Downloaded 24 times


![© 2023, Amazon Web Services, Inc. or its affiliates. All rights reserved.
© 2023, Amazon Web Services, Inc. or its affiliates. All rights reserved.
{
"id": 5432,
"name": "PostgreSQL",
"description": "World's most advanced open source
relational database",
"supportedVersions": [16, 15, 14, 13, 12]
}](https://image.slidesharecdn.com/scale21xvectors-240318141216-63e99587/85/Vectors-are-the-new-JSON-in-PostgreSQL-SCaLE-21x-2-320.jpg)
![© 2023, Amazon Web Services, Inc. or its affiliates. All rights reserved.
© 2023, Amazon Web Services, Inc. or its affiliates. All rights reserved.
{
"id": 5432,
"name":
"PostgreSQL",
"description":
"World's most advanced
open source relational
database",
"supportedVersions":
[16, 15, 14, 13, 12]
}
id 5432
name PostgreSQL
description world's most...
supportedVersions [16,15,14,13,12]](https://image.slidesharecdn.com/scale21xvectors-240318141216-63e99587/85/Vectors-are-the-new-JSON-in-PostgreSQL-SCaLE-21x-3-320.jpg)
![© 2023, Amazon Web Services, Inc. or its affiliates. All rights reserved.
© 2023, Amazon Web Services, Inc. or its affiliates. All rights reserved.
{
"id": 5432,
"name":
"PostgreSQL",
"description":
"World's most advanced
open source relational
database",
"supportedVersions":
[16, 15, 14, 13, 12]
}](https://image.slidesharecdn.com/scale21xvectors-240318141216-63e99587/85/Vectors-are-the-new-JSON-in-PostgreSQL-SCaLE-21x-4-320.jpg)


![© 2023, Amazon Web Services, Inc. or its affiliates. All rights reserved.
© 2023, Amazon Web Services, Inc. or its affiliates. All rights reserved.
[0.5, 0.5]](https://image.slidesharecdn.com/scale21xvectors-240318141216-63e99587/85/Vectors-are-the-new-JSON-in-PostgreSQL-SCaLE-21x-7-320.jpg)
![© 2023, Amazon Web Services, Inc. or its affiliates. All rights reserved.
© 2023, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Magnitude
|| [0.5, 0.5] || = √ (0.52 + 0.52) = 0.70710](https://image.slidesharecdn.com/scale21xvectors-240318141216-63e99587/85/Vectors-are-the-new-JSON-in-PostgreSQL-SCaLE-21x-8-320.jpg)
![© 2023, Amazon Web Services, Inc. or its affiliates. All rights reserved.
© 2023, Amazon Web Services, Inc. or its affiliates. All rights reserved.
Direction
Magnitude
[0.5, 0.5]](https://image.slidesharecdn.com/scale21xvectors-240318141216-63e99587/85/Vectors-are-the-new-JSON-in-PostgreSQL-SCaLE-21x-9-320.jpg)
![© 2023, Amazon Web Services, Inc. or its affiliates. All rights reserved.
© 2023, Amazon Web Services, Inc. or its affiliates. All rights reserved.
[0.5, 0.5, 0.5]](https://image.slidesharecdn.com/scale21xvectors-240318141216-63e99587/85/Vectors-are-the-new-JSON-in-PostgreSQL-SCaLE-21x-10-320.jpg)


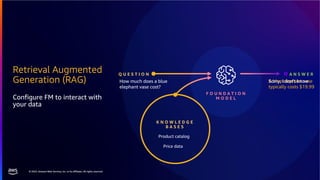
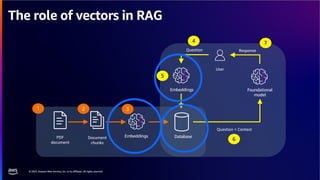






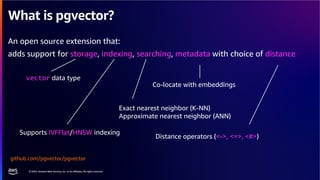
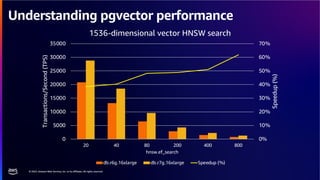












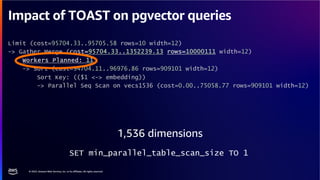


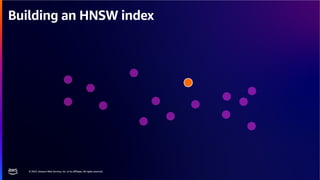
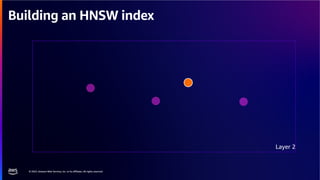
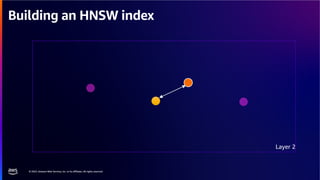

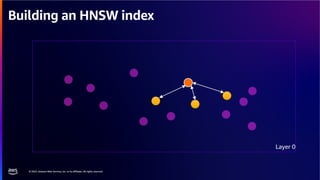

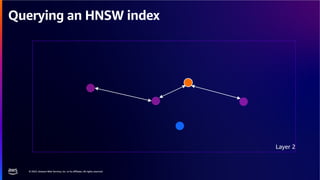
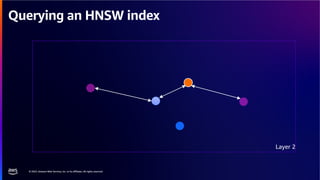
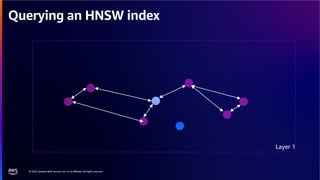
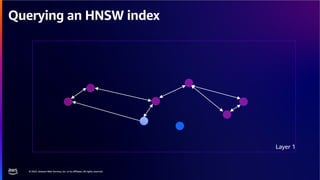
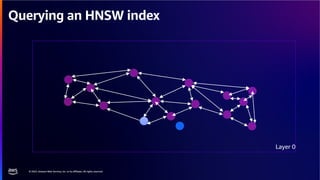
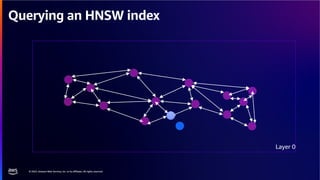

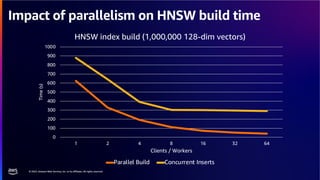
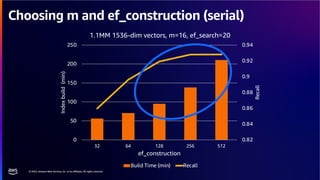
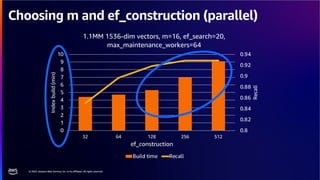
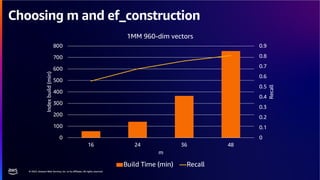



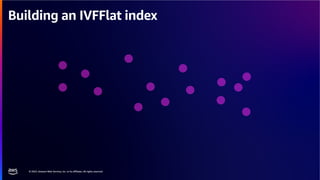







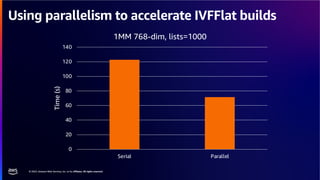






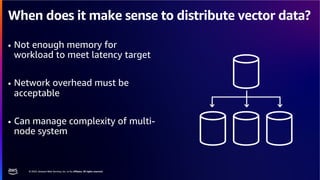


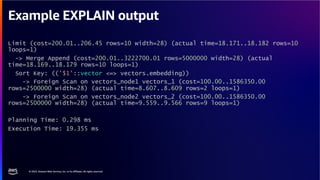





The document discusses PostgreSQL as an advanced open-source relational database, highlighting its support for JSON and the addition of features for vector storage with the pgvector extension. It elaborates on the challenges and strategies in using vectors for data storage and retrieval, including approximate nearest neighbor searches and the impact of PostgreSQL's TOAST mechanism on performance. Additionally, it provides best practices and insights on utilizing various indexing methods such as HNSW and IVFFlat for optimizing vector searches.







































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)











