Downloaded 45 times


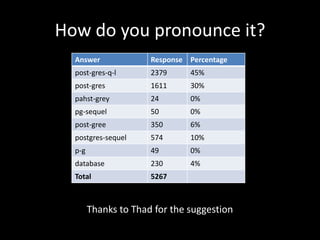










![Datatypes: arrays
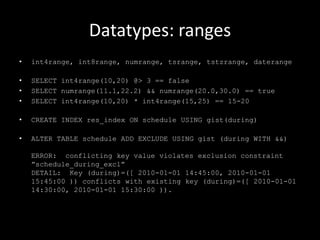
• CREATE TABLE sal_emp(name text, pay_by_quarter integer[],
schedule text[][])
• CREATE TABLE tictactoe ( squares integer[3][3] )
• INSERT INTO tictactoe VALUES („{{1,2,3},{4,5,6},{7,8,9}}‟)
• SELECT squares[1:2][1:1] == {{1},{4}}
• SELECT squares[2:3][2:3] == {{5,6},{8,9}}](https://image.slidesharecdn.com/postgresql-130717114659-phpapp01/85/PostgreSQL-It-s-kind-ve-a-nifty-database-17-320.jpg)






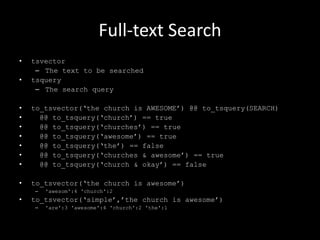
![Further exploration: PLV8
• CREATE OR REPLACE FUNCTION plv8_test(keys text[], vals text[])
RETURNS text AS $$
var o = {};
for(var i = 0; i < keys.length; i++) {
o[keys[i]] = vals[i];
}
return JSON.stringify(o);
$$ LANGUAGE plv8 IMMUTABLE STRICT;
SELECT plv8_test(ARRAY[„name‟,‟age‟],ARRAY[„Tom‟,‟29‟]);
• CREATE TYPE rec AS (i integer, t text);
CREATE FUNCTION set_of_records RETURNS SETOF rec AS $$
plv8.return_next({“i”: 1,”t”: ”a”});
plv8.return_next({“i”: 2,”t”: “b”});
$$ LANGUAGE plv8;
SELECT * FROM set_of_records();](https://image.slidesharecdn.com/postgresql-130717114659-phpapp01/85/PostgreSQL-It-s-kind-ve-a-nifty-database-24-320.jpg)




The document discusses PostgreSQL, highlighting its features, capabilities, and limitations. It emphasizes PostgreSQL's compliance with ACID principles, support for full-text search, and various data types while outlining practical implementations and comparisons with other search engines. Additionally, the author shares personal insights and experiences in utilizing PostgreSQL for web applications.






































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)






