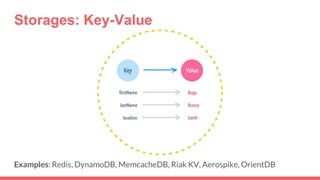
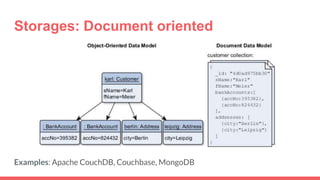
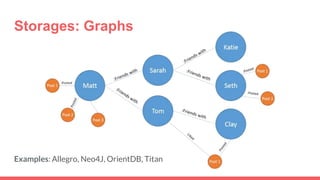
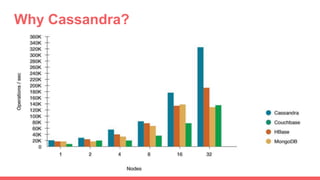
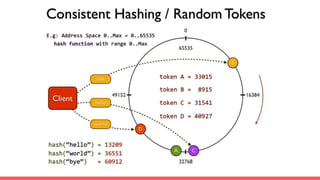
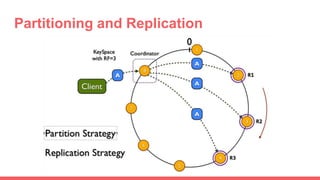
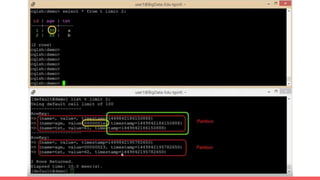
Big data storage systems address challenges of size, speed, and availability for huge volumes of data from sources like sensors, social networks, and logs. Common approaches include NoSQL distributed databases with horizontal scaling and data replication across clusters. Popular distributed file and key-value storage examples include Amazon, Redis, DynamoDB, and Cassandra which provide high availability through a masterless architecture with no single point of failure and support for rapid horizontal scaling.

![Agenda
[Big]Data Source: when it becomes Big?
What cluster is? Horizontal and vertical scaling
[Big]Data Storage challenges
Disadvantages
NoSQL = Not only SQL
Most popular and trendy](https://image.slidesharecdn.com/bigdatastorages-161104133033/85/Tatyana-Matvienko-Senior-Java-Developer-Big-data-storages-2-320.jpg)