Download as PDF, PPTX







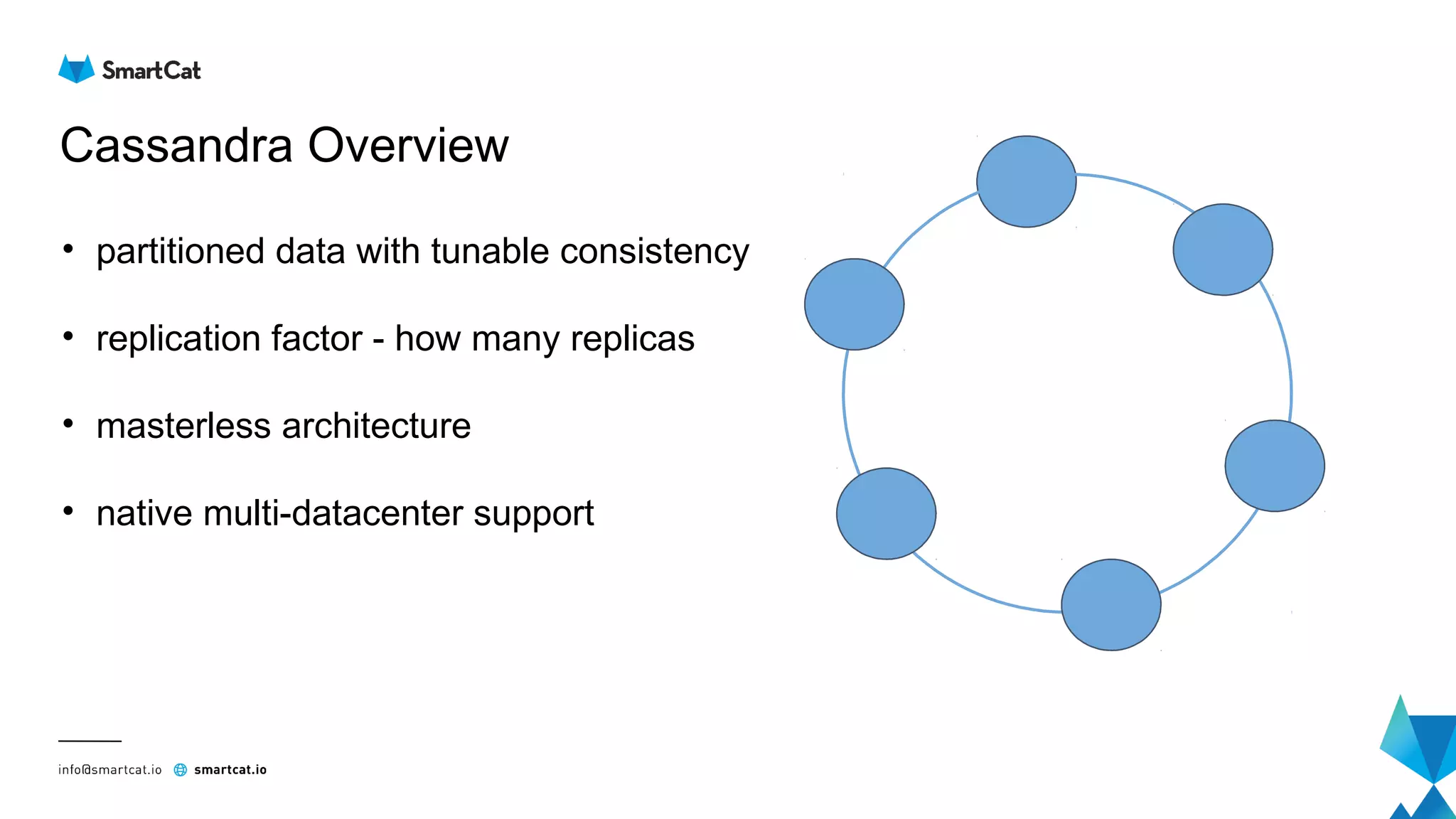
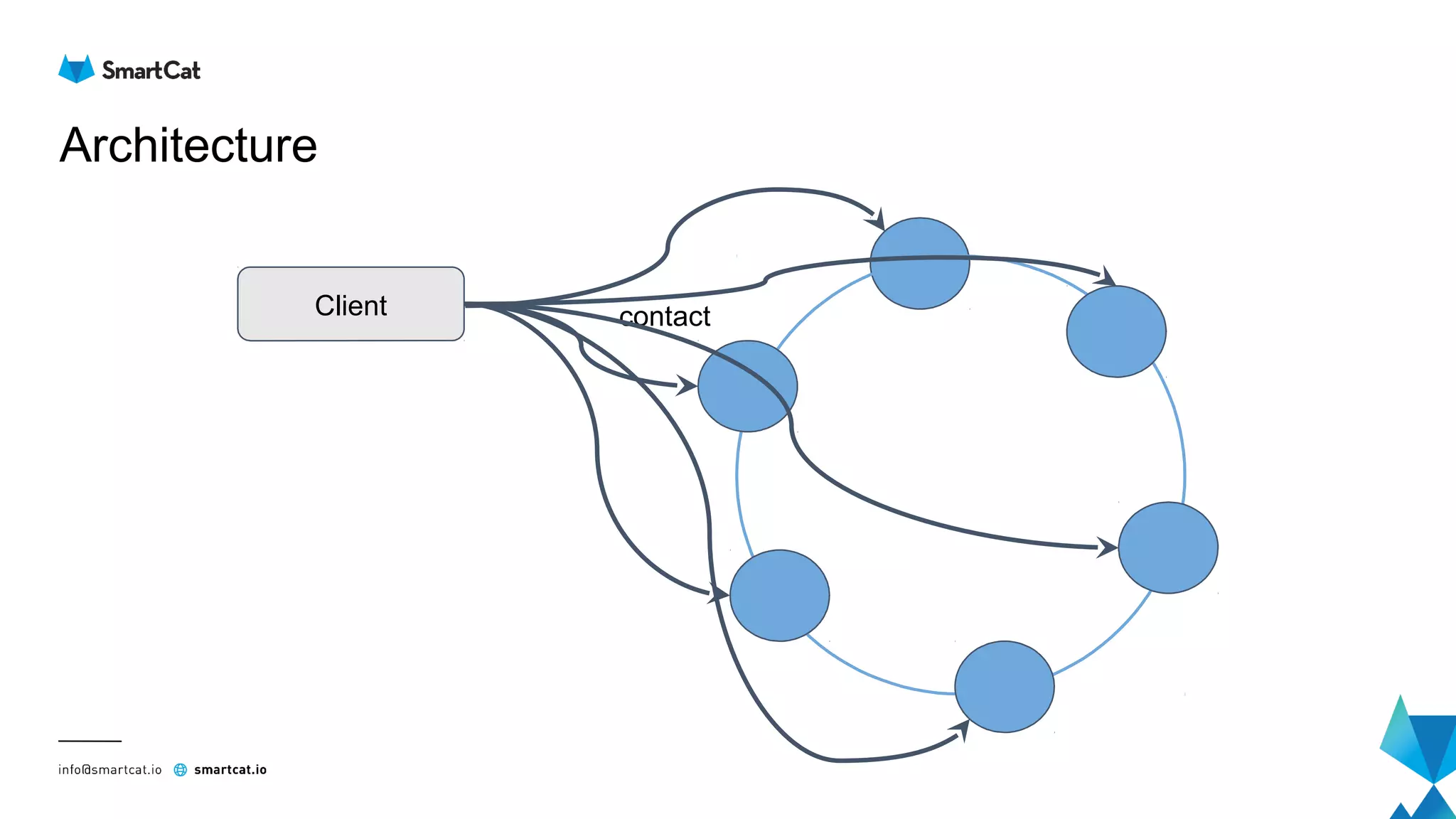
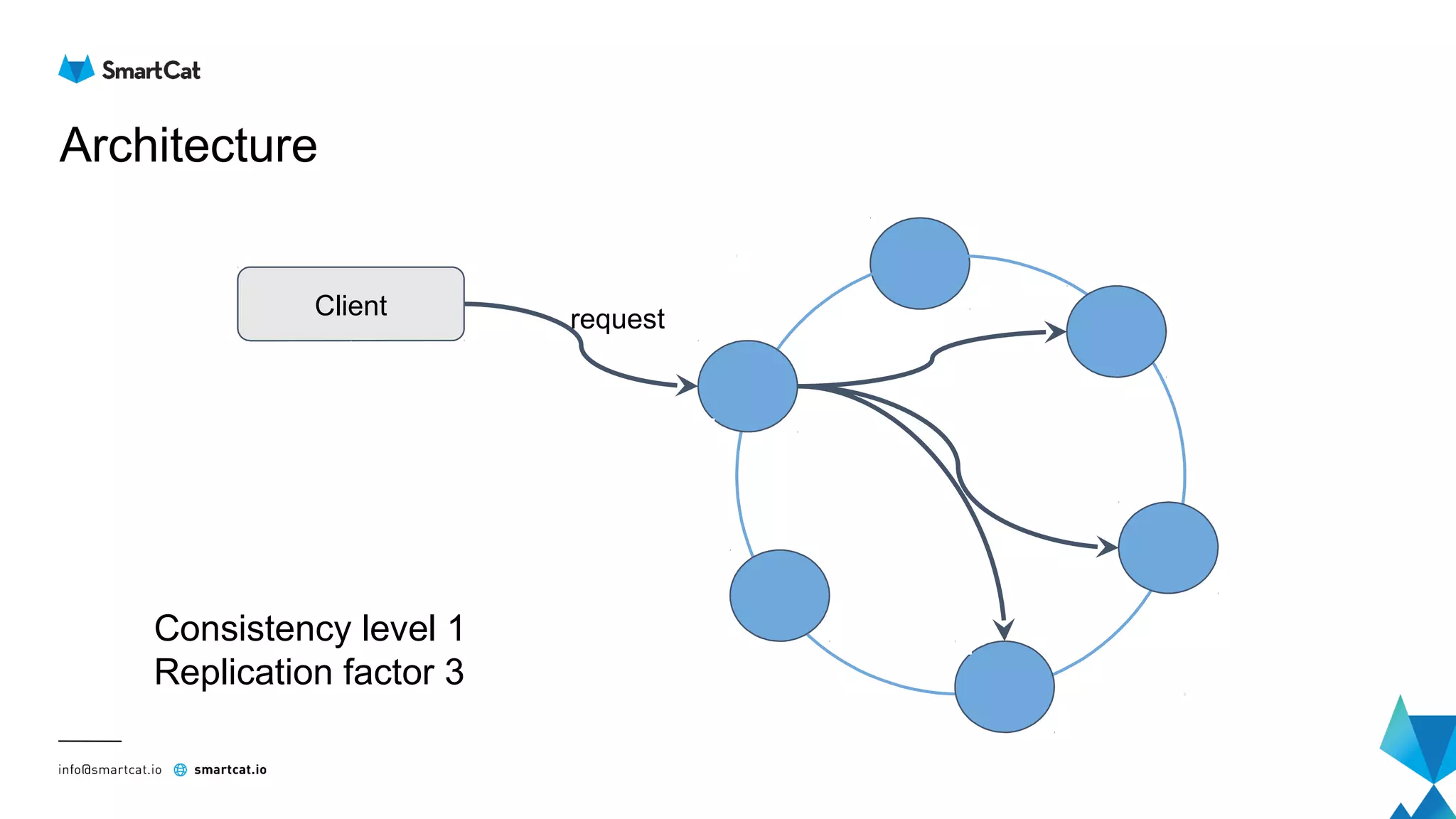
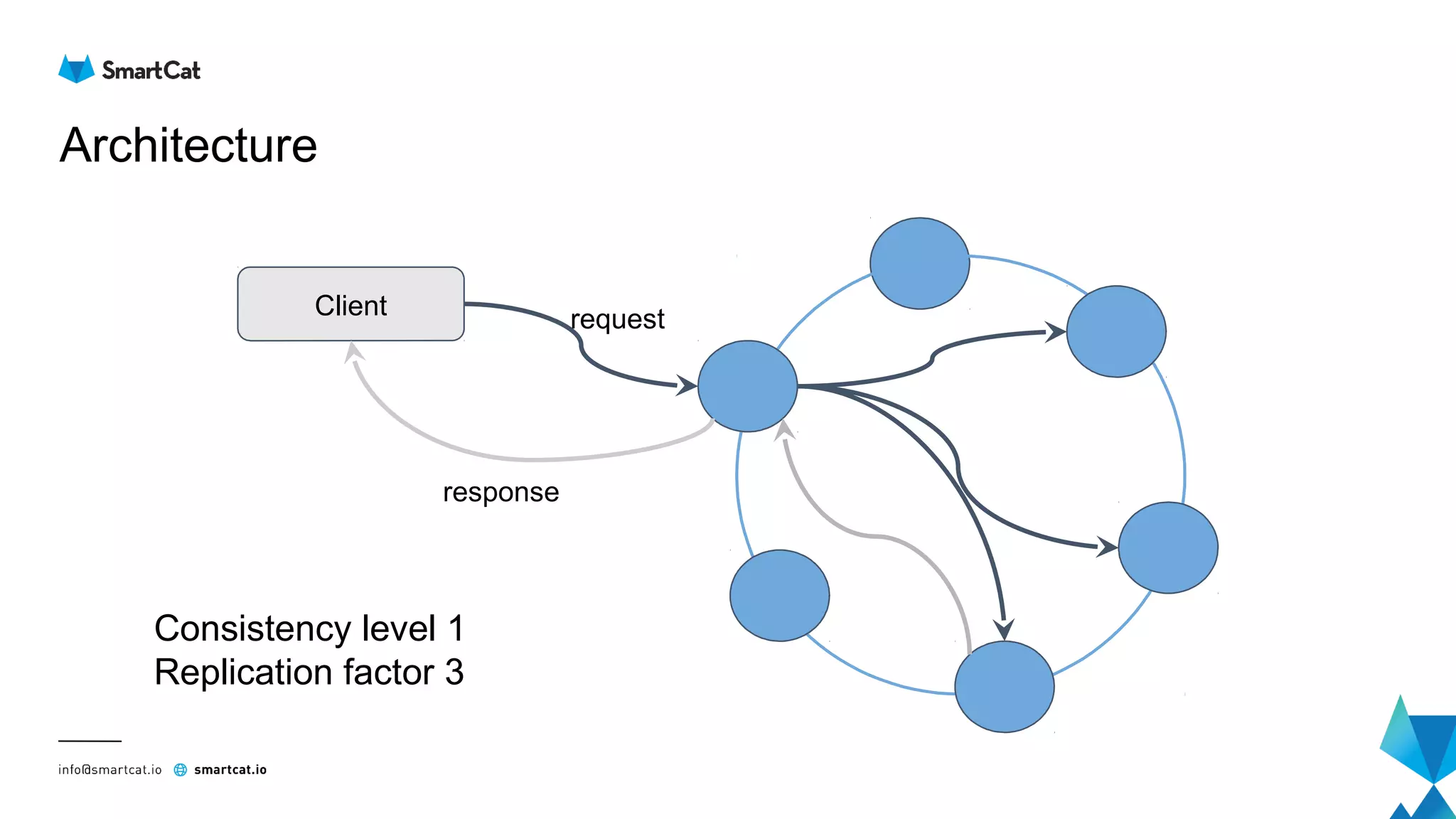
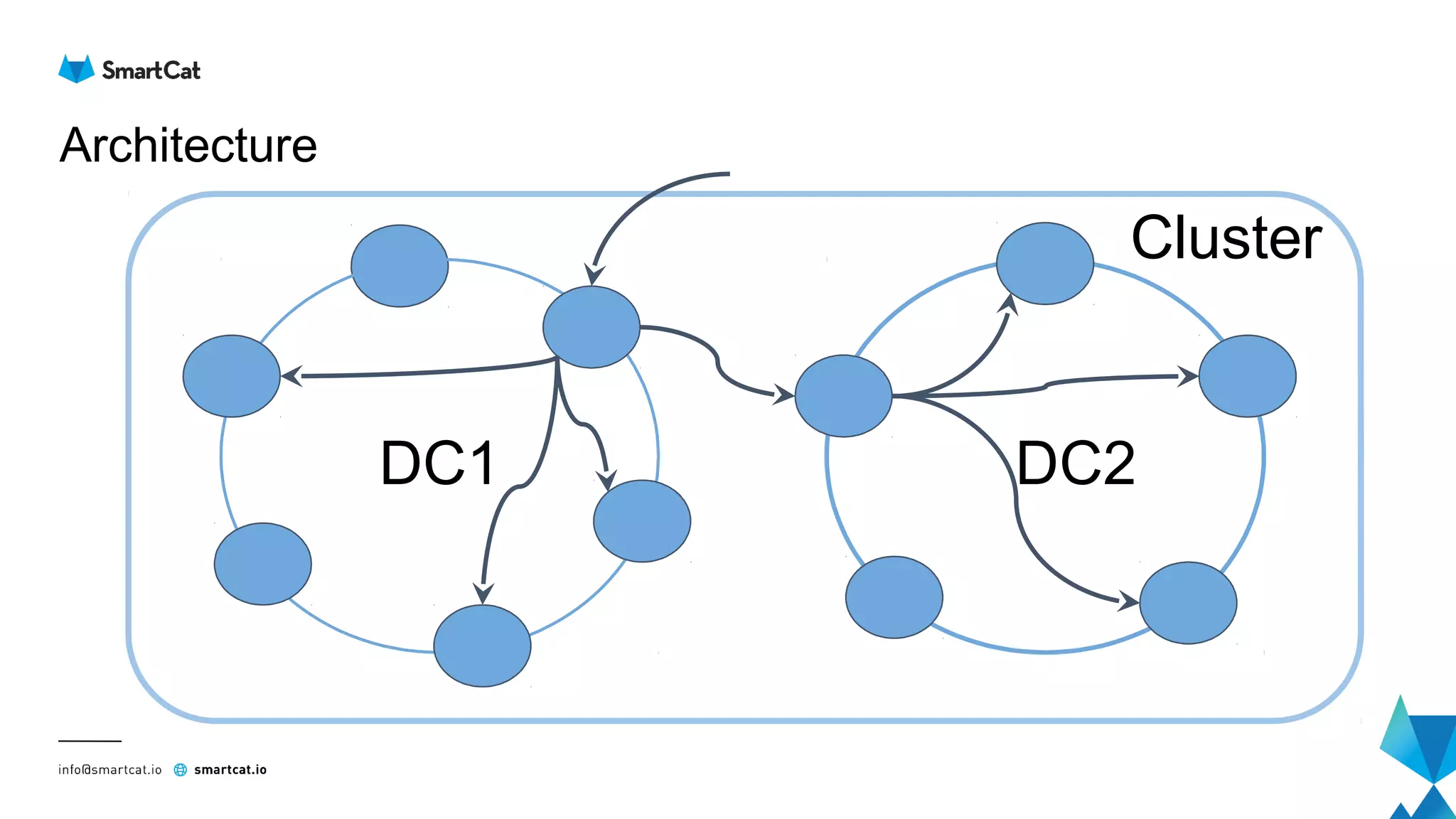

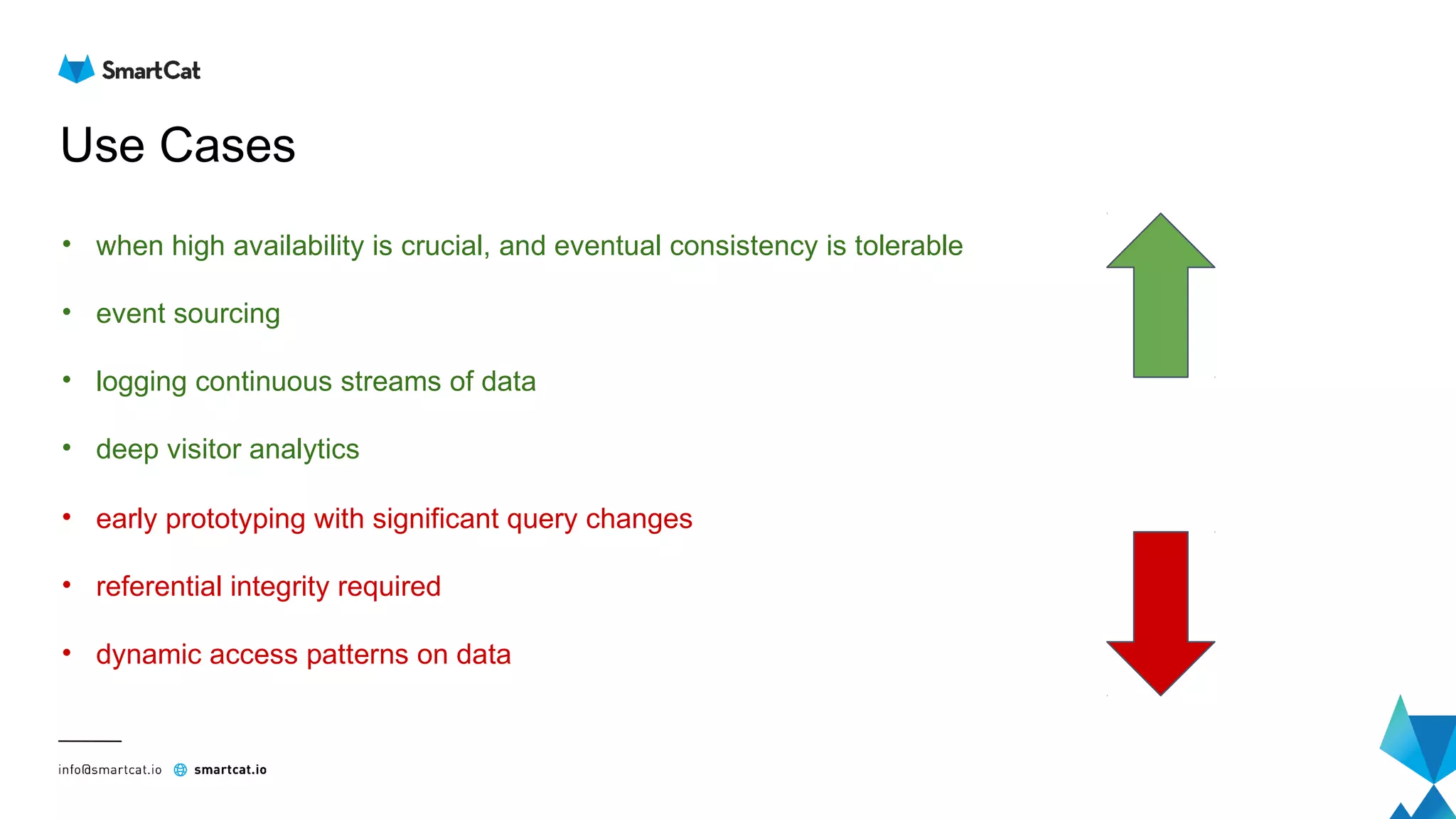


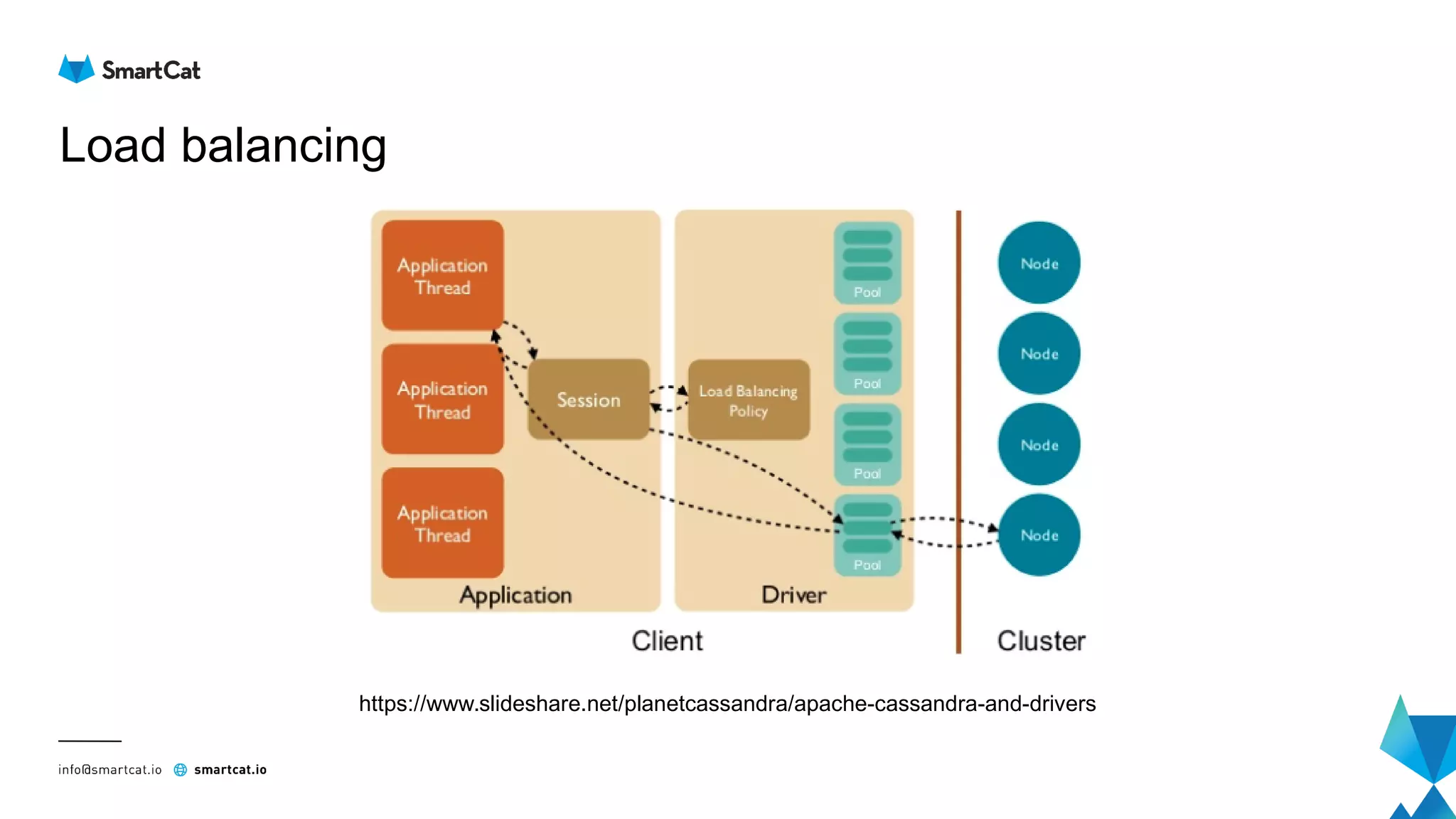
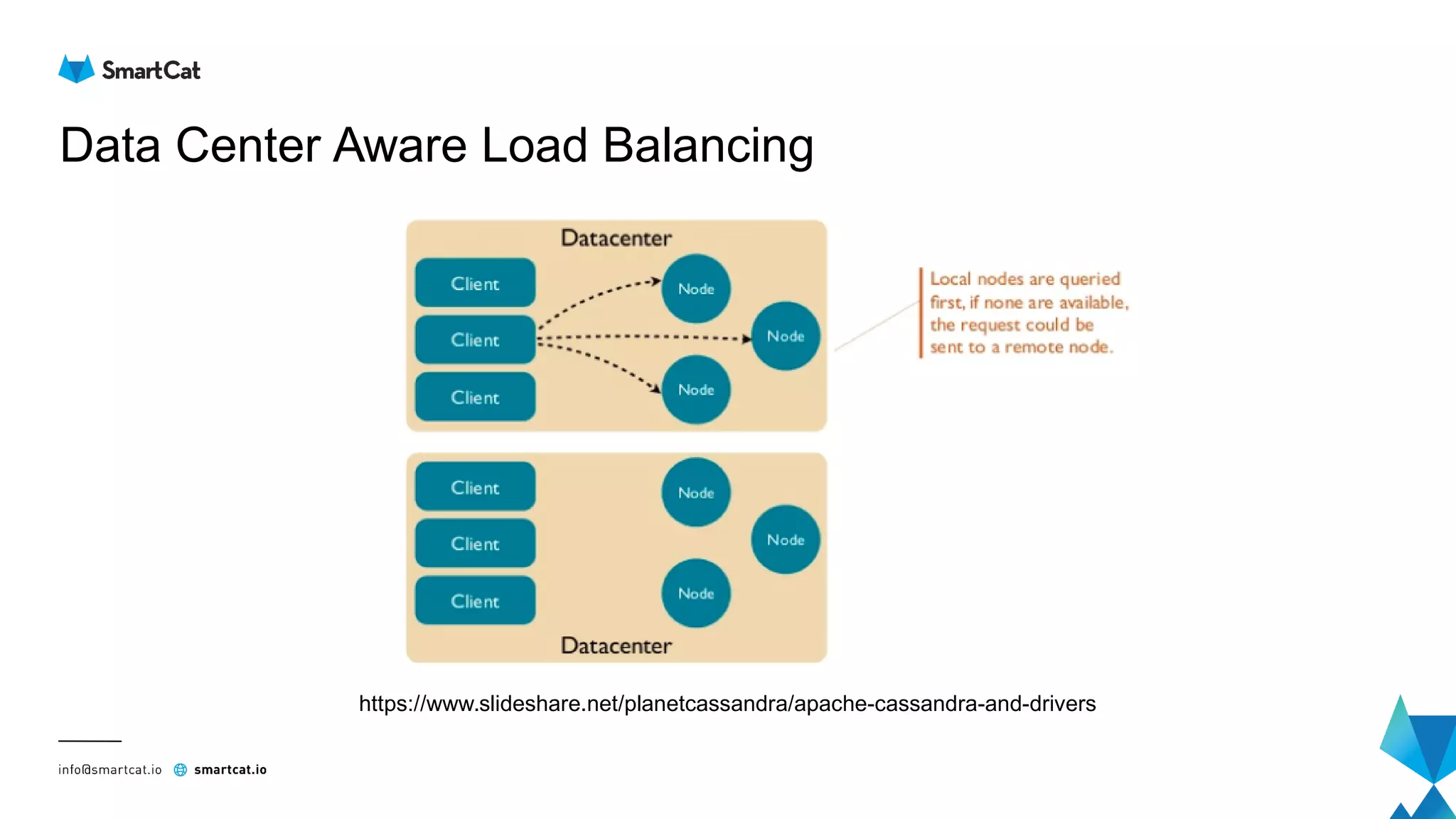
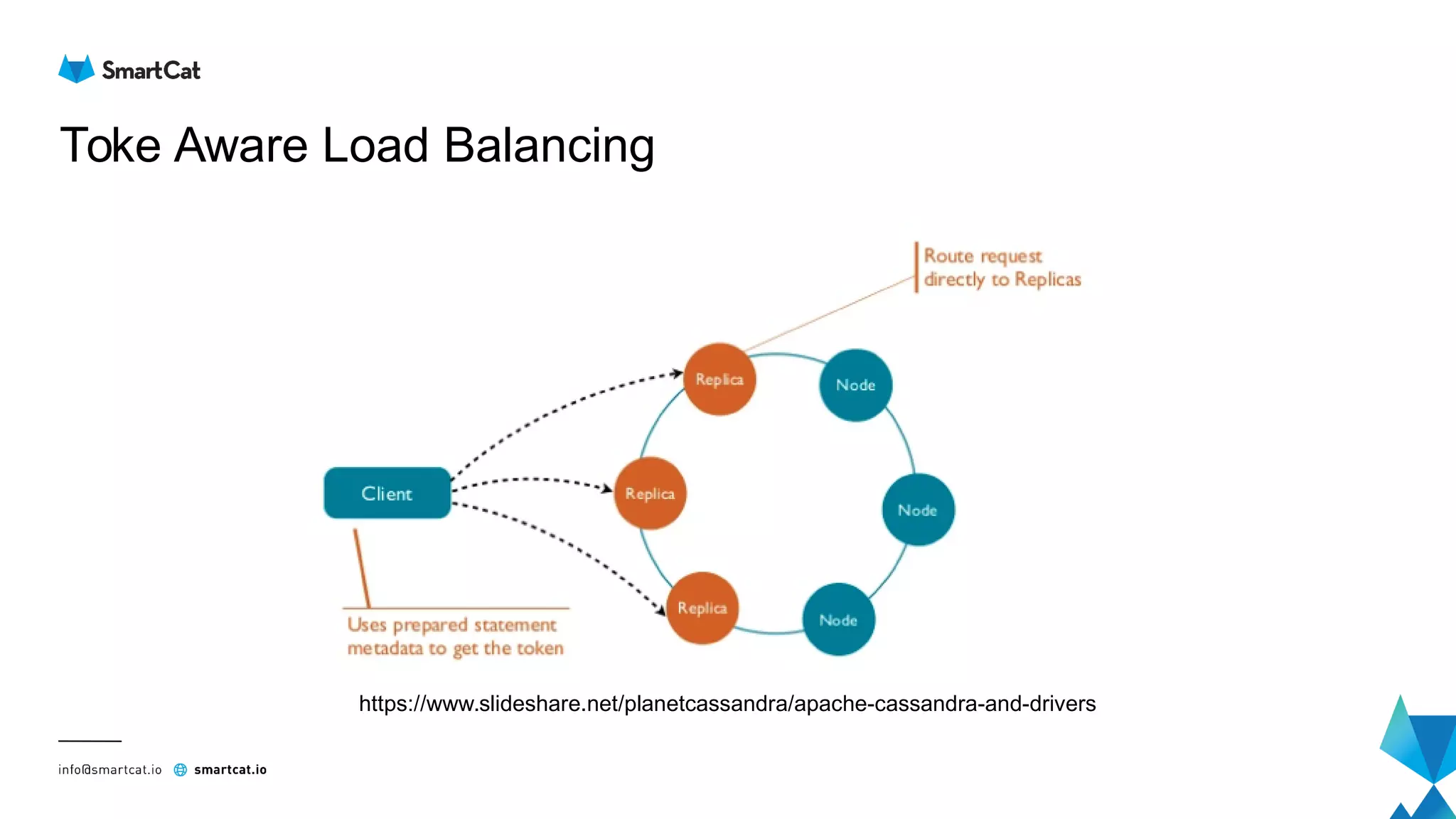



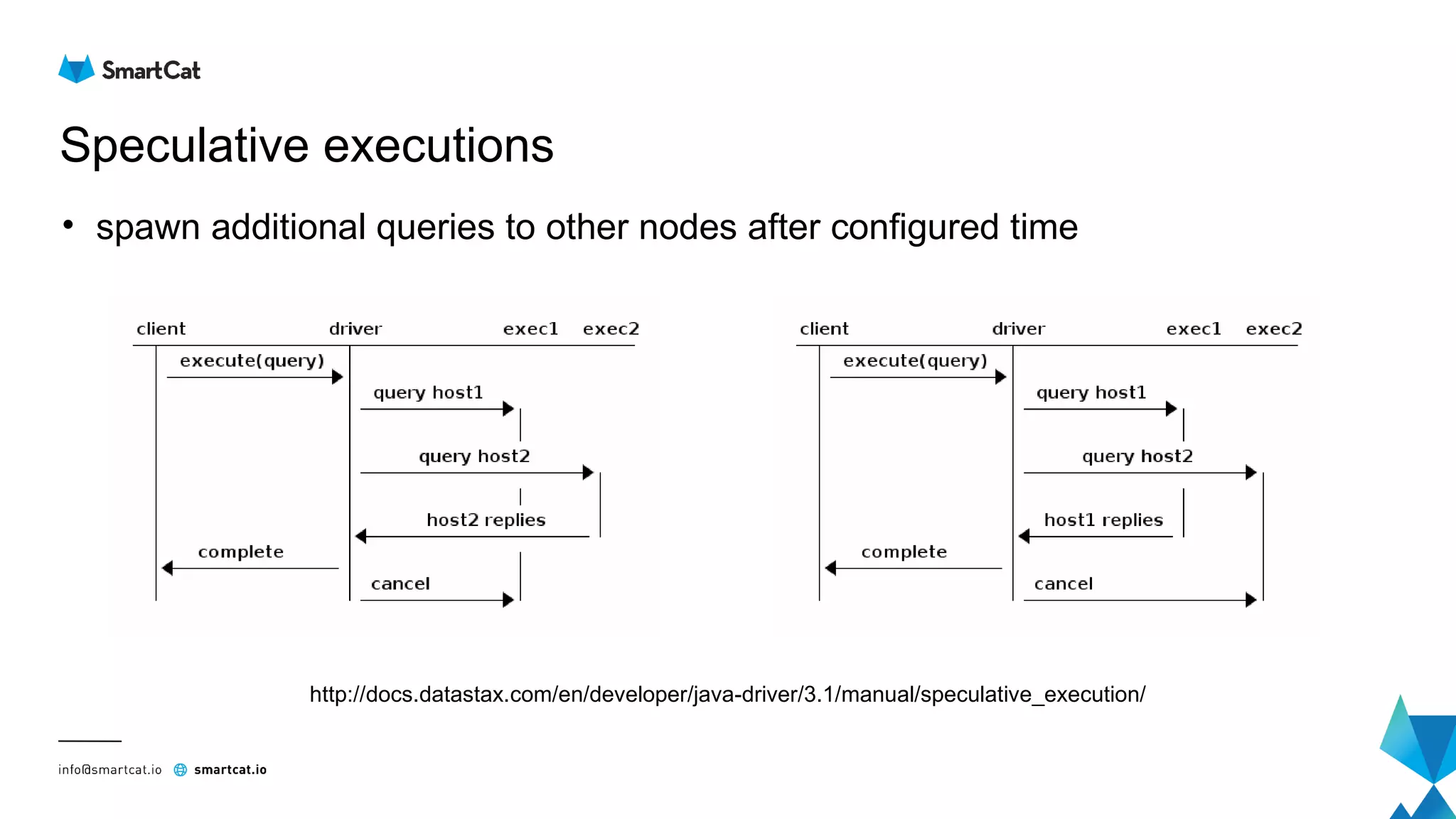
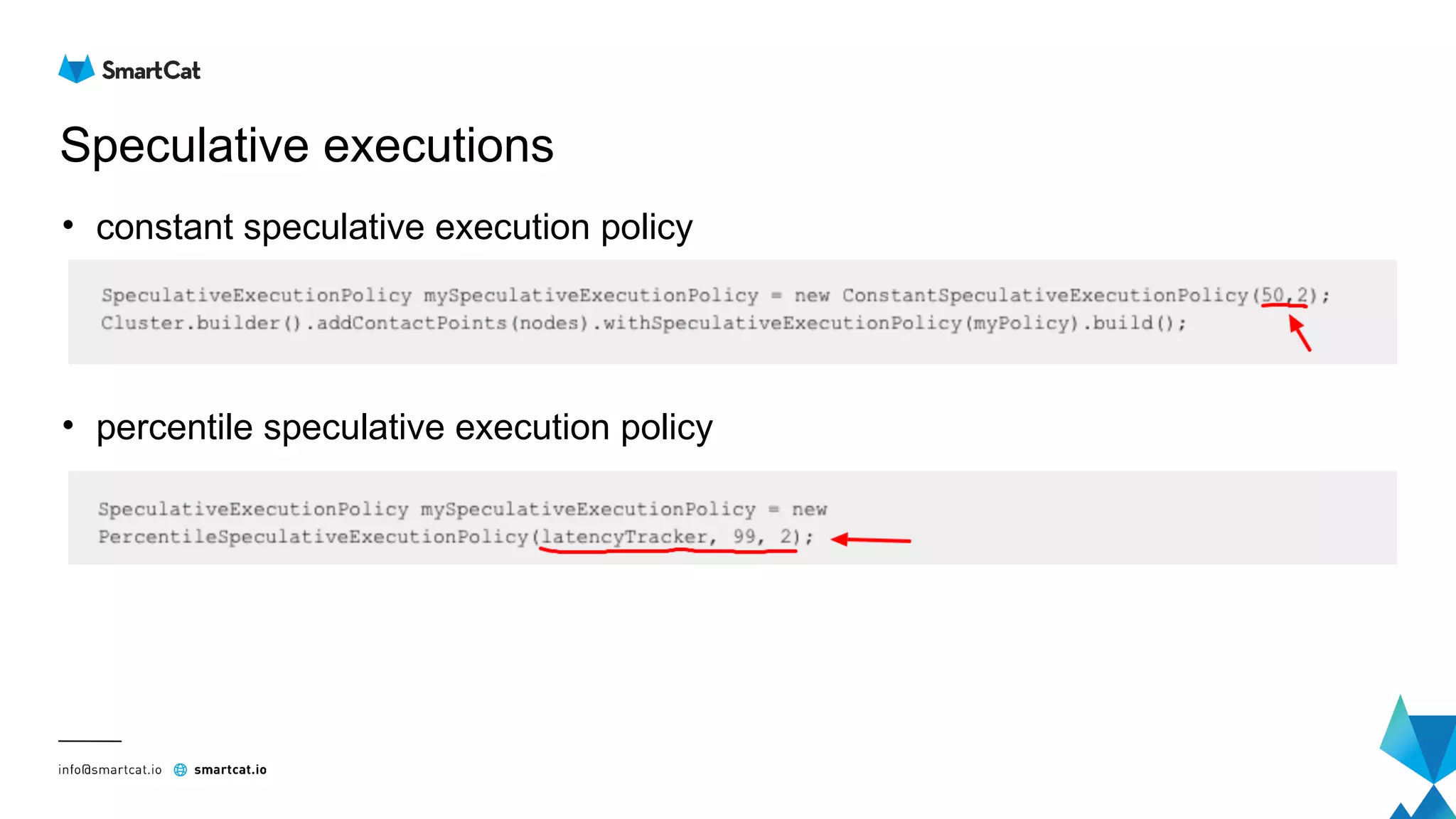











The document provides guidance on tuning the Java driver for Apache Cassandra, highlighting the architecture, data modeling, and specific use cases for high availability and eventual consistency. It discusses tuning options including load balancing, pooling, speculative executions, timeouts, and retry policies tailored to different scenarios like click stream data and mission-critical information. Key takeaways emphasize the importance of understanding use cases and proper monitoring to optimize database performance.








































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














