Download as PDF, PPTX





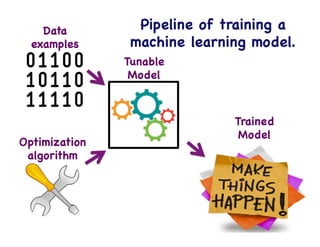






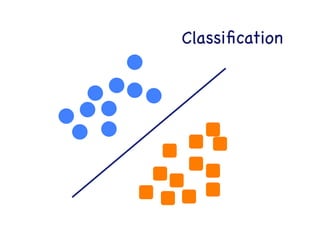
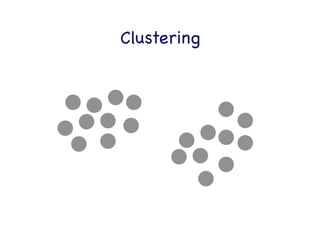
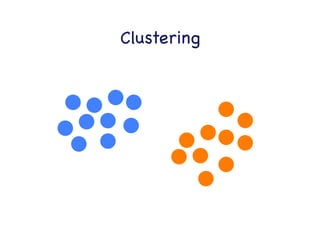
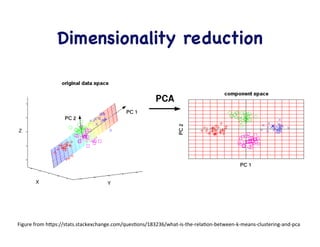
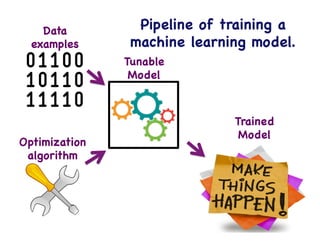
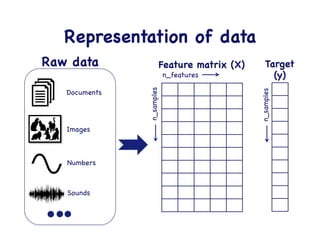

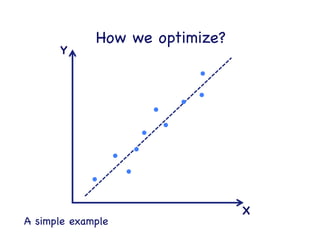
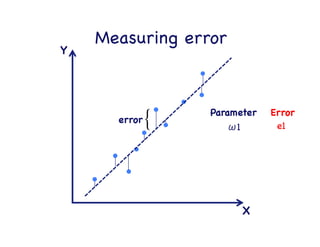
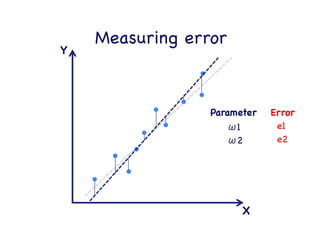
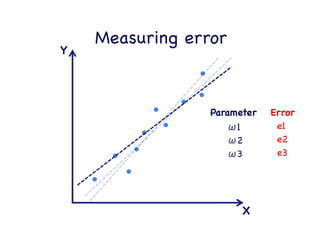
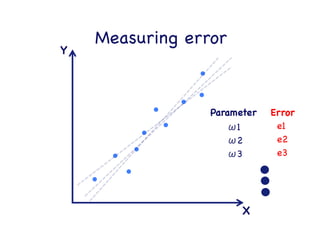
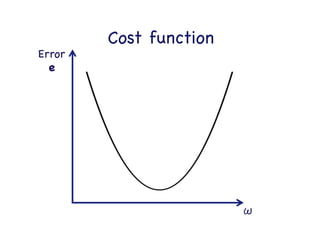
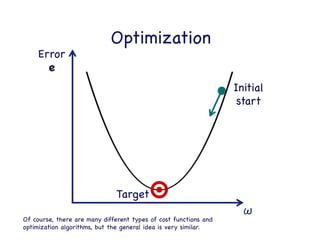
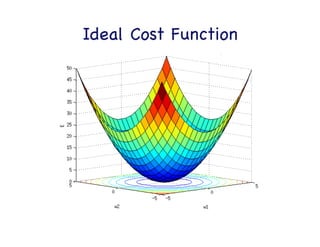








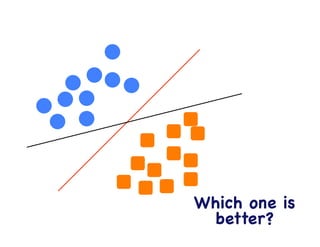
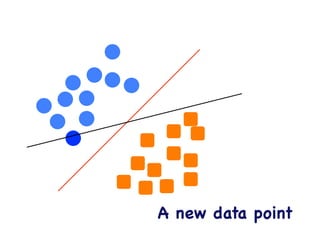
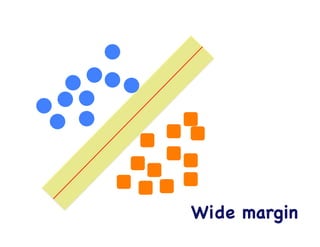
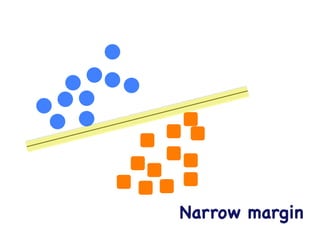
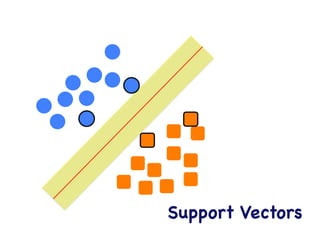

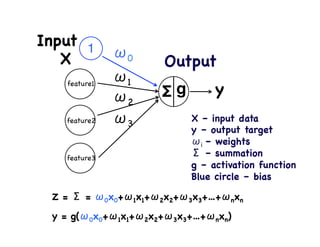
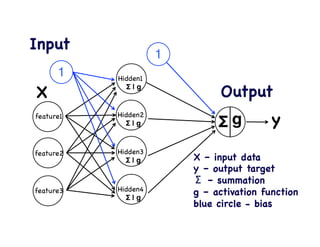

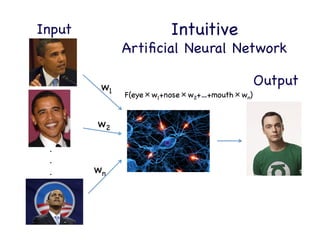
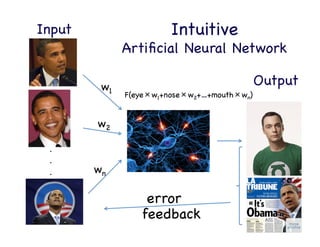
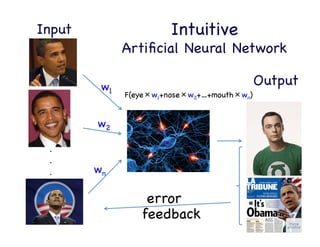
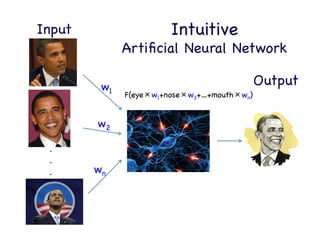


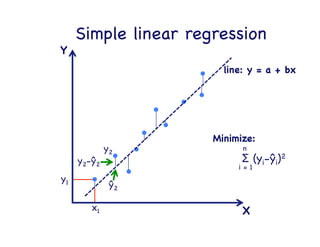

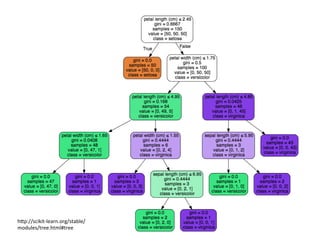
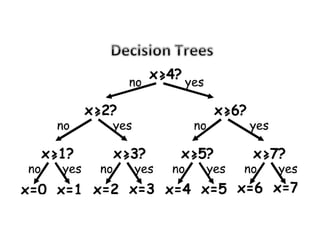
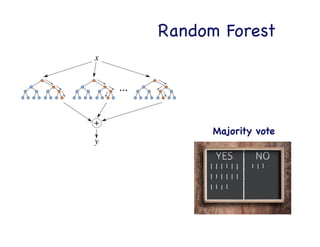


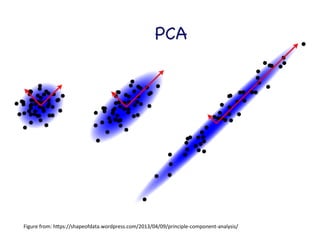
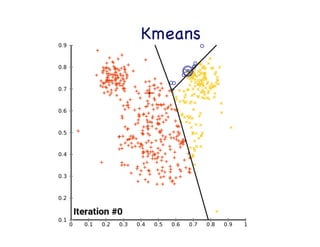



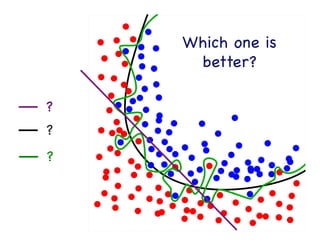
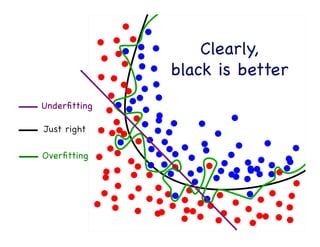

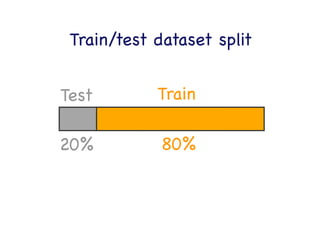
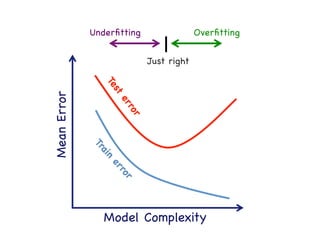


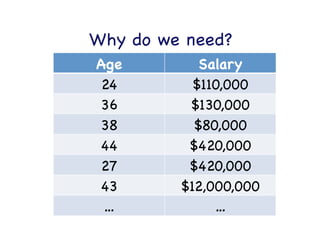



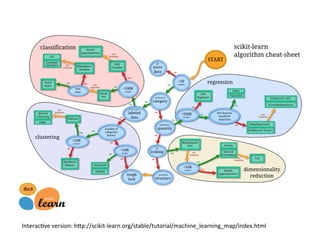

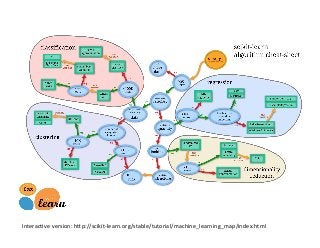


This document provides an overview of machine learning concepts and techniques using the scikit-learn library in Python. It begins with introductions to different types of machine learning problems including supervised learning tasks like classification and regression as well as unsupervised learning problems like clustering and dimensionality reduction. It then discusses common machine learning algorithms such as support vector machines, k-means clustering, random forests, and principal component analysis. The document also covers best practices for developing machine learning models including data preprocessing, evaluating model performance, and tuning hyperparameters.




































































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)















![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)

