Downloaded 24 times






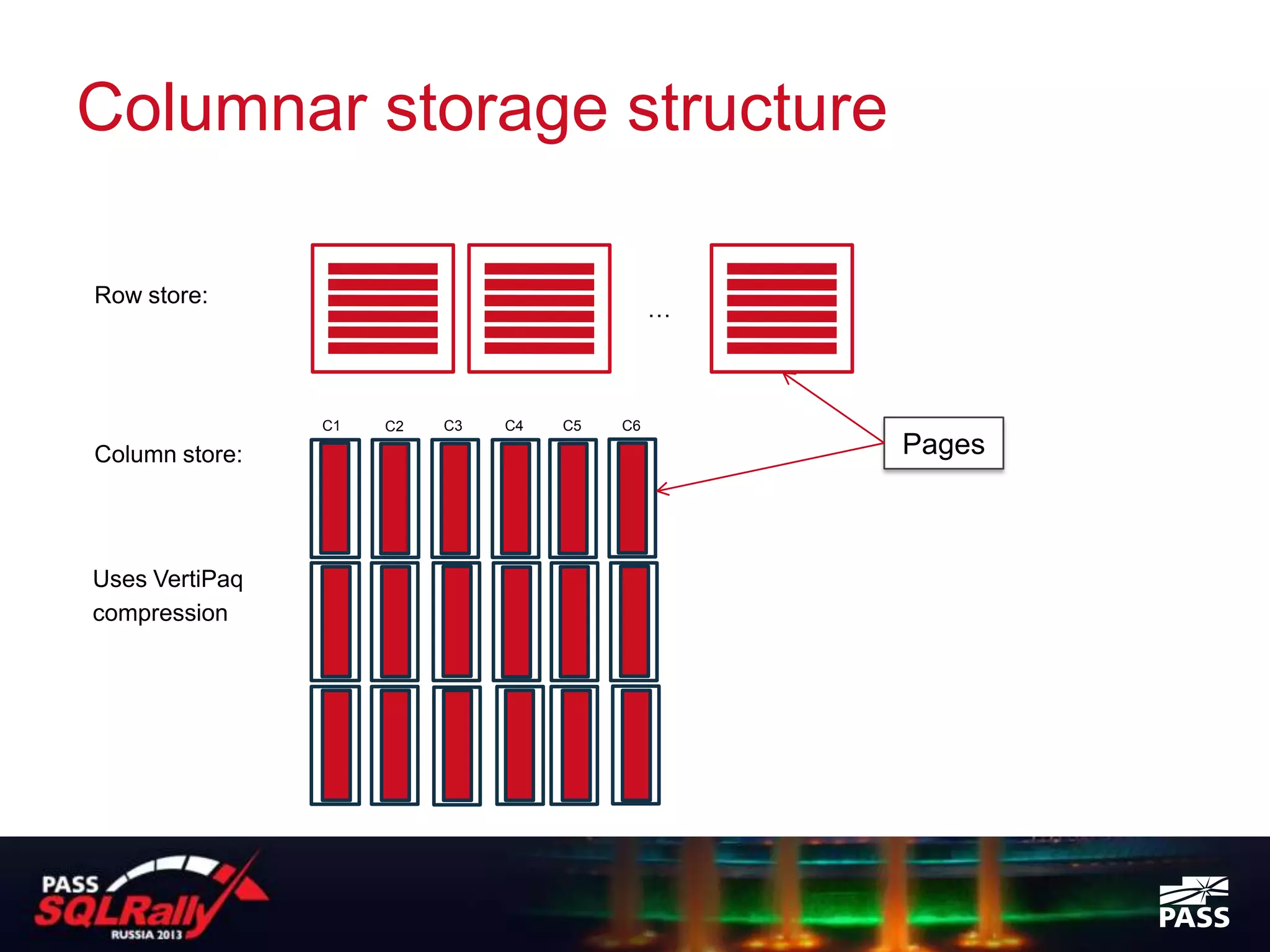



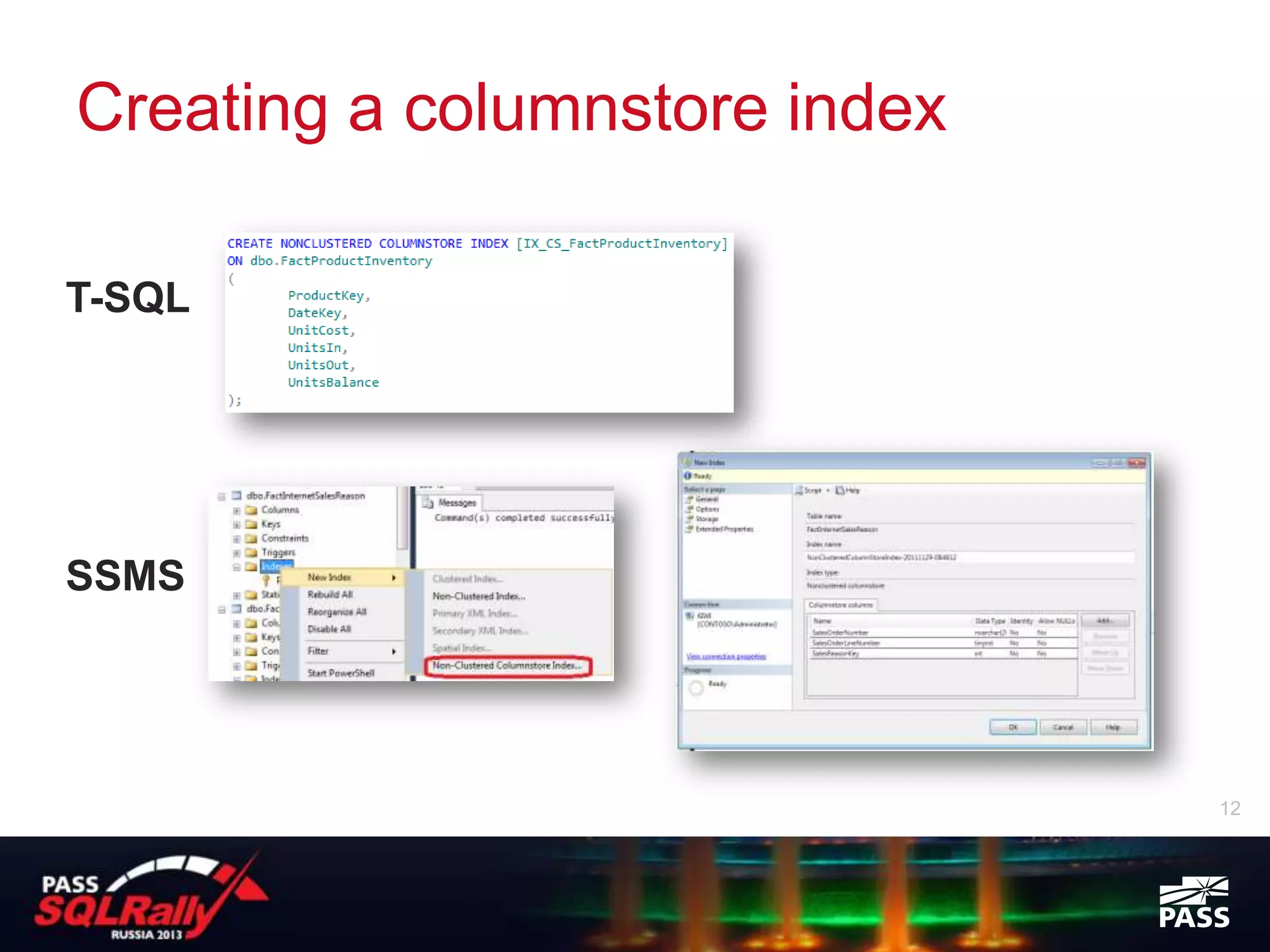

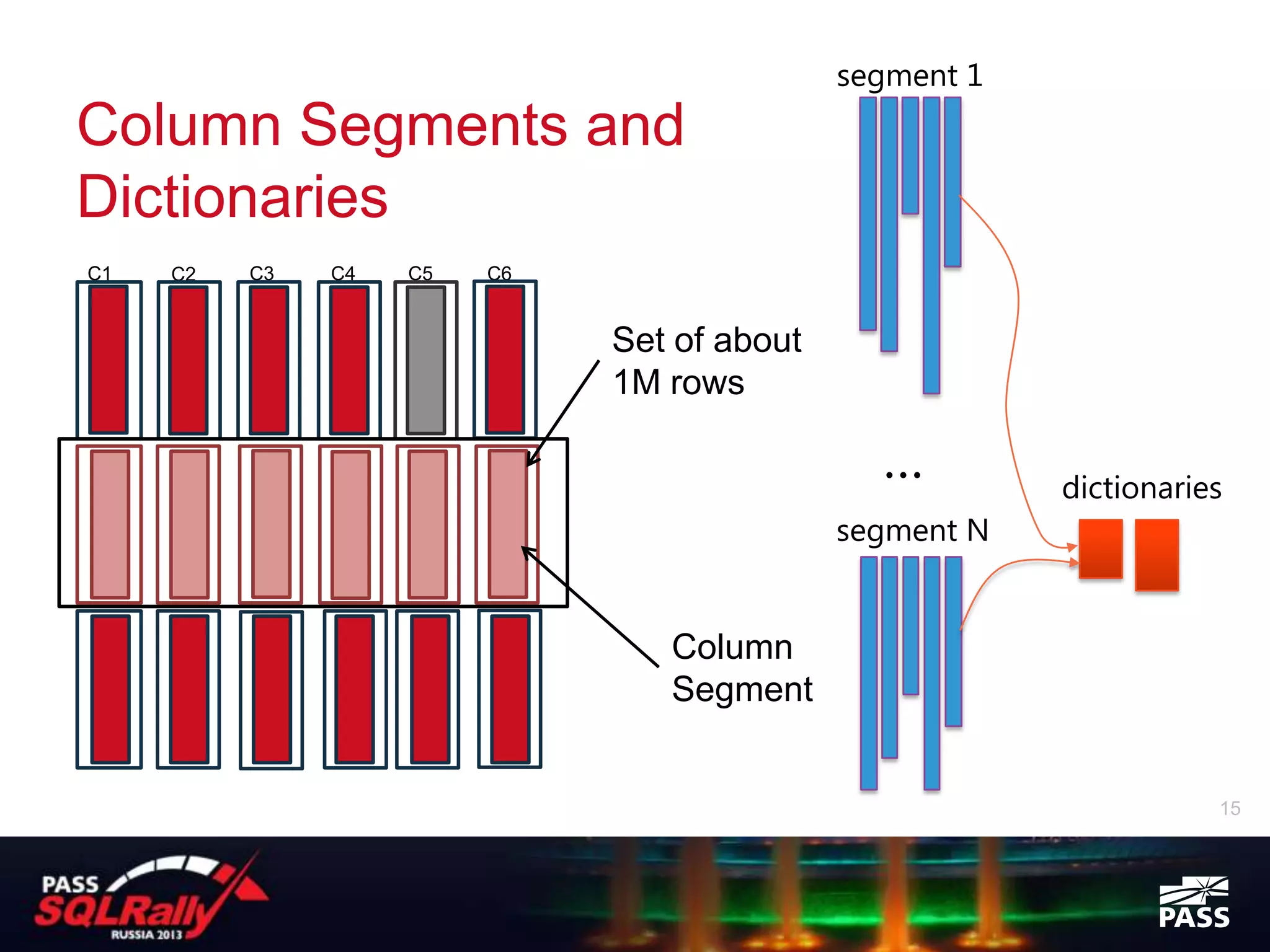
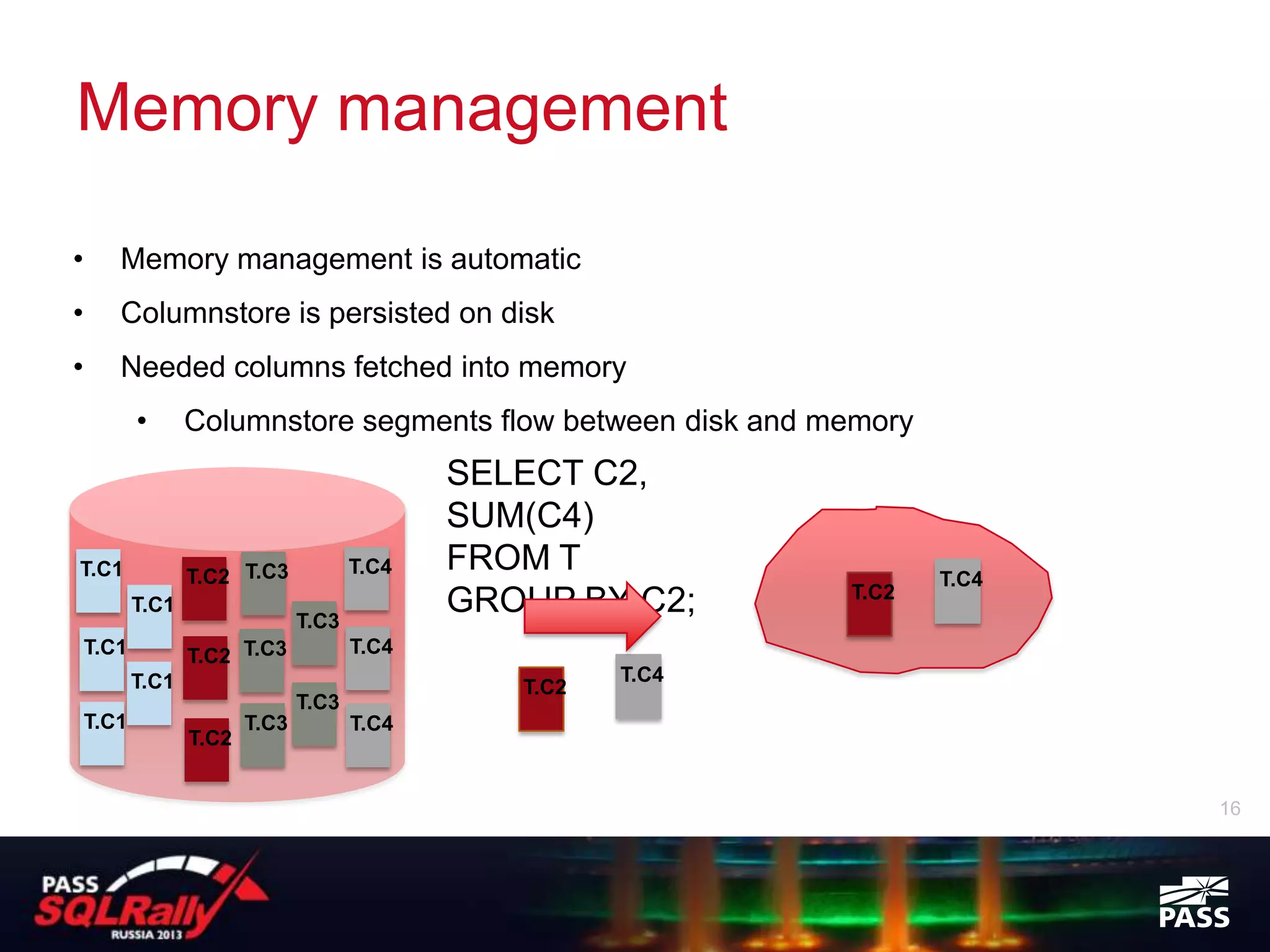














SQL Server 2012 introduced columnstore indexes which provide significant performance improvements for data warehouse and analytics queries against large datasets. Columnstore indexes store data by column rather than by row, allowing queries to access only the relevant columns needed. This results in lower I/O and higher data compression compared to row storage. Columnstore indexes also use a new batch processing execution mode which can further improve query performance by processing many rows at once in memory rather than row-by-row. Columnstore indexes require the table to be read-only but provide an easy way to boost query performance for analytics workloads by 10-100x without needing separate data marts or cubes.














![[db tech showcase Tokyo 2015] B15:最新PostgreSQLはパフォーマンスが飛躍的に向上する!? - PostgreSQ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b15postgresqlntt-oss-center-150619073139-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] A14:Amazon Redshiftの元となったスケールアウト型カラムナーDB徹底解説 その...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a14actian-matrix-insight-technology-150618094408-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)











































