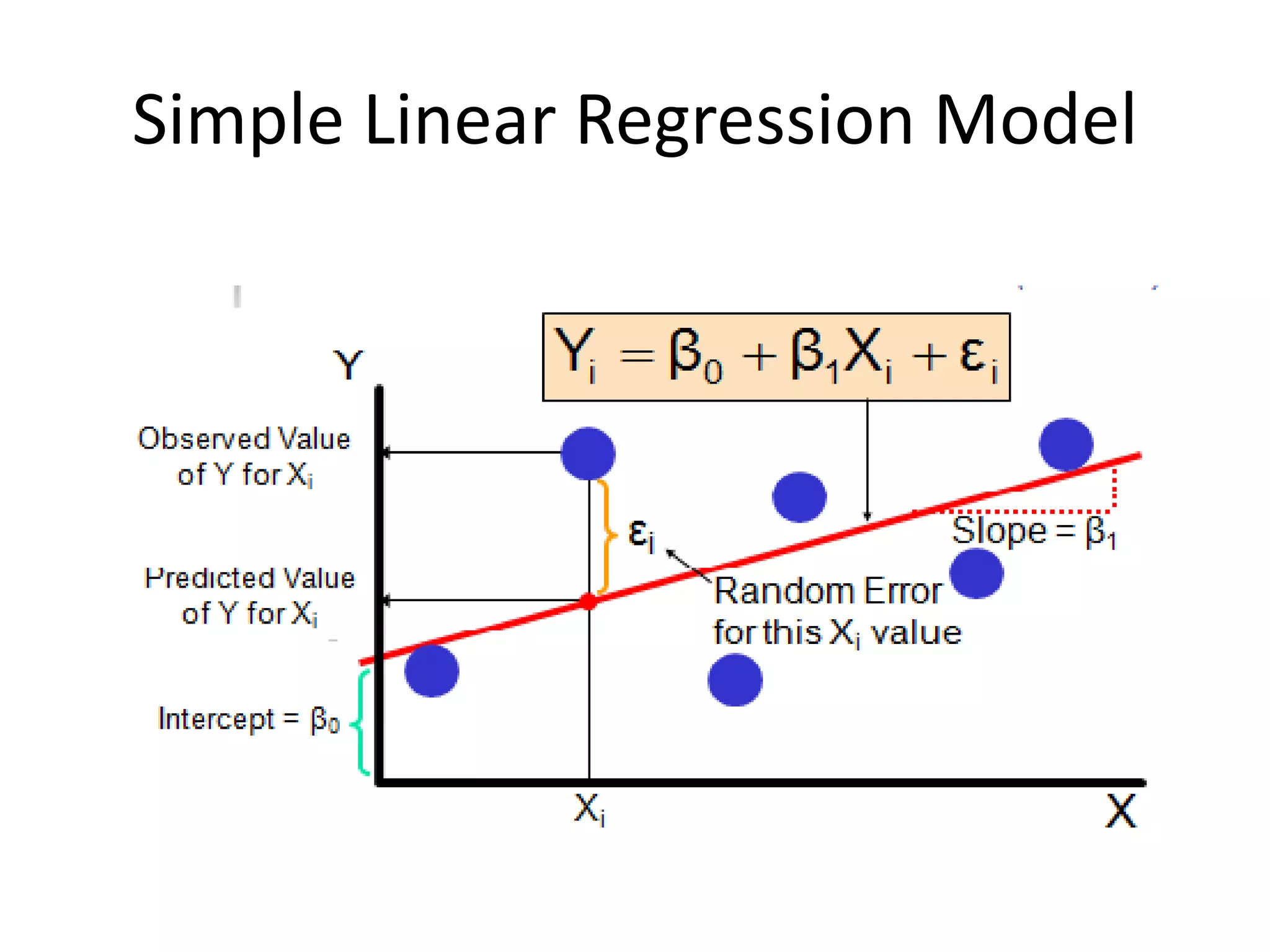
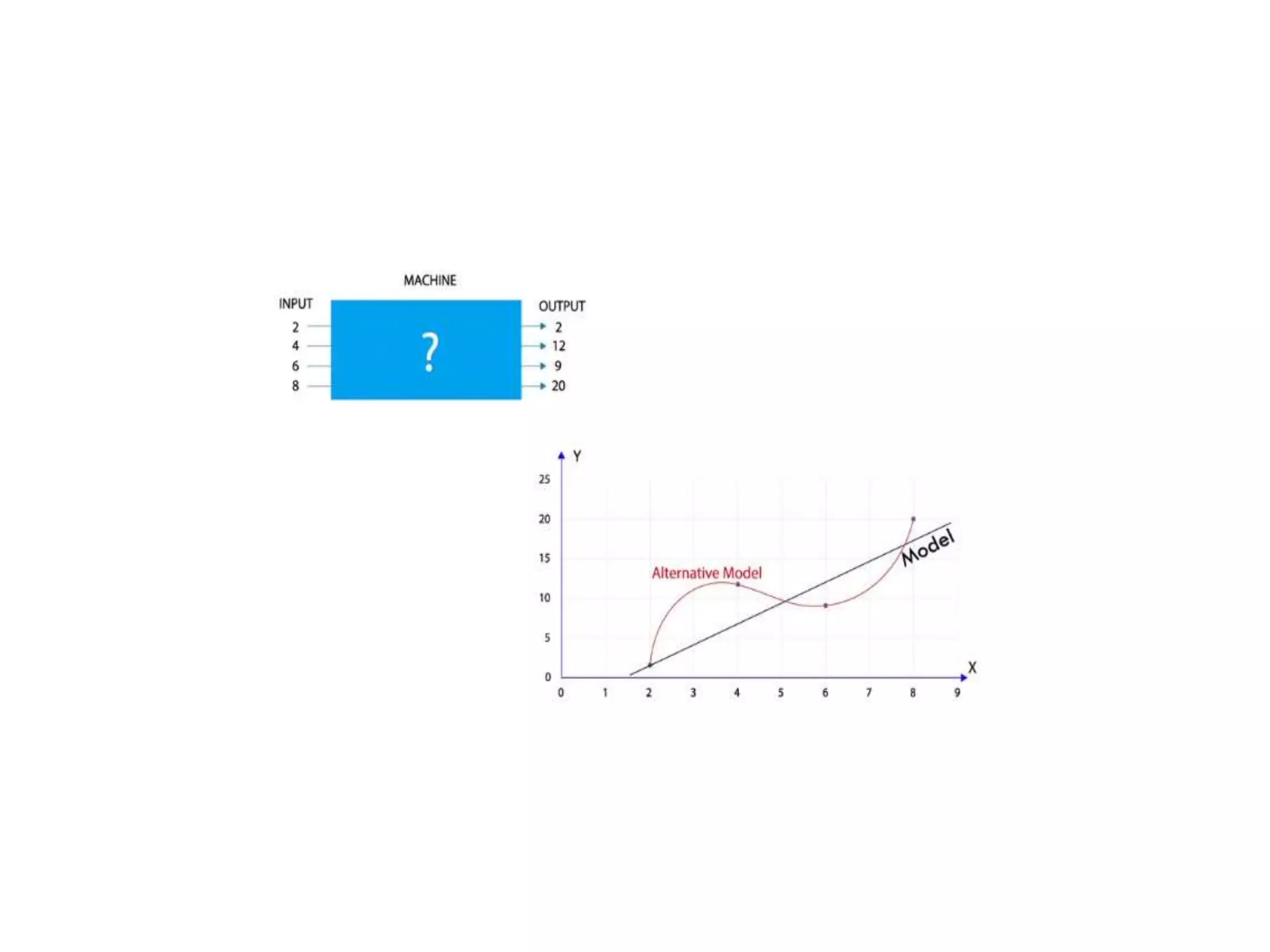
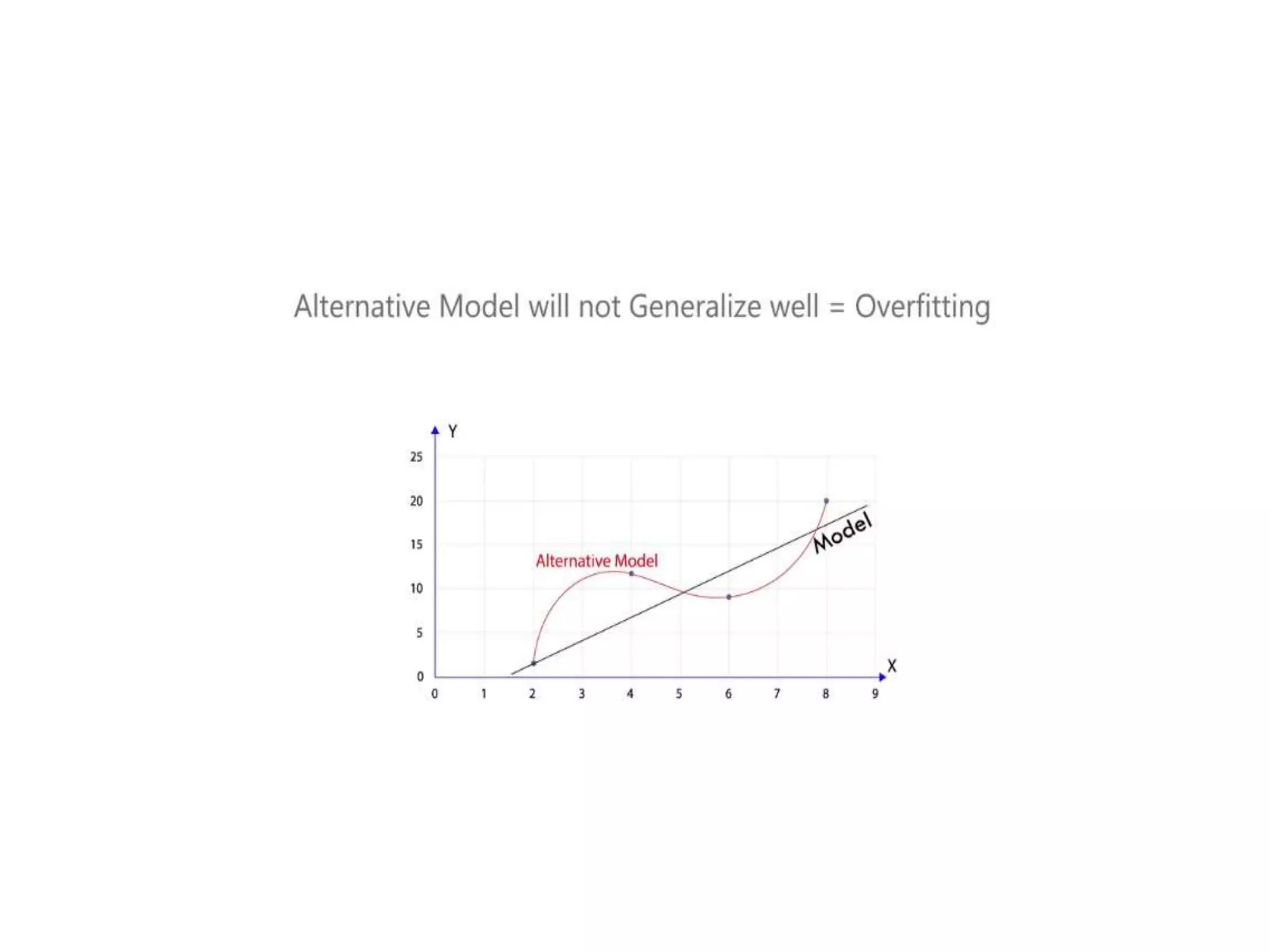
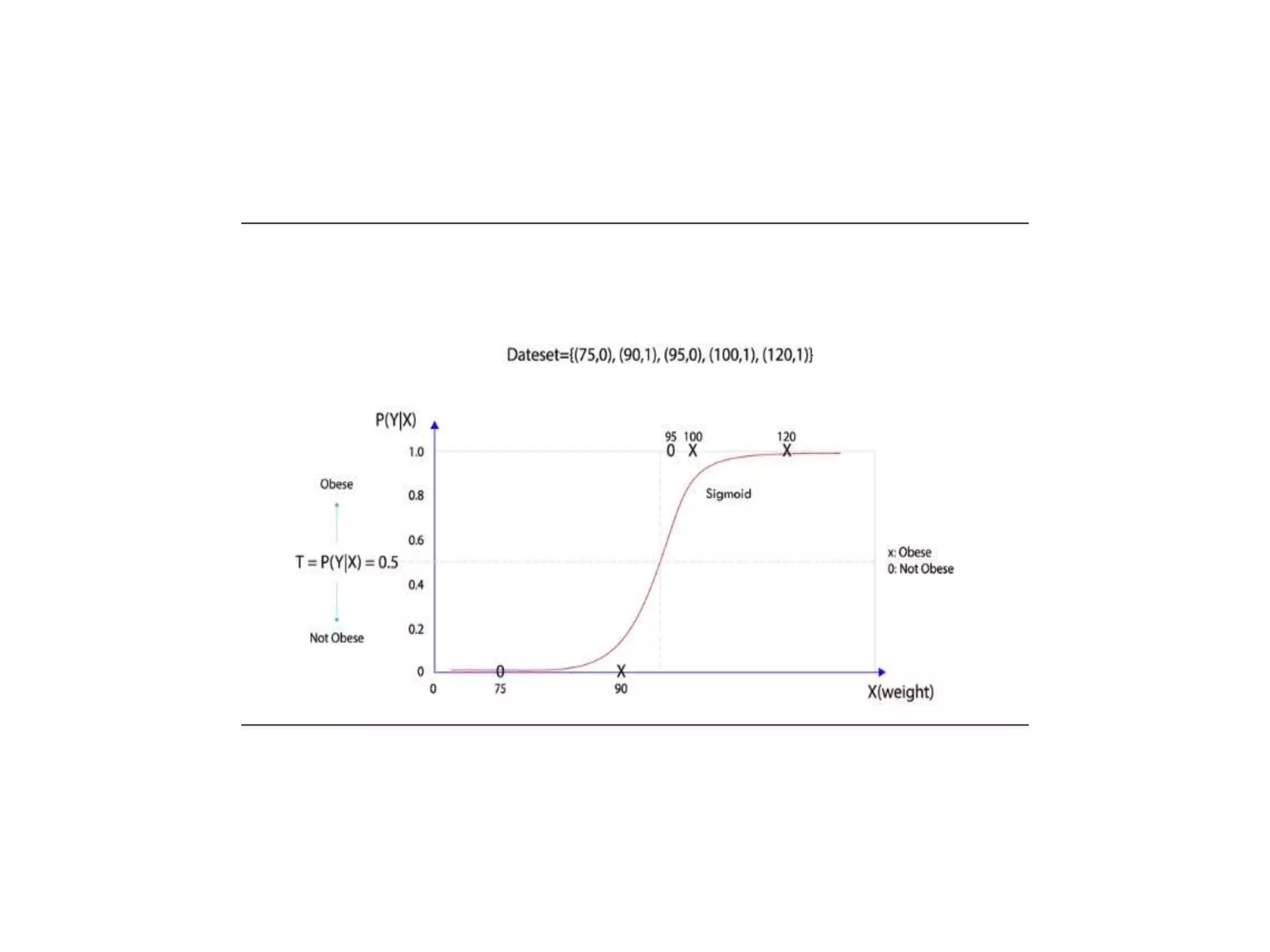
Deep learning is a subset of machine learning that uses artificial neural networks. Neural networks are composed of interconnected layers of nodes that process input data. Activation functions introduce non-linearity between layers to increase the model's ability to learn complex patterns. Models are trained via backpropagation to minimize loss by adjusting weights to better match predictions to actual outputs. Overfitting can occur if the model becomes too complex for the data.