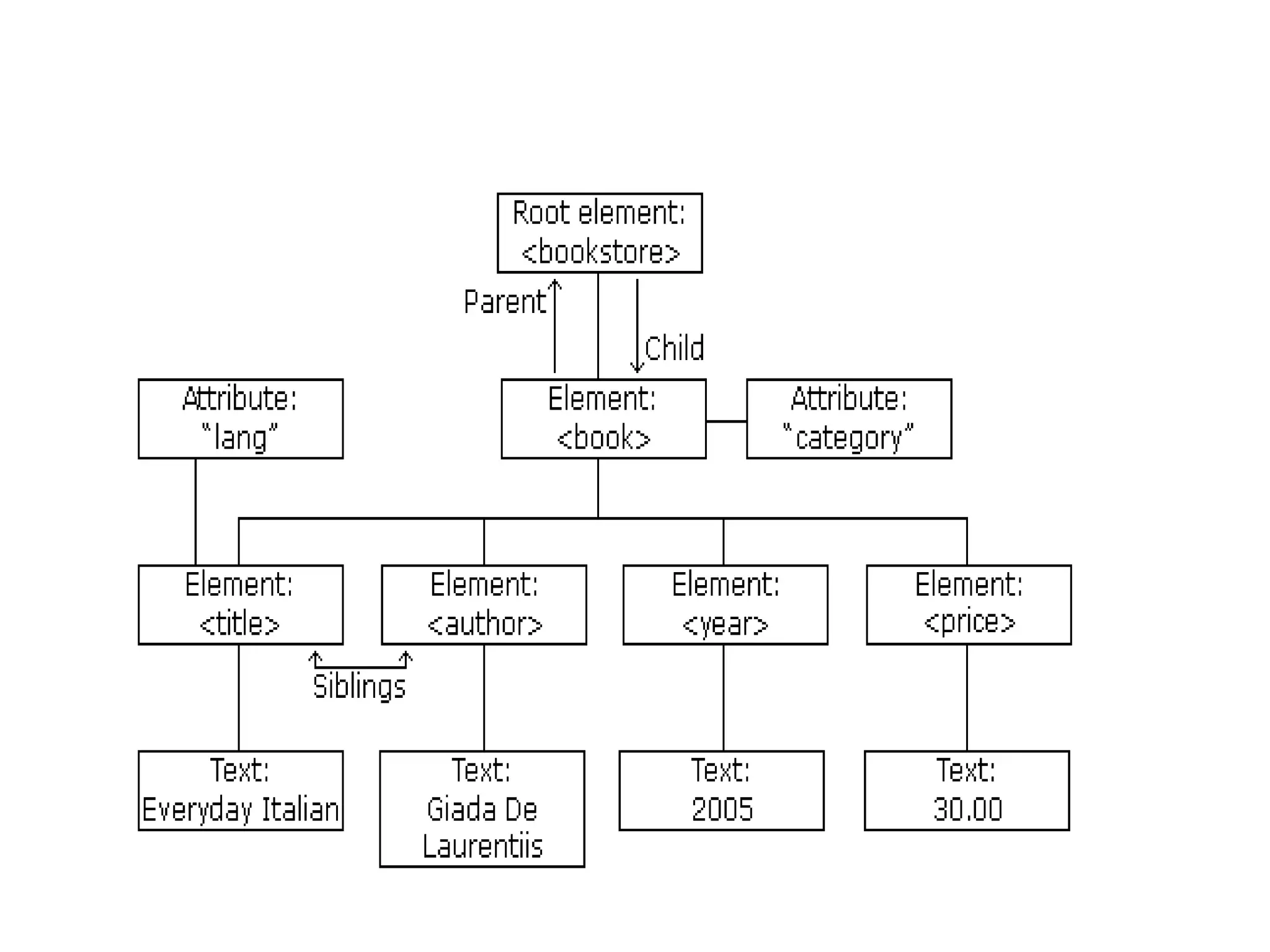
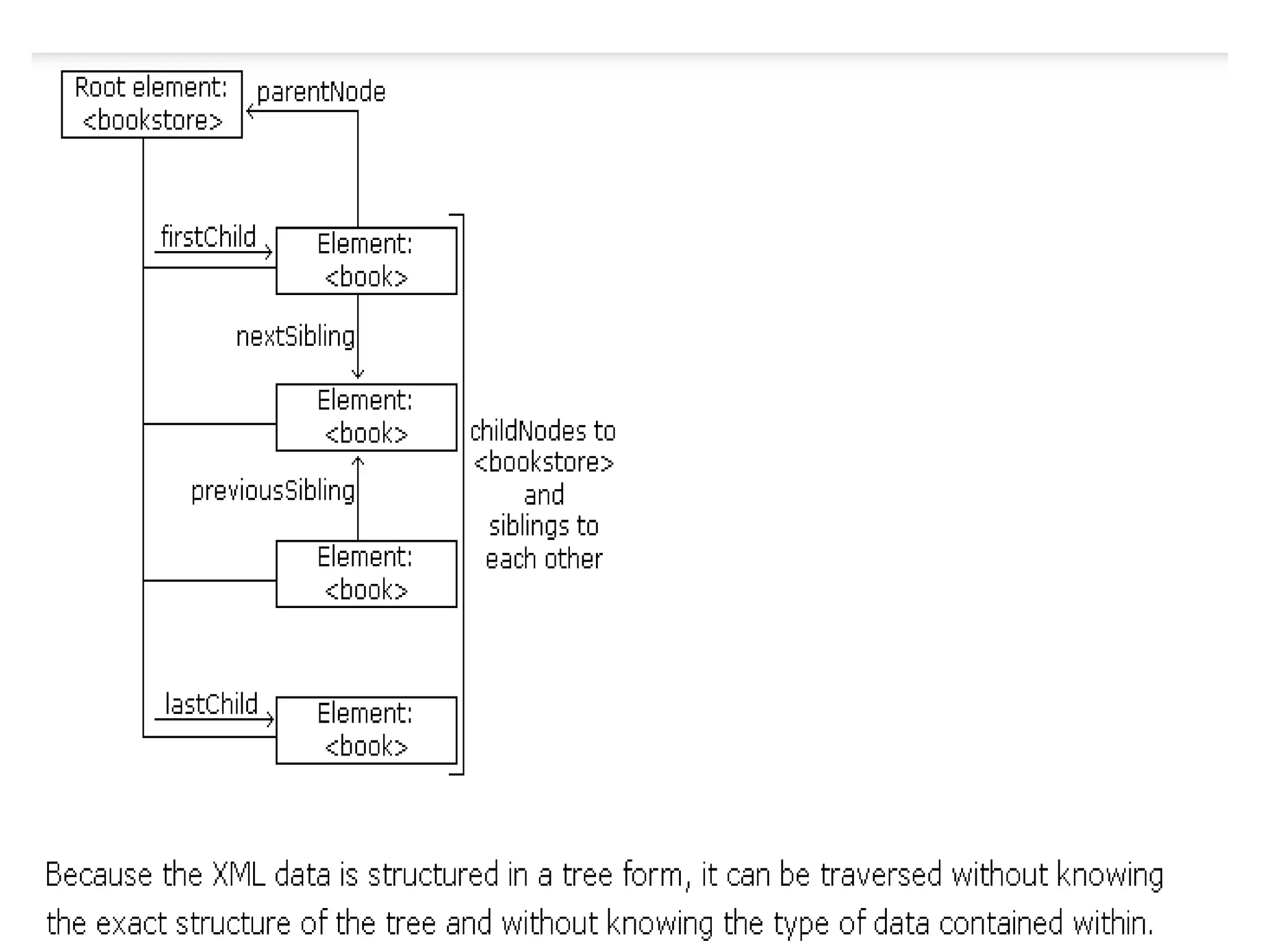
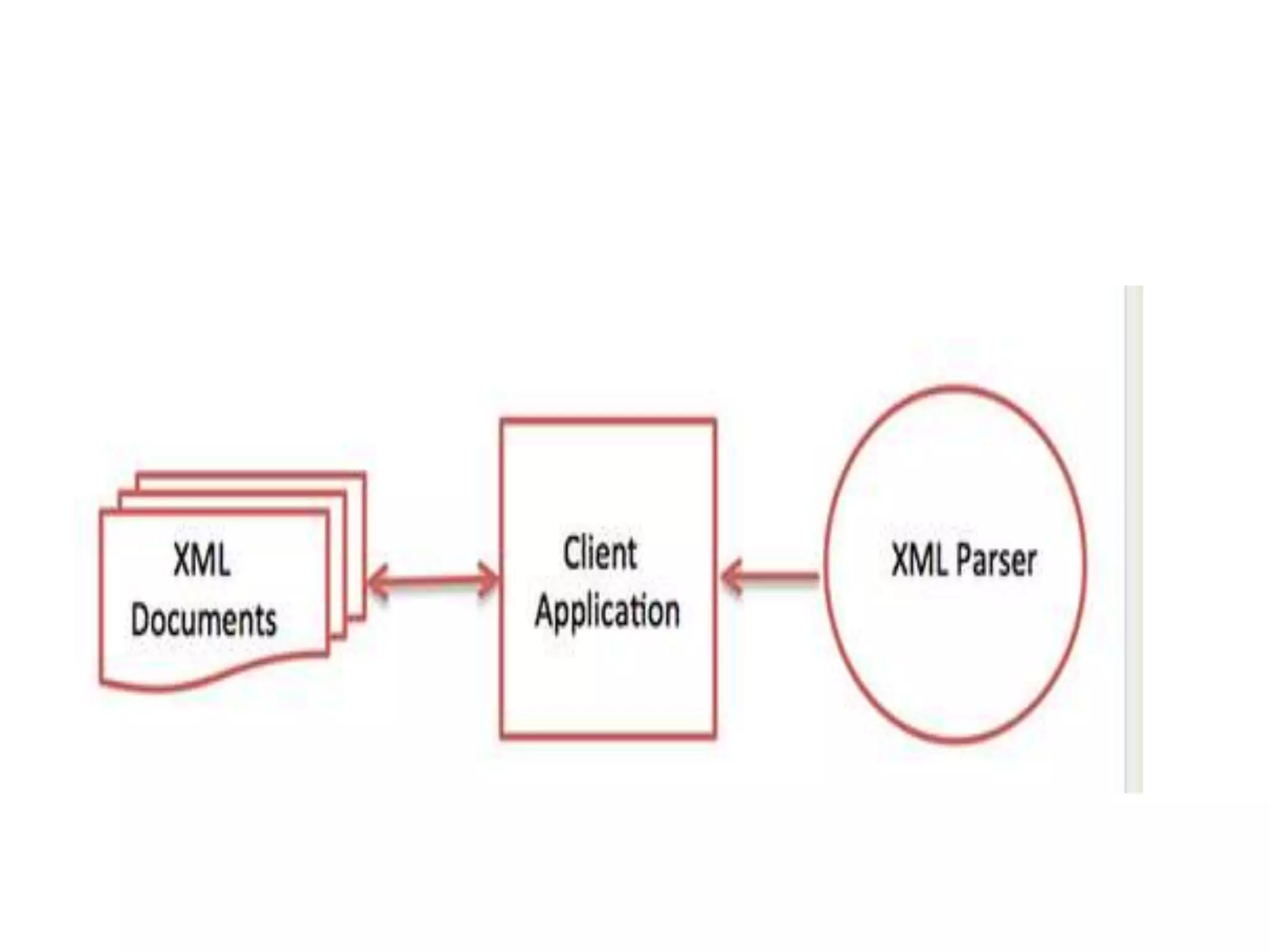
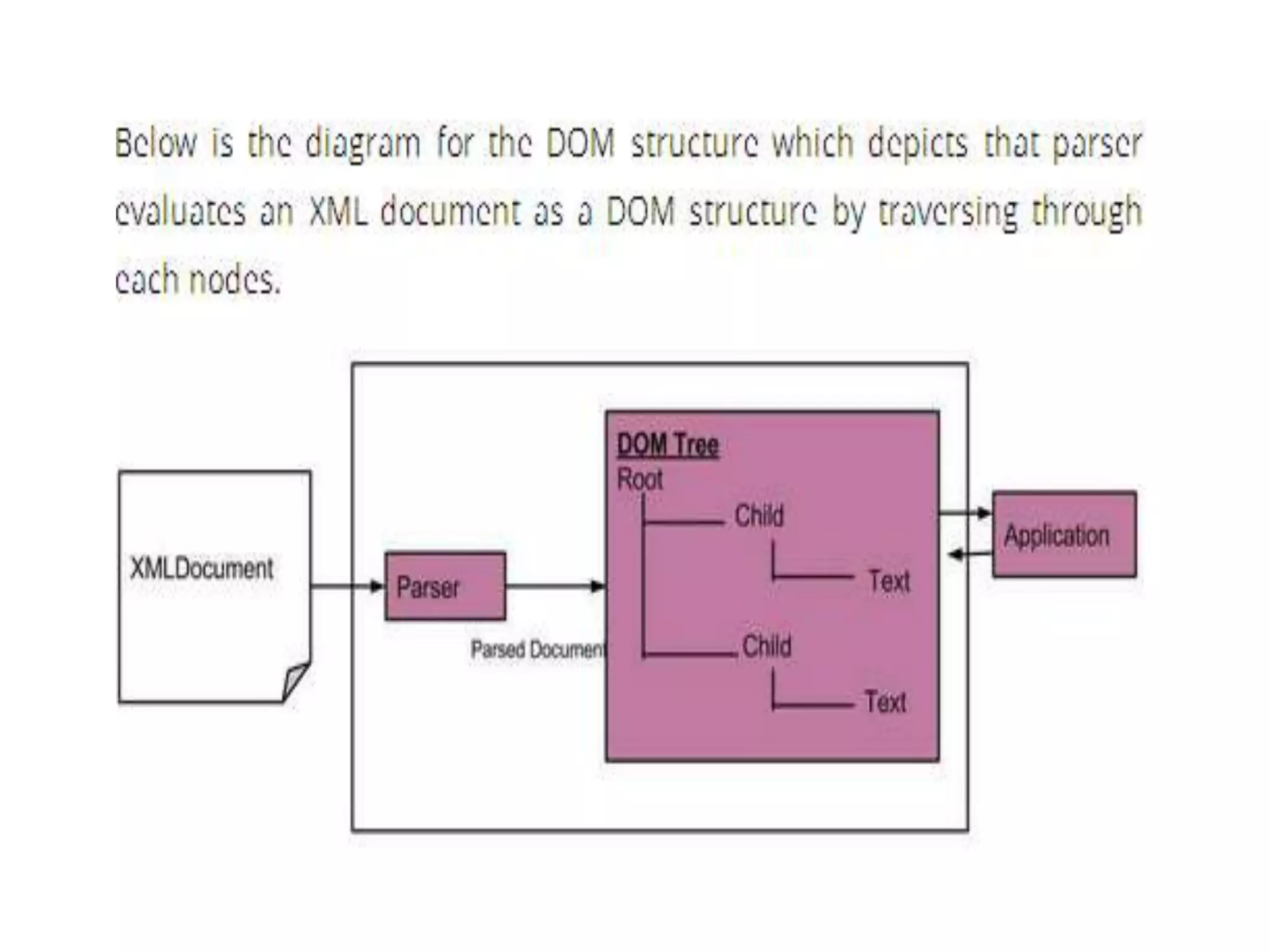
The document provides information about the XML DOM (Document Object Model). It defines the XML DOM as a programming interface that represents an XML document as a tree structure. The XML DOM defines a standard for accessing XML documents in a way that is independent of the programming language. Key points covered include:
- The XML DOM allows programmers to build and manipulate XML documents using JavaScript.
- The DOM represents an XML document as nodes that can be traversed and manipulated.
- Common DOM properties and methods allow accessing and modifying the XML tree structure programmatically.






















![PROGRAM 1
<!DOCTYPE html>
<html>
<head>
<script src="loadxmldoc.js"></script>
</head>
<body>
<script>
xmlDoc=loadXMLDoc("books.xml");
document.write(xmlDoc.getElementsByTagName("title")[0].childNodes[0].nodeValue + "<br>");
document.write(xmlDoc.getElementsByTagName("author")[0].childNodes[0].nodeValue + "<br>");
document.write(xmlDoc.getElementsByTagName("year")[0].childNodes[0].nodeValue);
</script>
</body>
</html>
OUTPUT:
Everyday Italian
Giada De Laurentiis
2005](https://image.slidesharecdn.com/unitivxmldom-220306134507/75/Unit-iv-xml-dom-27-2048.jpg)





![PROGRAM2
<!DOCTYPE html>
<html>
<head>
<script src="loadxmldoc.js"></script>
</head>
<body>
<script>
xmlDoc=loadXMLDoc("books.xml");
x=xmlDoc.getElementsByTagName("title");
for (i=0;i<x.length;i++)
{
document.write(x[i].childNodes[0].nodeValue);
document.write("<br>");
}
</script>
</body>
</html>
OUTPUT
Everyday Italian
Harry Potter
XQuery Kick Start
Learning XML](https://image.slidesharecdn.com/unitivxmldom-220306134507/75/Unit-iv-xml-dom-34-2048.jpg)
![• Traversing Nodes
• The following code loops through the child nodes, that are also element nodes, of
the root node:
• Example
• var xmlDoc=loadXMLDoc("books.xml");
var x=xmlDoc.documentElement.childNodes;
for (i=0;i<x.length;i++)
{
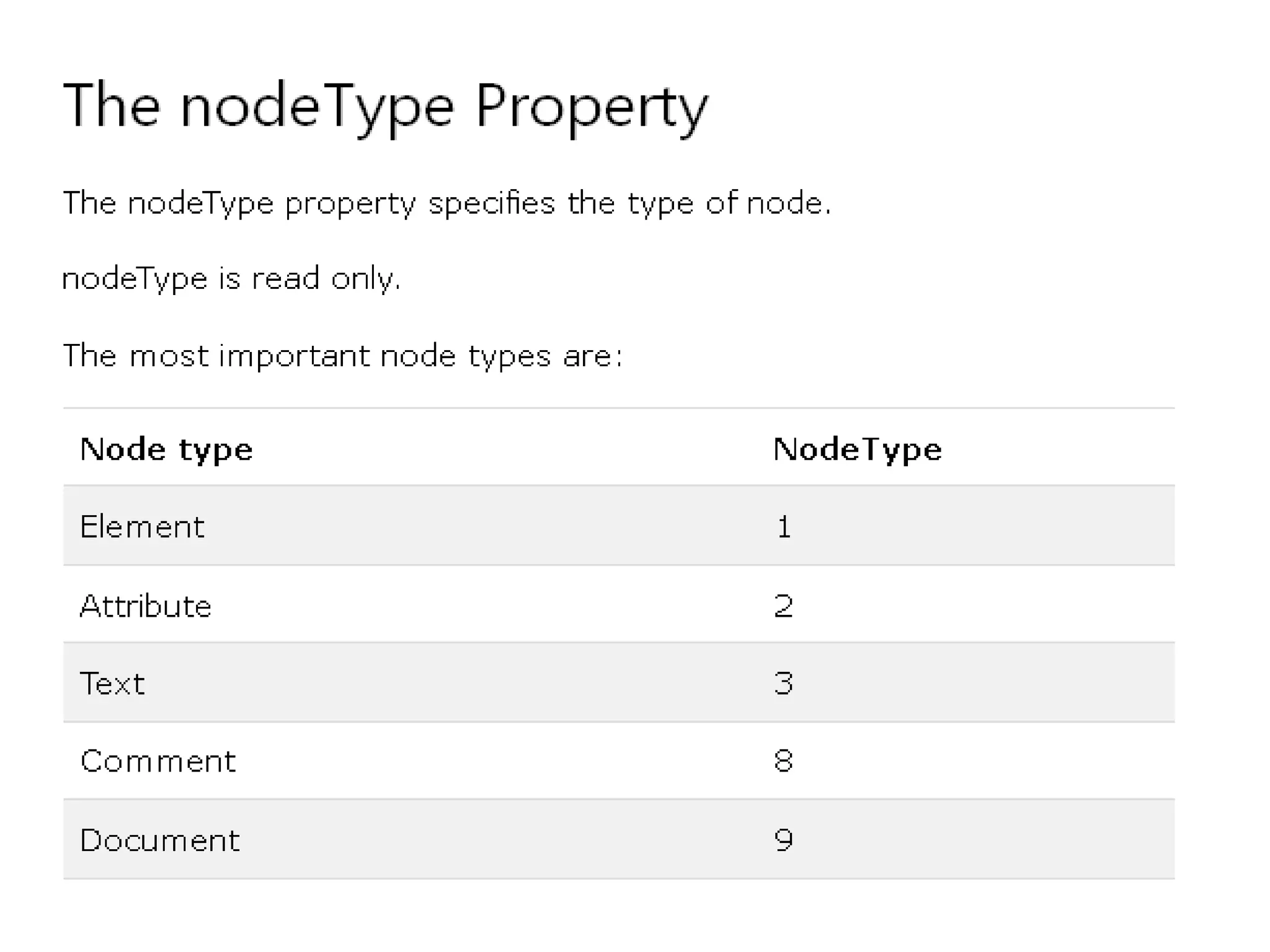
// Process only element nodes (type 1)
if (x[i].nodeType==1)
{
document.write(x[i].nodeName);
document.write("<br>");
}
}
OUTPUT
book
book
book
book](https://image.slidesharecdn.com/unitivxmldom-220306134507/75/Unit-iv-xml-dom-35-2048.jpg)
![• Navigating Node Relationships
• The following code navigates the node tree using the node relationships:
<!DOCTYPE html>
<html>
<head>
<script src="loadxmldoc.js"></script>
</head>
<body>
<script>
xmlDoc=loadXMLDoc("books.xml");
x=xmlDoc.getElementsByTagName("book")[0].childNodes;
y=xmlDoc.getElementsByTagName("book")[0].firstChild;
for (i=0;i<x.length;i++)
{
if (y.nodeType==1)
{//Process only element nodes (type 1)
document.write(y.nodeName + "<br>");
}
y=y.nextSibling;
}
</script>
</body>
</html>
Output
title
author
year
price](https://image.slidesharecdn.com/unitivxmldom-220306134507/75/Unit-iv-xml-dom-36-2048.jpg)



![Get the Value of an Element
• The following code retrieves the text node value of the first <title> element:
Example
<!DOCTYPE html>
<html>
<head>
<script src="loadxmldoc.js"></script>
</head>
<body>
<script>
xmlDoc=loadXMLDoc("books.xml");
x=xmlDoc.getElementsByTagName("title")[0]
y=x.childNodes[0];
document.write(y.nodeValue);
</script>
</body>
</html>
OUTPUT
Everyday Italian](https://image.slidesharecdn.com/unitivxmldom-220306134507/75/Unit-iv-xml-dom-40-2048.jpg)
![• The getAttribute() method returns an attribute value.
<!DOCTYPE html>
<html>
<head>
<script src="loadxmldoc.js">
</script>
</head>
<body>
<script>
xmlDoc=loadXMLDoc("books.xml");
x=xmlDoc.getElementsByTagName('book');
for (i=0;i<x.length;i++)
{
document.write(x[i].getAttribute('category'));
document.write("<br>");
}
</script>
</body>
</html>
Output
cooking
children
web
web](https://image.slidesharecdn.com/unitivxmldom-220306134507/75/Unit-iv-xml-dom-41-2048.jpg)
![The getAttributeNode() method
returns an attribute node.
<!DOCTYPE html>
<html>
<head>
<script src="loadxmldoc.js">
</script>
</head>
<body>
<script>
xmlDoc=loadXMLDoc("books.xml");
x=xmlDoc.getElementsByTagName("title")[0].getAttributeNode("lang");
txt=x.nodeValue;
document.write(txt);
</script>
</body>
</html>
OUTPUT
En](https://image.slidesharecdn.com/unitivxmldom-220306134507/75/Unit-iv-xml-dom-42-2048.jpg)
![Change the Value of an Element
• The following code changes the text node value of the first
<title> element:
Example
<script>
xmlDoc=loadXMLDoc("books.xml");
x=xmlDoc.getElementsByTagName("title")[0].childNodes[0];
x.nodeValue="Easy Cooking";
document.write(x.nodeValue);
</script>
OUTPUT:
• Easy Cooking](https://image.slidesharecdn.com/unitivxmldom-220306134507/75/Unit-iv-xml-dom-43-2048.jpg)
![Change an Attribute Using
setAttribute()
• The setAttribute() method changes the value of an existing
attribute, or creates a new attribute.
• The following code changes the category attribute of the <book>
element:
Example
<script>
xmlDoc=loadXMLDoc("books.xml");
x=xmlDoc.getElementsByTagName('book');
x[0].setAttribute("category","food");
document.write(x[0].getAttribute("category"));
</script>
OUTPUT:
FOOD](https://image.slidesharecdn.com/unitivxmldom-220306134507/75/Unit-iv-xml-dom-44-2048.jpg)

![EXAMPLE
//create a book element, title element and a text node
newNode=xmlDoc.createElement("book");
newTitle=xmlDoc.createElement("title");
newText=xmlDoc.createTextNode("A Notebook");
//add the text node to the title node,
newTitle.appendChild(newText);
//add the title node to the book node
newNode.appendChild(newTitle);
y=xmlDoc.getElementsByTagName("book")[0]
//replace the first book node with the new node
x.replaceChild(newNode,y);
z=xmlDoc.getElementsByTagName("title");
for (i=0;i<z.length;i++)
{
document.write(z[i].childNodes[0].nodeValue);
document.write("<br>");
}
</script>
</body>
</html>](https://image.slidesharecdn.com/unitivxmldom-220306134507/75/Unit-iv-xml-dom-46-2048.jpg)