

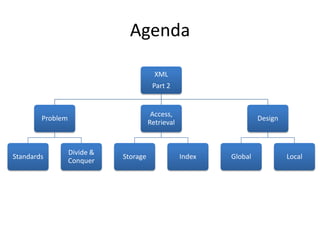
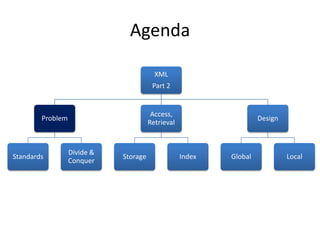



















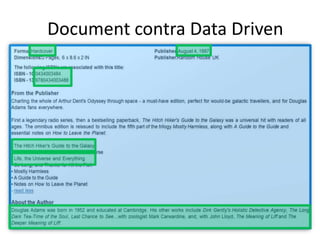




![HybridCLOBMixedcomplex[n]un/structuredXSD [y]B-Tree, IOTDocumentnaunstructuredXSD [n]XMLIndexRelational WorldXMLDB WorldXML Data StorageXMLTypecolumn/tablesXMLTypeViewsObj.Rel.Binary XMLContentcomplex[n]structuredXSD [y]B-Tree, IOT(Object) Relational ObjectsMixedcomplex[y]un/structuredXSD [y/n]XMLIndexRelational Tables](https://image.slidesharecdn.com/opp2010-programmingwithxmlinplsql-part2-amis-marcogralike-101020092839-phpapp02/85/OPP2010-Brussels-Programming-with-XML-in-PL-SQL-Part-2-38-320.jpg)
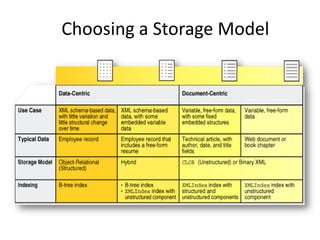
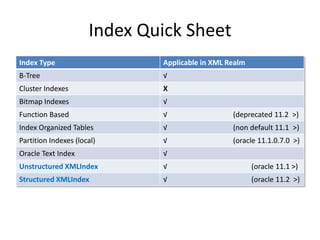
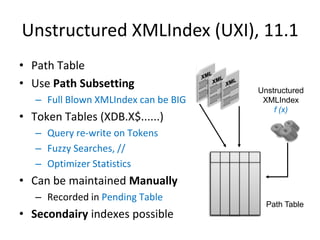
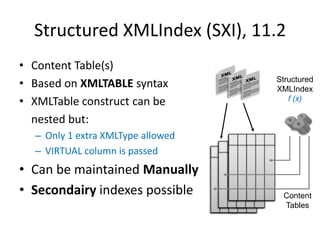
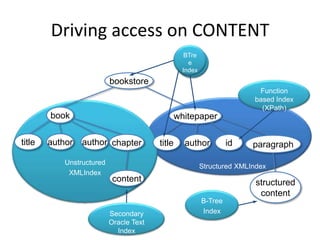
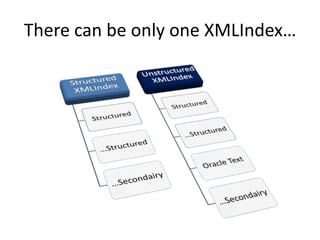
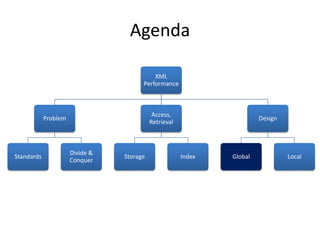
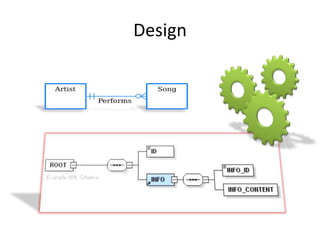






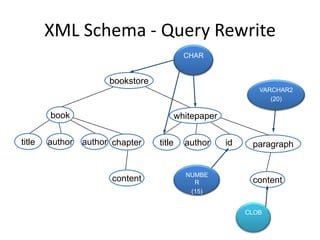




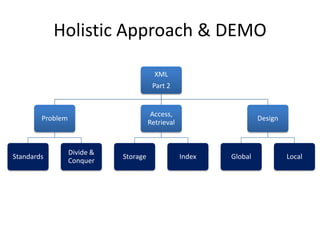
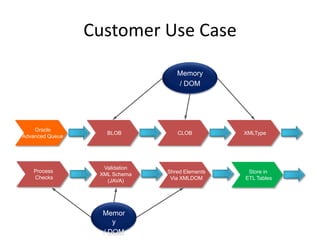
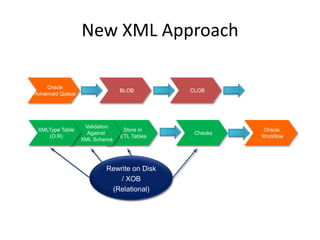
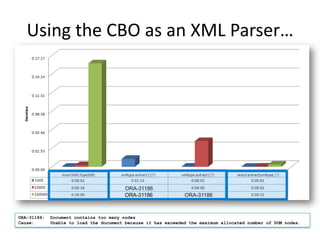

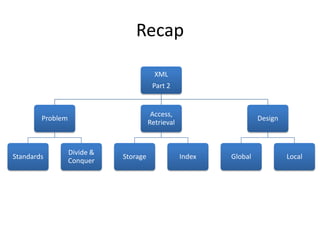

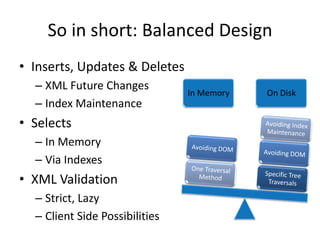





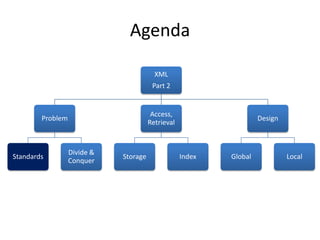
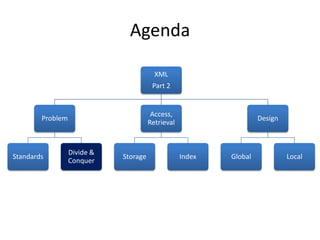
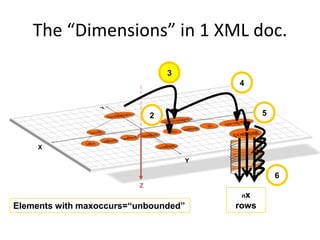
This document discusses optimizing XML performance in Oracle databases. It covers topics like choosing an XMLType storage model, using XML indexes, avoiding impedance mismatch between XML and relational models, and best practices for XML schema and data design. The goal is to provide fast DML operations on XML data through techniques like leveraging the relational engine, minimizing parsing overhead, and avoiding unnecessary validation. A demonstration shows how to use XDB utilities and annotations to optimize physical XML storage and access.
















































![UKOUG2018 - I Know what you did Last Summer [in my Database].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ukoug2018-marcogralike-iknowwhatyoudidlastsummerinmydatabase-230127092211-ddba588a-thumbnail.jpg?width=640&height=640&fit=bounds)





























