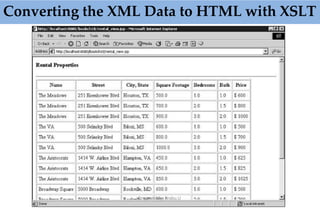
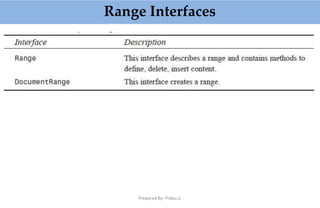
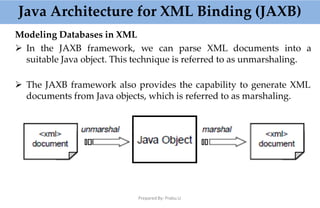
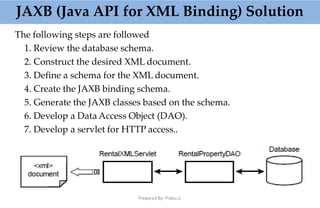
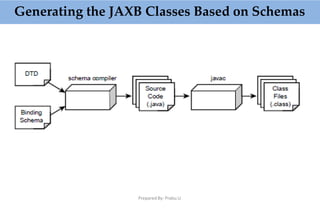
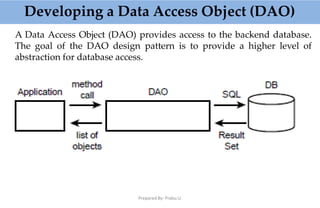
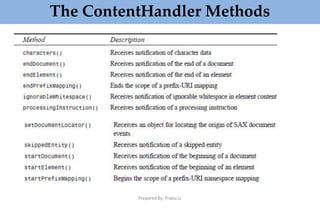
This document provides an overview of parsing XML using SAX (Simple API for XML). It describes what SAX is, how it works by sending events to registered handlers, and compares it to DOM. SAX is an event-based API that parses XML documents sequentially by notifying applications of elements and data, while DOM loads the entire document into memory at once. SAX is simpler and uses less memory than DOM, making it better for processing large documents or on resource-constrained devices.












![Prepared By: Prabu.U
public static void main(String args[]) throws Exception
{
SimpleWalker sw = new SimpleWalker();
sw.parse(args[0]);
sw.printAllElements();
}
} // class SimpleWalker](https://image.slidesharecdn.com/buildingxmlbasedapplications-180322042009-240214134154-ef503dd6/85/buildingxmlbasedapplications-180322042009-pptx-15-320.jpg)









































![Working with SAX
Prepared By: Prabu.U
import java.io.*;
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import javax.xml.parsers.*;
public class SAXDemo extends DefaultHandler
{
public void startDocument()
{
System.out.println(“***Start of Document***”);
}
public void endDocument()
{
System.out.println(“***End of Document***”);
}
public void startElement(String uri, String
localName,
String qName, Attributes attributes)
{
public void startElement(String uri, String localName,
String qName,Attributes attributes)
{
System.out.print(“<” + qName);
int n = attributes.getLength();
for (int i=0; i<n; i+=1)
{
System.out.print(“ “ + attributes.getQName(i) +
“=’” + attributes.getValue(i) + “‘“);
}
System.out.println(“>”);
}
public void characters(char[] ch, int start, int length)
{
System.out.println(new String(ch, start,
length).trim());
}
public void endElement(String namespaceURI, String
localName, String qName) throws SAXException
{
System.out.println(“</” + qName + “>”);
}](https://image.slidesharecdn.com/buildingxmlbasedapplications-180322042009-240214134154-ef503dd6/85/buildingxmlbasedapplications-180322042009-pptx-62-320.jpg)
![Working with SAX
Prepared By: Prabu.U
public static void main(String args[]) throws
Exception
{
if (args.length != 1)
{
System.err.println(“Usage: java SAXDemo <xml-
file>”);
System.exit(1);
}
SAXDemo handler = new SAXDemo();
SAXParserFactory factory =
SAXParserFactory.newInstance();
SAXParser parser = factory.newSAXParser();
parser.parse(new File(args[0]), handler);
}
}](https://image.slidesharecdn.com/buildingxmlbasedapplications-180322042009-240214134154-ef503dd6/85/buildingxmlbasedapplications-180322042009-pptx-63-320.jpg)

















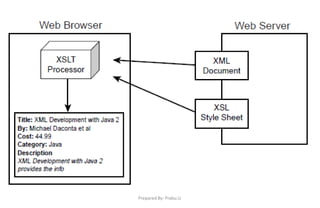

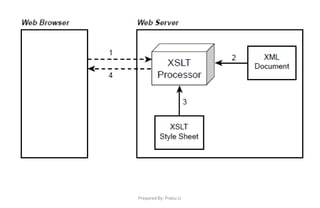


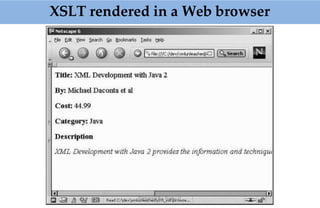



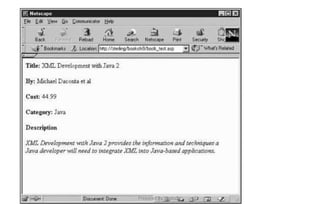




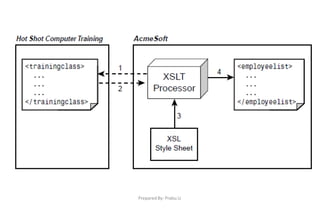













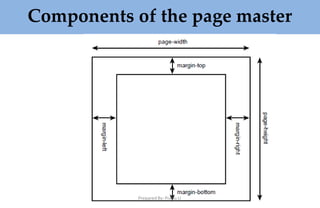
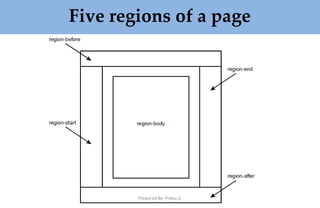

















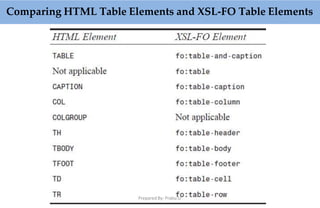





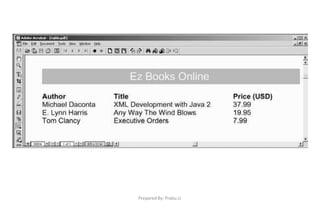
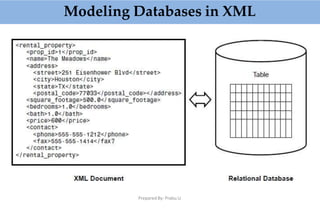

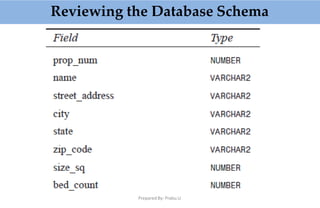
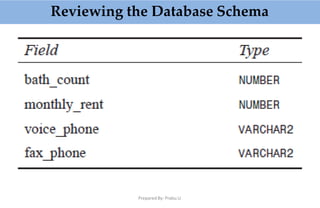








![Prepared By: Prabu.U
public static void main(String[] args)
{
try
{
TestApp myApp = new TestApp();
myApp.process();
}
catch (Exception exc)
{
exc.printStackTrace();
}
}](https://image.slidesharecdn.com/buildingxmlbasedapplications-180322042009-240214134154-ef503dd6/85/buildingxmlbasedapplications-180322042009-pptx-153-320.jpg)