

![3
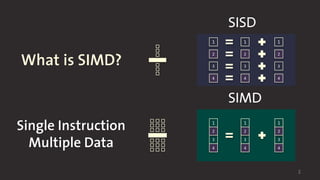
SISD
SIMD
1
3
2
4
1
3
2
4
1
3
2
4
1
3
2
4
1
3
2
4
1
3
2
4
AVX x4
#define T double
void add(T* x, T* y, T* z, int N) {
for(int i = 0; i < N; ++i) {
T x1, y1, z1;
x1 = x[i];
y1 = y[i];
z1 = x1 + y1;
z[i] = z1;
}
}
Scalar
#define T double
void add(T* x, T* y, T* z, int N) {
for(int i = 0; i < N; i += 4) {
__m256d x1, y1, z1;
x1 = _mm256_loadu_pd(x + i);
y1 = _mm256_loadu_pd(y + i);
z1 = _mm256_add_pd(x1, y1);
_mm256_storeu_pd(z + i, z1);
}
}](https://image.slidesharecdn.com/intrinsics-170622013750/85/Vectorization-with-LMS-SIMD-Intrinsics-3-320.jpg)
![4
SISD
SIMDAVX x4
#define T double
void add(T* x, T* y, T* z, int N) {
for(int i = 0; i < N; ++i) {
T x1, y1, z1;
x1 = x[i];
y1 = y[i];
z1 = x1 + y1;
z[i] = z1;
}
}
Scalar
#define T double
void add(T* x, T* y, T* z, int N) {
for(int i = 0; i < N; i += 4) {
__m256d x1, y1, z1;
x1 = _mm256_loadu_pd(x + i);
y1 = _mm256_loadu_pd(y + i);
z1 = _mm256_add_pd(x1, y1);
_mm256_storeu_pd(z + i, z1);
}
}
LBB0_3:
movsd (%rdi,%rax,8), %xmm0
addsd (%rsi,%rax,8), %xmm0
movsd %xmm0, (%rdx,%rax,8)
incq %rax
cmpl %eax, %r9d
jne LBB0_3
LBB0_3:
vmovupd (%rdi,%r10,8), %ymm0
vaddpd (%rsi,%r10,8), %ymm0, %ymm0
vmovupd %ymm0, (%rax)
addq $4, %r10
addq $32, %rax
addq $1, %rcx
jne LBB0_3](https://image.slidesharecdn.com/intrinsics-170622013750/85/Vectorization-with-LMS-SIMD-Intrinsics-4-320.jpg)



![Challenge #2
LMS has read / write effects
• Produce the effects
automatically using the
category data in the Intel
Intrinsics Guide
<intrinsic tech='AVX' rettype='__m256d' name='_mm256_loadu_pd'>
<type>Floating Point</type>
<CPUID>AVX</CPUID>
<category>Load</category>
<parameter varname='mem_addr' type='double const *’ />
<description>
Load 256-bits (composed of 4 packed
double-precision (64-bit) floating-point elements)
from memory into "dst". "mem_addr" does not need
to be aligned on any particular boundary.
</description>
<operation>
dst[255:0] := MEM[mem_addr+255:mem_addr]
dst[MAX:256] := 0
</operation>
<instruction name='vmovupd' form='ymm, m256’ />
<header>immintrin.h</header>
</intrinsic>](https://image.slidesharecdn.com/intrinsics-170622013750/85/Vectorization-with-LMS-SIMD-Intrinsics-11-320.jpg)



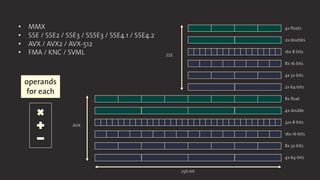
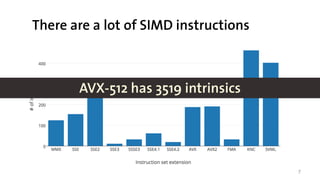
This document contains slides from a PLDI 2017 tutorial on vectorization with LMS using SIMD intrinsics. It discusses Single Instruction Multiple Data (SIMD) parallelism and how to implement SIMD intrinsics in LMS. Some challenges include handling large classes, automatically producing read/write effects, type mappings for unsigned values and pointers, and implementing arrays instead of general containers for the DSL. The slides provide examples of scalar and SIMD-vectorized code for addition, as well as an overview of SIMD instruction sets like AVX and the large number of intrinsics that need to be supported. It proposes generating intrinsics automatically from metadata to address porting them all to LMS.



































































