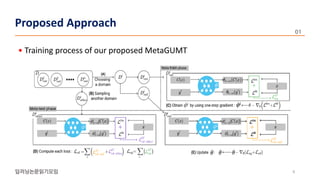
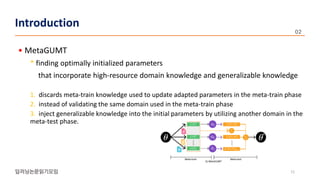
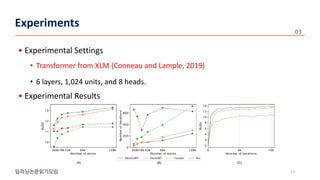
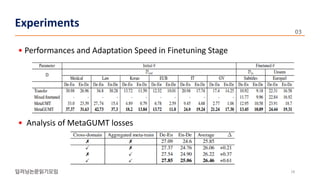
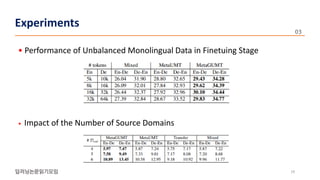
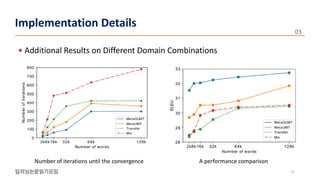
The document presents a novel meta-learning approach for unsupervised neural machine translation (UNMT) in low-resource domains, called meta-UMT, which allows for adaptation to new domains with limited monolingual data. It details two training phases: meta-training for domain-specific knowledge and meta-testing for optimization, alongside a comparison with a variant called meta-GUMT aimed at enhancing generalizability with high-resource knowledge. Experimental results demonstrate the effectiveness of the proposed methods in improving translation performance and adaptation speed.