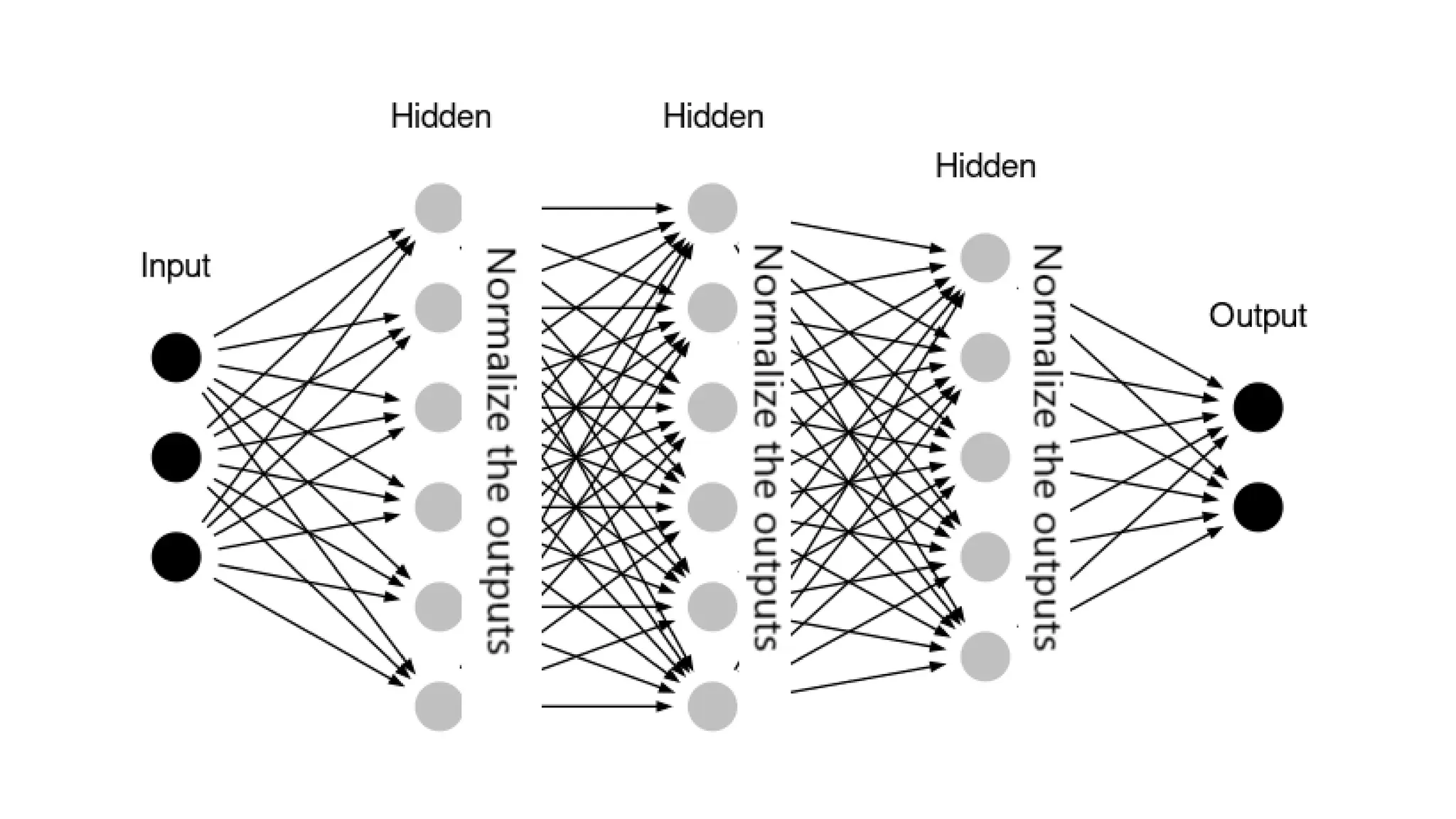
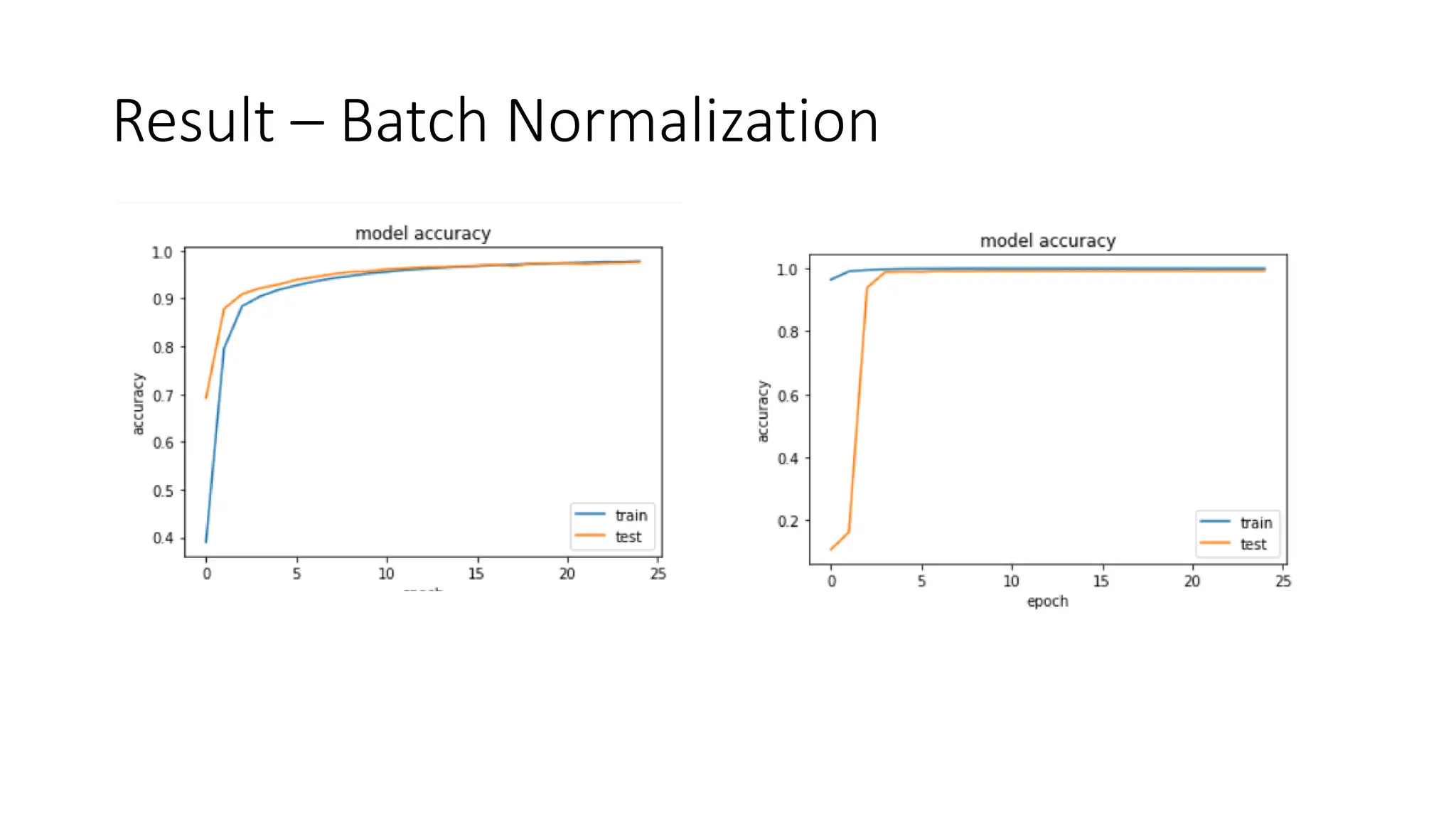
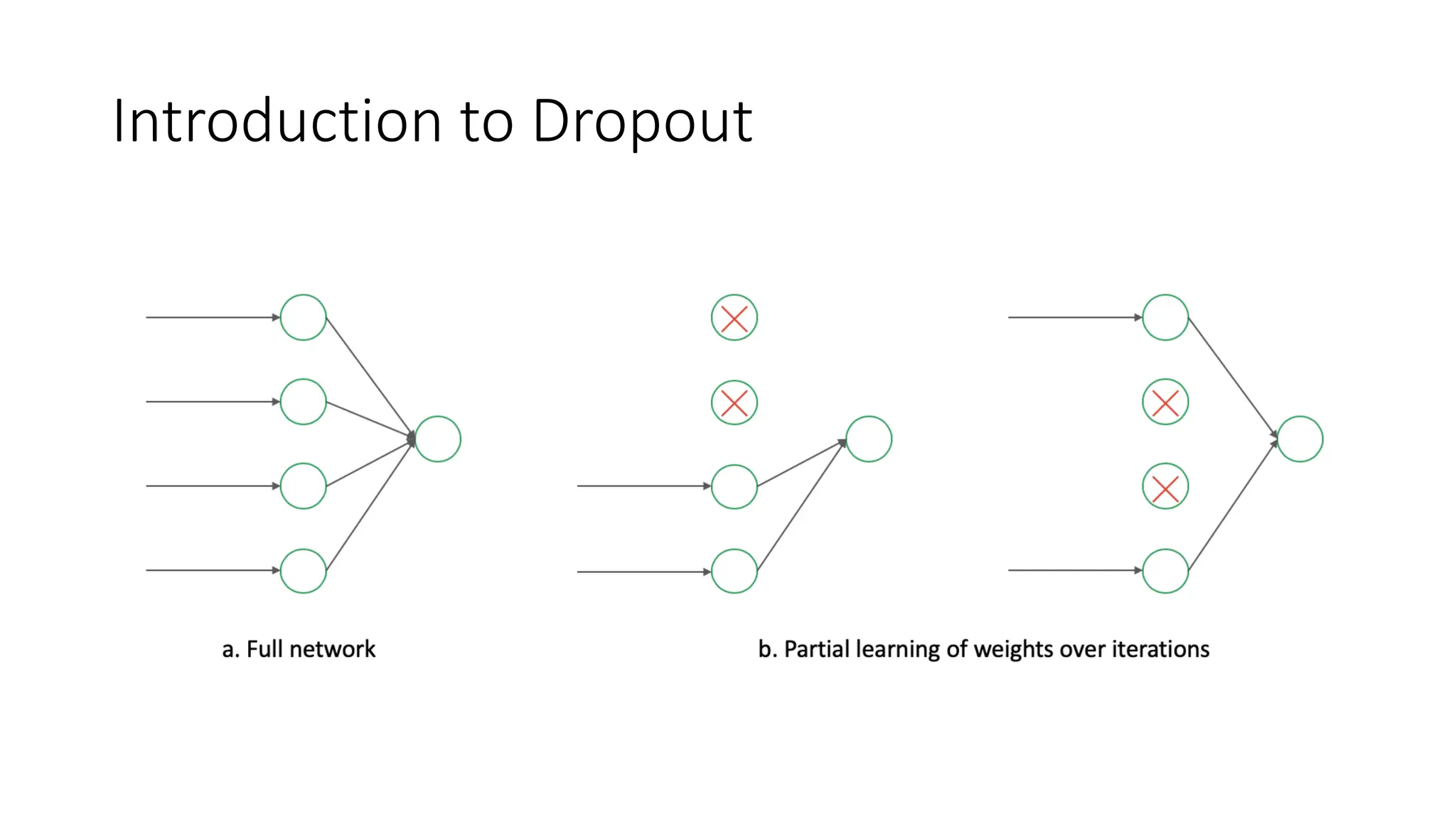
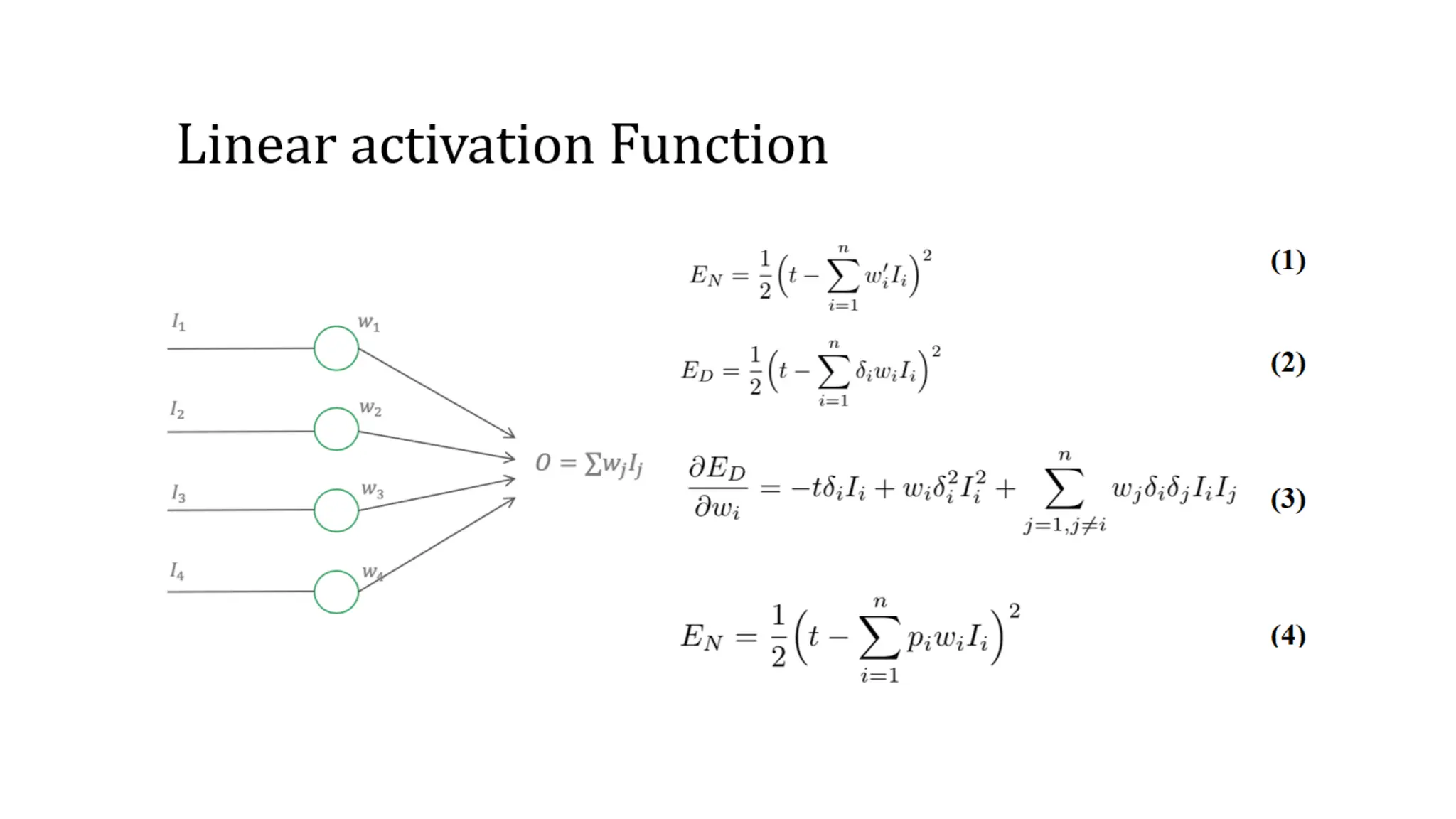
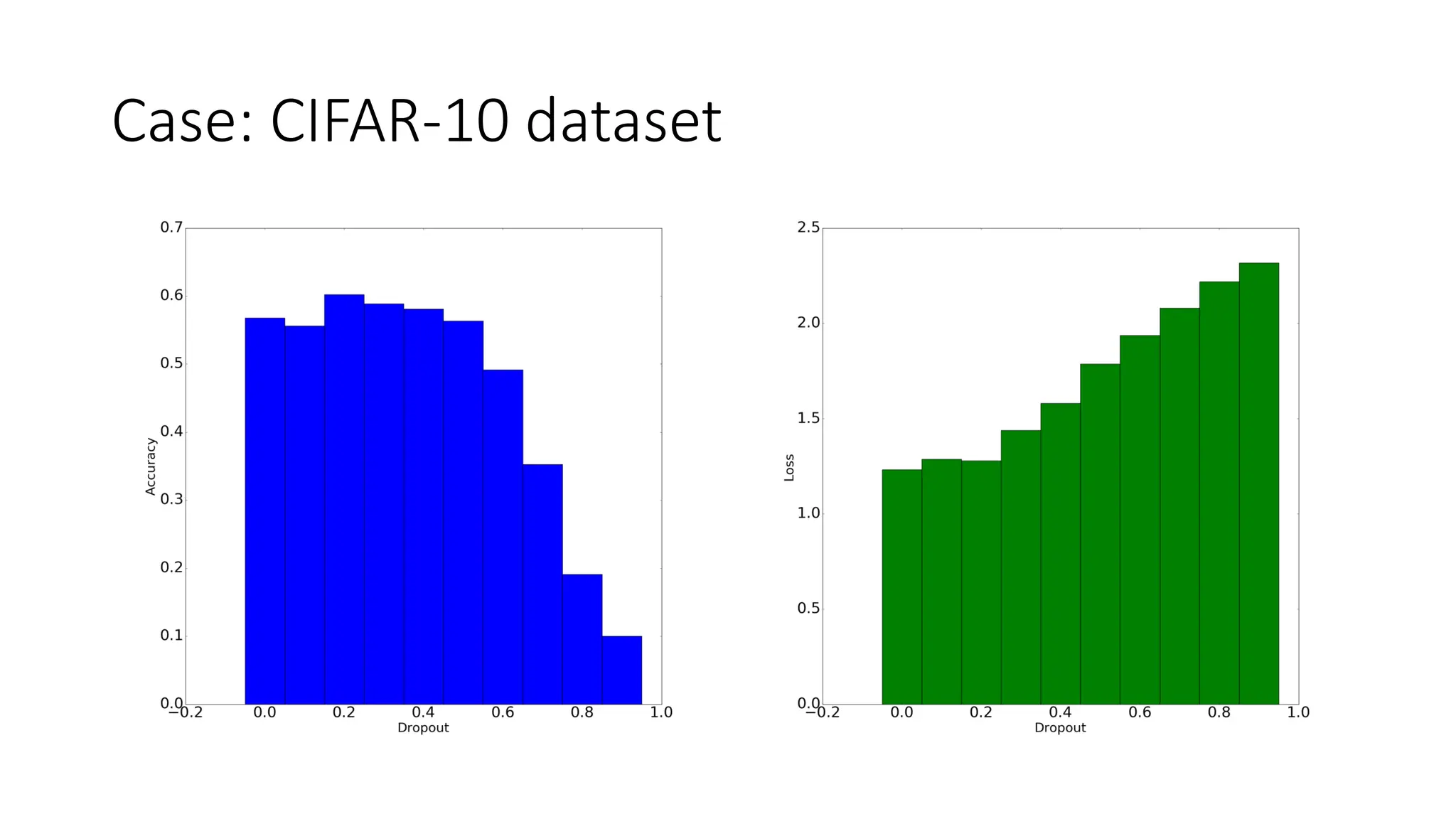
Dataset augmentation and regularization techniques like dropout and early stopping can help reduce overfitting in neural networks. Dropout randomly ignores neurons during training to prevent co-adaptation. Early stopping monitors validation performance and stops training once performance starts degrading to prevent overfitting. These techniques were applied in a case study using the CIFAR-10 dataset, where a convolutional neural network with dropout and early stopping achieved improved generalization performance compared to using no regularization.




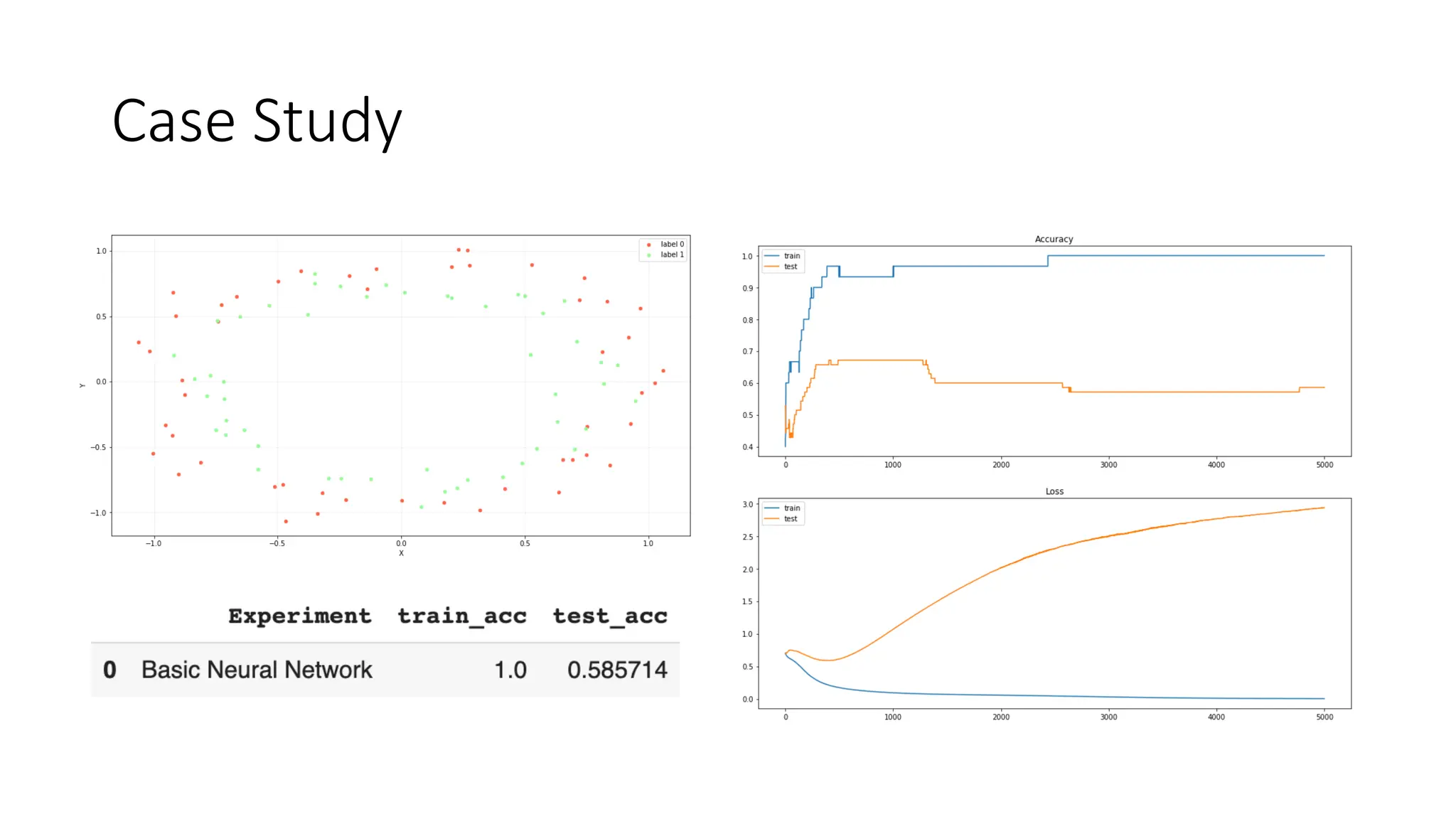





![Cont.,
• Early Stopping protect against over
fitting and needs considerably less
number of Epoch to train.
• A callback is a powerful tool to
customize the behavior of a Keras
model during training, evaluation, or
inference
• Callback-internal states and statistics
of a model during training
• Starting/ Stopping of the training
process
• End of epochs/ end of training a
batch.
• Monitor, patience, mode,
restore_best_weights
callback =
tf.keras.callbacks.EarlyStopping(patie
nce=4, restore_best_weights=True)
history1 = model2.fit(trn_images,
trn_labels,
epochs=50,validation_data=(valid_image
s, valid_labels),callbacks=[callback])](https://image.slidesharecdn.com/datasetaugmentation-240305143045-b94514e6/75/Dataset-Augmentation-and-machine-learning-pdf-19-2048.jpg)