Download as PDF, PPTX







![Example
// A 16 byte = 128bit vector struct
struct vector4 {
float x, y, z, w;
};
!
// Add two constant vectors and return the resulting vector
vector4 SSE_add(struct vector4 *v1, struct vector4 *v2)
{
struct vector4 ret;
__asm {
MOV EAX v1
MOV EBX, v2
MOVUPS XMM0, [EAX]
MOVUPS XMM1, [EBX]
ADDPS XMM0, XMM1
MOVUPS [ret], XMM0
}
return ret;
}](https://image.slidesharecdn.com/x86-simd-instructions-140524051450-phpapp01/85/X86-SIMD-Instructions-9-320.jpg)


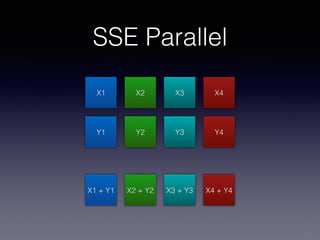
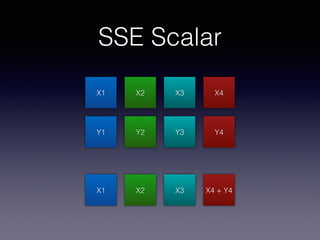
The document outlines the evolution of x86 SIMD instructions, beginning with MMX introduced in 1997, which added 8 new 64-bit registers for integer operations. It then discusses SSE, introduced in 1999, which included 8 new 128-bit registers and addressed issues with MMX, requiring OS support and data alignment. A code snippet illustrates the usage of SSE for adding two vectors using SIMD operations.

































