Downloaded 50 times













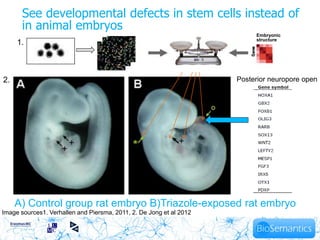





This document summarizes Kristina Hettne's PhD thesis defense on applying next-generation text mining to toxicogenomics data analysis. The thesis investigated improving information coverage in biomedical and chemical thesauri used for text mining by developing new chemical concept identification methods. A next-generation text mining approach was developed to statistically relate chemical information to gene expression data, allowing identification of toxicity effects at an earlier stage than manual curation alone. The approach was shown to complement and sometimes outperform existing databases, with potential to reduce animal testing through early prediction of drug toxicity.















































