Downloaded 67 times





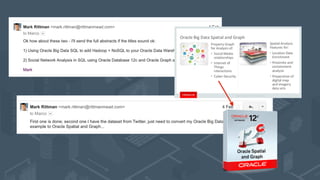





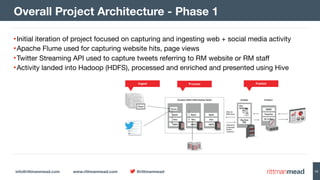








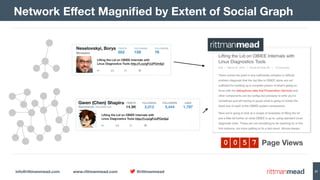

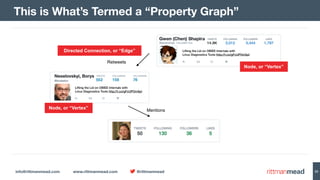


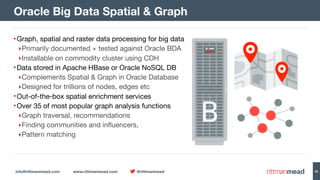
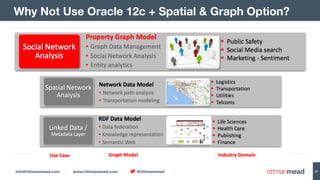

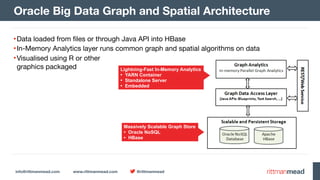
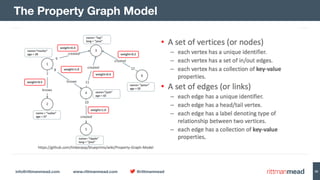
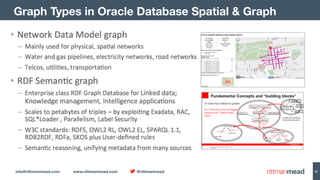



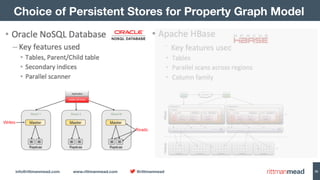
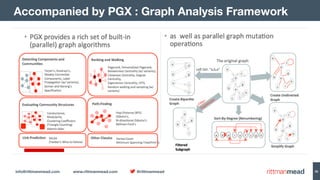



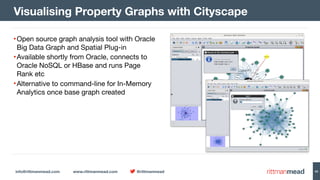
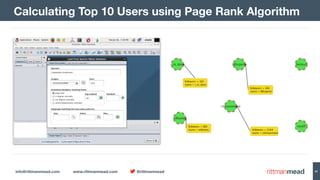
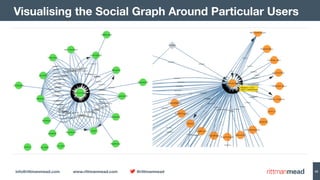
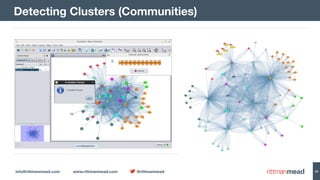
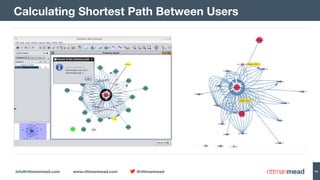



The document discusses using Hadoop and NoSQL technologies like Apache HBase to perform social network analysis on Twitter data related to a company's website and blog. It describes ingesting tweet and website log data into Hadoop HDFS and processing it with tools like Hive. Graph algorithms from Oracle Big Data Spatial & Graph were then used on the property graph stored in HBase to identify influential Twitter users and communities. This approach provided real-time insights at scale compared to using a traditional relational database.




































































































