Download to read offline






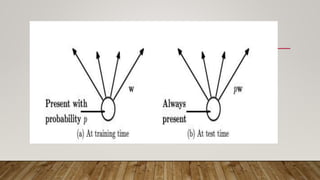










Regularization techniques like dropout and max-norm regularization help reduce overfitting in deep learning models. Dropout prevents overfitting by randomly ignoring nodes during training, ensuring nodes are not codependent. Max-norm regularization constrains weight vectors to have an L2 norm below a set value r to prevent large weights that overly fit the training data. Both techniques improve model generalization to unseen data compared to non-regularized networks, though dropout training may take longer.















































