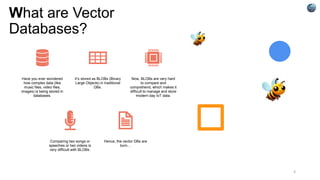
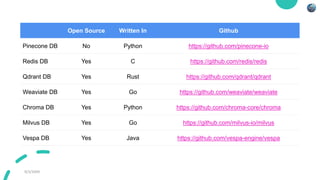
The document explains vector databases, which are designed for storing and querying high-dimensional data using vector embeddings, enhancing applications like machine learning and similarity searches. It discusses the pros and cons, comparing them with traditional databases, highlighting their scalability and efficiency but also noting potential complexity and storage overhead. The future of vector databases appears promising, with anticipated advancements in performance, integration with machine learning, and an expanding open-source ecosystem.










































































![ict_presentation_final_final_final[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ictpresentationfinalfinalfinal1-251230145259-2b4839bd-thumbnail.jpg?width=640&height=640&fit=bounds)















