Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
TS
Uploaded by
Toshiki Sakai
PDF, PPTX
1,636 views
Cv勉強会cvpr2018読み会: Im2Flow: Motion Hallucination from Static Images for Action Recognition
Im2Flow: Motion Hallucination from Static Images for Action Recognition
Data & Analytics
◦
Related topics:
Deep Learning
•
Computer Vision Insights
•
Read more
3
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 24
2
/ 24
3
/ 24
4
/ 24
5
/ 24
6
/ 24
7
/ 24
8
/ 24
9
/ 24
10
/ 24
11
/ 24
12
/ 24
13
/ 24
14
/ 24
15
/ 24
16
/ 24
17
/ 24
18
/ 24
19
/ 24
20
/ 24
21
/ 24
22
/ 24
23
/ 24
24
/ 24
More Related Content
PPTX
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
PDF
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
PDF
画像生成・生成モデル メタサーベイ
by
cvpaper. challenge
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
PPTX
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
by
Yusuke Uchida
PDF
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
PDF
【DL輪読会】NeRF in the Palm of Your Hand: Corrective Augmentation for Robotics vi...
by
Deep Learning JP
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
画像生成・生成モデル メタサーベイ
by
cvpaper. challenge
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
by
Yusuke Uchida
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
【DL輪読会】NeRF in the Palm of Your Hand: Corrective Augmentation for Robotics vi...
by
Deep Learning JP
What's hot
PDF
Visual SLAM: Why Bundle Adjust?の解説(第4回3D勉強会@関東)
by
Masaya Kaneko
PDF
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
PDF
大域マッチングコスト最小化とLiDAR-IMUタイトカップリングに基づく三次元地図生成
by
MobileRoboticsResear
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PDF
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
by
SSII
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
PDF
[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...
by
Deep Learning JP
PDF
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
PDF
[DL輪読会]StarGAN: Unified Generative Adversarial Networks for Multi-Domain Ima...
by
Deep Learning JP
PPTX
Triplet Loss 徹底解説
by
tancoro
PDF
RAFT: Recurrent All-Pairs Field Transforms for Optical Flow
by
MasanoriSuganuma
PPTX
[DL輪読会]End-to-End Object Detection with Transformers
by
Deep Learning JP
PPTX
【DL輪読会】Transformers are Sample Efficient World Models
by
Deep Learning JP
PPTX
【DL輪読会】"Instant Neural Graphics Primitives with a Multiresolution Hash Encoding"
by
Deep Learning JP
PPTX
これからの Vision & Language ~ Acadexit した4つの理由
by
Yoshitaka Ushiku
PPTX
[DL輪読会]Neural Ordinary Differential Equations
by
Deep Learning JP
PDF
研究効率化Tips Ver.2
by
cvpaper. challenge
PDF
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
PDF
SSII2019企画: 点群深層学習の研究動向
by
SSII
Visual SLAM: Why Bundle Adjust?の解説(第4回3D勉強会@関東)
by
Masaya Kaneko
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
大域マッチングコスト最小化とLiDAR-IMUタイトカップリングに基づく三次元地図生成
by
MobileRoboticsResear
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
by
SSII
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...
by
Deep Learning JP
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
[DL輪読会]StarGAN: Unified Generative Adversarial Networks for Multi-Domain Ima...
by
Deep Learning JP
Triplet Loss 徹底解説
by
tancoro
RAFT: Recurrent All-Pairs Field Transforms for Optical Flow
by
MasanoriSuganuma
[DL輪読会]End-to-End Object Detection with Transformers
by
Deep Learning JP
【DL輪読会】Transformers are Sample Efficient World Models
by
Deep Learning JP
【DL輪読会】"Instant Neural Graphics Primitives with a Multiresolution Hash Encoding"
by
Deep Learning JP
これからの Vision & Language ~ Acadexit した4つの理由
by
Yoshitaka Ushiku
[DL輪読会]Neural Ordinary Differential Equations
by
Deep Learning JP
研究効率化Tips Ver.2
by
cvpaper. challenge
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
SSII2019企画: 点群深層学習の研究動向
by
SSII
Similar to Cv勉強会cvpr2018読み会: Im2Flow: Motion Hallucination from Static Images for Action Recognition
PDF
【2016.04】cvpaper.challenge2016
by
cvpaper. challenge
PDF
動作認識の最前線:手法,タスク,データセット
by
Toru Tamaki
PDF
動画像理解のための深層学習アプローチ
by
Toru Tamaki
PDF
【チュートリアル】コンピュータビジョンによる動画認識 v2
by
Hirokatsu Kataoka
PDF
CV勉強会CVPR2019読み会: Video Action Transformer Network
by
Toshiki Sakai
PDF
文献紹介:Video Transformer Network
by
Toru Tamaki
PPTX
[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation
by
Deep Learning JP
PDF
【チュートリアル】動的な人物・物体認識技術 -Dense Trajectories-
by
Hirokatsu Kataoka
PDF
PFI成果発表会2014発表資料 Where Do You Look?
by
Hokuto Kagaya
PDF
【チュートリアル】コンピュータビジョンによる動画認識
by
Hirokatsu Kataoka
PDF
cvpaper.challenge@CVPR2015(Action Recognition)
by
cvpaper. challenge
PPTX
【論文LT資料】 Gait Recognition via Disentangled Representation Learning (CVPR2019)
by
Takuji Tahara
PPTX
DLゼミ: Ego-Body Pose Estimation via Ego-Head Pose Estimation
by
harmonylab
PPTX
CVPR2018 参加報告(速報版)初日
by
Atsushi Hashimoto
PDF
【2016.06】cvpaper.challenge2016
by
cvpaper. challenge
PDF
【メタサーベイ】Video Transformer
by
cvpaper. challenge
PDF
Towards Performant Video Recognition
by
cvpaper. challenge
PDF
動画認識における代表的なモデル・データセット(メタサーベイ)
by
cvpaper. challenge
PPTX
Eccv2018 report day2
by
Atsushi Hashimoto
PPTX
【DLゼミ】Generative Image Dynamics, CVPR2024
by
harmonylab
【2016.04】cvpaper.challenge2016
by
cvpaper. challenge
動作認識の最前線:手法,タスク,データセット
by
Toru Tamaki
動画像理解のための深層学習アプローチ
by
Toru Tamaki
【チュートリアル】コンピュータビジョンによる動画認識 v2
by
Hirokatsu Kataoka
CV勉強会CVPR2019読み会: Video Action Transformer Network
by
Toshiki Sakai
文献紹介:Video Transformer Network
by
Toru Tamaki
[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation
by
Deep Learning JP
【チュートリアル】動的な人物・物体認識技術 -Dense Trajectories-
by
Hirokatsu Kataoka
PFI成果発表会2014発表資料 Where Do You Look?
by
Hokuto Kagaya
【チュートリアル】コンピュータビジョンによる動画認識
by
Hirokatsu Kataoka
cvpaper.challenge@CVPR2015(Action Recognition)
by
cvpaper. challenge
【論文LT資料】 Gait Recognition via Disentangled Representation Learning (CVPR2019)
by
Takuji Tahara
DLゼミ: Ego-Body Pose Estimation via Ego-Head Pose Estimation
by
harmonylab
CVPR2018 参加報告(速報版)初日
by
Atsushi Hashimoto
【2016.06】cvpaper.challenge2016
by
cvpaper. challenge
【メタサーベイ】Video Transformer
by
cvpaper. challenge
Towards Performant Video Recognition
by
cvpaper. challenge
動画認識における代表的なモデル・データセット(メタサーベイ)
by
cvpaper. challenge
Eccv2018 report day2
by
Atsushi Hashimoto
【DLゼミ】Generative Image Dynamics, CVPR2024
by
harmonylab
Cv勉強会cvpr2018読み会: Im2Flow: Motion Hallucination from Static Images for Action Recognition
1.
論文紹介 Im2Flow: Motion Hallucination
from Static Images for Action Recognition 2018/7/7@CV勉強会 酒井 俊樹
2.
自己紹介 名前:酒井 俊樹 所属:NTTドコモ 仕事:Deep Learningを使ったAPI/サービスの研究開発 ● 画像認識のAPI開発/法人様向けソリューション提供 ●
スポーツ動画解析機能開発 ● 最近は言語系や時系列データにも手を 本発表は個人で行うものであり、所属組織とは関係ありません。 2
3.
論文概要 Im2Flow: Motion Hallucination
from Static Images for Action Recognition ● 著者:Ruohan Gao et al.(UT Austin) 概要 ● 画像から動き(Optical Flow)を推定する ネットワークを提案 ● ネットワークをラベルなしの動画像 データから学習する ● 推定したFlowと元画像を用いることで、 画像からの動作(action)推定の精度が向上 3
4.
静止画→動き→動作認識 ● 画像データを整理する際など、画像単体から動作を推定する必要がある →動きの情報のない画像データから行動・動作を推定する必要性 ● 人は画像単体から次の動きをある程度予測できる ●
人の視覚野は動いている物体を切り取った静止画に 対しても動画と同じように反応する[Kourtzi+ 2000] ①静止画からの動き(Optical Flow)の推定がNeural Networkにもできるのでは? ②動きを推定することが、静止画からの動作の推定に役立つのでは? 4 背側経路 =where経路 →運動を処理 腹側経路 =what経路 →対象の認識等
5.
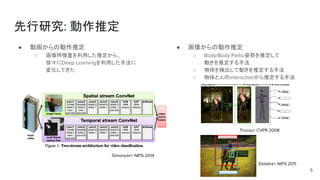
先行研究: 動作推定 ● 動画からの動作推定 ○
画像特徴量を利用した推定から、 徐々にDeep Learningを利用した手法に 変化してきた 5 ● 画像からの動作推定 ○ Body/Body Parts/姿勢を推定して 動きを推定する手法 ○ 物体を検出して動きを推定する手法 ○ 物体と人のinteractionから推定する手法 Simonyan+ NIPS 2014 Thurau+ CVPR 2008 Delaitre+ NIPS 2011
6.
先行研究: ● Image から動き(Optical
flow)を推定 ○ Walker+ ECCV 2016 ■ CNNを用いた分類で解く ■ ピクセルごとに、方向及び 強度の分類を行う 6 ● 画像→画像の変換 ○ 画像入力に対して、画像を出力する研究が GANの発明以降、盛ん ○ Encoder-Decoderの形式が良く使われる ○ 画像からのオプティカルフローの推定は、 RGB画像からOptical Flow画像の推定と とらえることが可能
7.
提案手法 1. 画像入力に対して、動き(Optical Flow)を推定するモデルを Encoder-Decoderの形で実現する 2.
上記の学習をUnlabeledな動画データをもとに学習する 3. 上記推定したOptical Flowを用いて、画像からの動作推定を行う 7
8.
下準備: Flowの表現方法 ● 通常Optical
Flowは2channelの画像データ であらわされる ○ 水平方向の符号つき強度 x 垂直方向の符号つき強度 ○ 2channelだと、一般的な画像認識向け 学習済みモデルを使うことができない 8 ● Optical Flowを角度と強度に分けたうえで 3channelで表現する手法を提案 ○ F1=sin(θ) ○ F2=cos(θ) ○ F3=Magnitude horizontal vertical
9.
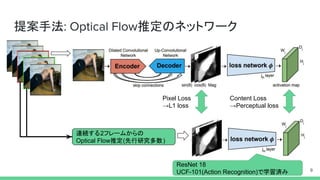
提案手法: Optical Flow推定のネットワーク 9 連続する2フレームからの Optical
Flow推定(先行研究多数) Pixel Loss →L1 loss ResNet 18 UCF-101(Action Recognition)で学習済み Content Loss →Perceptual loss
10.
提案手法: Loss ● 数式で表現すると以下の通り ●
Magnitudeが小さい動きは、手振れ等のカメラの動きに起因するもの →学習する必要があまりない →lossをMagnitudeで重みづけして学習 10
11.
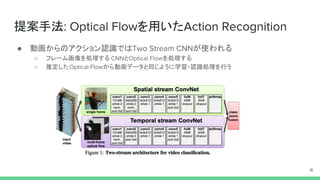
提案手法: Optical Flowを用いたAction
Recognition ● 動画からのアクション認識ではTwo Stream CNNが使われる ○ フレーム画像を処理する CNNとOptical Flowを処理する ○ 推定したOptical Flowから動画データと同じように学習・認識処理を行う 11
12.
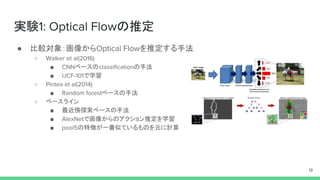
実験1: 画像からのOptical Flowの推定 ●
データセット ○ UCF-101:101種類の人のアクションの分類データ ○ HMDB-51: 51種類の人のアクションの分類データ ○ Weizmann: 単純な人の動作の動画データと特徴量のデータセット 12 動画データから 切り出した フレームを 学習/テストに利用
13.
実験1: Optical Flowの推定 ●
比較対象:画像からOptical Flowを推定する手法 ○ Walker et al(2016) ■ CNNベースのclassificationの手法 ■ UCF-101で学習 ○ Pintea et al(2014) ■ Random forestベースの手法 ○ ベースライン ■ 最近傍探索ベースの手法 ■ AlexNetで画像からのアクション推定を学習 ■ pool5の特徴が一番似ているものを元に計算 13
14.
実験1: 評価指標 ● 指標 ○
End-Point-Error(EPE): 予測のベクトル終点と正解のベクトルの終点のユークリッド距離 ○ Direction Similarity(DS): 予測と正解のコサイン距離 ○ Orientation Similarity(OS): DSの絶対値 ● 計算方法 ○ a)全ピクセルで計算 ○ b)Canny edgeを計算し、その上だけで計算 ○ c)Foreground Region上だけで計算 14 予測 正解 EPE DS
15.
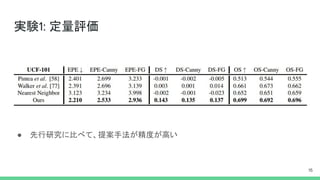
実験1: 定量評価 ● 先行研究に比べて、提案手法が精度が高い 15
16.
実験1: 定性評価 ● Pintea ○
単純動作には高精度 ○ 複雑な動作は困難 ● Walker ○ 全体的にうまく予測できて いる ○ 全体の動きのトレンドを予 測する傾向が強い ● 提案手法 ○ より精細な予測が可能 ○ 背景ノイズが多い場合など は失敗する 16
17.
実験1: Motion Potentical ●
画像入力に対するOptical Flowの大きさから、Motionの潜在能力を計算可能 17
18.
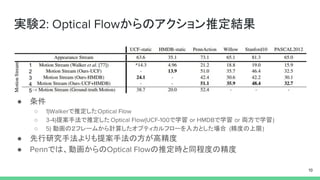
実験2: アクションの推定 ● データセット ○
UCF-101 ○ HMDB-51 ○ Penn Action: 動画からsportsアクションを推定するデータセット ○ Willow: 画像から7つのアクション分類 ○ Stanford10: Standord40のサブセット。画像からの 10のアクションへの分類 ○ PASCAL2012: 画像から11クラスのアクション分類のデータセット 18 どちらか、もしくは両方を Optical Flow推定の学習で利用
19.
実験2: Optical Flowからのアクション推定結果 ●
条件 ○ 1)Walkerで推定したOptical Flow ○ 3-4)提案手法で推定した Optical Flow(UCF-100で学習 or HMDBで学習 or 両方で学習) ○ 5) 動画の2フレームから計算したオプティカルフローを入力とした場合 (精度の上限) ● 先行研究手法よりも提案手法の方が高精度 ● Pennでは、動画からのOptical Flowの推定時と同程度の精度 19 1 2 3 4 5
20.
実験2: two streamでの動作推定 ●
条件 ○ 1)画像データのみからの推定 ○ 2)画像データ+先行研究の手法で推定した Optical Flow ○ 3-5)画像データ+提案手法で推定した Optical Flow ○ 6)画像データ+動画の2フレームから推定した Optical Flow(精度の上限) ● 提案手法が、画像単体からの推定よりももっとも精度向上(1-6%のgain) ● Flowの学習と違うドメインのデータセットでも精度向上 20 1 2 3 4 5 6
21.
実験2: 推定したOptical Flowによる認識精度向上 ●
画像的に似ている動作をOptical Flowの推定により区別できるようになった 21
22.
その他の実験結果 ● Dynamic scene
recognition ○ 自然現象の映像データの分類で 同じように精度向上が見られるか ○ im2flow自体も本データで再学習 22 ● Optical Flowを使わない、静止画からの アクション認識手法との比較 ○ 動作認識モデルをよりDeepにした方が 精度が上がることを確認 ○ 他の手法よりも良い精度
23.
なぜ画像から推定したFlowがAction認識に効くのか ● 画像からの動作推定には、動きのような複雑な高次元の信号に注意を向けること が必要だが、画像データ単体からは、動きを推定するための学習が困難 ○ 画像データ単体には上記を学習するための信号が不足している (似た画像で違う動きの画像がたくさんある
) ○ 以下のようなOptical Flow関連の知見とも一致 - 2枚の画像からOptical Flowを推定してから動作推定する方が、 2枚の単体の画像を 入力するより精度が上がる ● 大量の動画データから、正則化のための事前確率を学習できた ○ 画像からの動作推定のデータセットはデータ数が少ない →過学習しやすい 23
24.
まとめ ● 画像データから動きを推定する手法を提案 ● 推定した動きが動作推定における深情報となり、SOTAを上回る精度で動作推定が 可能になった 24
Download




![静止画→動き→動作認識
● 画像データを整理する際など、画像単体から動作を推定する必要がある
→動きの情報のない画像データから行動・動作を推定する必要性
● 人は画像単体から次の動きをある程度予測できる
● 人の視覚野は動いている物体を切り取った静止画に
対しても動画と同じように反応する[Kourtzi+ 2000]
①静止画からの動き(Optical Flow)の推定がNeural Networkにもできるのでは?
②動きを推定することが、静止画からの動作の推定に役立つのでは?
4
背側経路
=where経路
→運動を処理
腹側経路
=what経路
→対象の認識等](https://image.slidesharecdn.com/kantocvcvpr2018sakai-180707012150/85/Cv-cvpr2018-Im2Flow-Motion-Hallucination-from-Static-Images-for-Action-Recognition-4-320.jpg)














![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...](https://cdn.slidesharecdn.com/ss_thumbnails/ahigher-dimensionalrepresentationfortopologicallyvaryingneuralradiancefields1-210924021911-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]StarGAN: Unified Generative Adversarial Networks for Multi-Domain Ima...](https://cdn.slidesharecdn.com/ss_thumbnails/171222stargan-171225064145-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]End-to-End Object Detection with Transformers](https://cdn.slidesharecdn.com/ss_thumbnails/200529dlseminardetr-200529061512-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation](https://cdn.slidesharecdn.com/ss_thumbnails/0911mocogan-170911121936-thumbnail.jpg?width=640&height=640&fit=bounds)












