Downloaded 22 times








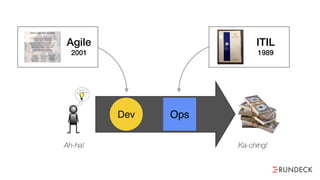
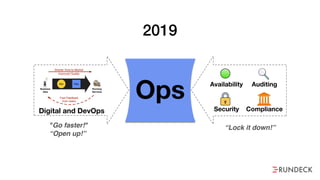




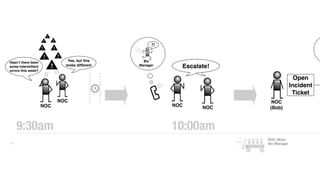
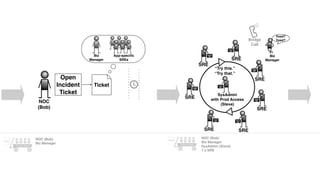
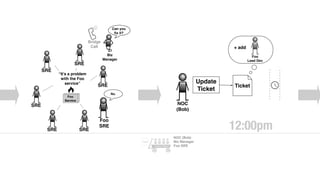
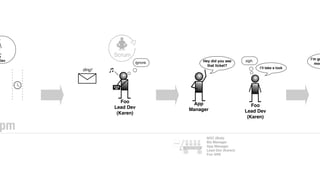
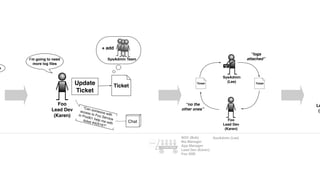
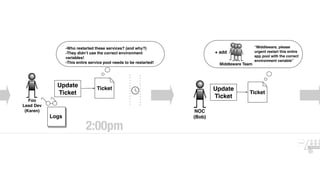
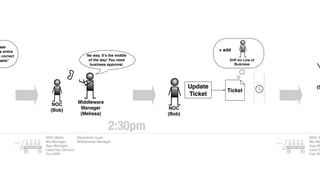
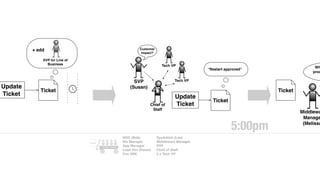
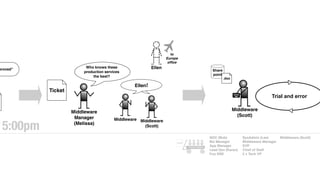
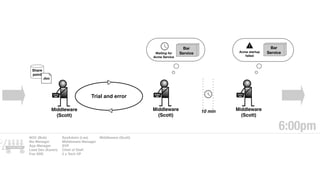

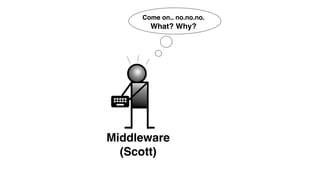
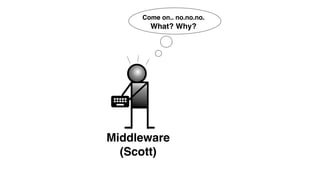
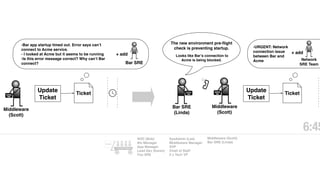
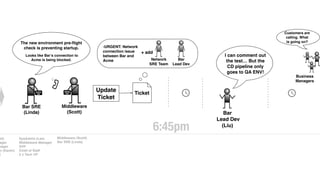
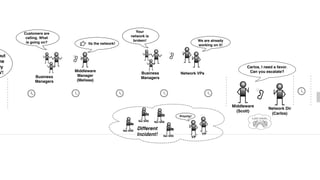
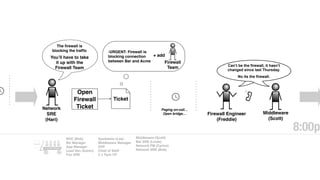
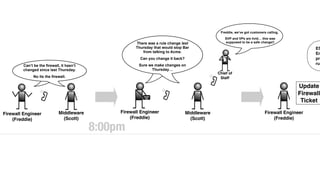
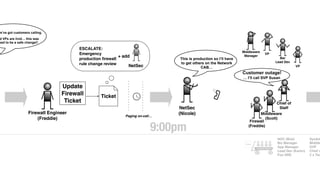
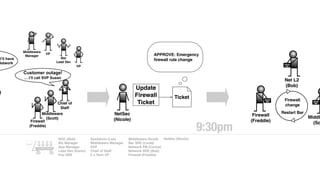
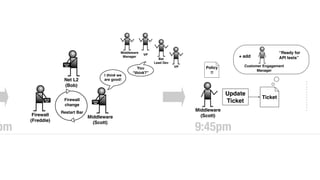
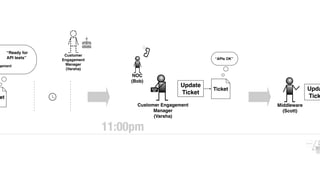
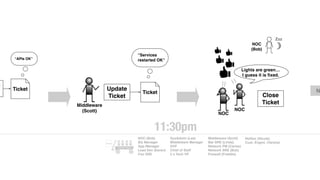
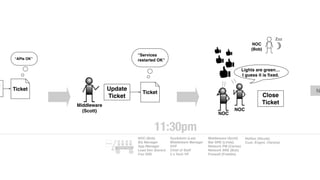











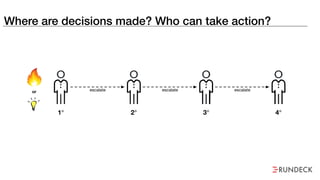
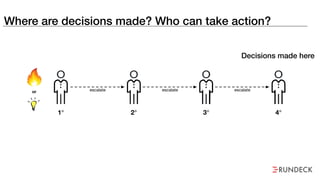





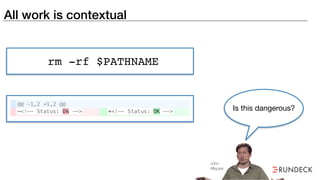

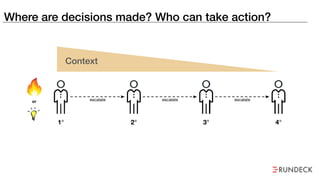



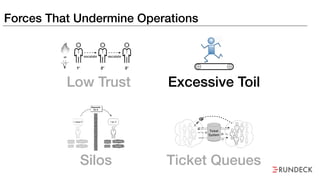


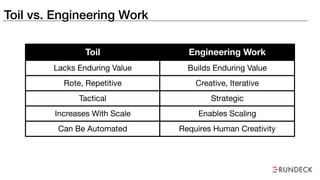
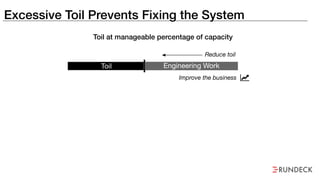


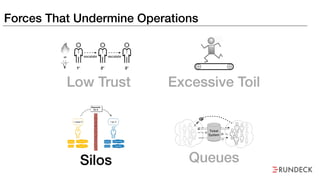
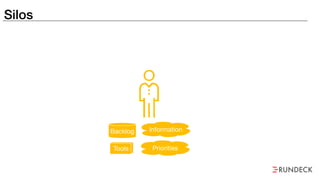
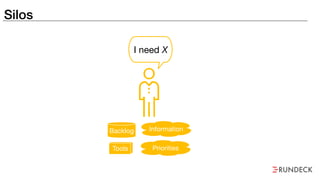
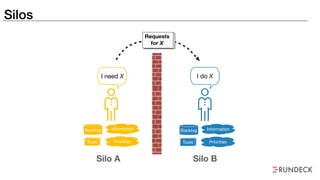
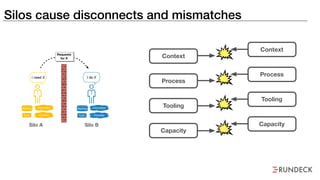
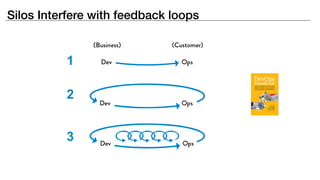
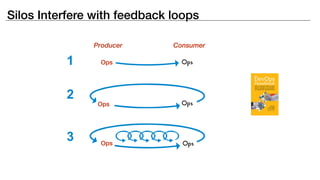
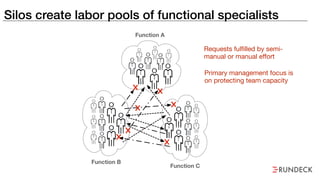
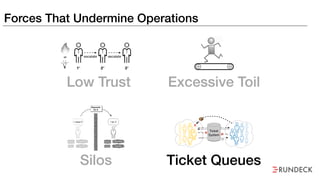
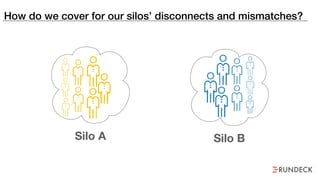
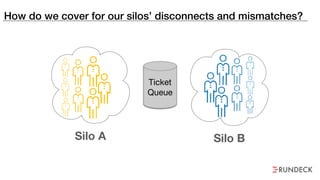
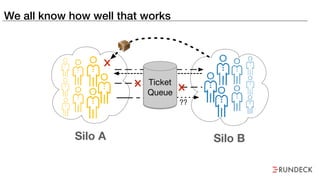
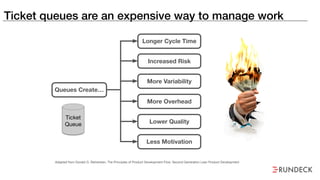

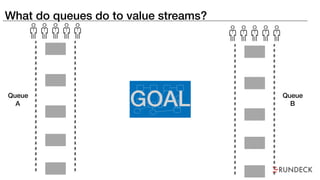
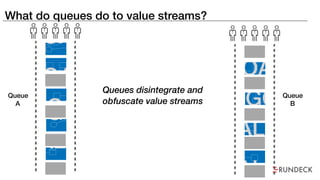
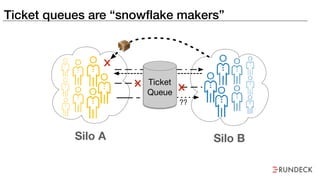


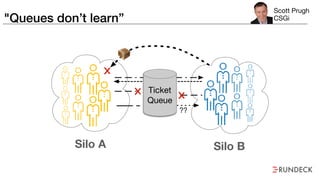
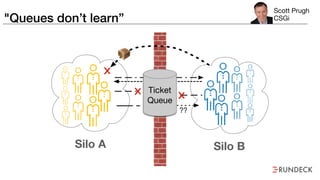
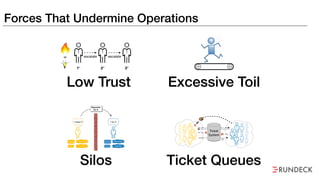


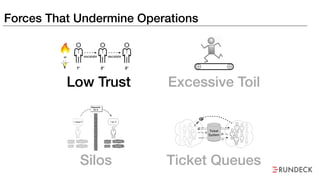
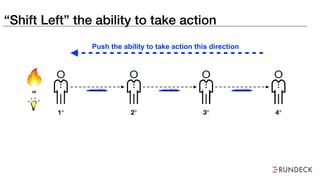
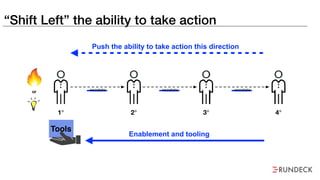
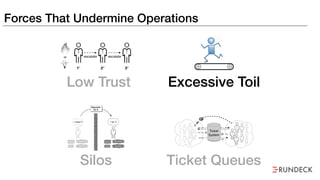













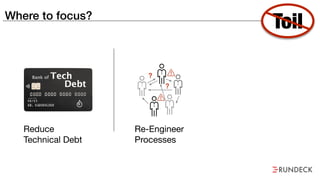
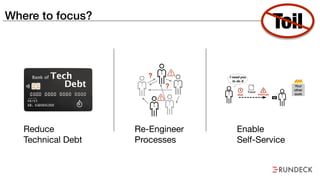
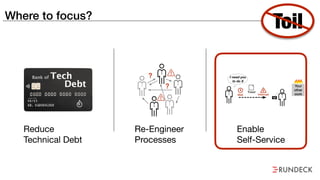
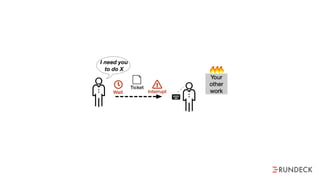
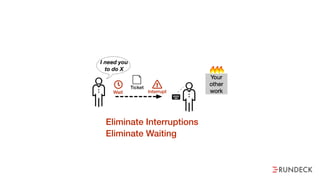
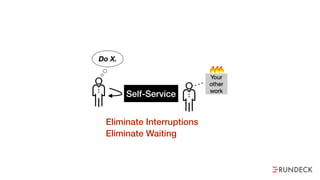
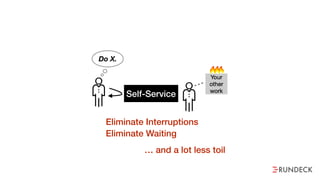

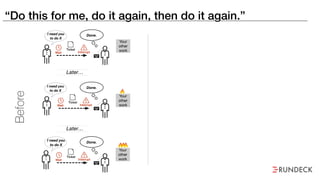
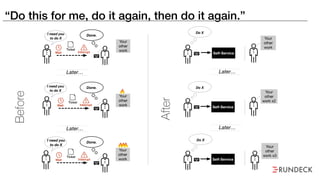

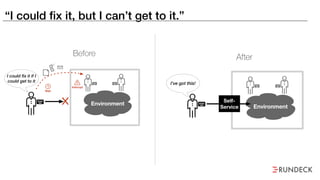
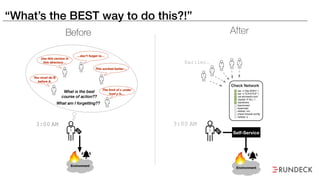

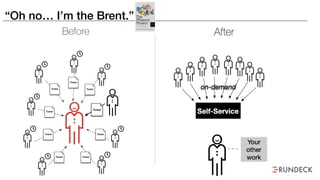
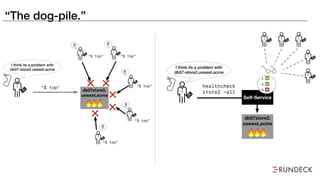

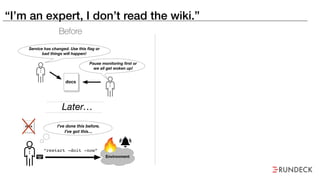
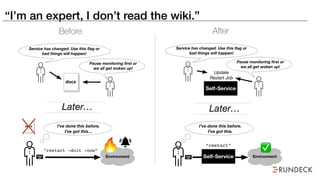
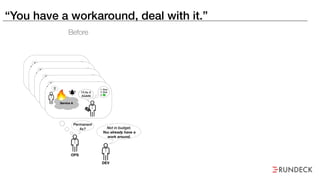
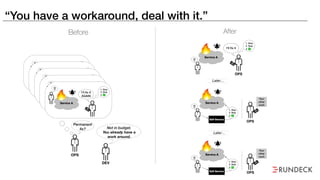
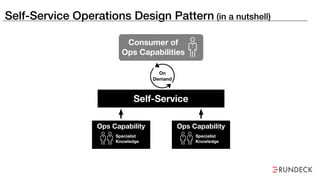
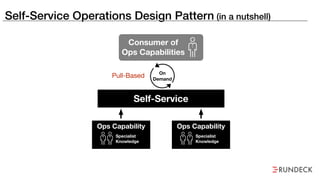
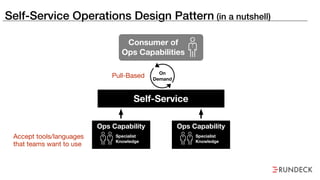
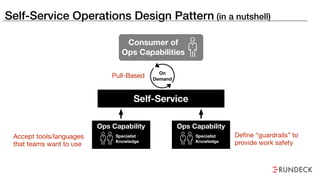
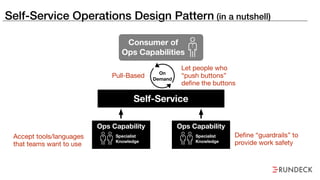
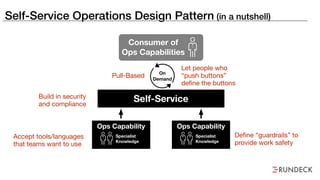




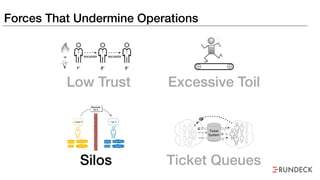
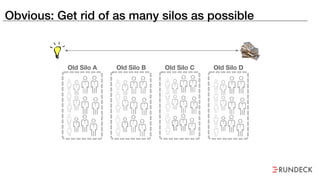
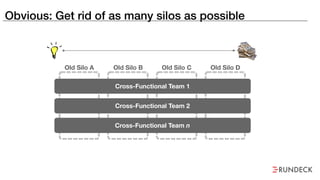
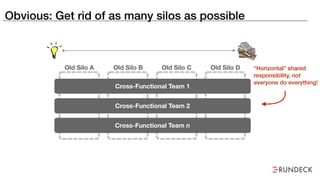

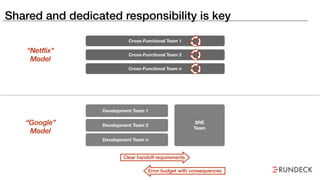
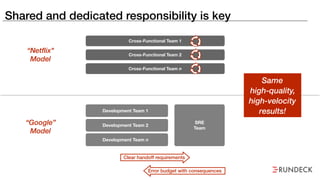
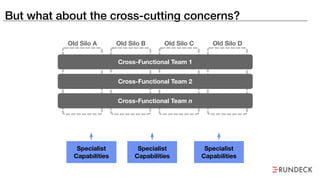
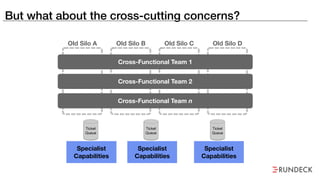
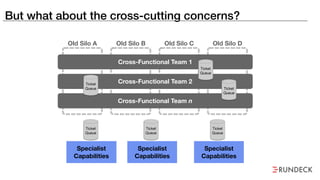
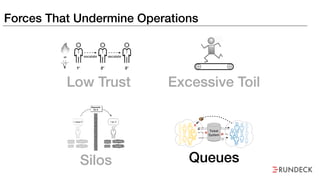
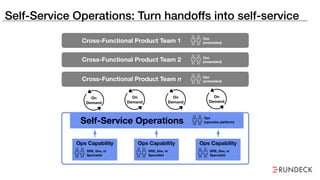
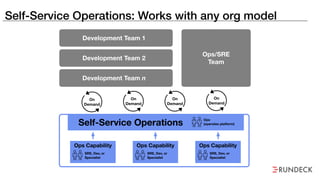
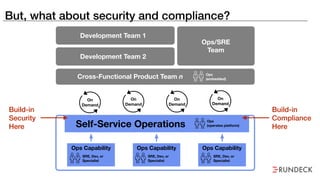







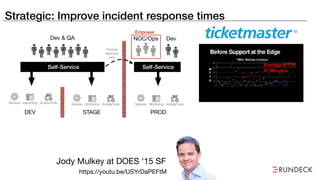
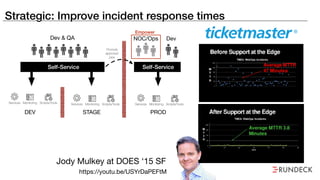
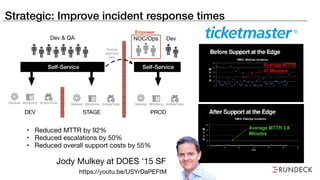


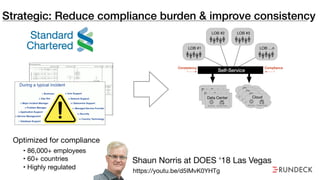
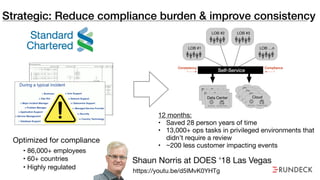

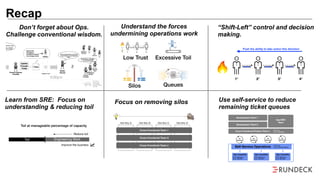


The document discusses the inefficiencies and frustrations caused by ticketing systems in operations, revealing how they contribute to miscommunication and delays in problem resolution. It emphasizes the need to challenge conventional wisdom around operations management, which often leads to excessive bureaucracy and toil, hindering productivity and innovation. The document also highlights the importance of psychological safety in teams to improve decision-making and responsiveness.





























































![Runbook Automation: Old News or a Key to Unlock Performance? [DOES2020]](https://cdn.slidesharecdn.com/ss_thumbnails/does-damonedwards-v2-201015073337-thumbnail.jpg?width=640&height=640&fit=bounds)

























