The document presents a study on generating type representations from text using a Type-to-Vector (t2v) approach, facilitated through distributional semantics and embeddings. It evaluates the properties of t2v, focusing on its ability to support analogical reasoning and measure similarity and relatedness between types. The findings indicate that t2v closely aligns with semantic meaning and can assist in ontology matching tasks.




![ESWC, Crete, 4th June 2018
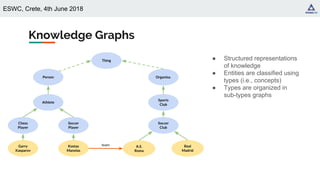
Embeddings for Representing Ontologies
● [Jayawardana+, 2017]
○ Instance-based approach for building word embeddings vectors of the instances in a custom
ontology (legal domain)
○ Embedding used to predict the best representative vector for each ontology type
(cluster-based approach)
○ Conclusions: type vectors are aggregation of entity embeddings
● [Smaili+, 2018]
○ Distributional hypothesis based embeddings for ontological representation
○ Textual document generated by considering axioms in an ontology as sentences of a text
○ Conclusions: uses the structure of the ontology](https://image.slidesharecdn.com/eswc2018typevectorrepresentations-190404082310/85/Type-Vector-Representations-from-Text-DL4KGS-ESWC-2018-8-320.jpg)
![ESWC, Crete, 4th June 2018
State-of-the-Art on Ontological Similarity
● [Rada+, 1989] (path)
○ Shortest path length between concepts
○ Equal path problem: two concepts with the same path length share the same semantic similarity
● [Wu&Palmer, 1994] (wup)
○ Considers the instances depth (based on the Least Common Subsumer - i.e., first common ancestor)
○ Equal depth problem: concepts at the same hierarchical level share the same similarity
● [Zhu&Iglesias, 2017] (wpath)
○ Weighted path length to evaluate the similarity between concepts
○ Exploitation of the statistical Information Content (IC) along with the topology
○ IC computed on text corpora and used to assign higher level to more specific entities
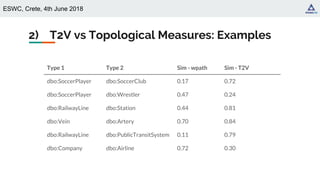
● Topological distant concepts may be highly related (e.g., SoccerPlayer and
SoccerClub)
● Not all siblings pairs are similar in the same way (e.g., is a SoccerPlayer equally
similar to a Wrestler and a BasketballPlayer)](https://image.slidesharecdn.com/eswc2018typevectorrepresentations-190404082310/85/Type-Vector-Representations-from-Text-DL4KGS-ESWC-2018-9-320.jpg)

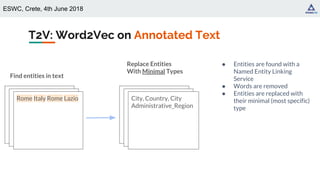
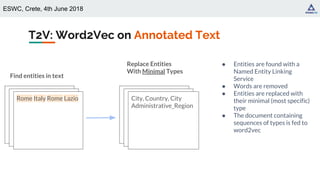
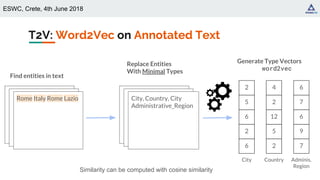
![ESWC, Crete, 4th June 2018
Word2Vec [Mikolov+, 2013]
Well-known algorithm for learning word
representations from an input corpus
Distributional hypothesis: similar words appear in
similar contexts (word-word co-occurrence)
Type to Vector (T2V): generate distributed
representations of types based on type-type
co-occurrence.
cat
black
eats
dog
similar words corresponds
to similar vectors
The big black cat eats its food.
My little black cat sleeps all day.
Sometimes my cat eats too much!
Two hyperparameters:
● Desired embedding size
● Length of the context window](https://image.slidesharecdn.com/eswc2018typevectorrepresentations-190404082310/85/Type-Vector-Representations-from-Text-DL4KGS-ESWC-2018-12-320.jpg)










![ESWC, Crete, 4th June 2018
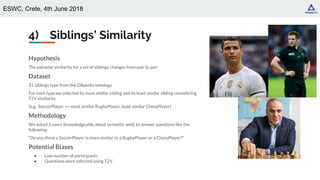
4) Siblings’ Similarity
Outcome
● Agreement between the user using Gwet AC1 [Gwet, 2008] is 0.9 (high agreement)
● Given an input type, users choose as answer the type that is also returned as most similar by
T2V
Examples
Is a Writer more similar to a dbo:Philosopher or a dbo:BusinessPerson?
Is a President more similar to a dbo:PrimeMinister or a dbo:Mayor?
Most challenging question for users
“is a dbo:Skyscraper more similar to a dbo:Hospital or a dbo:Museum?”](https://image.slidesharecdn.com/eswc2018typevectorrepresentations-190404082310/85/Type-Vector-Representations-from-Text-DL4KGS-ESWC-2018-29-320.jpg)