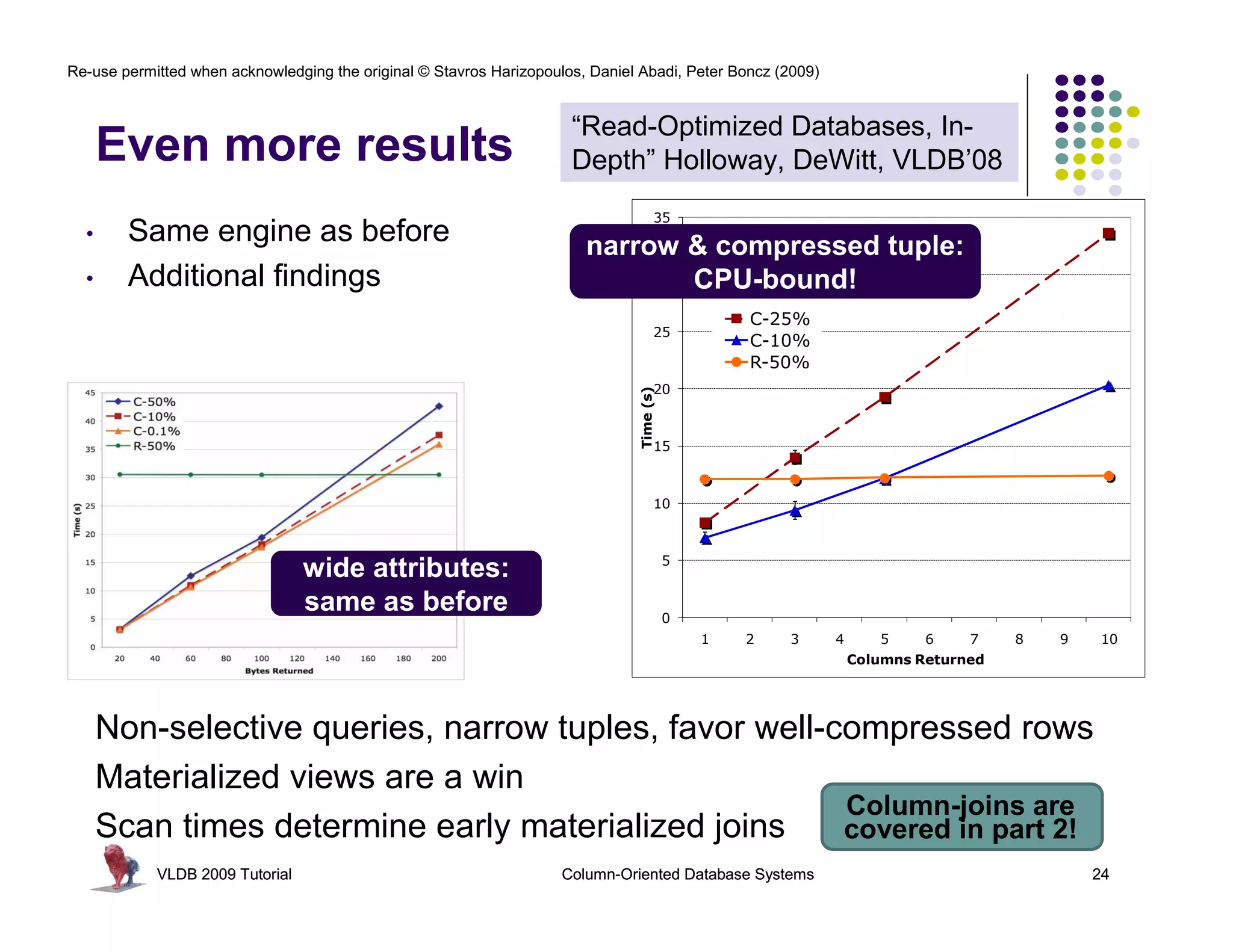
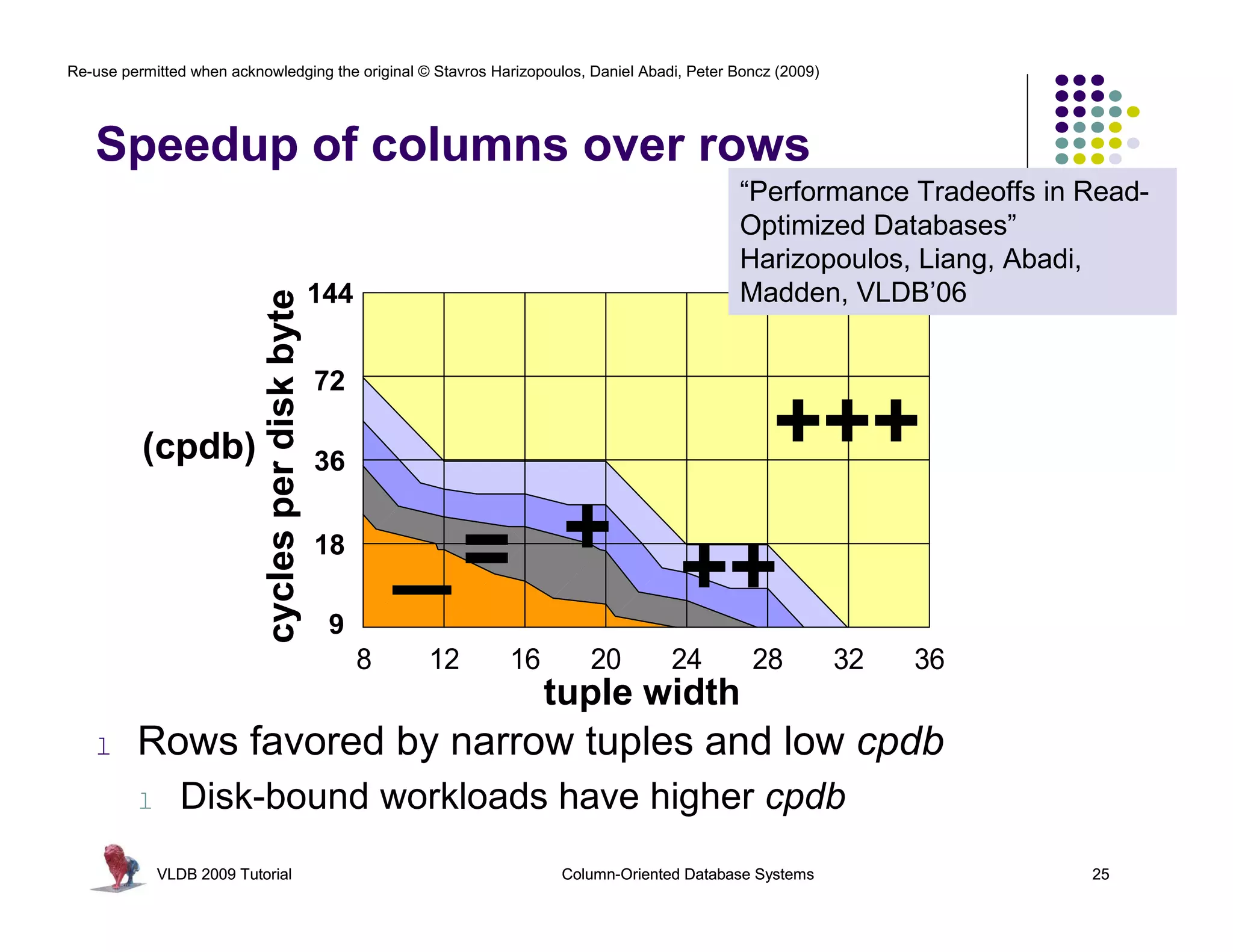

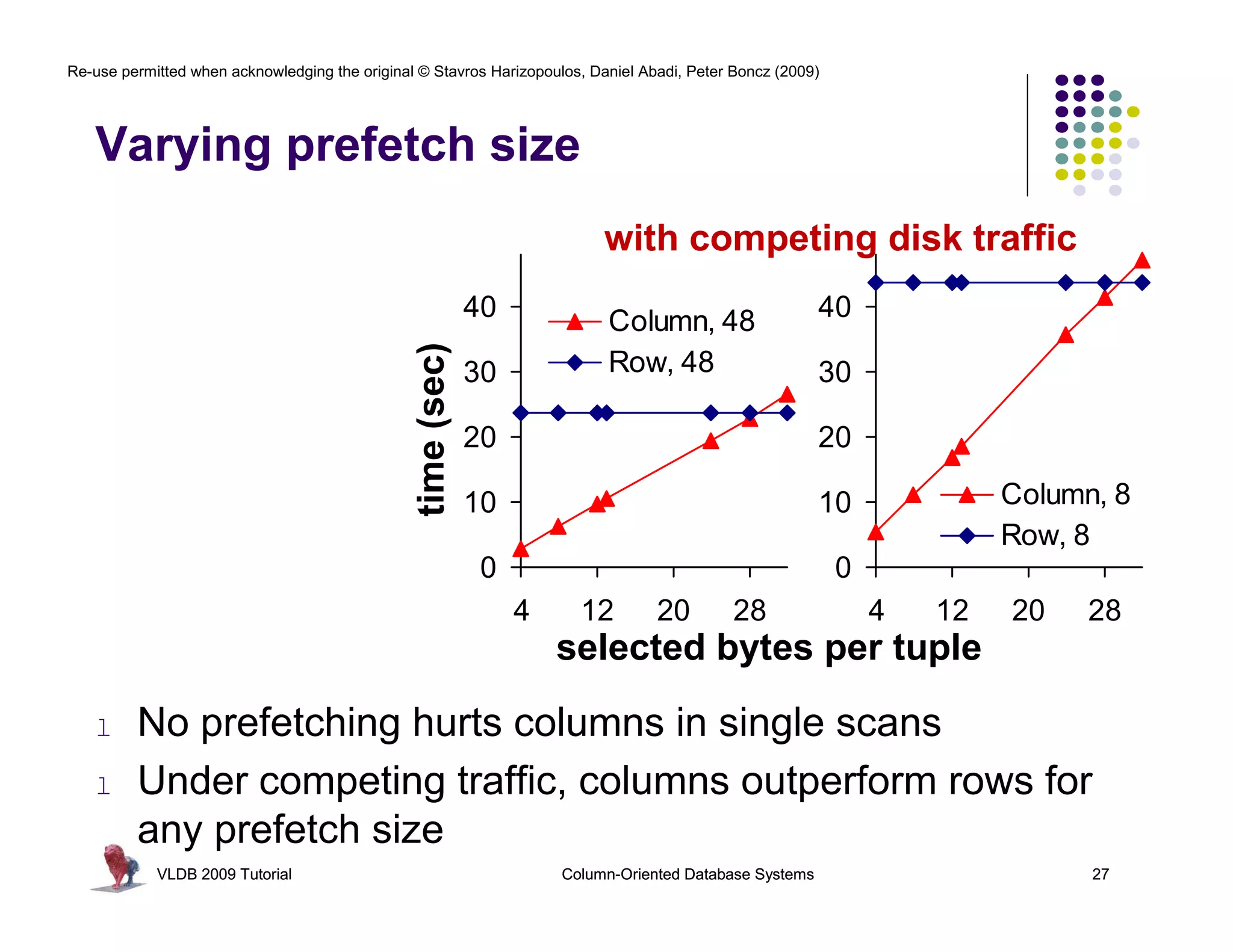
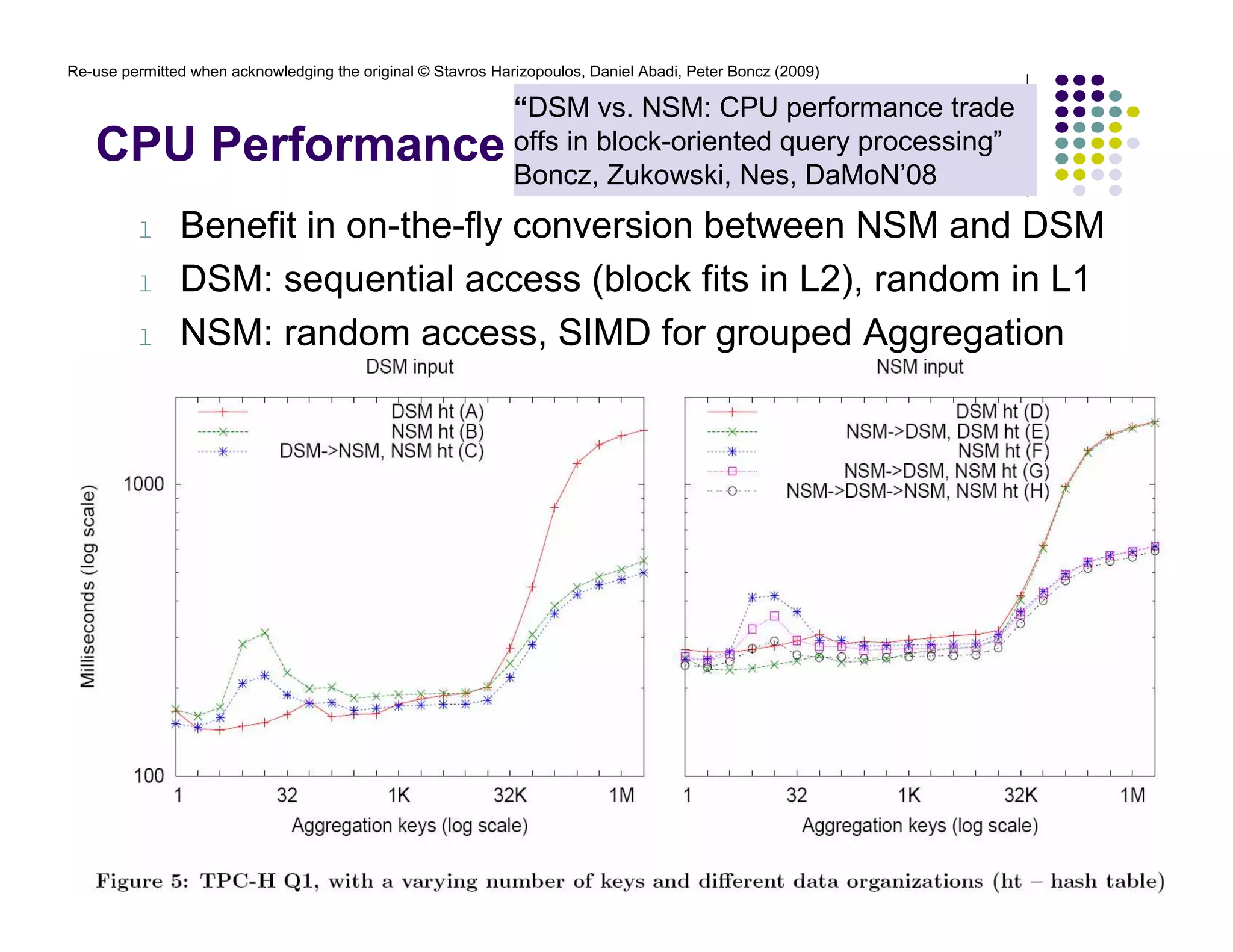

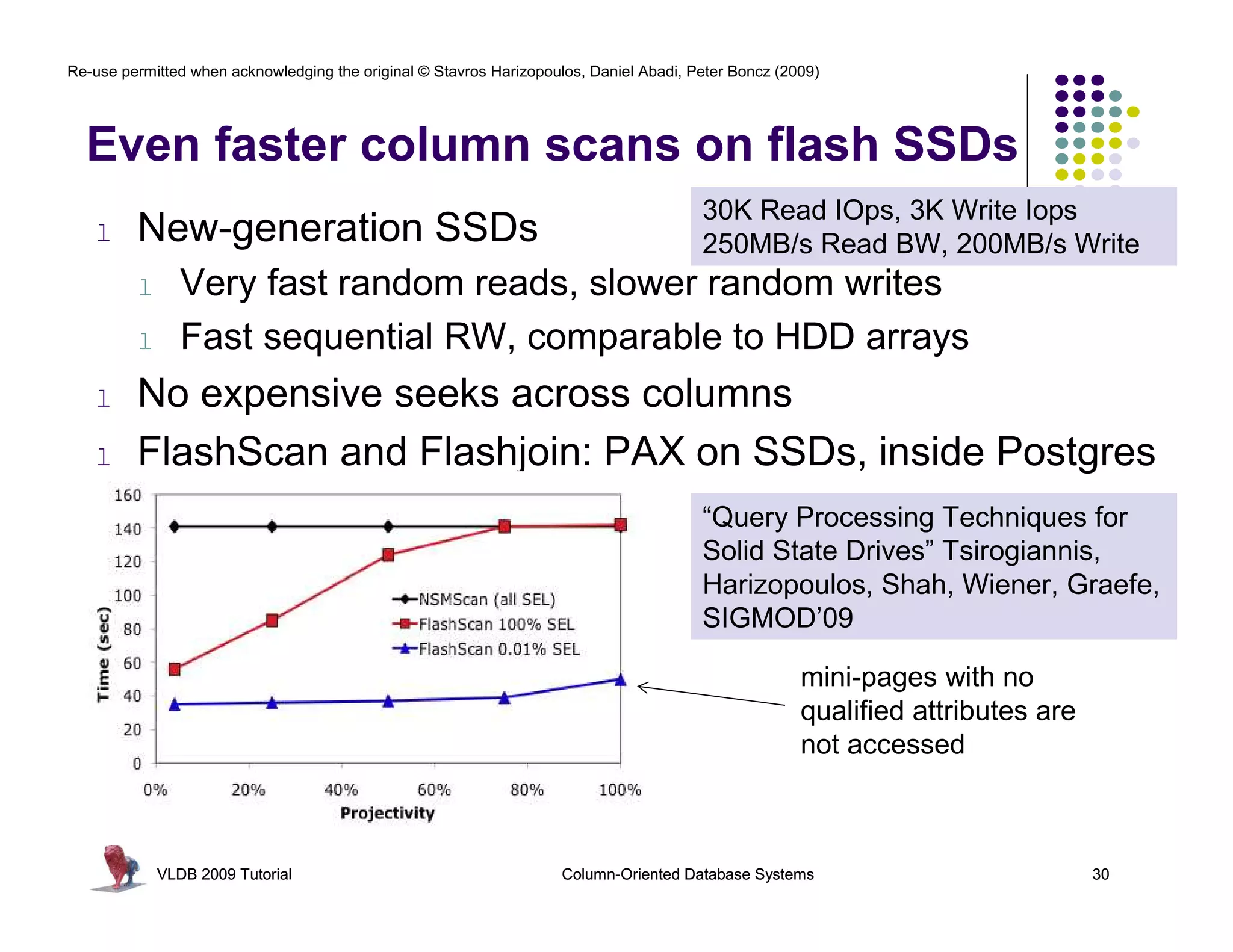
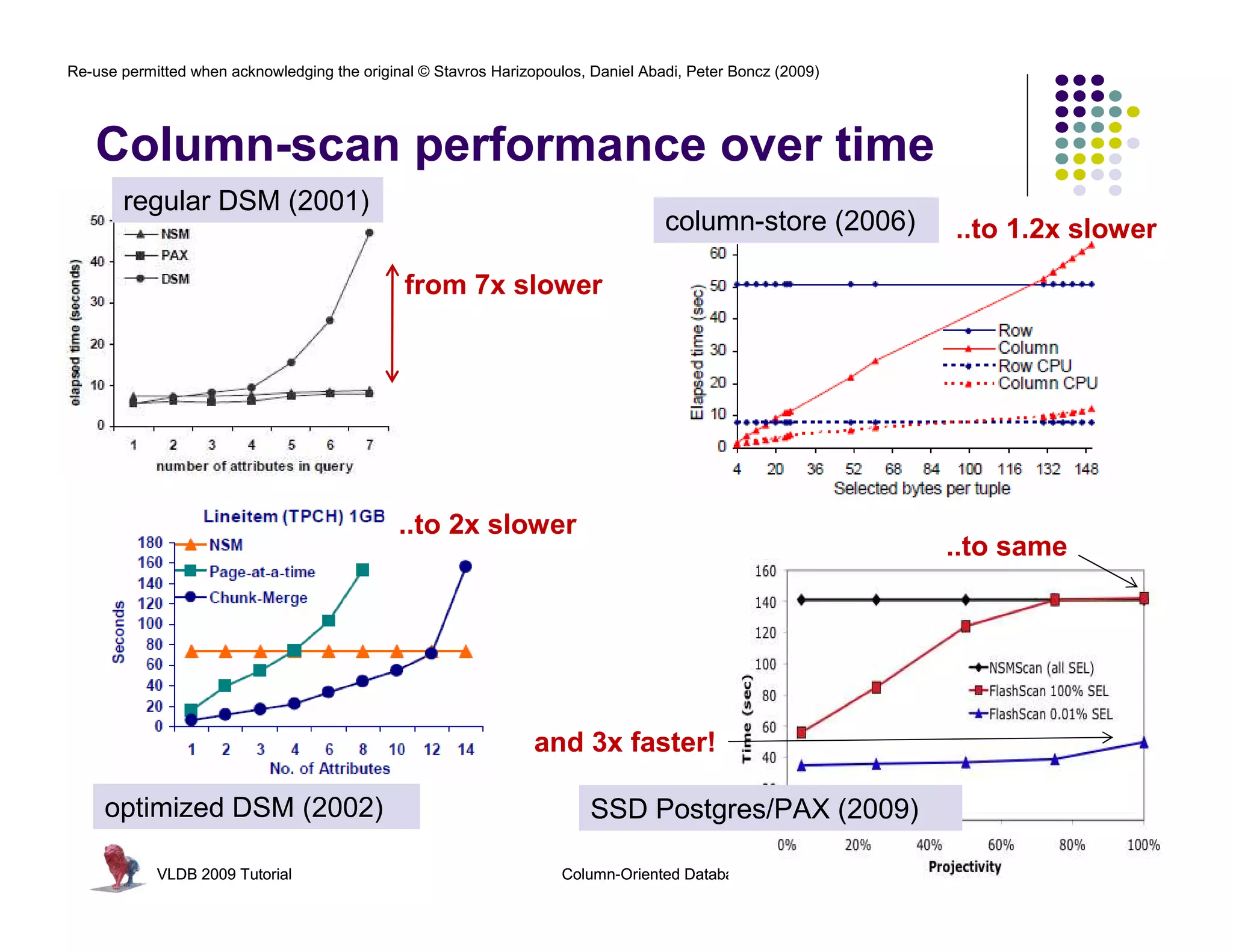

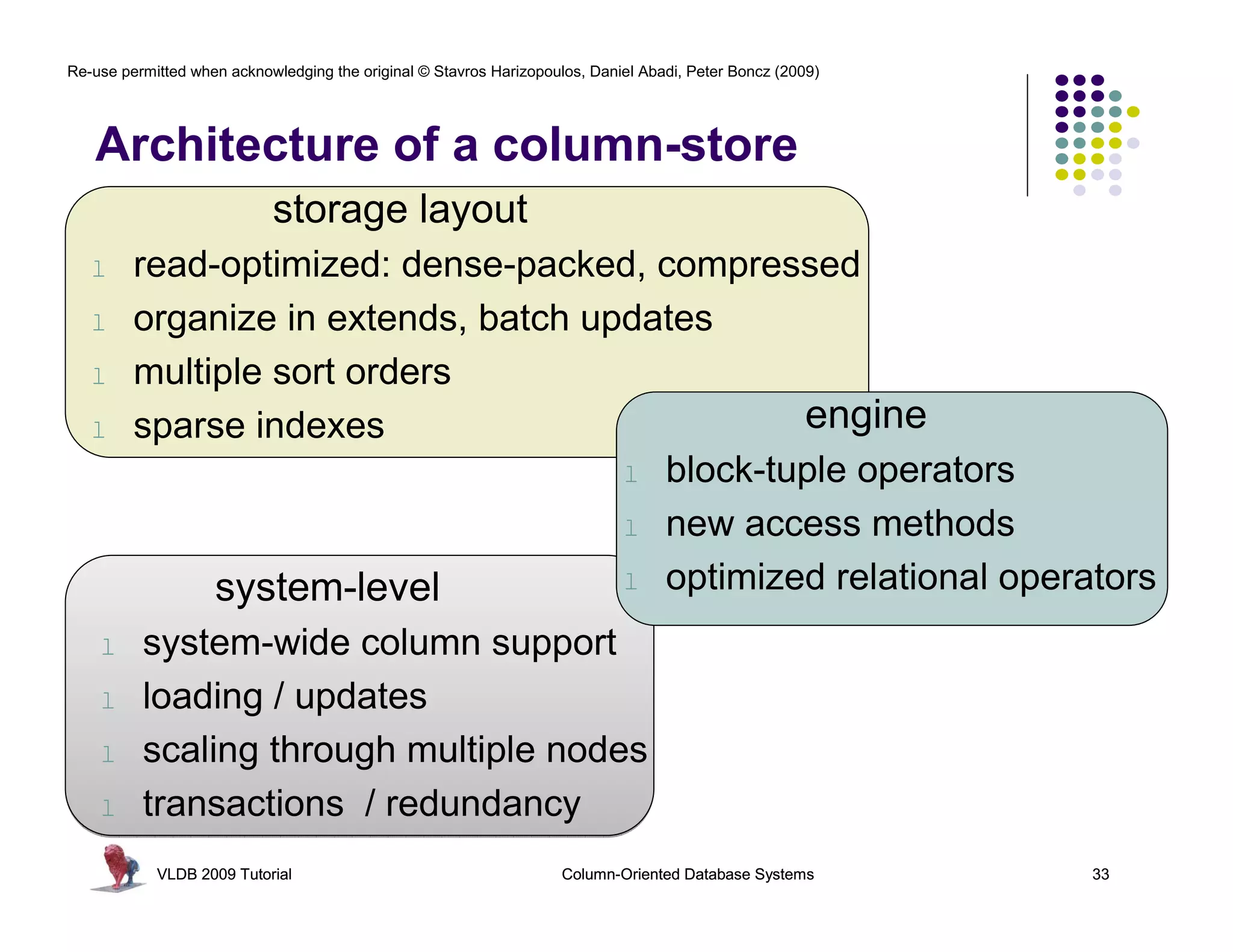


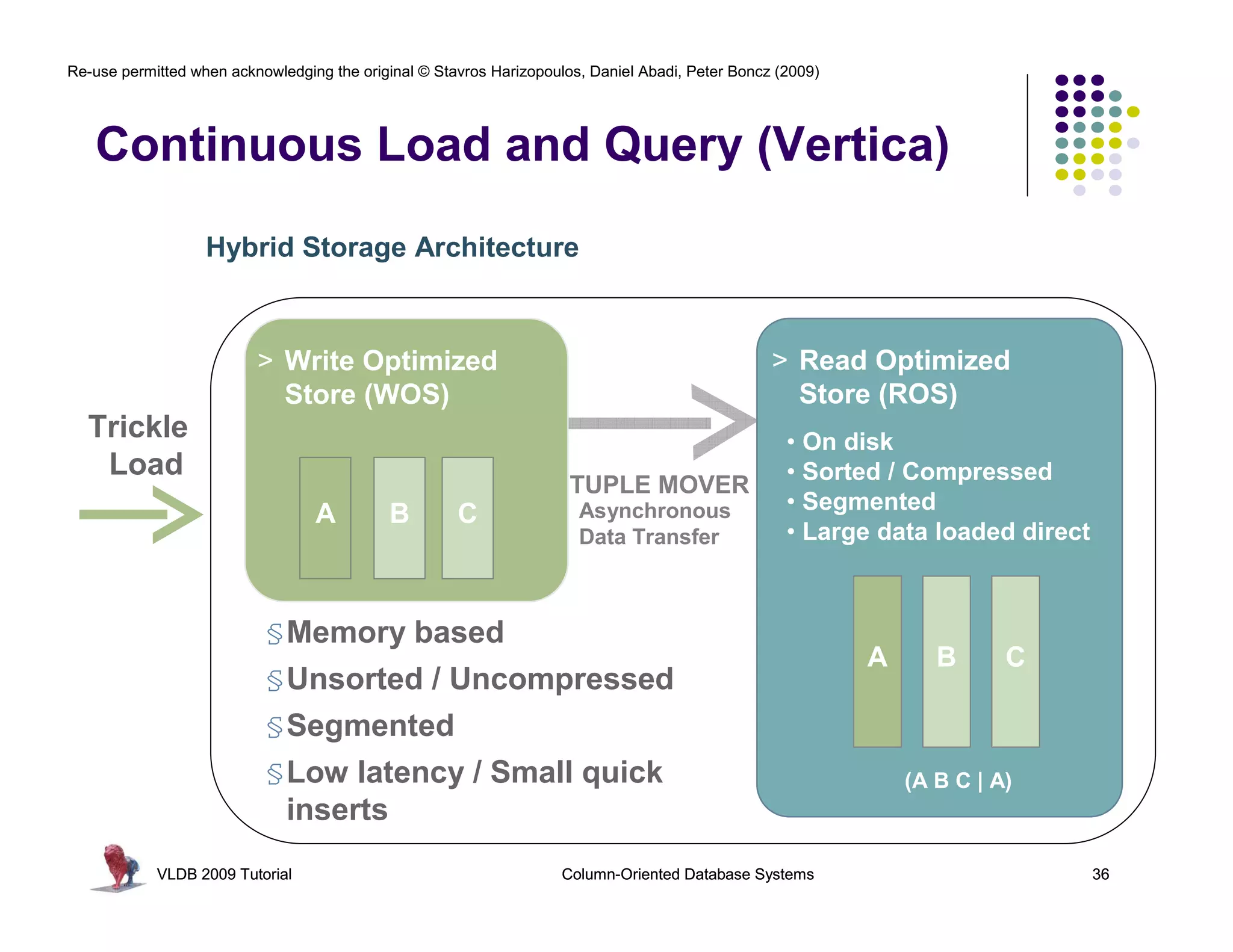











![Re-use permitted when acknowledging the original © Stavros Harizopoulos, Daniel Abadi, Peter Boncz (2009)
Bit-vector Encoding
“Integrating Compression and Execution in Column-
Oriented Database Systems” Abadi et. al, SIGMOD ’06
Product ID
1
1
1
1
1
2
2
…
1
1
2
3
…
ID: 1 ID: 2 ID: 3
1
1
1
1
1
0
0
…
1
1
0
0
…
…
0
0
0
0
0
0
0
…
0
0
0
0
…
0
0
0
0
0
0
0
…
0
0
0
1
…
0
0
0
0
0
1
1
…
0
0
1
0
…
l For each unique
value, v, in column
c, create bit-vector
b
l b[i] = 1 if c[i] = v
l Good for columns
with few unique
values
l Each bit-vector
can be further
compressed if
sparse
VLDB 2009 Tutorial Column-Oriented Database Systems 52](https://image.slidesharecdn.com/databasesystem-140901161805-phpapp01/75/Database-system-52-2048.jpg)

















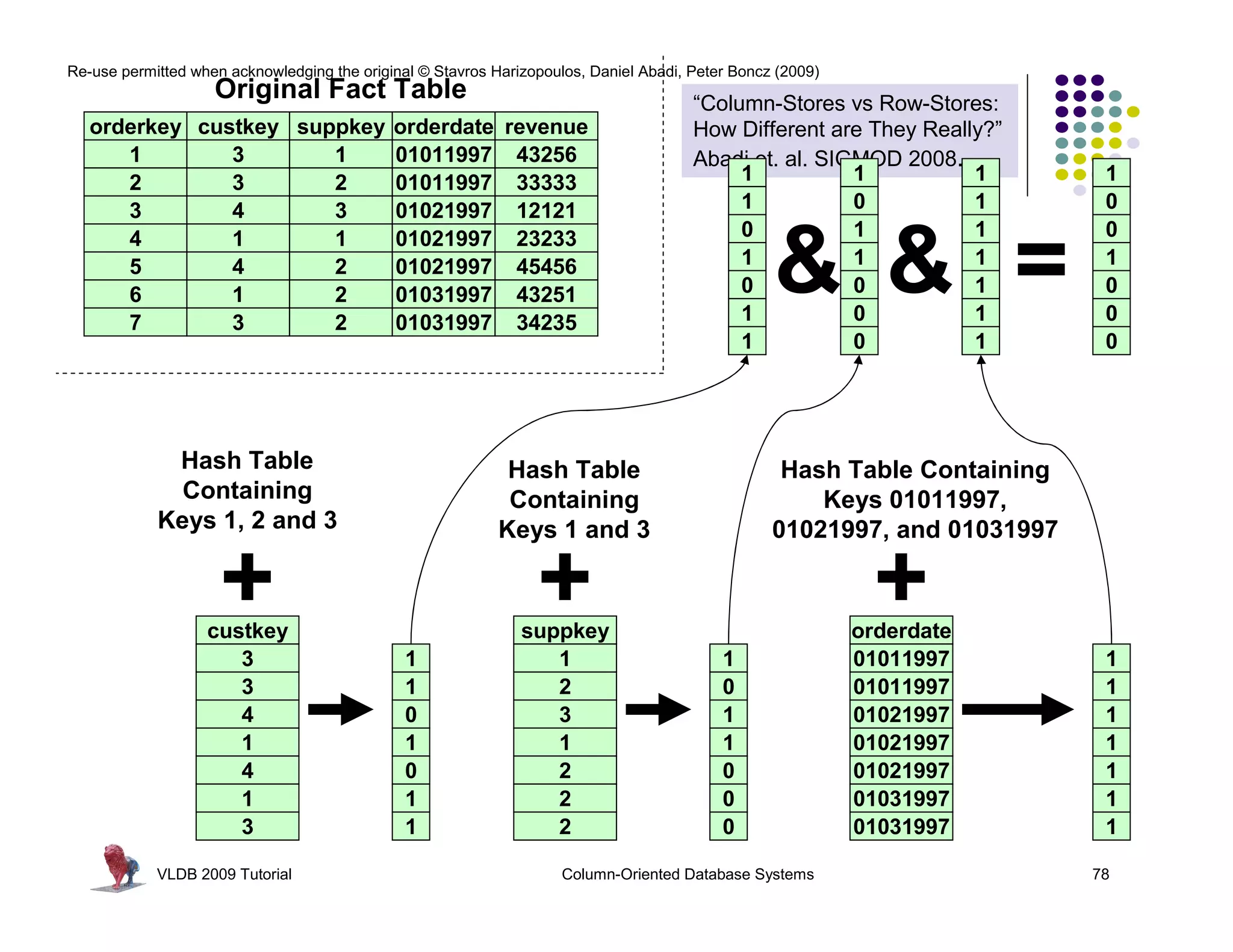
![Re-use permitted when acknowledging the original © Stavros Harizopoulos, Daniel Abadi, Peter Boncz (2009)
Invisible Join
“Column-Stores vs Row-Stores: How
Different are They Really?” Abadi,
Madden, and Hachem. SIGMOD 2008.
Apply “region = ‘Asia’” On Customer Table
custkey region nation …
1 ASIA CHINA …
2 ASIA INDIA …
3 ASIA INDIA …
Hash Table (or bit-map)
Containing Keys 1, 2 and 3
4 EUROPE FRANCE …
Apply “region = ‘Asia’” On Supplier Table
suppkey region nation …
1 ASIA RUSSIA …
2 EUROPE SPAIN …
Hash Table (or bit-map)
Containing Keys 1, 3
3 ASIA JAPAN …
Apply “year in [1992,1997]” On Date Table
dateid year …
01011997 1997 …
01021997 1997 …
01031997 1997 …
Hash Table Containing
Keys 01011997, 01021997,
and 01031997
VLDB 2009 Tutorial Column-Oriented Database Systems 77](https://image.slidesharecdn.com/databasesystem-140901161805-phpapp01/75/Database-system-77-2048.jpg)
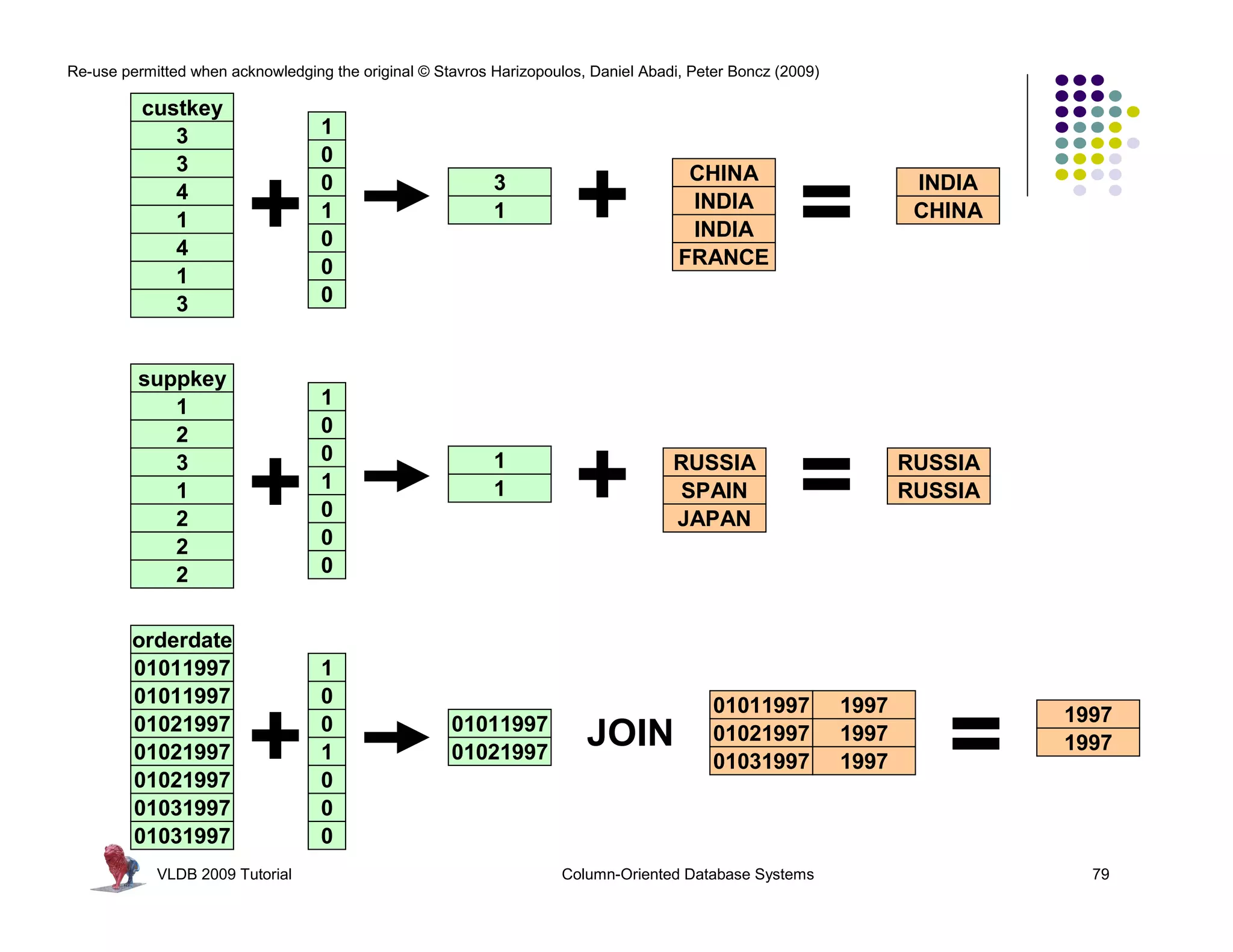
![Re-use permitted when acknowledging the original © Stavros Harizopoulos, Daniel Abadi, Peter Boncz (2009)
Invisible Join
“Column-Stores vs Row-Stores: How
Different are They Really?” Abadi,
Madden, and Hachem. SIGMOD 2008.
Apply “region = ‘Asia’” On Customer Table
custkey region nation …
1 ASIA CHINA …
2 ASIA INDIA …
3 ASIA INDIA …
Hash Table (or bit-map)
Containing Keys 1, 2 and 3
4 EUROPE FRANCE …
Apply “region = ‘Asia’” On Supplier Table
suppkey region nation …
1 ASIA RUSSIA …
2 EUROPE SPAIN …
Range [1-3]
(between-predicate rewriting)
Hash Table (or bit-map)
Containing Keys 1, 3
3 ASIA JAPAN …
Apply “year in [1992,1997]” On Date Table
dateid year …
01011997 1997 …
01021997 1997 …
01031997 1997 …
Hash Table Containing
Keys 01011997, 01021997,
and 01031997
VLDB 2009 Tutorial Column-Oriented Database Systems 80](https://image.slidesharecdn.com/databasesystem-140901161805-phpapp01/75/Database-system-80-2048.jpg)













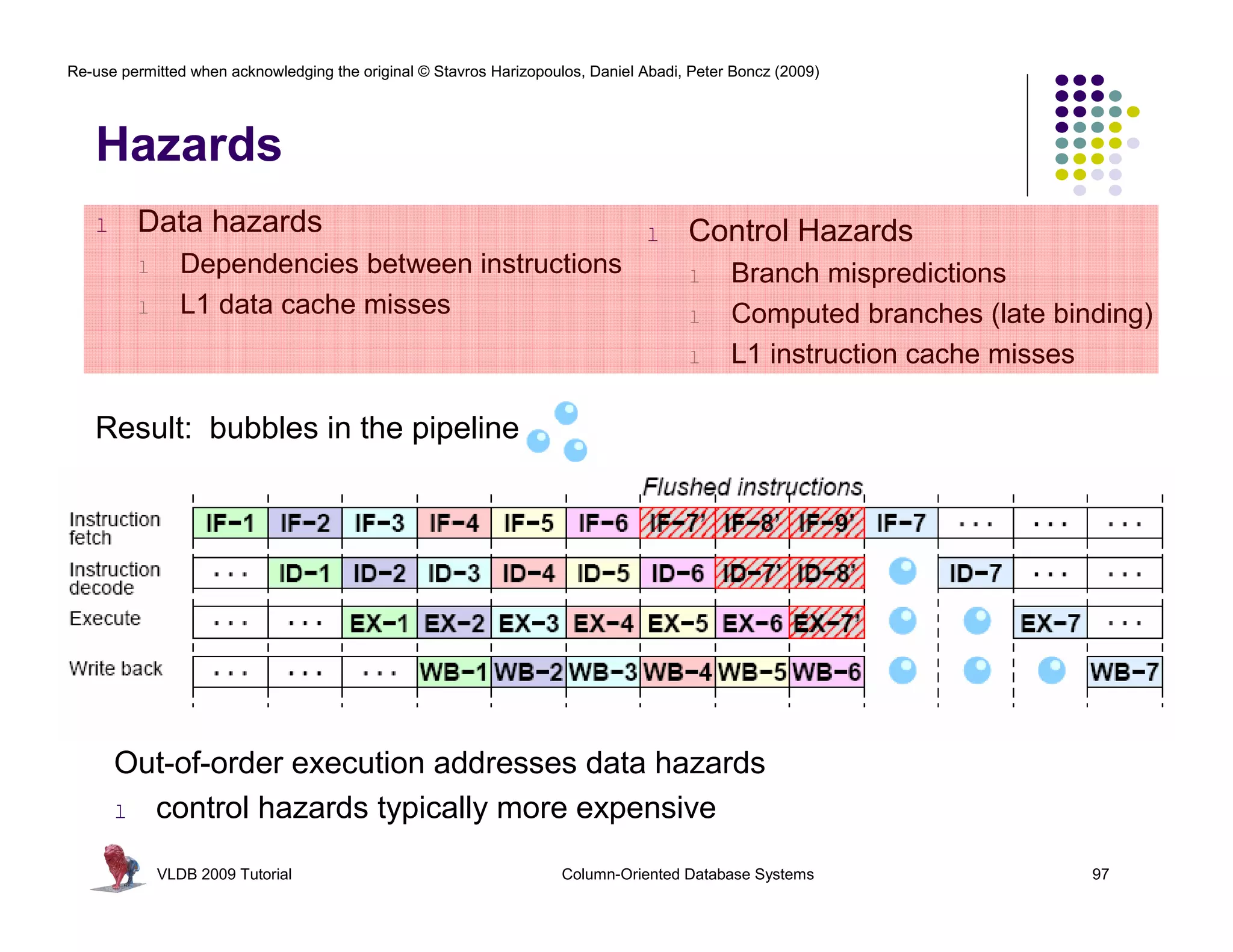








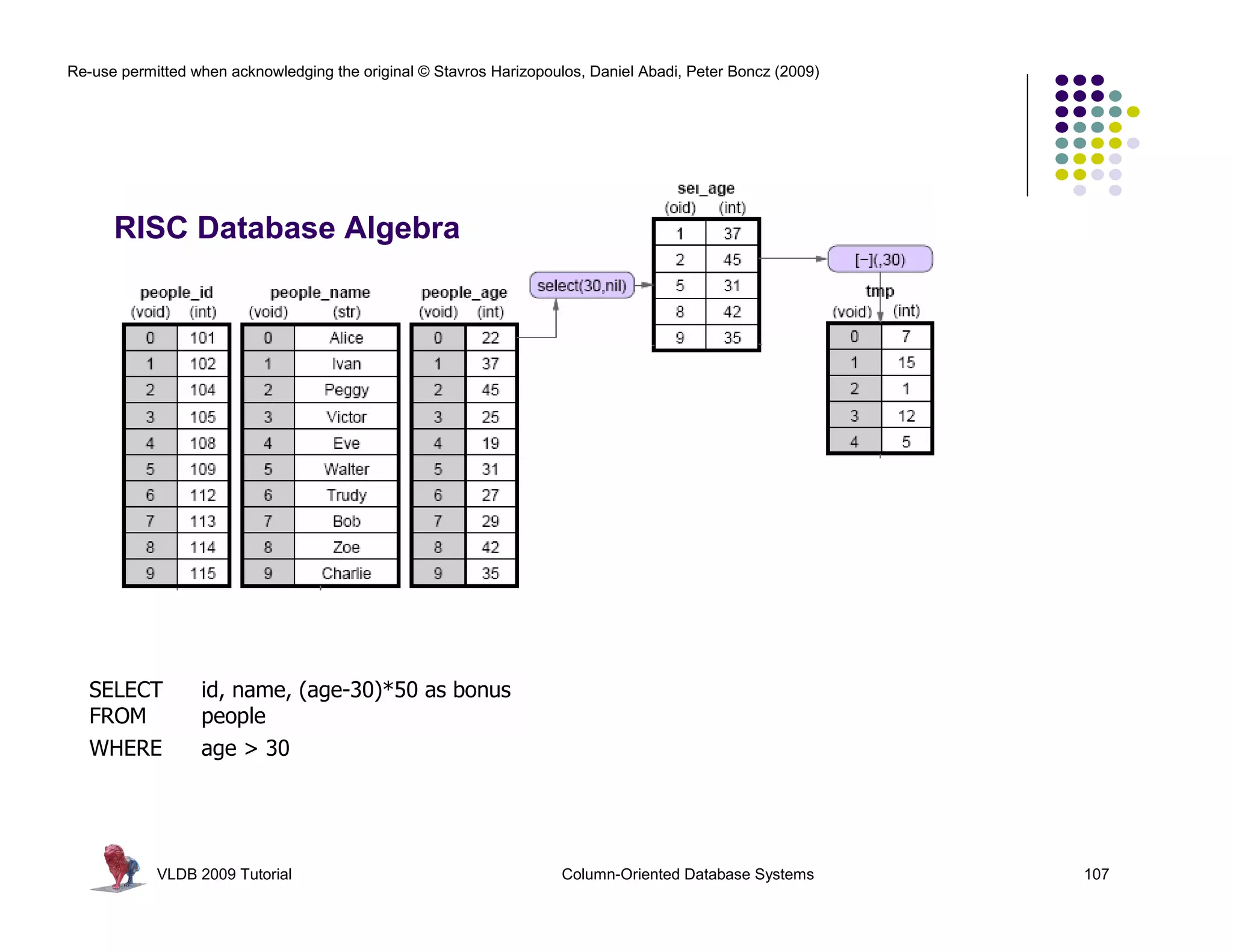
![Re-use permitted when acknowledging the original © Stavros Harizopoulos, Daniel Abadi, Peter Boncz (2009)
RISC Database Algebra
CPU happy? Give it “nice” code !
- few dependencies (control,data)
- CPU gets out-of-order execution
- compiler can e.g. generate SIMD
One loop for an entire column
- no per-tuple interpretation
- arrays: no record navigation
- better instruction cache locality
batcalc_minus_int(int* res,
int* col,
int val,
int n)
SELECT id, name, (age-30)*50 as bonus
FROM people
WHERE age > 30
VLDB 2009 Tutorial Column-Oriented Database Systems 108
{
for(i=0; i<n; i++)
res[i] = col[i] - val;
}
Simple, hard-coded
semantics
in operators](https://image.slidesharecdn.com/databasesystem-140901161805-phpapp01/75/Database-system-108-2048.jpg)
![Re-use permitted when acknowledging the original © Stavros Harizopoulos, Daniel Abadi, Peter Boncz (2009)
RISC Database Algebra
CPU happy? Give it “nice” code !
- few dependencies (control,data)
- CPU gets out-of-order execution
- compiler can e.g. generate SIMD
One loop for an entire column
- no per-tuple interpretation
- arrays: no record navigation
- better instruction cache locality
batcalc_minus_int(int* res,
int* col,
int val,
int n)
SELECT id, name, (age-30)*50 as bonus
FROM people
WHERE age > 30
VLDB 2009 Tutorial Column-Oriented Database Systems 109
{
for(i=0; i<n; i++)
res[i] = col[i] - val;
}
MATERIALIZED
intermediate
results](https://image.slidesharecdn.com/databasesystem-140901161805-phpapp01/75/Database-system-109-2048.jpg)







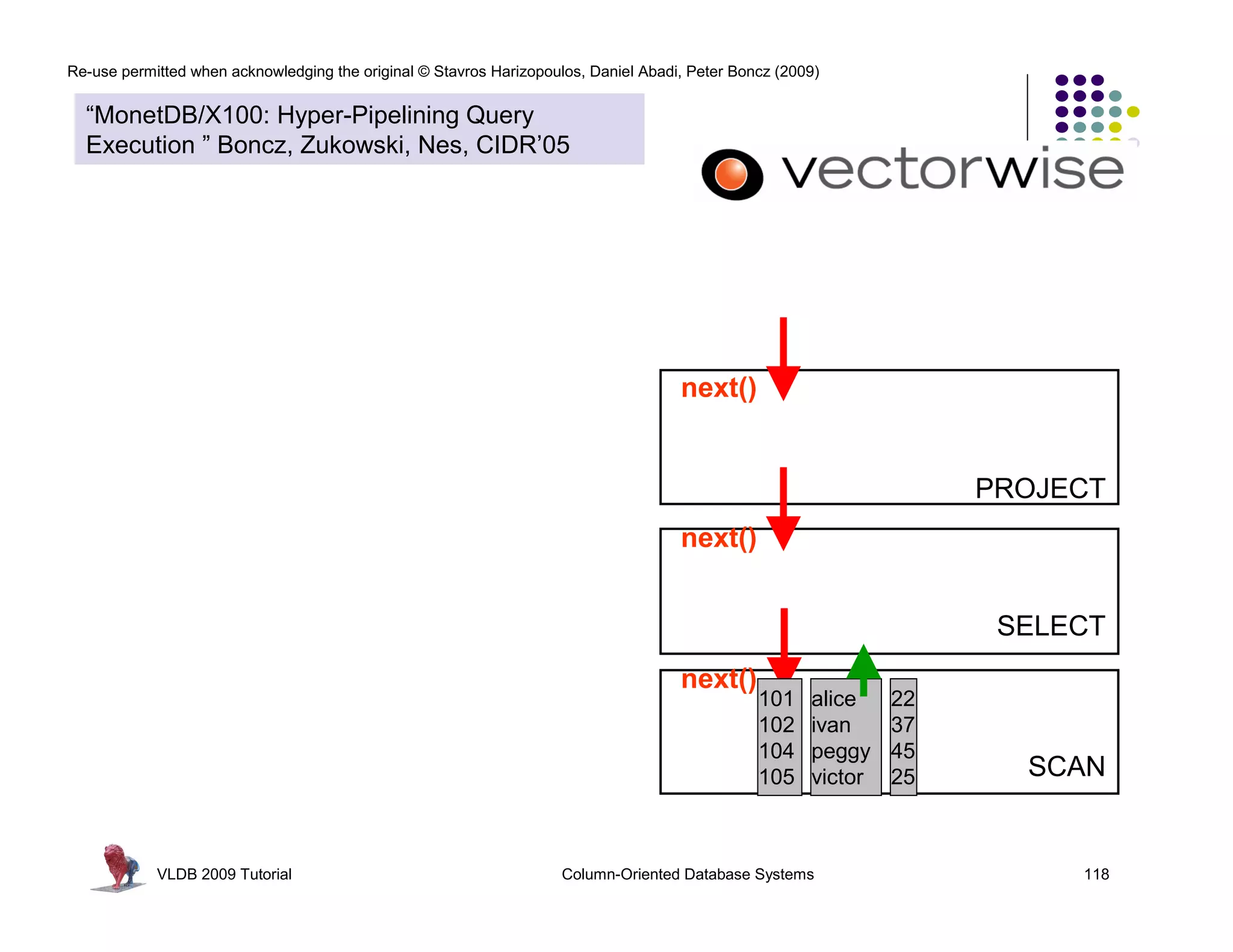
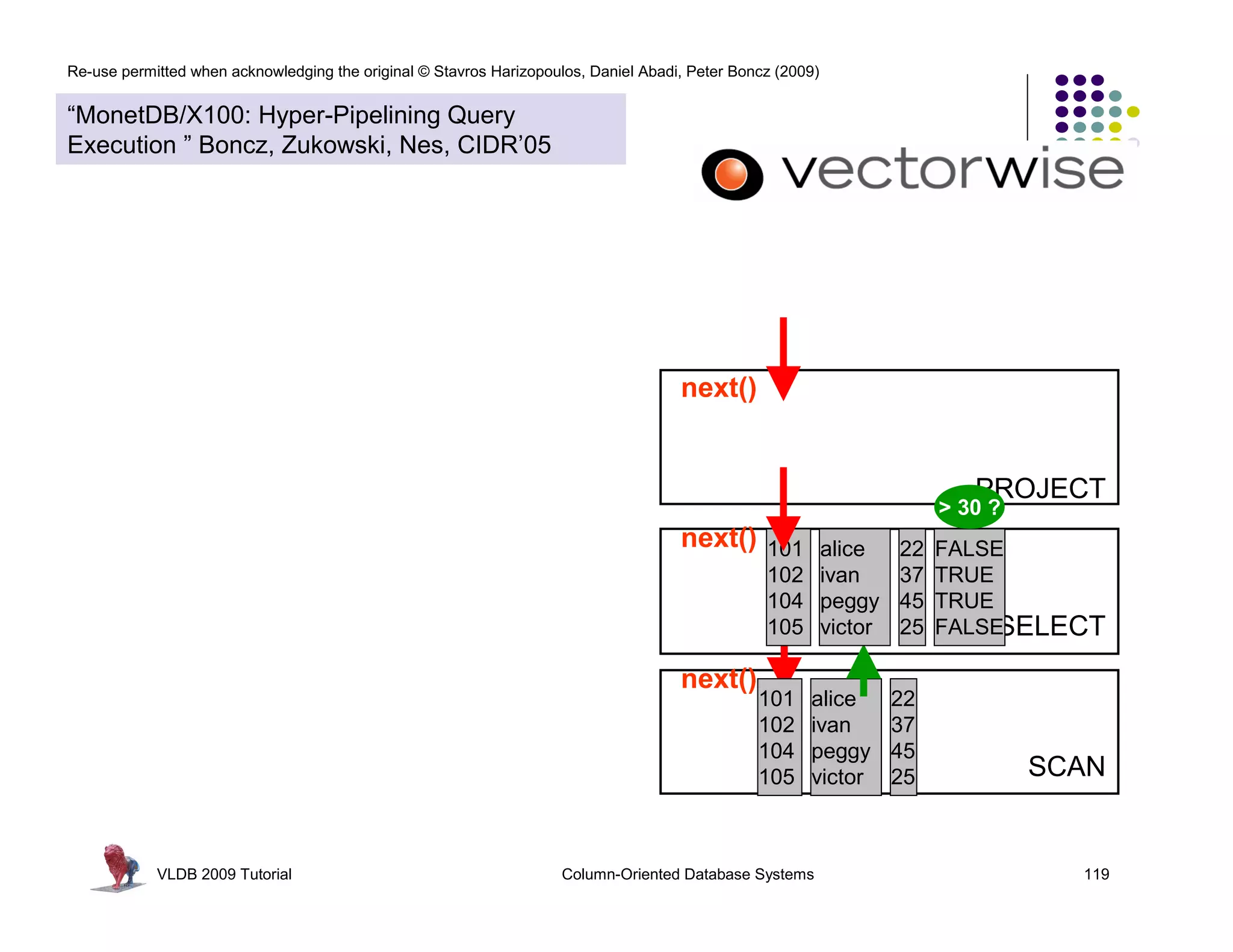
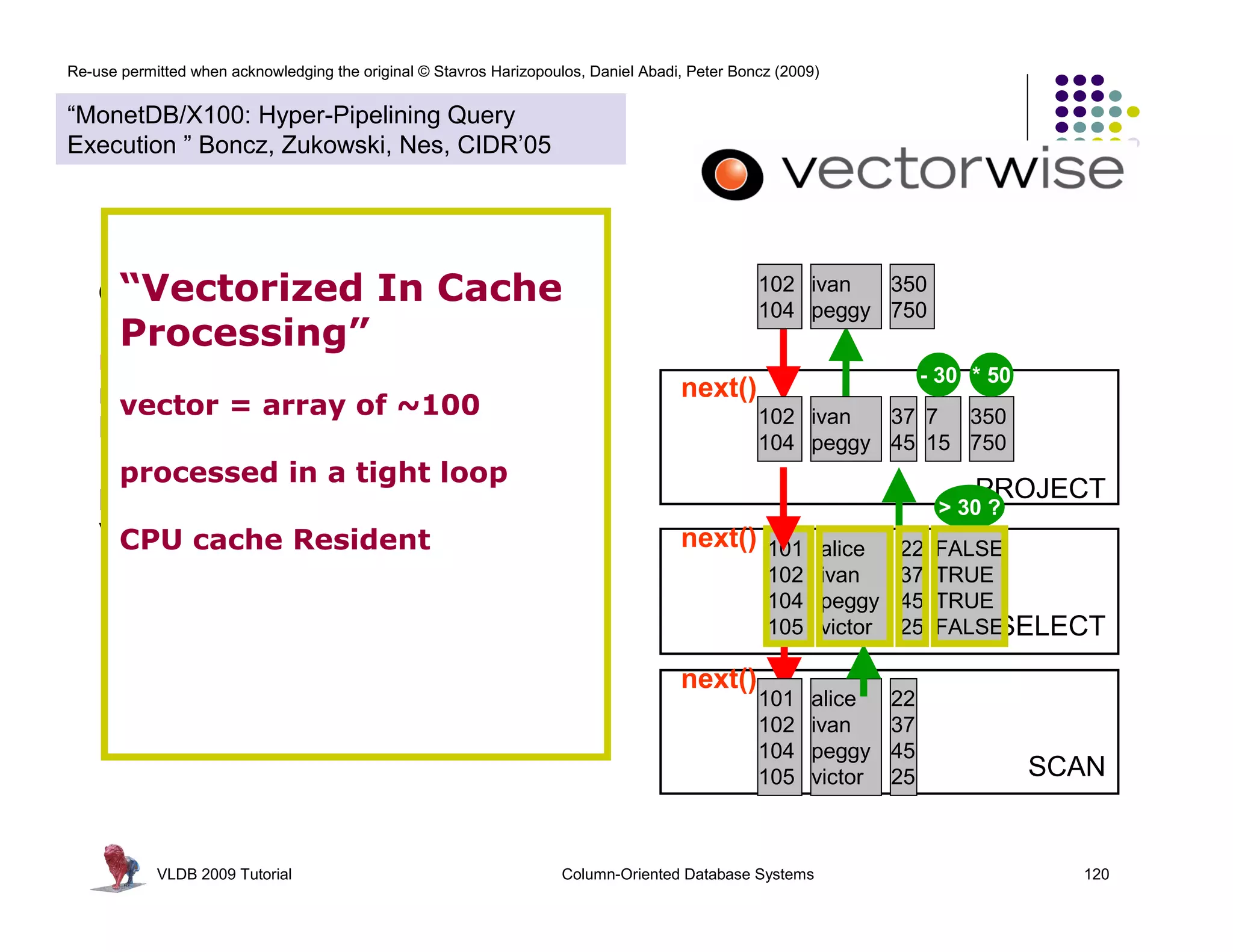
![Re-use permitted when acknowledging the original © Stavros Harizopoulos, Daniel Abadi, Peter Boncz (2009)
for(i=0; i<n; i++)
res[i] = (col[i] > x)
* 50
350
750
PROJECT
for(i=0; i<n; i++)
> 30 ?
FALSE
TRUE
TRUE
FALSE
res[i] = (col[i] - x)
SELECT
for(i=0; i<n; i++)
res[i] = (col[i] * x)
SCAN
“MonetDB/X100: Hyper-Pipelining Query
Execution ” Boncz, Zukowski, Nes, CIDR’05
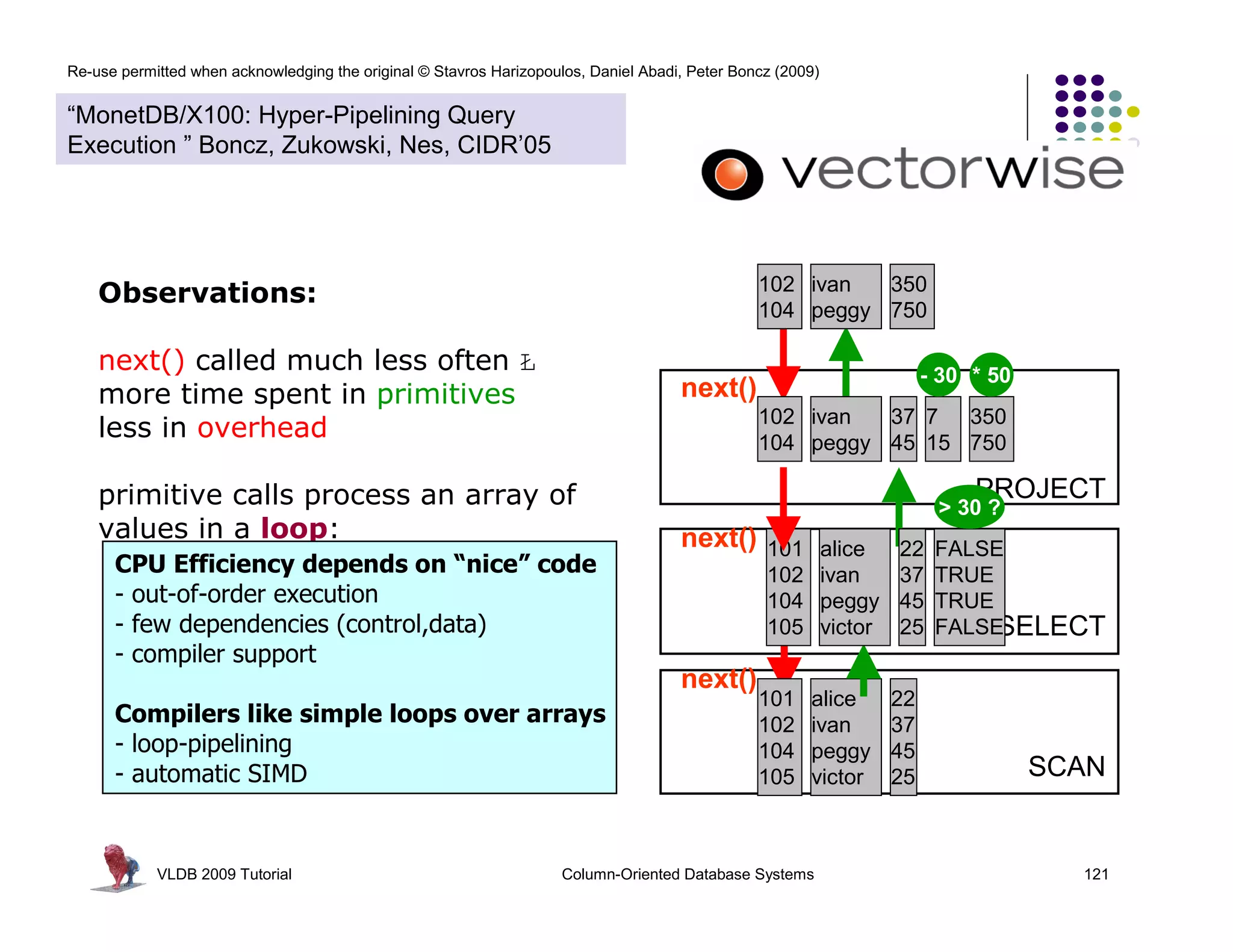
Observations:
next() called much less often Ł
more time spent in primitives
less in overhead
primitive calls process an array of
values in a loop:
CPU Efficiency depends on “nice” code
- out-of-order execution
- few dependencies (control,data)
- compiler support
Compilers like simple loops over arrays
- loop-pipelining
- automatic SIMD
> 30 ?
FALSE
TRUE
TRUE
FALSE
- 30
7
15
* 50
350
750
VLDB 2009 Tutorial Column-Oriented Database Systems 122](https://image.slidesharecdn.com/databasesystem-140901161805-phpapp01/75/Database-system-122-2048.jpg)
![Re-use permitted when acknowledging the original © Stavros Harizopoulos, Daniel Abadi, Peter Boncz (2009)
- 30 * 50
350
750
PROJECT
> 30 ?
SELECT
SCAN
next()
next()
next()
101
102
104
105
alice
ivan
peggy
victor
22
37
45
25
7
15
1
2
“MonetDB/X100: Hyper-Pipelining Query
Execution ” Boncz, Zukowski, Nes, CIDR’05
map_mul_flt_val_flt_col(
float *res,
int* sel,
float val,
float *col, int n)
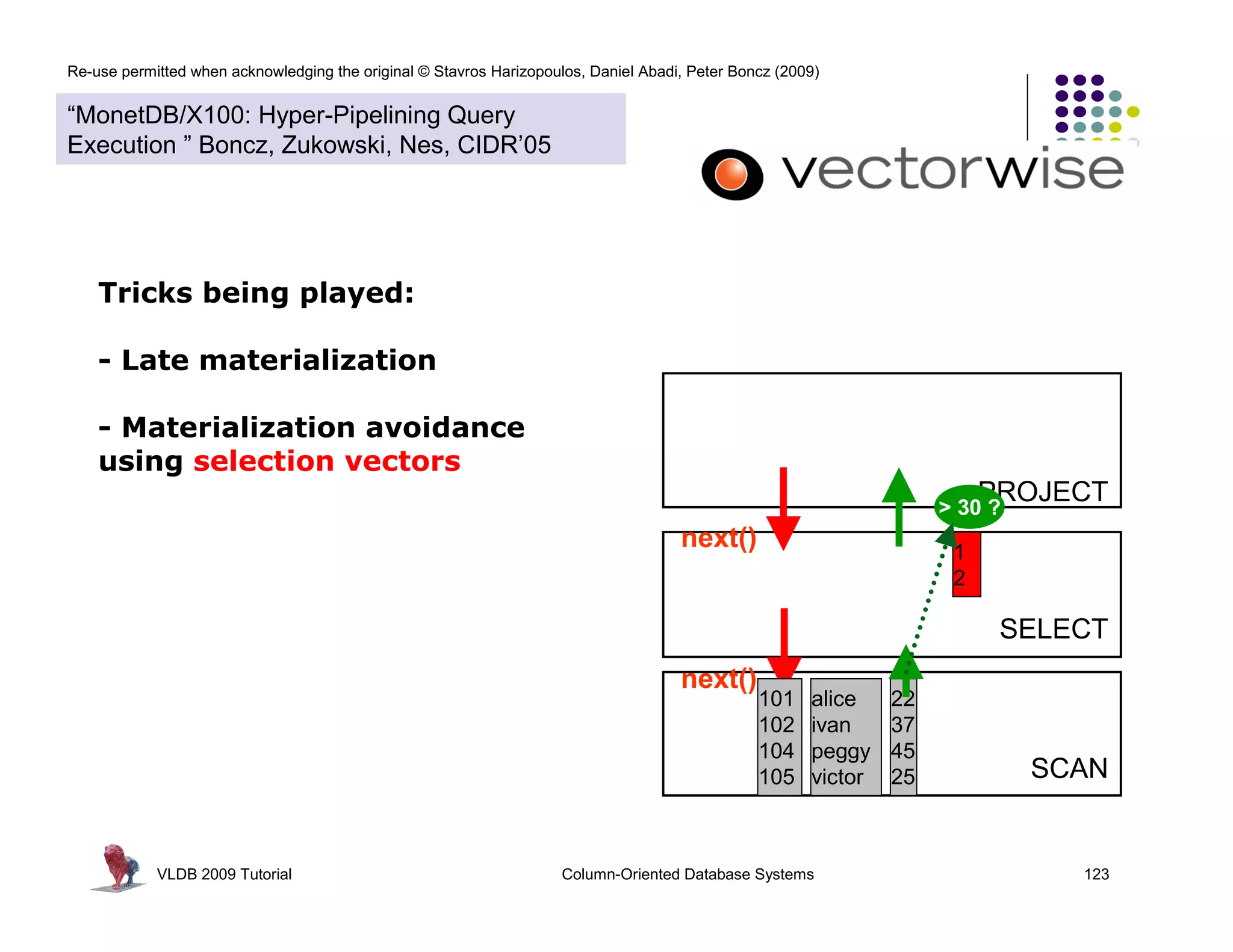
Tricks being played:
- Late materialization
- Materialization avoidance
using selection vectors
VLDB 2009 Tutorial Column-Oriented Database Systems 124
{
for(int i=0; i<n; i++)
res[i] = val * col[sel[i]];
}
selection vectors used to reduce
vector copying
contain selected positions](https://image.slidesharecdn.com/databasesystem-140901161805-phpapp01/75/Database-system-124-2048.jpg)
![Re-use permitted when acknowledging the original © Stavros Harizopoulos, Daniel Abadi, Peter Boncz (2009)
- 30 * 50
350
750
PROJECT
> 30 ?
SELECT
SCAN
next()
next()
next()
101
102
104
105
alice
ivan
peggy
victor
22
37
45
25
7
15
1
2
“MonetDB/X100: Hyper-Pipelining Query
Execution ” Boncz, Zukowski, Nes, CIDR’05
map_mul_flt_val_flt_col(
float *res,
int* sel,
float val,
float *col, int n)
Tricks being played:
- Late materialization
- Materialization avoidance
using selection vectors
VLDB 2009 Tutorial Column-Oriented Database Systems 125
{
for(int i=0; i<n; i++)
res[i] = val * col[sel[i]];
}
selection vectors used to reduce
vector copying
contain selected positions](https://image.slidesharecdn.com/databasesystem-140901161805-phpapp01/75/Database-system-125-2048.jpg)