Downloaded 63 times






























![Data Aware Procedures Parallelize procedure and prune to nodes with required data Extend the procedure call with the following syntax: Hint the data the procedure depends on CALL getOverBookedFlights( <bind arguments> ON TABLE FLIGHTAVAILABILITY WHERE FLIGHTID = <SomeFLIGHTID> ; If table is partitioned by columns in the where clause the procedure execution is pruned to nodes with the data (node with <someFLIGHTID> in this case) CALL [PROCEDURE] procedure_name ( [ expression [, expression ]* ] ) [ WITH RESULT PROCESSOR processor_name ] [ { ON TABLE table_name [ WHERE whereClause ] } | { ON {ALL | SERVER GROUPS (server_group_name [, server_group_name ]*) }} ] Fabric Server 2 Fabric Server 1 Client](https://image.slidesharecdn.com/vfabricsqlfireforhighperformancedata-111010115339-phpapp02/85/vFabric-SQLFire-for-high-performance-data-32-320.jpg)
![Parallelize procedure then aggregate (reduce) Fabric Server 2 Fabric Server 1 Client Fabric Server 3 CALL SQLF.CreateResultProcessor( processor_name, processor_class_name); register a Java Result Processor (optional in some cases) : CALL [PROCEDURE] procedure_name ( [ expression [, expression ]* ] ) [ WITH RESULT PROCESSOR processor_name ] [ { ON TABLE table_name [ WHERE whereClause ] } | { ON {ALL | SERVER GROUPS (server_group_name [, server_group_name ]*) }} ]](https://image.slidesharecdn.com/vfabricsqlfireforhighperformancedata-111010115339-phpapp02/85/vFabric-SQLFire-for-high-performance-data-33-320.jpg)












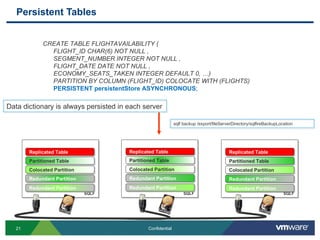
vFabric SQLFire is a distributed SQL database designed for scalability, performance and availability. It uses a shared-nothing architecture with hash partitioning and entity groups to scale linearly. SQLFire supports distributed transactions, SQL queries, and "data aware stored procedures" that can be parallelized across nodes to efficiently process queries involving large amounts of distributed data.























































































