Downloaded 27 times







![Qemu monitor: Back-end configuration
console interface
Log options:
out asm: show generated host code
In asm: show target assembly code
Exec: show trace before each executed TB
…etc
Generated log of (log exec):
Trace (Host Address) [(Target Address)]
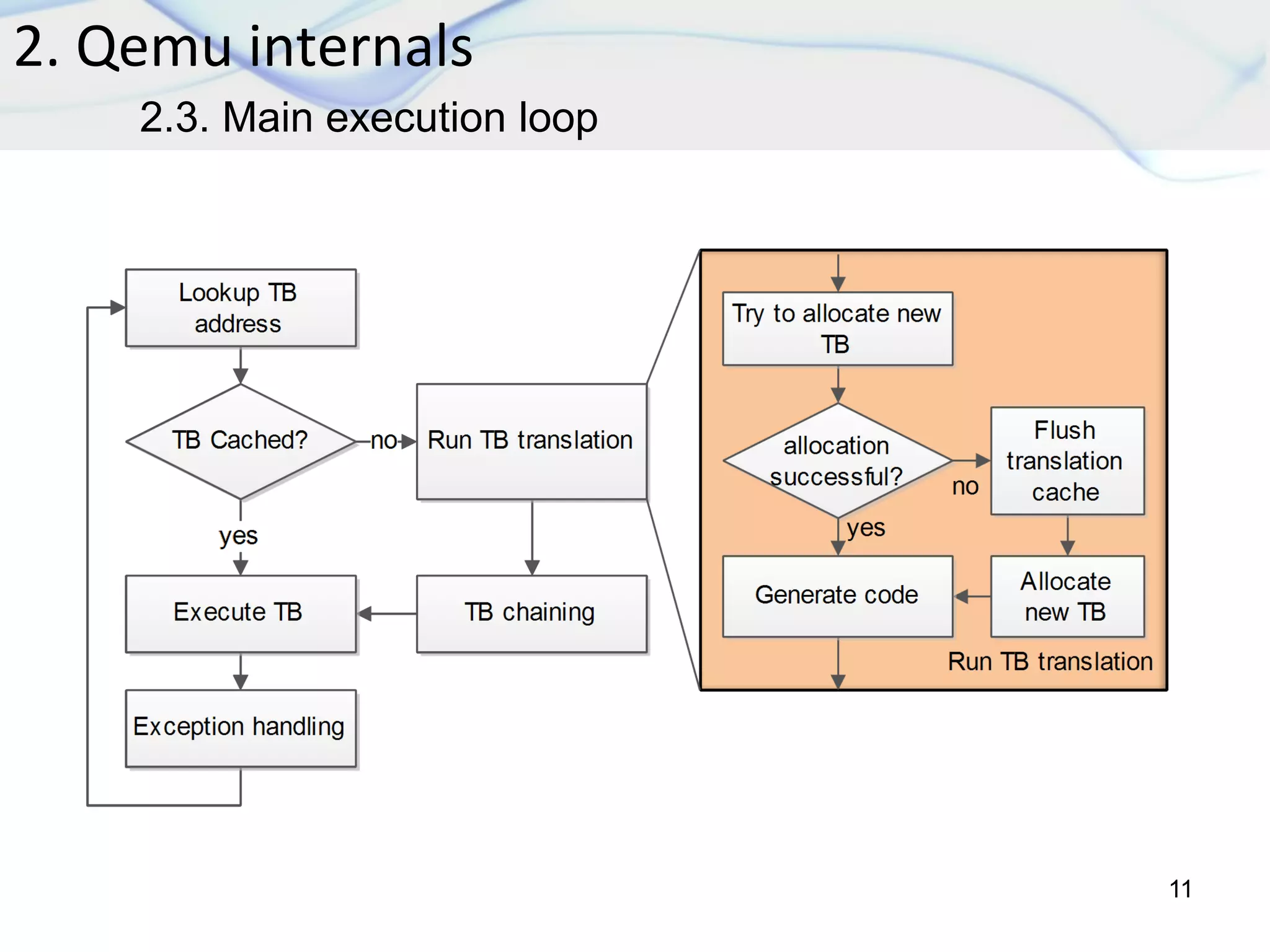
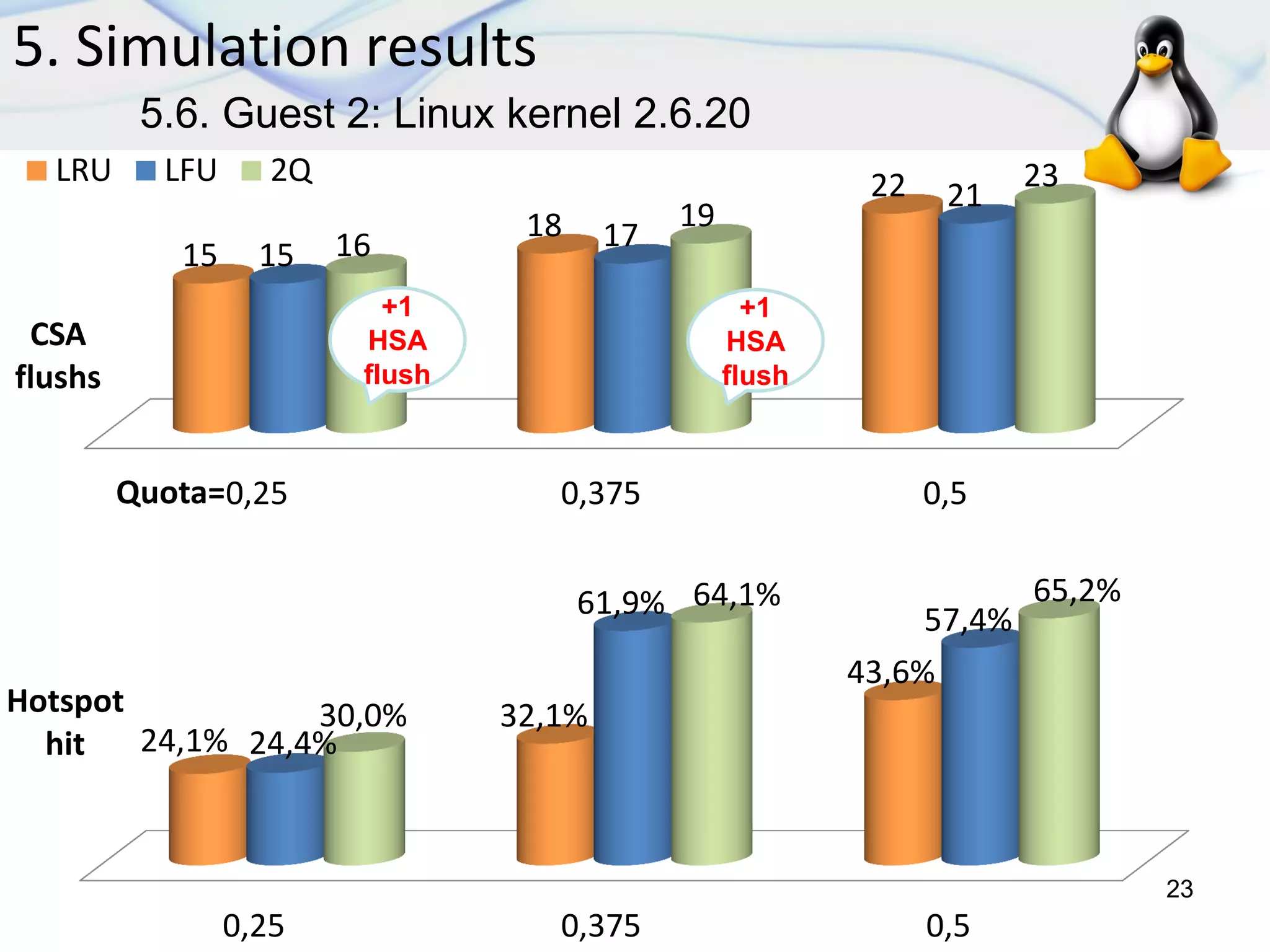
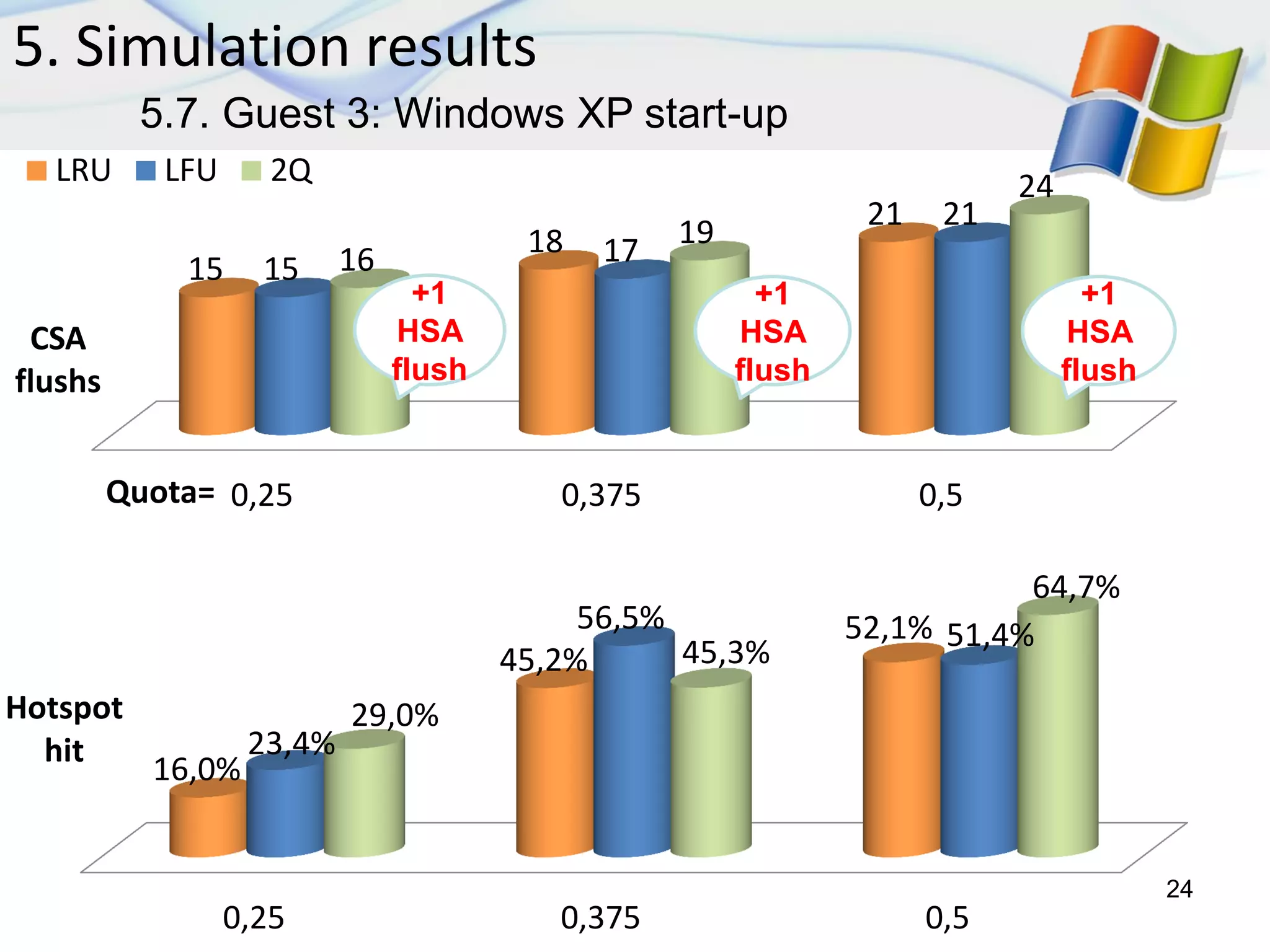
5. Simulation results
18
5.1. Qemu log](https://image.slidesharecdn.com/slides-pfe-160227195628/75/Translation-Cache-Policies-for-Dynamic-Binary-Translation-18-2048.jpg)






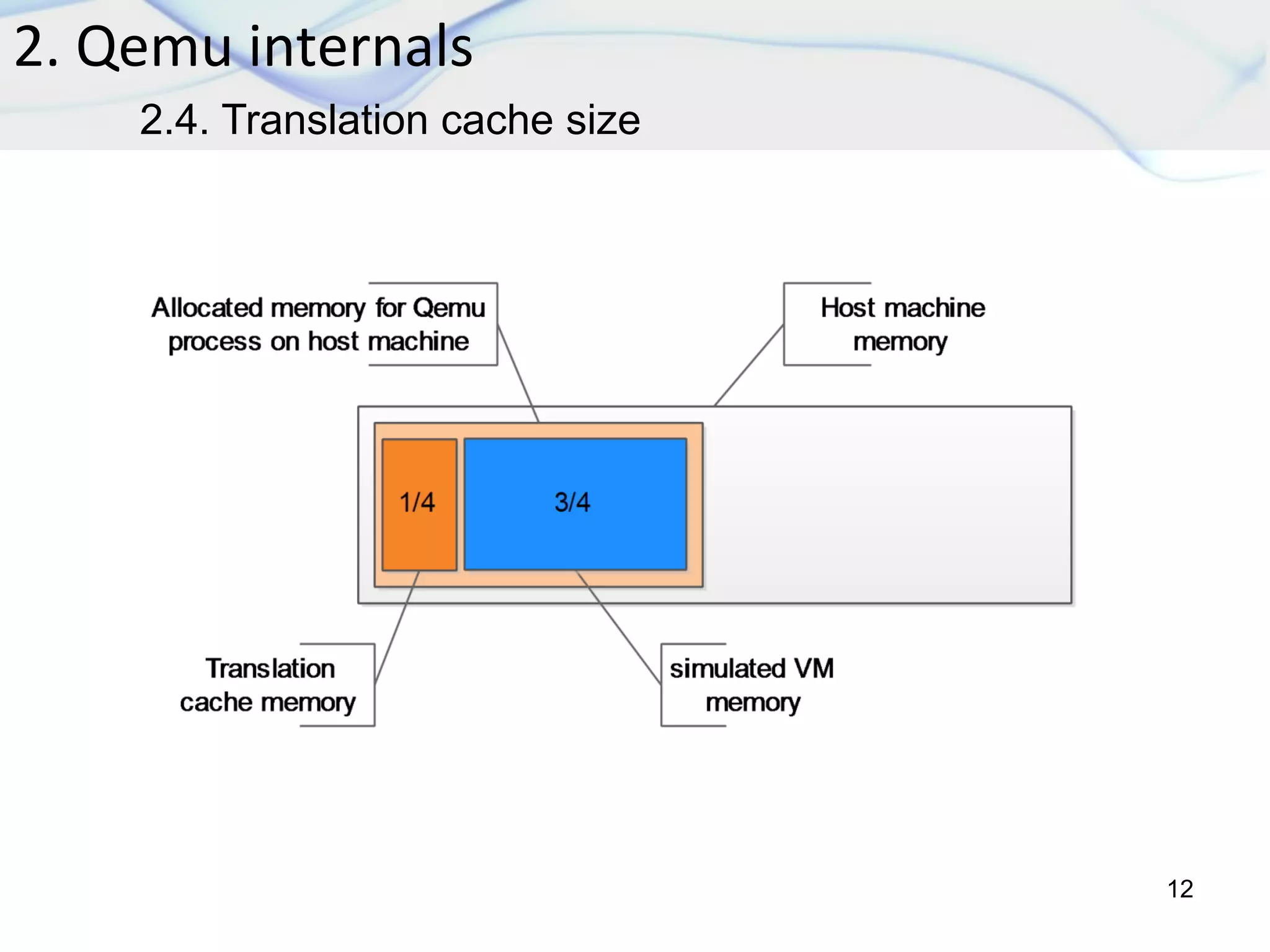
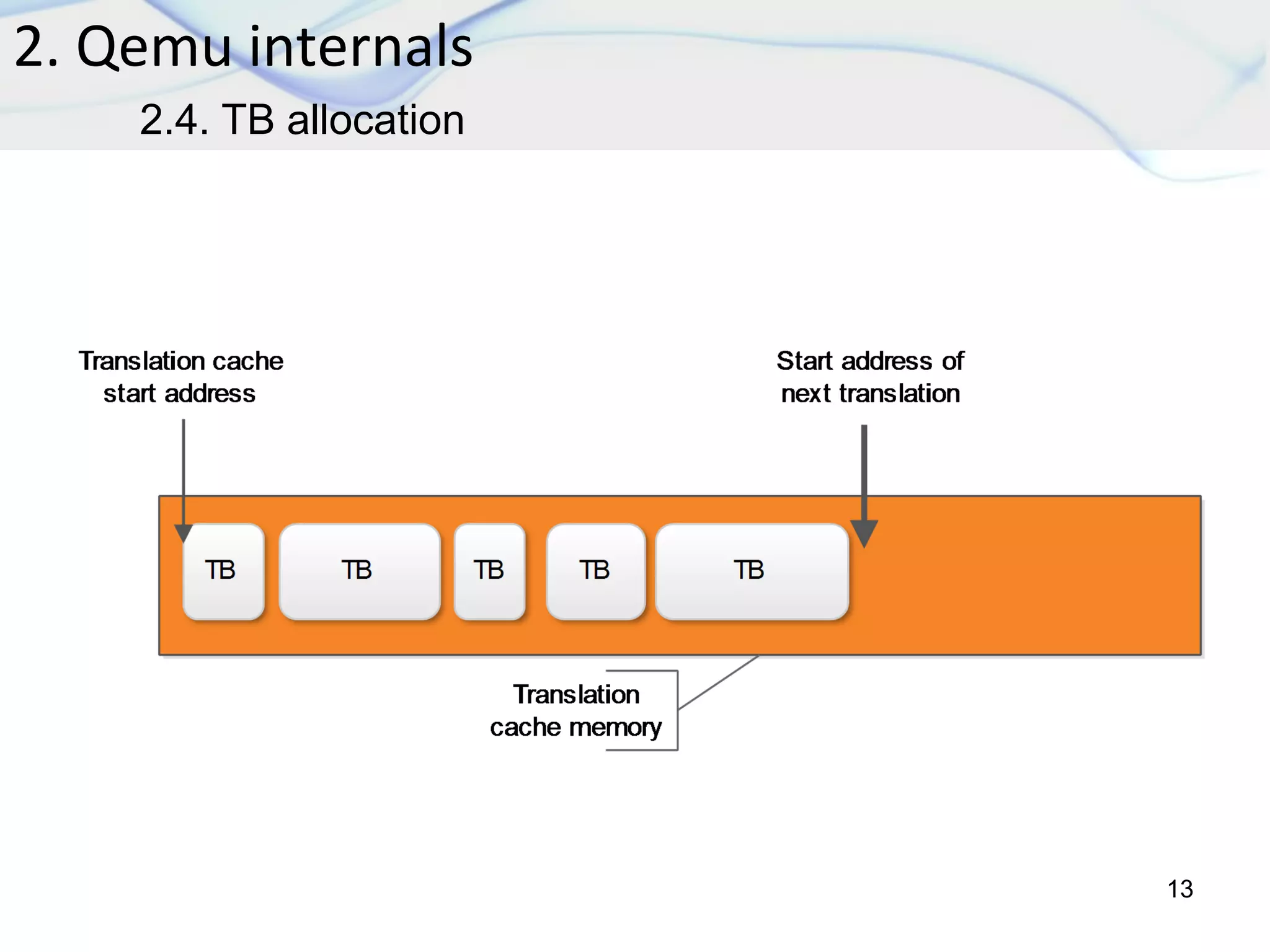
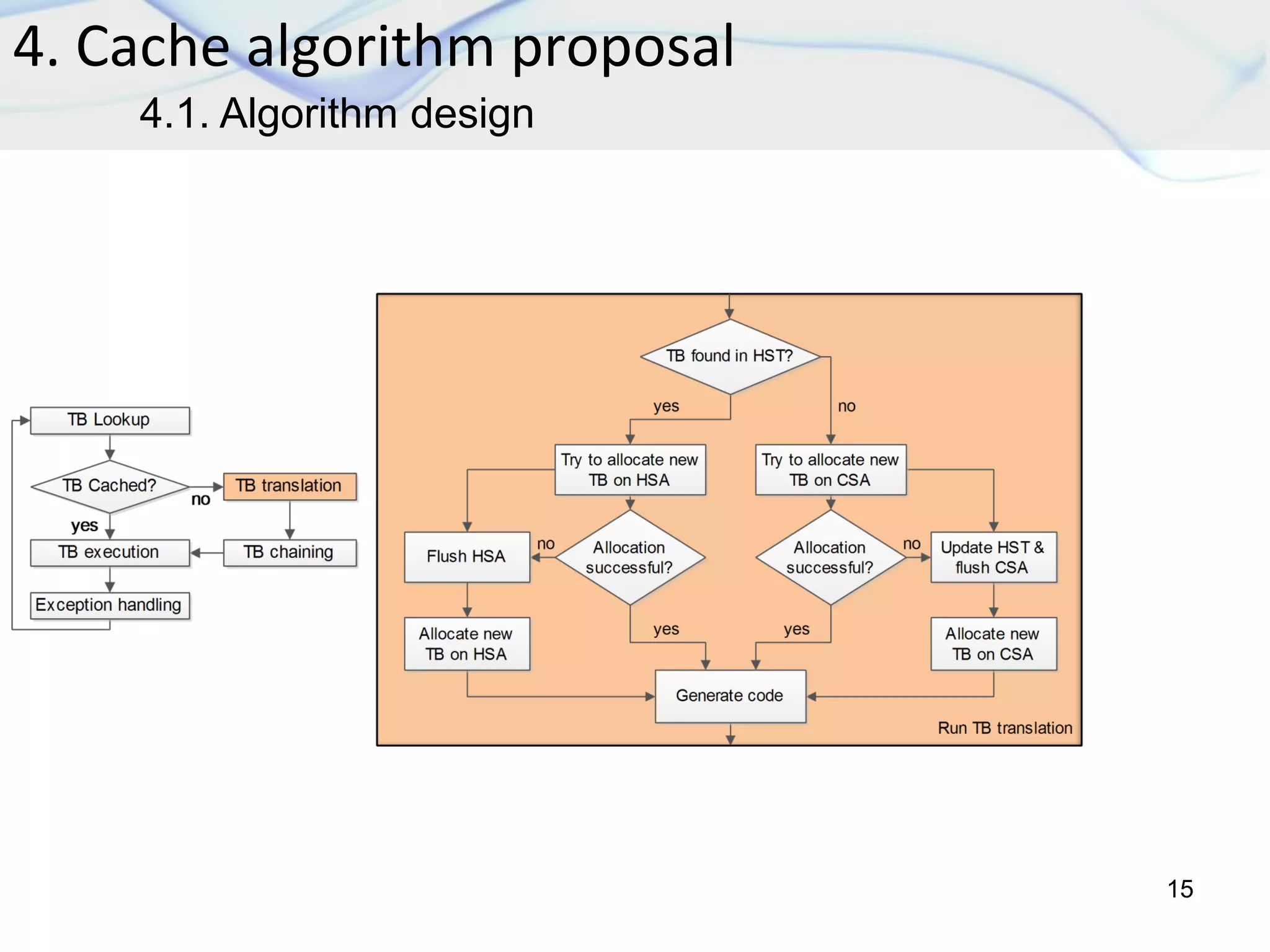
The document discusses dynamic binary translation (DBT) and the use of translation caches to improve the efficiency of code execution on different CPUs. It outlines virtualization techniques, QEMU internals, various cache algorithms, and proposes a new cache algorithm design along with its simulation results. The findings suggest that the current QEMU translation cache is inefficient, and the proposed algorithm may reduce unnecessary re-translations and improve performance.















![SMP Implementation for OpenBSD/sgi [Japanese Edition]](https://cdn.slidesharecdn.com/ss_thumbnails/cbugapr232010-100423110217-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)























































