Download as PDF, PPTX












![Single Convolution Layer
= 𝑅𝑒𝐿𝑈 + 𝑏1
*
= 𝑅𝑒𝐿𝑈 + 𝑏2
𝑎[0]
𝑊[1]
𝑧[1]
= 𝑊[1]
𝑎[0]
+ 𝑏[1]
𝑎[1]
= 𝑔(𝑧[1]
)](https://image.slidesharecdn.com/understanding-cnn-181215053311/85/Understanding-cnn-77-320.jpg)



![CNN Example # 1 (Basic)
𝑎[0] 𝑎[1] 𝑎[2]
𝑎[3]
𝑛 𝐻
[0]
∗ 𝑛 𝑊
0
∗ 𝑛 𝐶
[0]
39 ∗ 39 ∗ 3
𝑓[1]
= 3
𝑠[1]
= 1
𝑝[1]
= 0
10 𝑓𝑖𝑙𝑡𝑒𝑟𝑠
𝑛 + 2𝑝 − 𝑓
𝑠
+ 1
=
39+2∗0−3
1
+ 1
= 37
𝑛 𝐻
[1]
∗ 𝑛 𝑊
1
∗ 𝑛 𝐶
[1]
37 ∗ 37 ∗ 10
𝑓[2]
= 5
𝑠[2]
= 2
𝑝[2]
= 0
20 𝑓𝑖𝑙𝑡𝑒𝑟𝑠
𝑛 𝐻
[2]
∗ 𝑛 𝑊
2
∗ 𝑛 𝐶
[2]
17 ∗ 17 ∗ 20
𝑛 + 2𝑝 − 𝑓
𝑠
+ 1
=
37+2∗0−5
2
+ 1
= 17
𝑓[3]
= 5
𝑠[3]
= 2
𝑝[3]
= 0
40 𝑓𝑖𝑙𝑡𝑒𝑟𝑠
𝑛 + 2𝑝 − 𝑓
𝑠
+ 1
=
17+2∗0−5
2
+ 1
= 7
𝑛 𝐻
[3]
∗ 𝑛 𝑊
3
∗ 𝑛 𝐶
[3]
7 ∗ 7 ∗ 40
7 ∗ 7 ∗ 40
= 1960
vectorize
𝑦
Logistic
Regression /
Softmax](https://image.slidesharecdn.com/understanding-cnn-181215053311/85/Understanding-cnn-81-320.jpg)
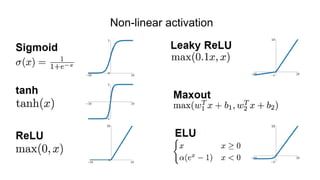

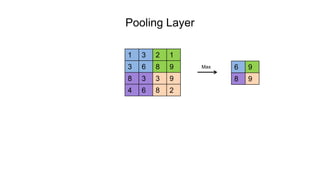
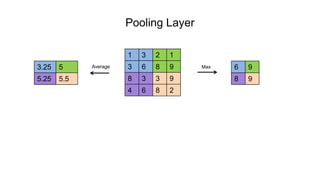
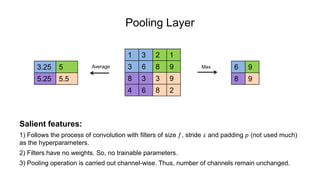

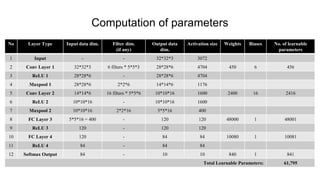
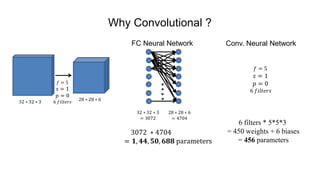
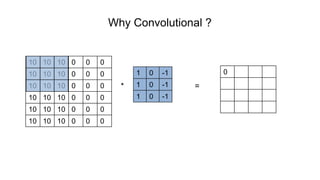
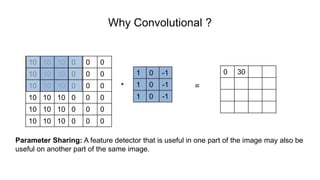

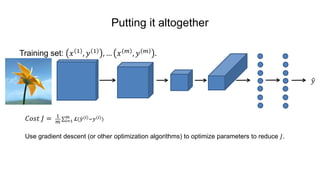

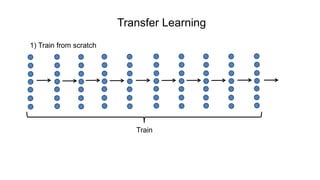
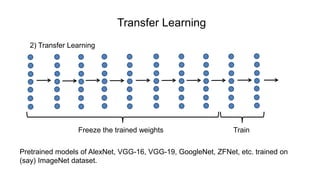





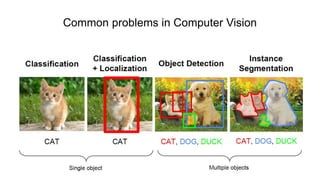
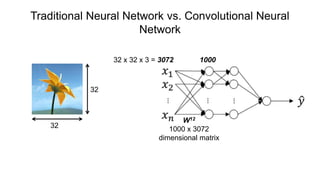
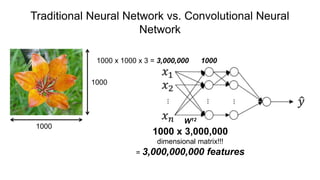
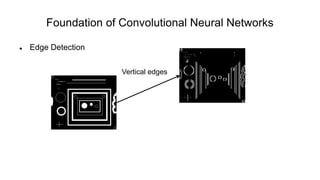
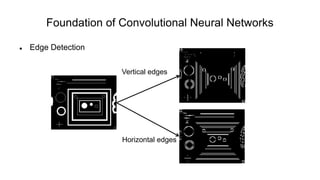
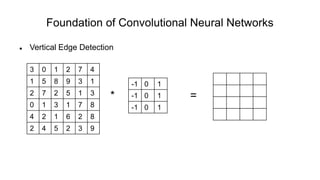
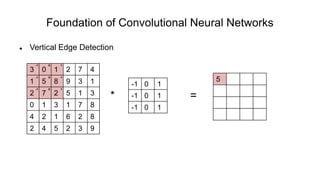
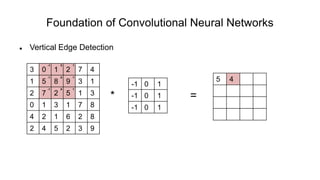
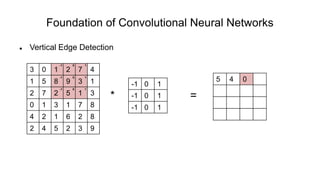
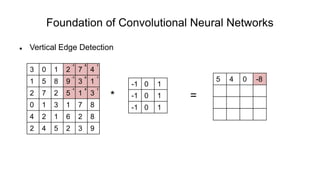
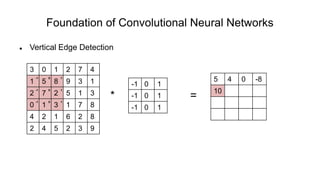
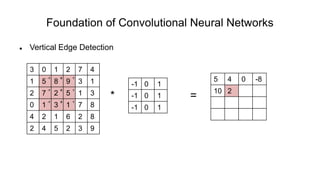
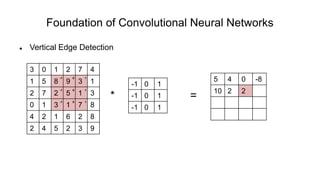
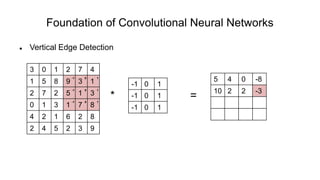
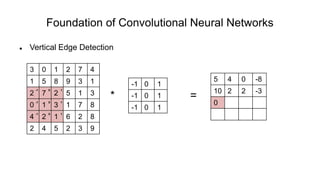
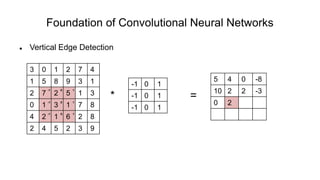
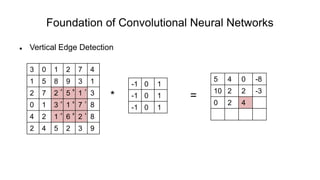
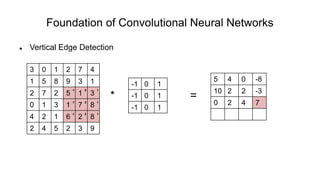
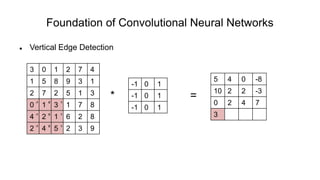
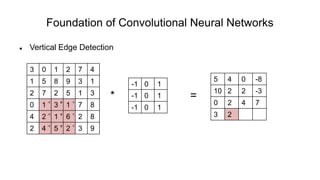
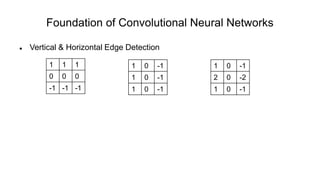
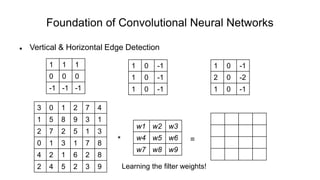
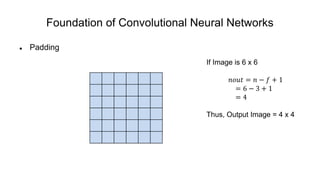
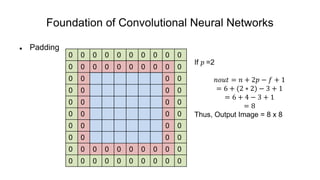
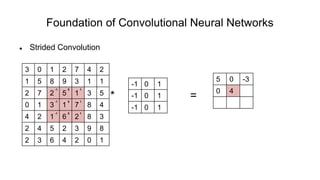
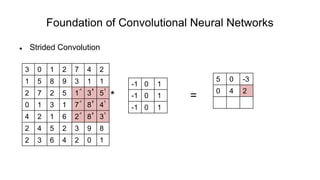
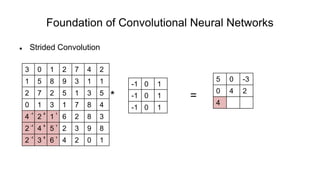
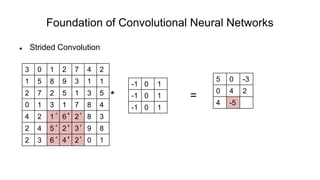
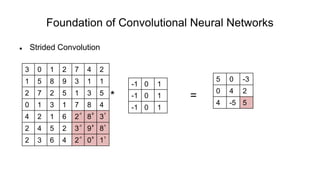
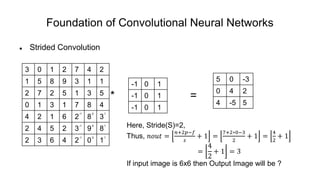
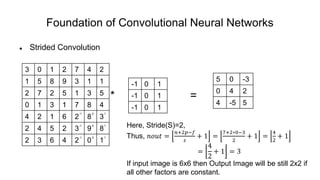
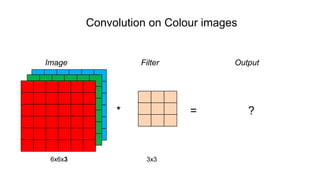
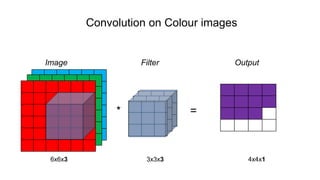
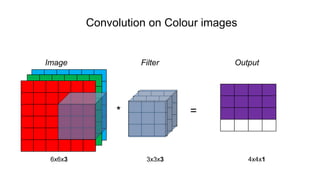
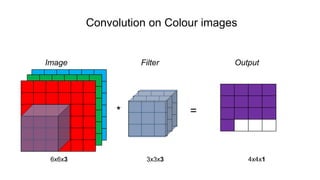
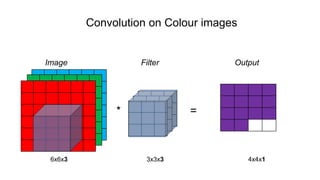
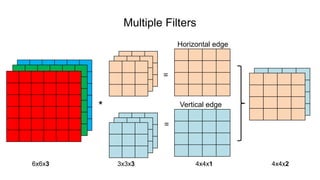
The document discusses the significance of convolutional neural networks (CNNs) in computer vision, highlighting their use in image recognition, video analysis, and more, implemented by major companies like Google and Facebook. It contrasts traditional neural networks with CNNs, focusing on CNNs' ability to handle spatial data and large images more efficiently. The presentation emphasizes the fundamental aspects of CNNs, including feature extraction stages, edge detection, and techniques like zero padding to maintain output dimensions.



































































