Download as PDF, PPTX





















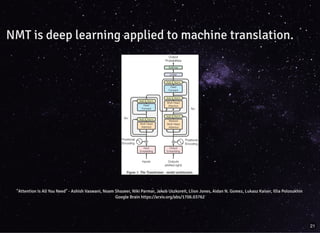

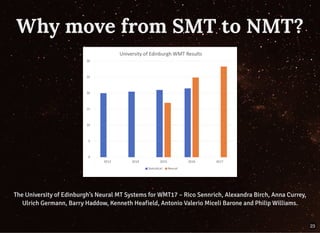
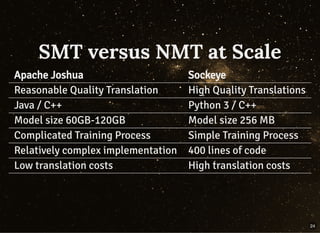




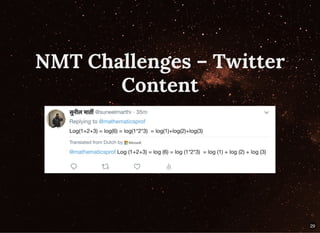
















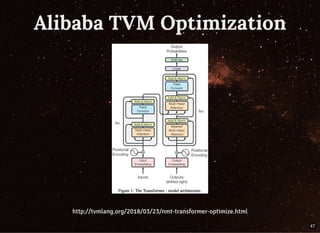
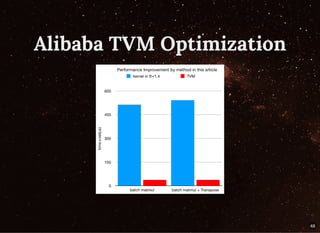








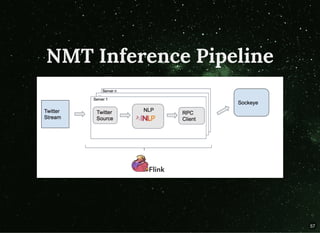








The document discusses building streaming pipelines for neural machine translation (NMT) and contrasts it with statistical machine translation (SMT). It covers various tools and technologies used in NMT, challenges faced in developing effective translation models, and highlights the benefits of transitioning from SMT to NMT. Furthermore, it outlines the complete pipeline for NMT inference employing Apache Flink and related tools.
























































