Downloaded 177 times







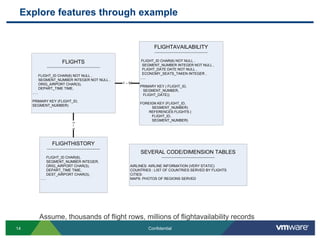
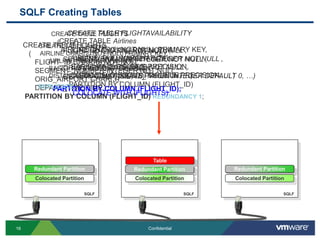














![Partitioning OptionsWhen you wish to partition on a column or columns that are not the primary key, use:PARTITION BY COLUMN (column-name [ , column-name ]*)CREATE TABLE FLIGHTAVAILABILITY ( FLIGHT_ID CHAR(6) NOT NULL , SEGMENT_NUMBER INTEGER NOT NULL , FLIGHT_DATE DATE NOT NULL , ECONOMY_SEATS_TAKEN INTEGER DEFAULT 0, …)PARTITION BY COLUMN (FLIGHT_ID);](https://image.slidesharecdn.com/whatsnextsqlfirev2-110803221409-phpapp02/85/vFabric-SQLFire-Introduction-34-320.jpg)
![Partitioning OptionsYou can partition entries based on a range of values of one of the columns:PARTITION BY RANGE (column-name )( VALUES BETWEEN value AND value[ , VALUES BETWEEN value AND value ]*)CREATE TABLE FLIGHTAVAILABILITY ( FLIGHT_ID CHAR(6) NOT NULL , SEGMENT_NUMBER INTEGER NOT NULL , FLIGHT_DATE DATE NOT NULL , ECONOMY_SEATS_TAKEN INTEGER DEFAULT 0, …)PARTITION BY RANGE ( economy_seats_taken )( VALUES BETWEEN 0 AND 50, VALUES BETWEEN 50 AND 100, VALUES BETWEEN 100 AND 500);](https://image.slidesharecdn.com/whatsnextsqlfirev2-110803221409-phpapp02/85/vFabric-SQLFire-Introduction-35-320.jpg)
![Partitioning OptionsYou can explicitly partition entries based on a list of potential values of a column:PARTITION BY LIST ( column-name ) ( VALUES ( value [ , value ]* ) [ , VALUES ( value [ , value ]* ) ]* ) CREATE TABLE Orders (OrderId INT NOT NULL, ItemId INT, NumItems INT, CustomerId INT, OrderDate DATE, Priority INT, Status CHAR(10), CONSTRAINT Pk_Orders PRIMARY KEY (OrderId) CONSTRAINT Fk_Items FOREIGN KEY (ItemId) REFERENCES Items(ItemId))PARTITION BY LIST ( Status )( VALUES ( 'pending', 'returned' ), VALUES ( 'shipped', 'received' ), VALUES ( 'hold' ));](https://image.slidesharecdn.com/whatsnextsqlfirev2-110803221409-phpapp02/85/vFabric-SQLFire-Introduction-36-320.jpg)


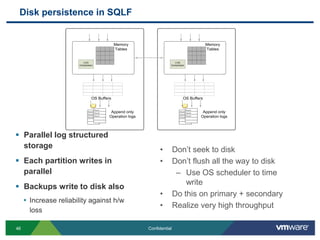

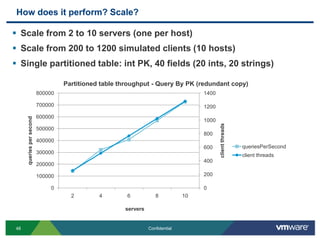
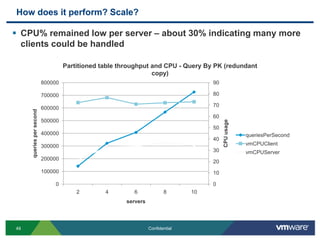
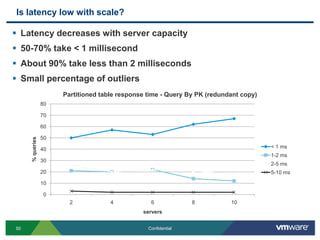

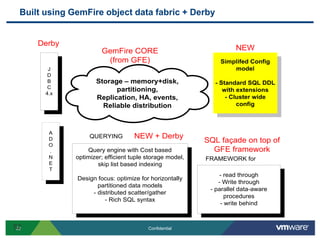

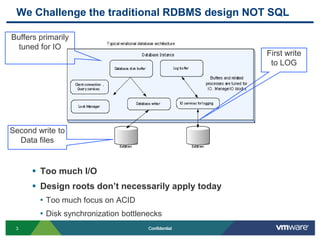
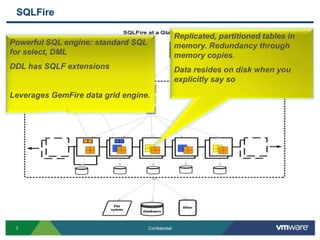
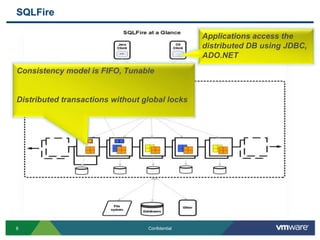
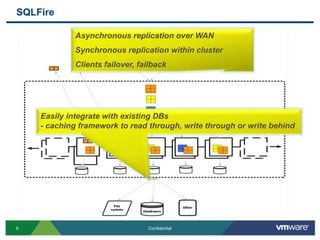
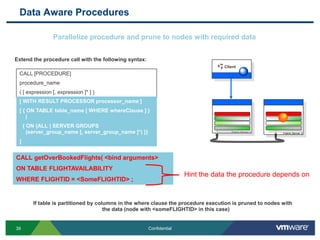
SQLFire is a scalable SQL database that provides an alternative to NoSQL databases by using SQL instead. It features hash partitioning, entity groups to colocate related data, and data aware stored procedures that can run queries in parallel across partitions. SQLFire uses a tunable consistency model and supports distributed transactions without global locks. Data is stored primarily in memory but can optionally be persisted to disk in parallel for high throughput writes without seeks. Benchmark results showed SQLFire can scale linearly from 2 to 10 servers and 200 to 1200 clients.



![[Www.pkbulk.blogspot.com]dbms10](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comdbms10-130615034621-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






























































